Halaman ini memperkenalkan cara melakukan evaluasi berbasis model berpasangan menggunakan AutoSxS, yang merupakan alat yang berjalan melalui layanan pipeline evaluasi. Kami menjelaskan cara menggunakan AutoSxS melalui Vertex AI API, Vertex AI SDK untuk Python, atau Google Cloud konsol.
AutoSxS
Automatic side-by-side (AutoSxS) adalah alat evaluasi berbasis model berpasangan yang berjalan melalui layanan pipeline evaluasi. AutoSxS dapat digunakan untuk mengevaluasi performa model AI generatif di Vertex AI Model Registry atau prediksi yang telah dibuat sebelumnya, sehingga dapat mendukung model dasar Vertex AI, model AI generatif yang telah disesuaikan, dan model bahasa pihak ketiga. AutoSxS menggunakan penilai otomatis untuk memutuskan model mana yang memberikan respons yang lebih baik terhadap perintah. Alat ini tersedia sesuai permintaan dan mengevaluasi model bahasa dengan performa yang sebanding dengan pemberi rating manusia.
Autorater
Secara umum, diagram ini menunjukkan cara AutoSxS membandingkan prediksi model A dan B dengan model ketiga, yaitu autorater.
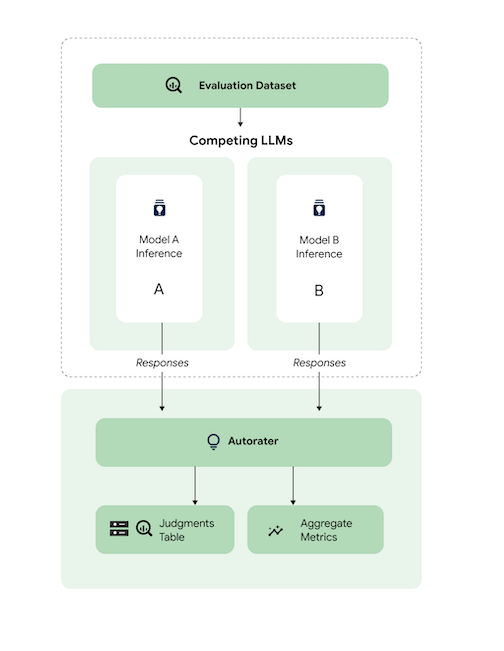
Model A dan B menerima perintah input, dan setiap model menghasilkan respons yang dikirim ke pemberi rating otomatis. Mirip dengan pemberi rating manusia, autorater adalah model bahasa yang menilai kualitas respons model berdasarkan perintah inferensi asli. Dengan AutoSxS, autorater membandingkan kualitas dua respons model berdasarkan petunjuk inferensinya menggunakan serangkaian kriteria. Kriteria ini digunakan untuk menentukan model mana yang berperforma terbaik dengan membandingkan hasil Model A dengan hasil Model B. Autorater menampilkan preferensi respons sebagai metrik gabungan dan menampilkan penjelasan preferensi serta skor keyakinan untuk setiap contoh. Untuk mengetahui informasi selengkapnya, lihat tabel putusan.
Model yang didukung
AutoSxS mendukung evaluasi model apa pun jika prediksi yang telah dibuat sebelumnya diberikan. AutoSxS juga mendukung pembuatan respons secara otomatis untuk model apa pun di Vertex AI Model Registry yang mendukung prediksi batch di Vertex AI.
Jika Model teks Anda tidak didukung oleh Vertex AI Model Registry, AutoSxS juga menerima prediksi yang telah dibuat sebelumnya dan disimpan sebagai JSONL di Cloud Storage atau tabel BigQuery. Untuk mengetahui harga, lihat Pembuatan teks.
Tugas dan kriteria yang didukung
AutoSxS mendukung evaluasi model untuk tugas peringkasan dan question answering. Kriteria evaluasi telah ditentukan sebelumnya untuk setiap tugas, sehingga evaluasi bahasa menjadi lebih objektif dan meningkatkan kualitas respons.
Kriteria dicantumkan menurut tugas.
Ringkasan
Tugas summarization memiliki token
input dengan batas 4.096.
Daftar kriteria evaluasi untuk summarization adalah sebagai berikut:
| Kriteria | |
|---|---|
| 1. Mengikuti petunjuk | Sejauh mana respons model menunjukkan pemahaman tentang petunjuk dari perintah? |
| 2. Grounded | Apakah respons hanya menyertakan informasi dari konteks inferensi dan petunjuk inferensi? |
| 3. Komprehensif | Sejauh mana model menangkap detail penting dalam ringkasan? |
| 4. Singkat | Apakah ringkasannya terlalu panjang? Apakah menggunakan bahasa yang indah? Apakah terlalu singkat? |
Jawaban pertanyaan
Tugas question_answering memiliki token
input dengan batas 4.096.
