O MedLM é uma família de modelos de fundação ajustados para o setor de saúde. O Med-PaLM 2 é um dos modelos baseados em texto desenvolvidos pela Google Research que alimenta o MedLM e foi o primeiro sistema de IA a atingir o nível de especialista humano em respostas a perguntas similares ao Exame de Licenciamento Médico (USMLE) dos EUA. O desenvolvimento desses modelos foi orientado por necessidades específicas dos clientes, como respostas a perguntas médicas e elaboração de resumos.
Card de modelo do MedLM
O card de modelo do MedLM descreve os detalhes do modelo, como o uso pretendido, a visão geral dos dados e as informações de segurança. Clique no link a seguir para fazer o download de uma versão em PDF do card do modelo do MedLM:
Faça o download do card do modelo do MedLM
Casos de uso
- Respostas a perguntas: envie rascunhos de respostas para perguntas sobre saúde, apresentadas em formato de texto.
- Resumir: esboce uma versão mais curta de um documento (como um resumo após a visita ou uma nota de histórico e exame físico) que incorpore informações relevantes do texto original.
Para saber mais sobre como criar comandos de texto, consulte Criar comandos de texto (link em inglês).
Solicitação HTTP
MedLM-medium (medlm-medium):
POST https://us-central1-aiplatform.googleapis.com/v1/projects/{PROJECT_ID}/locations/us-central1/publishers/google/models/medlm-medium:predict
MedLM-large (medlm-large):
POST https://us-central1-aiplatform.googleapis.com/v1/projects/{PROJECT_ID}/locations/us-central1/publishers/google/models/medlm-large:predict
Consulte o método predict para mais informações.
Versões do modelo
O MedLM oferece os seguintes modelos:
- MedLM-medium (
medlm-medium) - MedLM-large (
medlm-large)
A tabela a seguir contém as versões de modelo estável disponíveis:
| modelo medlm-medium | Data da versão |
|---|---|
| medlm-medium | 13 de dezembro de 2023 |
| modelo medlm-large | Data da versão |
|---|---|
| medlm-large | 13 de dezembro de 2023 |
O MedLM-medium e o MedLM-large têm endpoints separados e oferecem aos clientes mais flexibilidade nos casos de uso. O MedLM-medium oferece aos clientes melhores capacidades de processamento e inclui dados mais recentes. O MedLM-large é o mesmo modelo da fase de pré-lançamento. Os dois modelos continuarão a ser atualizados durante o ciclo de vida do produto. Nesta página, "MedLM" se refere aos dois modelos.
Para mais informações, consulte Versões e ciclo de vida do modelo.
Filtros e atributos de segurança do MedLM
O conteúdo processado pela API MedLM é avaliado em relação a uma lista de atributos de segurança, incluindo "categorias prejudiciais" e temas que podem ser considerados sensíveis. Se você vir uma resposta substituta, como "Não posso ajudar com isso, já que sou apenas um modelo de linguagem", isso significa que o comando ou a resposta está acionando um filtro de segurança.
Limites de segurança
Ao usar a Vertex AI Studio, é possível usar
um limite de filtro de segurança ajustável para determinar a probabilidade de
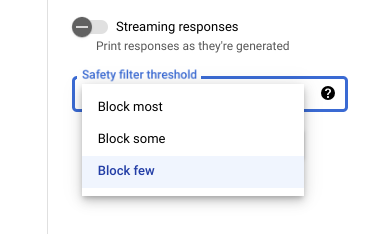
encontrar respostas possivelmente prejudiciais. As respostas do modelo são bloqueadas com base na probabilidade de conterem assédio, discurso de ódio, conteúdo perigoso ou conteúdo sexualmente explícito. A configuração do filtro de segurança está localizada à direita do campo de comando no Vertex AI Studio. É possível escolher entre três opções: block most, block some e block few.
Como testar seus limites de confiança e gravidade
É possível testar os filtros de segurança do Google e definir limites de confiança ideais para sua empresa. Ao usar esses limites, é possível tomar medidas abrangentes para detectar conteúdos que violem as políticas de uso ou os Termos de Serviço do Google e tomar as medidas apropriadas.
As pontuações de confiança são apenas previsões, e você não deve depender da confiabilidade ou precisão delas. O Google não é responsável por interpretar ou usar essas pontuações para decisões de negócios.
Práticas recomendadas
Para utilizar essa tecnologia com segurança e responsabilidade, é importante considerar outros riscos específicos para o caso de uso, usuários e contexto empresarial, além das salvaguardas técnicas integradas.
Recomendamos seguir estas etapas:
- Analise os riscos de segurança do aplicativo.
- Faça ajustes para evitar riscos de segurança.
