Visual Question Answering (VQA) vous permettent de fournir une image au modèle et de poser une question sur son contenu. En réponse à votre question, vous obtenez une ou plusieurs réponses en langage naturel.
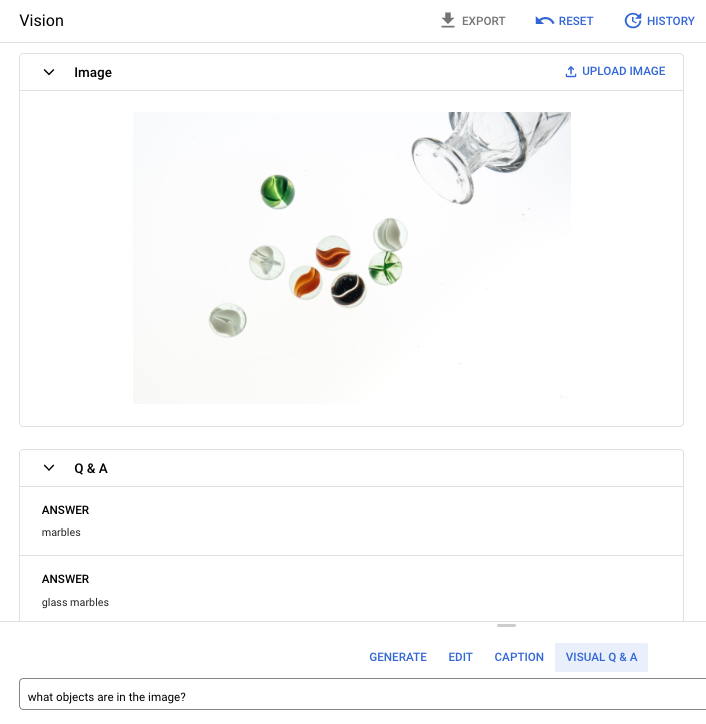
Prompt question: What objects are in the image?
Réponse 1 : marbres
Réponse 2 : marbres en verre
Langages acceptés
VQA est disponible dans les langues suivantes :
- Anglais (en)
Performances et limites
Les limites suivantes s'appliquent lorsque vous utilisez le modèle :
| Limites | Valeur |
|---|---|
| Nombre maximal de requêtes API (version courte) par minute et par projet | 500 |
| Nombre maximal de jetons renvoyés dans la réponse (version courte) | 64 jetons |
| Nombre maximal de jetons acceptés dans la requête (version courte VQA uniquement) | 80 jetons |
Les estimations de latence de service suivantes s'appliquent lorsque vous utilisez ce modèle. Ces valeurs sont fournies à titre indicatif et ne constituent pas une promesse de service :
| Latence | Valeur |
|---|---|
| Requêtes API (version courte) | 1,5 secondes |
Emplacements
Un emplacement est une région que vous pouvez spécifier dans une requête pour contrôler l'emplacement de stockage des données au repos. Pour obtenir la liste des régions disponibles, consultez la section Emplacements AI générative sur Vertex AI.
Filtrage Sécurité de l'IA responsable
Le modèle de fonctionnalité de sous-titrage et de systèmes visuels de questions-réponses d'images (Visual Question Answering, VQA) n'est pas compatible avec les filtres de sécurité configurables par l'utilisateur. Toutefois, le filtrage de sécurité global d'Imagen s'effectue sur les données suivantes :
- Entrée utilisateur
- Sortie du modèle
Par conséquent, votre sortie peut différer de l'exemple de sortie si Imagen applique ces filtres de sécurité. Prenons les exemples suivants.