Daftar kriteria evaluasi untuk question_answering adalah sebagai berikut:
| Kriteria | |
|---|---|
| 1. Menjawab pertanyaan sepenuhnya | Jawaban merespons pertanyaan secara lengkap. |
| 2. Grounded | Apakah respons hanya menyertakan informasi dari konteks petunjuk dan petunjuk inferensi? |
| 3. Relevansi | Apakah konten jawaban terkait dengan pertanyaan? |
| 4. Komprehensif | Seberapa jauh model menangkap detail penting dalam pertanyaan? |
Menyiapkan set data evaluasi untuk AutoSxS
Bagian ini menjelaskan data yang harus Anda berikan dalam set data evaluasi AutoSxS dan praktik terbaik untuk pembuatan set data. Contoh harus mencerminkan input dunia nyata yang mungkin dihadapi model Anda dalam produksi dan paling baik membandingkan perilaku model aktif Anda.
Format set data
AutoSxS menerima satu set data evaluasi dengan skema yang fleksibel. Set data dapat berupa tabel BigQuery atau disimpan sebagai JSON Lines di Cloud Storage.
Setiap baris set data evaluasi mewakili satu contoh, dan kolomnya adalah salah satu dari berikut ini:
- Kolom ID: Digunakan untuk mengidentifikasi setiap contoh unik.
- Kolom data: Digunakan untuk mengisi template perintah. Lihat Parameter perintah
- Prediksi yang dibuat sebelumnya: Prediksi yang dibuat oleh model yang sama menggunakan perintah yang sama. Menggunakan prediksi yang dibuat sebelumnya akan menghemat waktu dan resource.
- Preferensi manusia kebenaran nyata: Digunakan untuk mengukur performa AutoSxS terhadap data preferensi kebenaran nyata Anda saat prediksi yang telah dibuat sebelumnya diberikan untuk kedua model.
Berikut adalah contoh set data evaluasi dengan context dan question sebagai kolom data, serta model_b_response berisi prediksi yang telah dibuat sebelumnya.
context |
question |
model_b_response |
|---|---|---|
| Beberapa orang mungkin berpikir bahwa baja atau titanium adalah bahan terkeras, tetapi sebenarnya berlian adalah bahan terkeras. | Apa bahan yang paling keras? | Intan adalah bahan terkeras. Lebih keras daripada baja atau titanium. |
Untuk mengetahui informasi selengkapnya tentang cara memanggil AutoSxS, lihat Melakukan evaluasi model. Untuk mengetahui detail tentang panjang token, lihat Tugas dan kriteria yang didukung. Untuk mengupload data Anda ke Cloud Storage, lihat Mengupload set data evaluasi ke Cloud Storage.
Parameter perintah
Banyak model bahasa menggunakan parameter perintah sebagai input, bukan string perintah
tunggal. Misalnya,
chat-bison menggunakan
beberapa parameter perintah (messages, examples, context), yang membentuk bagian
dari perintah. Namun, text-bison
hanya memiliki satu parameter perintah, yang bernama prompt, yang berisi seluruh
perintah.
Kami menguraikan cara Anda dapat secara fleksibel menentukan parameter perintah model pada waktu inferensi dan evaluasi. AutoSxS memberi Anda fleksibilitas untuk memanggil model bahasa dengan berbagai input yang diharapkan melalui parameter perintah yang dibuat dengan template.
Inferensi
Jika salah satu model tidak memiliki prediksi yang telah dibuat sebelumnya, AutoSxS akan menggunakan prediksi batch Vertex AI untuk menghasilkan respons. Parameter perintah setiap model harus ditentukan.
Di AutoSxS, Anda dapat memberikan satu kolom dalam set data evaluasi sebagai parameter perintah.
{'some_parameter': {'column': 'my_column'}}
Atau, Anda dapat menentukan template, menggunakan kolom dari set data evaluasi sebagai variabel, untuk menentukan parameter perintah:
{'some_parameter': {'template': 'Summarize the following: {{ my_column }}.'}}
Saat memberikan parameter perintah model untuk inferensi, pengguna dapat menggunakan kata kunci default_instruction yang dilindungi sebagai argumen template, yang diganti dengan petunjuk inferensi default untuk tugas tertentu:
model_prompt_parameters = {
'prompt': {'template': '{{ default_instruction }}: {{ context }}'},
}
Jika membuat prediksi, berikan parameter perintah model dan kolom output. Lihat contoh berikut:
Gemini
Untuk model Gemini, kunci parameter perintah model adalah
contents (wajib) dan system_instruction (opsional), yang sesuai dengan
skema isi permintaan Gemini.
model_a_prompt_parameters={
'contents': {
'column': 'context'
},
'system_instruction': {'template': '{{ default_instruction }}'},
},
text-bison
Misalnya, text-bison menggunakan "prompt" untuk input dan "content" untuk
output. Ikuti langkah-langkah
berikut:
- Identifikasi input dan output yang diperlukan oleh model yang dievaluasi.
