안전 속성 신뢰도 및 심각도 점수
Vertex AI PaLM API를 통해 처리된 콘텐츠는 '유해한 카테고리'와 민감하다고 간주될 수 있는 주제가 포함된 안전 속성 목록에 대해 평가됩니다.
각 안전 속성에는 0.0~1.0(소수점 1자리 반올림) 사이의 지정된 신뢰도 점수가 있으며 이 점수로 특정 카테고리에 속하는 입력이나 응답이 발생할 가능성을 나타냅니다.
이러한 4가지 안전 속성(괴롭힘, 증오심 표현, 위험한 콘텐츠, 음란물)에는 안전성 평점(심각도 수준)과 0.0~1.0 사이의 심각도 점수(소수점 한 자리로 반올림)가 할당됩니다. 이러한 평점과 점수는 특정 카테고리에 속하는 콘텐츠의 예측 심각도를 나타냅니다.
샘플 응답
{
"predictions": [
{
"safetyAttributes": {
"categories": [
"Derogatory",
"Toxic",
"Violent",
"Sexual",
"Insult",
"Profanity",
"Death, Harm & Tragedy",
"Firearms & Weapons",
"Public Safety",
"Health",
"Religion & Belief",
"Illicit Drugs",
"War & Conflict",
"Politics",
"Finance",
"Legal"
],
"scores": [
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1
],
"safetyRatings": [
{"category": "Hate Speech", "severity": "NEGLIGIBLE", "severityScore": 0.0,"probabilityScore": 0.1},
{"category": "Dangerous Content", "severity": "LOW", "severityScore": 0.3, "probabilityScore": 0.1},
{"category": "Harassment", "severity": "MEDIUM", "severityScore": 0.6, "probabilityScore": 0.1},
{"category": "Sexually Explicit", "severity": "HIGH", "severityScore": 0.9, "probabilityScore": 0.1}
],
"blocked": false
},
"content": "<>"
}
]
}
참고: 점수가 0.0으로 반올림된 카테고리는 응답에서 생략됩니다. 이 샘플 응답은 설명을 위한 것입니다.
차단 시 샘플 응답
{
"predictions": [
{
"safetyAttributes": {
"blocked": true,
"errors": [
150,
152,
250
]
},
"content": ""
}
]
}
안전 속성 설명
| 안전 속성 | 설명 |
|---|---|
| 혐오 | ID 또는 보호 속성을 대상으로 하는 부정적이거나 유해한 댓글 |
| 유해 | 무례하거나 모욕적이거나 욕설이 있는 콘텐츠 |
| 성적 | 성행위 또는 기타 외설적인 콘텐츠에 대한 참조가 포함 |
| 폭력적 | 개인 또는 그룹에 대한 폭력을 묘사하는 시나리오 또는 유혈 콘텐츠에 대한 일반적인 설명을 묘사 |
| 모욕 | 한 사람 또는 여러 그룹에 대한 욕설, 분노 또는 부정적인 댓글 |
| 욕설 | 저주와 같은 외설적이거나 저속한 언어 |
| 사망, 피해 및 참사 | 인간의 죽음, 참사, 사고, 재해, 자해 |
| 총기 및 무기 | 칼, 총, 개인 무기, 액세서리(예: 탄약, 권총집)를 언급하는 콘텐츠 |
| 공공 안전 | 구제책을 제공하고 공공 안전을 보장하는 서비스 및 조직 |
| 상태 | 건강 상태, 즉 질병, 장애를 포함한 인간 건강 의학 치료, 약물, 백신 접종, 의료 관행 지원 그룹을 포함한 치료용 리소스 |
| 종교 및 신앙 | 초자연 법칙 및 존재 가능성을 다루는 신념 체계 즉, 종교, 신앙, 신념, 영적 수행, 교회, 예배 장소. 점성학 및 오컬트 포함 |
| 불법 약물 | 유흥 및 불법 약물: 마약 용품 및 재배, 마약 상점 등. 일반적으로 기분 전환용으로 사용되는 약물(예: 마리화나)의 의학적 사용은 포함됩니다. |
| 전쟁 및 분쟁 | 전쟁, 군사적 충돌, 많은 사람들이 관련된 중대한 물리적 충돌. 전쟁이나 분쟁과 직접적인 관련이 없더라도 군 복무에 대한 논의는 포함됩니다. |
| 금융 | 은행, 대출, 신용, 투자, 보험 등 소비자 및 비즈니스 금융 서비스 |
| 정치 | 정치 뉴스 및 미디어, 사회, 정부, 공공 정책에 대한 토론 |
| 법무 | 법률 회사, 법률 정보, 주요 법률 자료, 준법 서비스, 법적 간행물 및 기술, 전문가 증인, 소송 컨설턴트, 기타 법률 서비스 제공업체를 포함한 법률 관련 콘텐츠 |
안전 평점이 포함된 안전 속성
| 안전 속성 | 정의 | 수준 |
|---|---|---|
| 증오심 표현 | ID 또는 보호 속성을 대상으로 하는 부정적이거나 유해한 댓글 | 높음, 보통, 낮음, 무시할 수 있음 |
| 괴롭힘 | 다른 사람을 대상으로 위협하거나 괴롭히거나 모욕하는 악성 댓글 | 높음, 보통, 낮음, 무시할 수 있음 |
| 음란물 | 성행위 또는 기타 외설적인 콘텐츠에 대한 참조가 포함 | 높음, 보통, 낮음, 무시할 수 있음 |
| 위험한 콘텐츠 | 유해한 상품, 서비스, 활동 홍보 및 이에 대한 액세스 지원 | 높음, 보통, 낮음, 무시할 수 있음 |
안전 기준
다음과 같은 안전 속성에 안전 기준이 적용됩니다.