Entrée filtrée
Si l'entrée est filtrée, la réponse se présente comme suit:
{
"error": {
"code": 400,
"message": "Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394",
"status": "INVALID_ARGUMENT",
"details": [
{
"@type": "type.googleapis.com/google.rpc.DebugInfo",
"detail": "[ORIGINAL ERROR] generic::invalid_argument: Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394 [google.rpc.error_details_ext] { message: \"Media reasoning failed with the following error: The response is blocked, as it may violate our policies. If you believe this is an error, please send feedback to your account team. Error Code: 63429089, 72817394\" }"
}
]
}
}
Résultat filtré
Si le nombre de réponses renvoyées est inférieur au nombre d'échantillons spécifié, cela signifie que les réponses manquantes sont filtrées par l'IA responsable. Par exemple, voici une réponse à une requête comportant "sampleCount": 2, mais pour laquelle l'une des réponses a été filtrée :
{
"predictions": [
"cappuccino"
]
}
Si l'ensemble du résultat est filtré, la réponse est un objet vide semblable à ce qui suit :
{}
Utiliser VQA sur une image (réponses version courte)
Utilisez les exemples suivants pour poser une question et obtenir une réponse sur une image.
REST
Pour en savoir plus sur les requêtes de modèle imagetext, consultez la
documentation de référence de l'API de modèle imagetext.
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
- PROJECT_ID : L'ID de votre projet Google Cloud.
- LOCATION : région de votre projet. Par exemple,
us-central1,europe-west2ouasia-northeast3. Pour obtenir la liste des régions disponibles, consultez la section IA générative sur les emplacements Vertex AI. - VQA_PROMPT : question pour laquelle vous souhaitez obtenir une réponse concernant votre image.
- De quelle couleur est cette chaussure ?
- Quel type de manchots se trouve sur la chemise ?
- B64_IMAGE : image pour laquelle vous souhaitez obtenir une légende. L'image doit être spécifiée en tant que chaîne d'octets encodée en base64. Limite de taille : 10 Mo
- RESPONSE_COUNT : nombre de réponses que vous souhaitez générer. Valeurs entières acceptées : 1-3.
Méthode HTTP et URL :
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict
Corps JSON de la requête :
{
"instances": [
{
"prompt": "VQA_PROMPT",
"image": {
"bytesBase64Encoded": "B64_IMAGE"
}
}
],
"parameters": {
"sampleCount": RESPONSE_COUNT
}
}
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict"
PowerShell
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/imagetext:predict" | Select-Object -Expand Content
"sampleCount": 2 et "prompt": "What is this?". La réponse renvoie deux réponses de chaînes de prédiction.
{
"predictions": [
"cappuccino",
"coffee"
]
}
Python
Avant d'essayer cet exemple, suivez les instructions de configuration pour Python décrites dans le guide de démarrage rapide de Vertex AI à l'aide des bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API Vertex AI Python.
Pour vous authentifier auprès de Vertex AI, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.
Dans cet exemple, la méthode load_from_file vous permet de référencer un fichier local en tant qu'Image de base pour obtenir des informations. Après avoir spécifié l'image de base, vous utilisez la méthode ask_question sur ImageTextModel et imprimez le résultat.
Utiliser des paramètres pour VQA
Lorsque vous obtenez des réponses VQA, vous pouvez définir plusieurs paramètres en fonction de votre cas d'utilisation.
Nombre de résultats
Utilisez le paramètre Nombre de résultats pour limiter la quantité de réponses renvoyées pour chaque requête que vous envoyez. Pour en savoir plus, consultez la documentation de référence de l'API du modèle imagetext (VQA).
Numéro source
Nombre que vous ajoutez à une requête pour rendre les réponses générées déterministes. L'ajout d'un nombre source à votre requête vous permet d'obtenir la même prédiction (réponses) à chaque fois. Cependant, les réponses ne sont pas nécessairement renvoyées dans le même ordre. Pour en savoir plus, consultez la documentation de référence de l'API du modèle imagetext (VQA).
Étape suivante
Consultez des articles sur Imagen et d'autres produits d'IA générative sur Vertex AI :
- Guide du développeur pour commencer à utiliser Imagen 3 sur Vertex AI
- Nouveaux outils et modèles multimédias génératifs, conçus avec et pour les créateurs
- Nouveau dans Gemini : Custom Gems et génération d'images améliorée avec Imagen 3
- Google DeepMind : Imagen 3 – Notre modèle texte-vers-image de la plus haute qualité