- Tentukan input sebagai parameter perintah model.
- Teruskan output ke kolom respons.
model_a_prompt_parameters={
'prompt': {
'template': {
'Answer the following question from the point of view of a college professor: {{ context }}\n{{ question }}'
},
},
},
response_column_a='content', # Column in Model A response.
response_column_b='model_b_response', # Column in eval dataset.
Evaluasi
Sama seperti Anda harus memberikan parameter perintah untuk inferensi, Anda juga harus memberikan parameter perintah untuk evaluasi. Autorater memerlukan parameter perintah berikut:
| Parameter perintah pemberi rating otomatis | Dapat dikonfigurasi oleh pengguna? | Deskripsi | Contoh |
|---|---|---|---|
| Petunjuk pemberi rating otomatis | Tidak | Petunjuk yang dikalibrasi yang menjelaskan kriteria yang harus digunakan oleh pemberi skor otomatis untuk menilai respons yang diberikan. | Pilih respons yang menjawab pertanyaan dan paling sesuai dengan petunjuk. |
| Petunjuk inferensi | Ya | Deskripsi tugas yang harus dilakukan setiap model kandidat. | Jawab pertanyaan dengan akurat: Bahan manakah yang paling keras? |
| Konteks inferensi | Ya | Konteks tambahan untuk tugas yang sedang dilakukan. | Meskipun titanium dan berlian lebih keras daripada tembaga, berlian memiliki tingkat kekerasan 98, sedangkan titanium memiliki tingkat kekerasan 36. Rating yang lebih tinggi berarti kekerasan yang lebih tinggi. |
| Respons | Tidak1 | Sepasang respons untuk dievaluasi, satu dari setiap model kandidat. | Diamond |
1Anda hanya dapat mengonfigurasi parameter perintah melalui respons yang telah dibuat sebelumnya.
Contoh kode menggunakan parameter:
autorater_prompt_parameters={
'inference_instruction': {
'template': 'Answer the following question from the point of view of a college professor: {{ question }}.'
},
'inference_context': {
'column': 'context'
}
}
Model A dan B dapat memiliki petunjuk dan konteks inferensi yang diformat secara berbeda, baik informasi yang sama diberikan atau tidak. Artinya, autorater mengambil satu petunjuk dan konteks inferensi yang terpisah.
Contoh set data evaluasi
Bagian ini memberikan contoh set data evaluasi tugas tanya jawab,
termasuk prediksi yang telah dibuat sebelumnya untuk model B. Dalam contoh ini, AutoSxS
hanya melakukan inferensi untuk model A. Kami menyediakan kolom id untuk membedakan
antara contoh dengan pertanyaan dan konteks yang sama.
{
"id": 1,
"question": "What is the hardest material?",
"context": "Some might think that steel is the hardest material, or even titanium. However, diamond is actually the hardest material.",
"model_b_response": "Diamond is the hardest material. It is harder than steel or titanium."
}
{
"id": 2,
"question": "What is the highest mountain in the world?",
"context": "K2 and Everest are the two tallest mountains, with K2 being just over 28k feet and Everest being 29k feet tall.",
"model_b_response": "Mount Everest is the tallest mountain, with a height of 29k feet."
}
{
"id": 3,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "Francis Ford Coppola directed The Godfather."
}
{
"id": 4,
"question": "Who directed The Godfather?",
"context": "Mario Puzo and Francis Ford Coppola co-wrote the screenplay for The Godfather, and the latter directed it as well.",
"model_b_response": "John Smith."
}
Praktik terbaik
Ikuti praktik terbaik berikut saat menentukan set data evaluasi Anda:
- Berikan contoh yang mewakili jenis input yang diproses model Anda dalam produksi.
- Set data Anda harus menyertakan minimal satu contoh evaluasi. Sebaiknya gunakan sekitar 100 contoh untuk memastikan metrik gabungan berkualitas tinggi. Tingkat peningkatan kualitas metrik gabungan cenderung menurun jika lebih dari 400 contoh diberikan.
- Untuk panduan menulis perintah, lihat Mendesain perintah teks.
- Jika Anda menggunakan prediksi yang telah dibuat sebelumnya untuk salah satu model, sertakan prediksi yang telah dibuat sebelumnya dalam kolom set data evaluasi Anda. Menyediakan prediksi yang telah dibuat sebelumnya berguna karena memungkinkan Anda membandingkan output model yang tidak ada di Vertex Model Registry dan memungkinkan Anda menggunakan kembali respons.
