HTTP 트리거와 함께 이벤트 기반 Cloud 함수를 사용하고 Cloud Scheduler를 사용하여 사전 컴파일된 파이프라인 실행을 예약할 수 있습니다.
간단한 파이프라인 빌드 및 컴파일
Kubeflow Pipelines SDK를 사용하여 예약된 파이프라인을 빌드하고 이를 YAML 파일로 컴파일합니다.
샘플 hello-world-scheduled-pipeline:
from kfp import compiler
from kfp import dsl
# A simple component that prints and returns a greeting string
@dsl.component
def hello_world(message: str) -> str:
greeting_str = f'Hello, {message}'
print(greeting_str)
return greeting_str
# A simple pipeline that contains a single hello_world task
@dsl.pipeline(
name='hello-world-scheduled-pipeline')
def hello_world_scheduled_pipeline(greet_name: str):
hello_world_task = hello_world(greet_name)
# Compile the pipeline and generate a YAML file
compiler.Compiler().compile(pipeline_func=hello_world_scheduled_pipeline,
package_path='hello_world_scheduled_pipeline.yaml')
컴파일된 파이프라인 YAML을 Cloud Storage 버킷에 업로드
Google Cloud 콘솔에서 Cloud Storage 브라우저를 엽니다.
프로젝트를 구성할 때 만든 Cloud Storage 버킷을 클릭합니다.
기존 폴더 또는 새 폴더를 사용하여 컴파일된 파이프라인 YAML(이 예시에서는
hello_world_scheduled_pipeline.yaml)을 선택한 폴더에 업로드합니다.업로드된 YAML 파일을 클릭하여 세부정보에 액세스합니다. 나중에 사용할 수 있도록 gsutil URI를 복사합니다.
HTTP 트리거로 Cloud 함수 만들기
Console에서 Cloud Functions 페이지로 이동합니다.
함수 만들기 버튼을 클릭합니다.
기본사항 섹션에서 함수 이름을 지정합니다(예:
hello-world-scheduled-pipeline-function).트리거 섹션에서 트리거 유형으로 HTTP를 선택합니다.
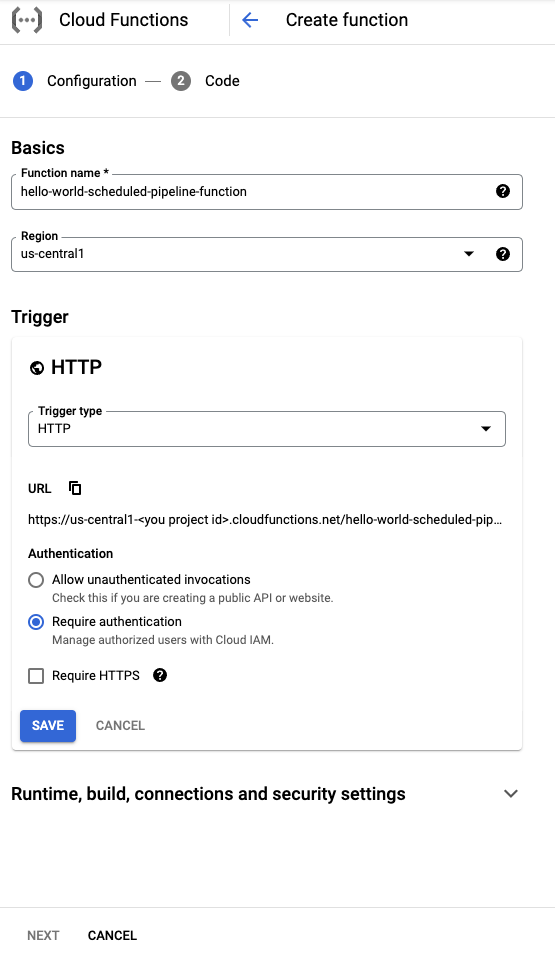
이 트리거로 생성된 URL을 기록해두고 다음 섹션에 사용할 수 있도록 저장합니다.
다른 필드는 모두 기본값으로 두고 저장을 클릭하여 트리거 섹션 구성을 저장합니다.
다른 필드는 모두 기본값으로 두고 다음을 클릭하여 코드 섹션으로 이동합니다.
런타임에서 Python 3.7을 선택합니다.
진입점에서 process_request(예시 코드 진입점 함수 이름)를 입력합니다.
아직 선택하지 않았으면 소스 코드 아래에서 인라인 편집기를 선택합니다.
main.py파일에서 다음 코드를 추가합니다.import json from google.cloud import aiplatform PROJECT_ID = 'your-project-id' # <---CHANGE THIS REGION = 'your-region' # <---CHANGE THIS PIPELINE_ROOT = 'your-cloud-storage-pipeline-root' # <---CHANGE THIS def process_request(request): """Processes the incoming HTTP request. Args: request (flask.Request): HTTP request object. Returns: The response text or any set of values that can be turned into a Response object using `make_response <http://flask.pocoo.org/docs/1.0/api/#flask.Flask.make_response>`. """ # decode http request payload and translate into JSON object request_str = request.data.decode('utf-8') request_json = json.loads(request_str) pipeline_spec_uri = request_json['pipeline_spec_uri'] parameter_values = request_json['parameter_values'] aiplatform.init( project=PROJECT_ID, location=REGION, ) job = aiplatform.PipelineJob( display_name=f'hello-world-cloud-function-pipeline', template_path=pipeline_spec_uri, pipeline_root=PIPELINE_ROOT, enable_caching=False, parameter_values=parameter_values ) job.submit() return "Job submitted"다음을 바꿉니다.