- Realize testes de segurança de acordo com seu caso de uso.
- Peça o feedback do usuário e monitore os conteúdos.
Para saber mais, consulte as recomendações do Google sobre IA responsável.
Corpo da solicitação
{
"instances": [
{
"content": string
}
],
"parameters": {
"temperature": number,
"maxOutputTokens": integer,
"topK": integer,
"topP": number
}
}
Use os seguintes parâmetros para os modelos medlm-medium e medlm-large.
Para mais informações, consulte Projetar prompts de texto.
| Parâmetro | Descrição | Valores aceitáveis |
|---|---|---|
|
Entrada de texto para gerar uma resposta do modelo. As solicitações podem incluir preâmbulos, perguntas, sugestões, instruções ou exemplos. | Texto |
|
A temperatura é usada para amostragem durante a geração da resposta, que ocorre quando topP e topK são aplicados. A temperatura controla o grau de aleatoriedade na seleção do token.
Temperaturas mais baixas são boas para solicitações que exigem uma resposta menos aberta ou criativa, enquanto temperaturas mais altas podem levar a resultados mais diversos ou criativos. Uma temperatura de 0 significa que os tokens de maior probabilidade são sempre selecionados. Nesse caso, as respostas para uma determinada solicitação são, na maioria das vezes, deterministas, mas uma pequena variação ainda é possível.
Se o modelo retornar uma resposta muito genérica, muito curta ou se o modelo fornecer uma resposta alternativa, tente aumentar a temperatura. |
|
|
Número máximo de tokens que podem ser gerados na resposta. Um token tem cerca de quatro caracteres. 100 tokens correspondem a cerca de 60 a 80 palavras.
Especifique um valor mais baixo para respostas mais curtas e um valor mais alto para respostas potencialmente mais longas. |
|
|
O Top-K muda a forma como o modelo seleciona tokens para saída. Um top-K de
1 significa que o próximo token selecionado é o mais provável entre todos
os tokens no vocabulário do modelo (também chamado de decodificação gananciosa), enquanto um top-K de
3 significa que o próximo token está selecionado entre os três tokens mais
prováveis usando a temperatura.
Para cada etapa da seleção de tokens, são amostrados os tokens top-K com as maiores probabilidades. Em seguida, os tokens são filtrados com base no valor de top-P com o token final selecionado por meio da amostragem de temperatura. Especifique um valor mais baixo para respostas menos aleatórias e um valor mais alto para respostas mais aleatórias. |
|
|
O Top-P muda a forma como o modelo seleciona tokens para saída. Os tokens são selecionados
do mais provável (veja o top-K) para o menos provável até que a soma das probabilidades
seja igual ao valor do top-P. Por exemplo, se os tokens A, B e C tiverem uma probabilidade de 0,3, 0,2 e 0,1 e o valor de top-P for 0.5, o modelo selecionará A ou B como token seguinte usando temperatura e exclui C como
candidato.
Especifique um valor mais baixo para respostas menos aleatórias e um valor mais alto para respostas mais aleatórias. |
|
Exemplo de solicitação
Ao usar a API MedLM, é importante incorporar a engenharia de comando. Por exemplo, recomendamos fornecer instruções apropriadas e específicas da tarefa no início de cada comando. Para mais informações, consulte Introdução à criação de comandos.
REST
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
PROJECT_ID: o ID do projeto.MEDLM_MODEL: o modelo MedLM,medlm-mediumoumedlm-large.
Método HTTP e URL:
POST https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/MEDLM_MODEL:predict
Corpo JSON da solicitação:
{
"instances": [
{
"content": "Question: What causes you to get ringworm?"
}
],
"parameters": {
"temperature": 0,
"maxOutputTokens": 256,
"topK": 40,
"topP": 0.95
}
}
Para enviar a solicitação, escolha uma destas opções:
curl
Salve o corpo da solicitação em um arquivo chamado request.json.
Execute o comando a seguir no terminal para criar ou substituir
esse arquivo no diretório atual:
cat > request.json << 'EOF'
{
"instances": [
{
"content": "Question: What causes you to get ringworm?"
}
],
"parameters": {
"temperature": 0,
"maxOutputTokens": 256,
"topK": 40,
"topP": 0.95
}
}
EOF
Depois execute o comando a seguir para enviar a solicitação REST:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/MEDLM_MODEL:predict"
PowerShell
Salve o corpo da solicitação em um arquivo chamado request.json.
Execute o comando a seguir no terminal para criar ou substituir
esse arquivo no diretório atual:
@'
{
"instances": [
{
"content": "Question: What causes you to get ringworm?"