Melakukan evaluasi model
Anda dapat mengevaluasi model menggunakan REST API, Vertex AI SDK untuk Python, atau Google Cloud konsol.
Gunakan sintaksis ini untuk menentukan jalur ke model Anda:
- Model penayang:
publishers/PUBLISHER/models/MODELContoh:publishers/google/models/text-bison Model yang disesuaikan:
projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL@VERSIONContoh:projects/123456789012/locations/us-central1/models/1234567890123456789
REST
Untuk membuat tugas evaluasi model, kirim permintaan POST menggunakan
metode pipelineJobs.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
- PIPELINEJOB_DISPLAYNAME : Nama tampilan untuk
pipelineJob. - PROJECT_ID : Google Cloud project yang menjalankan komponen pipeline.
- LOCATION : Region untuk menjalankan komponen pipeline.
us-central1didukung. - OUTPUT_DIR : URI Cloud Storage untuk menyimpan output evaluasi.
- EVALUATION_DATASET : Tabel BigQuery atau daftar jalur Cloud Storage yang dipisahkan koma ke set data JSONL yang berisi contoh evaluasi.
- TASK : Tugas evaluasi, yang dapat berupa salah satu dari
[summarization, question_answering]. - ID_COLUMNS : Kolom yang membedakan contoh evaluasi unik.
- AUTORATER_PROMPT_PARAMETERS : Parameter perintah Autorater dipetakan ke kolom atau template. Parameter yang diharapkan adalah:
inference_instruction(detail tentang cara melakukan tugas) daninference_context(konten yang akan dirujuk untuk melakukan tugas). Sebagai contoh,{'inference_context': {'column': 'my_prompt'}}menggunakan kolom `my_prompt` set data evaluasi untuk konteks autorater. - RESPONSE_COLUMN_A : Nama kolom dalam set data evaluasi yang berisi prediksi yang telah ditentukan sebelumnya, atau nama kolom dalam output Model A yang berisi prediksi. Jika tidak ada nilai yang diberikan, nama kolom output model yang benar akan coba disimpulkan.
- RESPONSE_COLUMN_B : Nama kolom dalam set data evaluasi yang berisi prediksi yang telah ditentukan sebelumnya, atau nama kolom dalam output Model B yang berisi prediksi. Jika tidak ada nilai yang diberikan, nama kolom output model yang benar akan coba disimpulkan.
- MODEL_A (Opsional): Nama resource model yang sepenuhnya memenuhi syarat (
projects/{project}/locations/{location}/models/{model}@{version}) atau nama resource model penayang (publishers/{publisher}/models/{model}). Jika respons Model A ditentukan, parameter ini tidak boleh diberikan. - MODEL_B (Opsional): Nama resource model yang sepenuhnya memenuhi syarat (
projects/{project}/locations/{location}/models/{model}@{version}) atau nama resource model penayang (publishers/{publisher}/models/{model}). Jika respons Model B ditentukan, parameter ini tidak boleh diberikan. - MODEL_A_PROMPT_PARAMETERS (Opsional): Parameter template perintah Model A yang dipetakan ke kolom atau template. Jika respons Model A telah ditentukan sebelumnya, parameter ini tidak boleh diberikan. Contoh:
{'prompt': {'column': 'my_prompt'}}menggunakan kolommy_promptset data evaluasi untuk parameter perintah bernamaprompt. - MODEL_B_PROMPT_PARAMETERS (Opsional): Parameter template perintah Model B dipetakan ke kolom atau template. Jika respons Model B telah ditentukan sebelumnya, parameter ini tidak boleh diberikan. Contoh:
{'prompt': {'column': 'my_prompt'}}menggunakan kolommy_promptset data evaluasi untuk parameter perintah bernamaprompt. - JUDGMENTS_FORMAT
(Opsional): Format untuk menulis penilaian. Dapat berupa
jsonl(default),json, ataubigquery. - BIGQUERY_DESTINATION_PREFIX: Tabel BigQuery untuk menulis penilaian jika format yang ditentukan adalah
bigquery.