- PROJECT_ID: 이 파이프라인이 실행되는 Google Cloud 프로젝트입니다.
- REGION: 이 파이프라인이 실행되는 리전입니다.
- PIPELINE_ROOT: 파이프라인 서비스 계정이 액세스할 수 있는 Cloud Storage URI를 지정합니다. 파이프라인 실행의 아티팩트는 파이프라인 루트에 저장됩니다.
requirements.txt파일에서 콘텐츠를 다음 패키지 요구사항으로 바꿉니다.google-api-python-client>=1.7.8,<2 google-cloud-aiplatform배포를 클릭하여 함수를 배포합니다.
Cloud Scheduler 작업 만들기
콘솔에서 Cloud Scheduler 페이지로 이동합니다.
작업 만들기 버튼을 클릭합니다.
작업에 이름(예:
my-hello-world-schedule)을 지정하고 필요 시 설명을 추가합니다.unix-cron 형식을 사용하여 작업의 빈도를 지정합니다. 예를 들면 다음과 같습니다.
0 9 * * 1이 예시 크론 일정은 매주 월요일 오전 9:00에 실행됩니다. 자세한 내용은 크론 작업 일정 구성을 참조하세요.
시간대를 선택합니다.
계속을 클릭하여 실행을 구성합니다.
대상 유형 메뉴에서 HTTP를 선택합니다.
URL 필드에 이전 섹션에서 저장한 트리거 URL을 입력합니다.
아직 선택하지 않았으면 POST를 HTTP 메서드로 선택합니다.
본문 상자에서 코드에 정의된 형식으로 JSON 문자열을 입력합니다. 이전 섹션의 예시 사용:
{ "pipeline_spec_uri": "<path-to-your-compiled-pipeline>", "parameter_values": { "greet_name": "<any-greet-string>" } }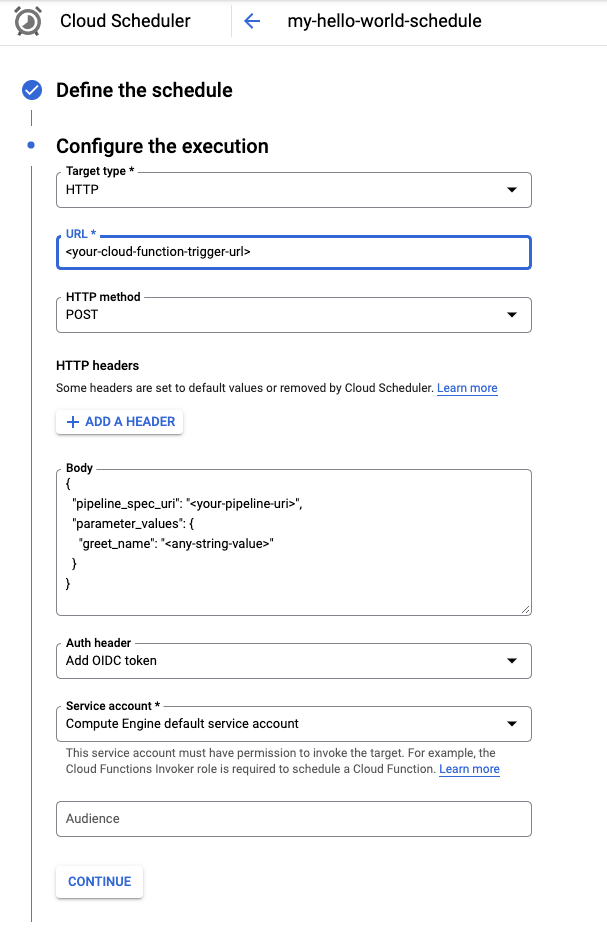
인증 헤더 드롭다운에서 OIDC 토큰 추가를 선택합니다.
서비스 계정 드롭다운에서 Cloud 함수 호출 권한이 있는 서비스 계정을 선택합니다. 이 튜토리얼에서는 Compute Engine 기본 서비스 계정을 사용할 수 있습니다.
다른 필드는 모두 기본값으로 두고 만들기를 클릭합니다.
수동으로 작업 실행(선택사항)
필요에 따라 바로 전에 만든 작업을 실행하여 기능을 확인합니다.
Cloud Scheduler 콘솔 페이지를 엽니다.
작업 이름 옆에 있는 지금 실행 버튼을 클릭합니다.
프로젝트에 만들어진 첫 번째 작업은 필수 구성 때문에 처음 호출되면 실행하는 데 몇 분이 소요될 수 있습니다.
결과 열에서 작업 상태를 확인할 수 있습니다.