}
],
"parameters": {
"temperature": 0,
"maxOutputTokens": 256,
"topK": 40,
"topP": 0.95
}
}
'@ | Out-File -FilePath request.json -Encoding utf8
Depois execute o comando a seguir para enviar a solicitação REST:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/MEDLM_MODEL:predict" | Select-Object -Expand Content
Corpo da resposta
{
"predictions": [
{
"content": string,
"citationMetadata": {
"citations": [
{
"startIndex": integer,
"endIndex": integer,
"url": string,
"title": string,
"license": string,
"publicationDate": string
}
]
},
"logprobs": {
"tokenLogProbs": [ float ],
"tokens": [ string ],
"topLogProbs": [ { map<string, float> } ]
},
"safetyAttributes": {
"categories": [ string ],
"blocked": boolean,
"scores": [ float ],
"errors": [ int ]
}
}
],
"metadata": {
"tokenMetadata": {
"input_token_count": {
"total_tokens": integer,
"total_billable_characters": integer
},
"output_token_count": {
"total_tokens": integer,
"total_billable_characters": integer
}
}
}
}
| Elemento de resposta | Descrição |
|---|---|
content |
O resultado gerado a partir do texto de entrada. |
categories |
Os nomes de exibição das categorias de atributo de segurança associadas ao conteúdo gerado. A ordem corresponde às pontuações. |
scores |
As pontuações de confiança de cada categoria, maior valor significa maior confiança. |
blocked |
Uma flag que indica se a entrada ou saída do modelo foi bloqueada. |
errors |
Um código de erro que identifica por que a entrada ou saída foi bloqueada. Veja uma lista de códigos de erro em Filtros e atributos de segurança. |
startIndex |
Índice na saída de previsão em que a citação começa (inclusive). Precisa ser maior ou igual a 0 e menor que end_index. |
endIndex |
Índice na saída da previsão em que a citação termina (exclusiva). Precisa ser maior que start_index e menor que len(output). |
url |
URL associado a essa citação. Se presente, esse URL está vinculado à página da Web da fonte da citação. Os possíveis URLs incluem sites de notícias, repositórios do GitHub e assim por diante. |
title |
Título associado a essa citação. Se presente, refere-se ao título da fonte desta citação. Isso inclui títulos de notícias, de livros e assim por diante. |
license |
Licença associada a esta recitação. Se estiver presente, refere-se à licença da fonte dessa citação. As possíveis licenças incluem licenças de código, como a MIT. |
publicationDate |
Data de publicação associada a esta citação. Se presente, refere-se à data em que a fonte da citação foi publicada. Os formatos possíveis são AAAA, AAAA-MM, AAAA-MM-DD. |
input_token_count |
Número de tokens de entrada. Esse é o número total de tokens em todos os comandos, os prefixos e os sufixos. |
output_token_count |
Número de tokens de saída. Esse é o número total de tokens em content em todas as previsões. |
tokens |
Os tokens de amostra. |
tokenLogProbs |
Probabilidades de registro dos tokens de amostra. |
topLogProb |
Os tokens candidatos mais prováveis e as probabilidades de registro deles em cada etapa. |
logprobs |
Resultados do parâmetro `logprobs`. Mapeamento de 1-1 para "candidatos". |
Exemplo de resposta
{
"predictions": [
{
"citationMetadata": {
"citations": []
},
"content": "\n\nAnswer and Explanation:\nRingworm is a fungal infection of the skin that is caused by a type of fungus called dermatophyte. Dermatophytes can live on the skin, hair, and nails, and they can be spread from person to person through direct contact or through contact with contaminated objects.\n\nRingworm can cause a variety of symptoms, including:\n\n* A red, itchy rash\n* A raised, circular border\n* Blisters or scales\n* Hair loss\n\nRingworm is most commonly treated with antifungal medications, which can be applied to the skin or taken by mouth. In some cases, surgery may be necessary to remove infected hair or nails.",
"safetyAttributes": {
"scores": [
1
],
"blocked": false,
"categories": [
"Health"
]
}
}
],
"metadata": {
"tokenMetadata": {
"outputTokenCount": {
"totalTokens": 140,
"totalBillableCharacters": 508
},
"inputTokenCount": {
"totalTokens": 10,
"totalBillableCharacters": 36
}
}
}
}
Resposta de stream de modelos de IA generativa
Os parâmetros são os mesmos para streaming e solicitações sem streaming para as APIs.
Para conferir exemplos de solicitações de código e respostas usando a API REST, consulte Exemplos usando a API REST.
Para conferir exemplos de solicitações de código e respostas usando o SDK da Vertex AI para Python, consulte Exemplos que usam o SDK da Vertex AI para Python.