Isi JSON permintaan
{
"displayName": "PIPELINEJOB_DISPLAYNAME",
"runtimeConfig": {
"gcsOutputDirectory": "gs://OUTPUT_DIR",
"parameterValues": {
"evaluation_dataset": "EVALUATION_DATASET",
"id_columns": ["ID_COLUMNS"],
"task": "TASK",
"autorater_prompt_parameters": AUTORATER_PROMPT_PARAMETERS,
"response_column_a": "RESPONSE_COLUMN_A",
"response_column_b": "RESPONSE_COLUMN_B",
"model_a": "MODEL_A",
"model_a_prompt_parameters": MODEL_A_PROMPT_PARAMETERS,
"model_b": "MODEL_B",
"model_b_prompt_parameters": MODEL_B_PROMPT_PARAMETERS,
"judgments_format": "JUDGMENTS_FORMAT",
"bigquery_destination_prefix":BIGQUERY_DESTINATION_PREFIX,
},
},
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default"
}
Gunakan curl untuk mengirim permintaan Anda.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/pipelineJobs"
Respons
"state": "PIPELINE_STATE_PENDING",
"labels": {
"vertex-ai-pipelines-run-billing-id": "1234567890123456789"
},
"runtimeConfig": {
"gcsOutputDirectory": "gs://my-evaluation-bucket/output",
"parameterValues": {
"evaluation_dataset": "gs://my-evaluation-bucket/output/data.json",
"id_columns": [
"context"
],
"task": "question_answering",
"autorater_prompt_parameters": {
"inference_instruction": {
"template": "Answer the following question: {{ question }} }."
},
"inference_context": {
"column": "context"
}
},
"response_column_a": "",
"response_column_b": "response_b",
"model_a": "publishers/google/models/text-bison@002",
"model_a_prompt_parameters": {
"prompt": {
"template": "Answer the following question from the point of view of a college professor: {{ question }}\n{{ context }} }"
}
},
"model_b": "",
"model_b_prompt_parameters": {}
}
},
"serviceAccount": "123456789012-compute@",
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default",
"templateMetadata": {
"version": "sha256:7366b784205551ed28f2c076e841c0dbeec4111b6df16743fc5605daa2da8f8a"
}
}
Vertex AI SDK untuk Python
Untuk mempelajari cara menginstal atau mengupdate Vertex AI SDK untuk Python, lihat Menginstal Vertex AI SDK untuk Python. Untuk mengetahui informasi selengkapnya tentang Python API, lihat Vertex AI SDK untuk Python API.
Untuk mengetahui informasi selengkapnya tentang parameter pipeline, lihat Dokumentasi Referensi Komponen Pipeline Google Cloud.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
- PIPELINEJOB_DISPLAYNAME : Nama tampilan untuk
pipelineJob. - PROJECT_ID : Google Cloud project yang menjalankan komponen pipeline.
- LOCATION : Region untuk menjalankan komponen pipeline.
us-central1didukung. - OUTPUT_DIR : URI Cloud Storage untuk menyimpan output evaluasi.
- EVALUATION_DATASET : Tabel BigQuery atau daftar jalur Cloud Storage yang dipisahkan koma ke set data JSONL yang berisi contoh evaluasi.
- TASK : Tugas evaluasi, yang dapat berupa salah satu dari
[summarization, question_answering]. - ID_COLUMNS : Kolom yang membedakan contoh evaluasi unik.
- AUTORATER_PROMPT_PARAMETERS : Parameter perintah Autorater dipetakan ke kolom atau template. Parameter yang diharapkan adalah:
inference_instruction(detail tentang cara melakukan tugas) daninference_context(konten yang akan dirujuk untuk melakukan tugas). Sebagai contoh,{'inference_context': {'column': 'my_prompt'}}menggunakan kolom `my_prompt` set data evaluasi untuk konteks autorater. - RESPONSE_COLUMN_A : Nama kolom dalam set data evaluasi yang berisi prediksi yang telah ditentukan sebelumnya, atau nama kolom dalam output Model A yang berisi prediksi. Jika tidak ada nilai yang diberikan, nama kolom output model yang benar akan coba disimpulkan.
- RESPONSE_COLUMN_B : Nama kolom dalam set data evaluasi yang berisi prediksi yang telah ditentukan sebelumnya, atau nama kolom dalam output Model B yang berisi prediksi. Jika tidak ada nilai yang diberikan, nama kolom output model yang benar akan coba disimpulkan.
- MODEL_A (Opsional): Nama resource model yang sepenuhnya memenuhi syarat (
projects/{project}/locations/{location}/models/{model}@{version}) atau nama resource model penayang (publishers/{publisher}/models/{model}). Jika respons Model A ditentukan, parameter ini tidak boleh diberikan. - MODEL_B (Opsional): Nama resource model yang sepenuhnya memenuhi syarat (
projects/{project}/locations/{location}/models/{model}@{version}) atau nama resource model penayang (publishers/{publisher}/models/{model}). Jika respons Model B ditentukan, parameter ini tidak boleh diberikan. - MODEL_A_PROMPT_PARAMETERS (Opsional): Parameter template perintah Model A yang dipetakan ke kolom atau template. Jika respons Model A telah ditentukan sebelumnya, parameter ini tidak boleh diberikan. Contoh:
{'prompt': {'column': 'my_prompt'}}menggunakan kolommy_promptset data evaluasi untuk parameter perintah bernamaprompt. - MODEL_B_PROMPT_PARAMETERS (Opsional): Parameter template perintah Model B dipetakan ke kolom atau template. Jika respons Model B telah ditentukan sebelumnya, parameter ini tidak boleh diberikan. Contoh:
{'prompt': {'column': 'my_prompt'}}menggunakan kolommy_promptset data evaluasi untuk parameter perintah bernamaprompt. - JUDGMENTS_FORMAT
(Opsional): Format untuk menulis penilaian. Dapat berupa
jsonl(default),json, ataubigquery. - BIGQUERY_DESTINATION_PREFIX: Tabel BigQuery untuk menulis penilaian jika format yang ditentukan adalah
bigquery.
import os
from google.cloud import aiplatform
parameters = {
'evaluation_dataset': 'EVALUATION_DATASET',
'id_columns': ['ID_COLUMNS'],
'task': 'TASK',
'autorater_prompt_parameters': AUTORATER_PROMPT_PARAMETERS,
'response_column_a': 'RESPONSE_COLUMN_A',
'response_column_b': 'RESPONSE_COLUMN_B',
'model_a': 'MODEL_A',
'model_a_prompt_parameters': MODEL_A_PROMPT_PARAMETERS,
'model_b': 'MODEL_B',
'model_b_prompt_parameters': MODEL_B_PROMPT_PARAMETERS,
'judgments_format': 'JUDGMENTS_FORMAT',
'bigquery_destination_prefix':
BIGQUERY_DESTINATION_PREFIX,
}
aiplatform.init(project='PROJECT_ID', location='LOCATION', staging_bucket='gs://OUTPUT_DIR')
aiplatform.PipelineJob(
display_name='PIPELINEJOB_DISPLAYNAME',
pipeline_root=os.path.join('gs://OUTPUT_DIR', 'PIPELINEJOB_DISPLAYNAME'),
template_path=(
'https://us-kfp.pkg.dev/ml-pipeline/google-cloud-registry/autosxs-template/default'),
parameter_values=parameters,
).run()
Konsol
Untuk membuat tugas evaluasi model berpasangan menggunakan konsol Google Cloud , lakukan langkah-langkah berikut:
Mulai dengan model dasar Google, atau gunakan model yang sudah ada di Vertex AI Model Registry Anda:
Untuk mengevaluasi model dasar Google:
Buka Vertex AI Model Garden dan pilih model yang mendukung evaluasi berpasangan, seperti
text-bison.Klik Evaluate.
Di menu yang muncul, klik Pilih untuk memilih versi model.
Panel Simpan model dapat meminta Anda menyimpan salinan model di Vertex AI Model Registry jika Anda belum memiliki salinannya. Masukkan Nama model, lalu klik Simpan.
Halaman Create Evaluation akan muncul. Untuk langkah Evaluate Method, pilih Evaluate this model against another model.
Klik Lanjutkan.
Untuk mengevaluasi model yang ada di Vertex AI Model Registry:
Buka halaman Vertex AI Model Registry:
Klik nama model yang ingin dievaluasi. Pastikan jenis model memiliki dukungan evaluasi berpasangan. Contohnya,
text-bison.Di tab Evaluate, klik SxS.
Klik Buat Evaluasi SxS.
Untuk setiap langkah di halaman pembuatan evaluasi, masukkan informasi yang diperlukan, lalu klik Lanjutkan:
Untuk langkah Set data evaluasi, pilih tujuan evaluasi dan model untuk dibandingkan dengan model yang Anda pilih. Pilih set data evaluasi dan masukkan kolom ID (kolom respons).
Untuk langkah Setelan model, tentukan apakah Anda ingin menggunakan respons model yang sudah ada di set data Anda, atau apakah Anda ingin menggunakan Vertex AI Batch Prediction untuk membuat respons. Tentukan kolom respons untuk kedua model. Untuk opsi Prediksi Batch Vertex AI, Anda dapat menentukan parameter perintah model inferensi.
Untuk langkah Setelan autorater, masukkan parameter perintah autorater dan lokasi output untuk evaluasi.
Klik Mulai Evaluasi.
Melihat hasil evaluasi
Anda dapat menemukan hasil evaluasi di Vertex AI Pipelines dengan memeriksa artefak berikut yang dihasilkan oleh pipeline AutoSxS:
- Tabel penilaian dibuat oleh penentu AutoSxS.
- Metrik gabungan dihasilkan oleh komponen metrik AutoSxS.
- Metrik keselarasan preferensi manusia dihasilkan oleh komponen metrik AutoSxS.
Putusan
AutoSxS menghasilkan penilaian (metrik tingkat contoh) yang membantu pengguna memahami performa model di tingkat contoh. Penilaian mencakup informasi berikut:
- Perintah inferensi
- Respons model
- Keputusan pemberi rating otomatis
- Penjelasan rating
- Skor keyakinan
Penilaian dapat ditulis ke Cloud Storage dalam format JSONL atau ke tabel BigQuery dengan kolom berikut:
| Kolom | Deskripsi |
|---|---|
| kolom ID | Kolom yang membedakan contoh evaluasi unik. |
inference_instruction |
Petunjuk yang digunakan untuk membuat respons model. |
inference_context |
Konteks yang digunakan untuk menghasilkan respons model. |
response_a |
Respons Model A, dengan petunjuk dan konteks inferensi yang diberikan. |
response_b |
Respons Model B, dengan petunjuk dan konteks inferensi yang diberikan. |
choice |
Model dengan respons yang lebih baik. Nilai yang mungkin adalah Model A, Model B, atau Error. Error berarti error mencegah pemberi rating otomatis menentukan apakah respons model A atau respons model B yang terbaik. |
confidence |
Skor antara 0 dan 1, yang menunjukkan tingkat keyakinan autorater dengan pilihannya. |
explanation |
Alasan autorater memilih pilihan tersebut. |
Metrik agregat
AutoSxS menghitung metrik agregat (rasio kemenangan) menggunakan tabel penilaian. Jika tidak ada data preferensi manusia yang diberikan, metrik gabungan berikut akan dibuat:
| Metrik | Deskripsi |
|---|---|
| Rasio menang model AutoRater A | Persentase waktu saat autorater memutuskan bahwa model A memiliki respons yang lebih baik. |
| Rasio kemenangan model B AutoRater | Persentase waktu saat autorater memutuskan bahwa model B memiliki respons yang lebih baik. |
Untuk lebih memahami rasio kemenangan, lihat hasil berbasis baris dan penjelasan autorater untuk menentukan apakah hasil dan penjelasan tersebut sesuai dengan ekspektasi Anda.
Metrik keselarasan preferensi manusia
Jika data preferensi manusia diberikan, AutoSxS akan menampilkan metrik berikut:
| Metrik | Deskripsi | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Rasio menang model AutoRater A | Persentase waktu saat autorater memutuskan bahwa model A memiliki respons yang lebih baik. | ||||||||||||||
| Rasio kemenangan model B AutoRater | Persentase waktu saat autorater memutuskan bahwa model B memiliki respons yang lebih baik. | ||||||||||||||
| Rasio menang model A yang sesuai dengan preferensi manusia | Persentase waktu saat manusia memutuskan bahwa model A memberikan respons yang lebih baik. | ||||||||||||||
| Rasio menang model B preferensi manusia | Persentase waktu saat manusia memutuskan bahwa model B memberikan respons yang lebih baik. | ||||||||||||||
| TP | Jumlah contoh di mana autorater dan preferensi manusia menunjukkan bahwa Model A memberikan respons yang lebih baik. | ||||||||||||||
| FP | Jumlah contoh saat autorater memilih Model A sebagai respons yang lebih baik, tetapi preferensi manusia adalah Model B memiliki respons yang lebih baik. | ||||||||||||||
| TN | Jumlah contoh di mana autorater dan preferensi manusia menunjukkan bahwa Model B memberikan respons yang lebih baik. | ||||||||||||||
| FN | Jumlah contoh saat autorater memilih Model B sebagai respons yang lebih baik, tetapi preferensi manusia adalah Model A memiliki respons yang lebih baik. | ||||||||||||||
| Akurasi | Persentase waktu saat pemberi rating otomatis setuju dengan pemberi rating manual. | ||||||||||||||
| Presisi | Persentase waktu saat autorater dan manusia menganggap Model A memiliki respons yang lebih baik, dari semua kasus saat autorater menganggap Model A memiliki respons yang lebih baik. | ||||||||||||||
| Recall | Persentase waktu saat autorater dan manusia menganggap Respons Model A lebih baik, dari semua kasus saat manusia menganggap Respons Model A lebih baik. | ||||||||||||||
| F1 | Rata-rata presisi dan recall yang harmonis. | ||||||||||||||
| Kappa Cohen | Pengukuran kesepakatan antara pemberi rating otomatis dan pemberi rating manusia yang memperhitungkan kemungkinan kesepakatan acak. Cohen menyarankan interpretasi berikut:
|
Kasus penggunaan AutoSxS
Anda dapat mempelajari cara menggunakan AutoSxS dengan tiga skenario kasus penggunaan.
Membandingkan model
Mengevaluasi model pihak pertama (1p) yang telah di-tuning terhadap model 1p referensi.
Anda dapat menentukan bahwa inferensi berjalan pada kedua model secara bersamaan.
Contoh kode ini mengevaluasi model yang disesuaikan dari Vertex Model Registry terhadap model referensi dari registry yang sama.
# Evaluation dataset schema:
# my_question: str
# my_context: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'model_a': 'publishers/google/models/text-bison@002',
'model_a_prompt_parameters': {QUESTION: {'template': '{{my_question}}\nCONTEXT: {{my_context}}'}},
'response_column_a': 'content',
'model_b': 'projects/abc/locations/abc/models/tuned_bison',
'model_b_prompt_parameters': {'prompt': {'template': '{{my_context}}\n{{my_question}}'}},
'response_column_b': 'content',
}
Membandingkan prediksi
Mengevaluasi model pihak ketiga (3p) yang di-tuning terhadap model 3p referensi.
Anda dapat melewati inferensi dengan memberikan respons model secara langsung.
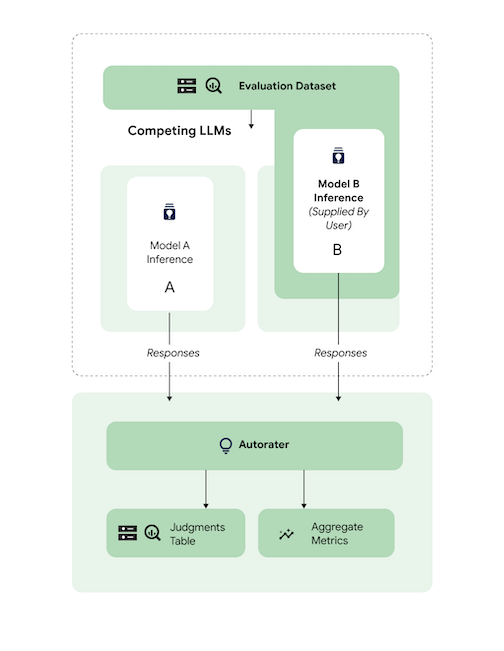
Contoh kode ini mengevaluasi model pihak ketiga yang di-tuning terhadap model pihak ketiga referensi.
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_b: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters':
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'content',
'response_column_b': 'response_b',
}
Periksa perataan
Semua tugas yang didukung telah diukur menggunakan data pemberi rating manusia untuk memastikan respons pemberi rating otomatis selaras dengan preferensi manusia. Jika Anda ingin mengukur performa AutoSxS untuk kasus penggunaan Anda, berikan data preferensi manusia langsung ke AutoSxS, yang akan menghasilkan statistik gabungan keselarasan.
Untuk memeriksa keselarasan dengan set data preferensi manusia, Anda dapat menentukan kedua output (hasil prediksi) ke autorater. Anda juga dapat memberikan hasil inferensi.
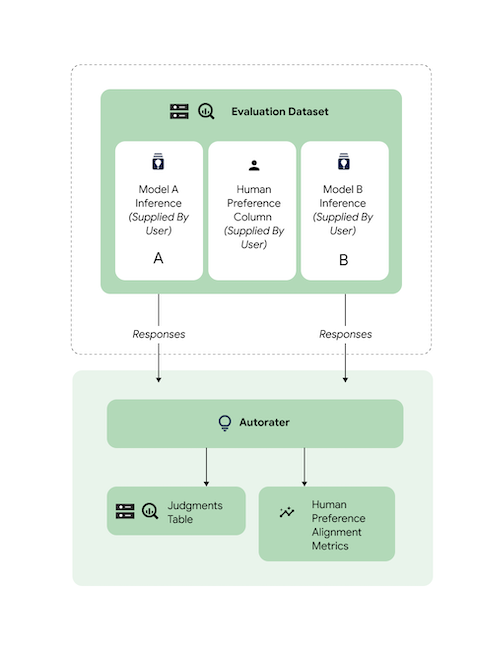
Contoh kode ini memverifikasi bahwa hasil dan penjelasan pemberi rating otomatis sesuai dengan ekspektasi Anda.
# Evaluation dataset schema:
# my_question: str
# my_context: str
# response_a: str
# response_b: str
# actual: str
parameters = {
'evaluation_dataset': DATASET,
'id_columns': ['my_context'],
'task': 'question_answering',
'autorater_prompt_parameters': {
'inference_instruction': {'column': 'my_question'},
'inference_context': {'column': 'my_context'},
},
'response_column_a': 'response_a',
'response_column_b': 'response_b',
'human_preference_column': 'actual',
}
Langkah berikutnya
- Pelajari evaluasi AI generatif.
- Pelajari evaluasi online dengan Layanan Evaluasi AI Generatif.
- Pelajari cara menyesuaikan model dasar bahasa.