- 증오심 표현
- 괴롭힘
- 음란물
- 위험한 콘텐츠
Google은 이러한 안전 속성에 지정된 심각도 점수를 초과하는 모델 응답을 차단합니다. 안전 기준을 수정하는 기능을 요청하려면 Google Cloud 계정팀에 문의하세요.
신뢰도 및 심각도 기준 테스트
Google의 안전 필터를 테스트하고 비즈니스에 맞는 신뢰도 기준을 정의할 수 있습니다. 이러한 기준을 사용하면 Google의 사용 정책 또는 서비스 약관을 위반하는 콘텐츠를 감지하고 적절한 조치를 취할 수 있습니다.
신뢰도 점수는 예측일 뿐이므로 신뢰성 또는 정확성 점수를 의존해서는 안 됩니다. Google은 비즈니스 결정을 위해 이러한 점수를 해석하거나 사용할 책임이 없습니다.
중요: 확률 및 심각도
안전 평점이 있는 안전 속성 4개를 제외하고 PaLM API 안전 필터 신뢰도 점수는 콘텐츠의 심각도가 아닌 안전하지 않을 확률을 기준으로 합니다. 일부 콘텐츠는 심각도의 유해성이 높더라도 안전하지 않을 가능성이 낮을 수 있으므로 이를 고려하는 것이 중요합니다. 예를 들어 다음 문장을 비교해보겠습니다.
- 로봇이 나를 때렸습니다.
- 로봇이 나를 베었습니다.
문장 1은 안전하지 않을 가능성이 더 높을 수 있지만 폭력 측면에서는 문장 2가 더 심각하다고 생각할 수 있습니다.
따라서 최종 사용자에게 해를 주지 않으면서 주요 사용 사례를 지원하는 데 필요한 적절한 수준의 차단이 무엇인지 신중하게 고려하고 테스트해야 합니다.
안전 오류
안전 오류 코드는 프롬프트나 응답이 차단된 이유를 나타내는 3자리 코드입니다. 1번째 자릿수는 코드가 프롬프트나 응답에 적용되는지 여부를 나타내는 프리픽스이며 나머지 자릿수는 프롬프트나 응답이 차단된 이유를 식별합니다.
예를 들어 251 오류 코드는 모델의 응답에 증오감 표현 콘텐츠 문제로 인해 응답이 차단되었음을 나타냅니다.
단일 응답에서 여러 오류 코드가 반환될 수 있습니다.
모델의 응답 콘텐츠를 차단하는 오류가 발생하면(프리픽스 = 2(예: 250)) 요청에서 temperature 설정을 조정합니다. 이렇게 하면 차단 가능성이 줄어드는 다양한 응답 집합을 생성할 수 있습니다.
오류 코드 프리픽스
오류 코드 프리픽스는 오류 코드의 1번째 자릿수입니다.
| 1 | 모델로 전송된 프롬프트에 오류 코드가 적용됩니다. |
| 2 | 오류 코드는 모델의 응답에 적용됩니다. |
오류 코드 이유
오류 코드 이유는 오류 코드의 2번째 및 3번째 자릿수입니다.
3 또는 4로 시작하는 오류 코드 이유는 안전 속성 위반의 신뢰도 기준이 충족되었기 때문에 차단된 프롬프트나 응답을 나타냅니다.
5로 시작하는 오류 코드 이유는 안전하지 않은 콘텐츠가 발견된 프롬프트나 응답을 나타냅니다.
| 10 | 품질 문제 또는 인용 메타데이터에 영향을 주는 매개변수 설정으로 인해 응답이 차단되었습니다. 이는 모델의 응답에만 적용됩니다. 즉, 인용 검사기는 매개변수 설정에서 발생하는 품질 문제 또는 기타 문제를 식별합니다. 다른 응답을 생성하려면 자세한 내용은 인용 메타데이터를 참조하세요. |
| 20 | 제공되거나 반환된 언어는 지원되지 않습니다. 지원되는 언어 목록은 언어 지원을 참조하세요. |
| 30 | 프롬프트나 응답에서 유해 가능성이 확인되어 차단되었습니다. 용어는 용어 차단 목록에 포함되어 있습니다. 프롬프트를 변경합니다. |
| 31 | 콘텐츠에는 민감한 개인 식별 정보(SPII)가 포함될 수 있습니다. 프롬프트를 변경합니다. |
| 40 | 프롬프트나 응답에서 유해 가능성이 확인되어 차단되었습니다. 콘텐츠가 세이프서치 설정을 위반합니다. 프롬프트를 변경합니다. |
| 50 | 프롬프트나 응답에 음란물이 포함되어 있을 수 있으므로 차단되었습니다. 프롬프트를 변경합니다. |
| 51 | 프롬프트나 응답에 증오감 표현 콘텐츠가 포함되어 있을 수 있으므로 차단되었습니다. 프롬프트를 변경합니다. |
| 52 | 프롬프트나 응답에 괴롭힘 콘텐츠가 포함되어 있을 수 있으므로 차단되었습니다. 프롬프트를 변경합니다. |
| 53 | 프롬프트나 응답에 위험한 콘텐츠가 포함되었을 수 있으므로 차단되었습니다. 프롬프트를 변경합니다. |
| 54 | 프롬프트나 응답에 유해한 콘텐츠가 포함되었을 수 있으므로 차단되었습니다. 프롬프트를 변경합니다. |
| 00 | 이유를 알 수 없습니다. 프롬프트를 변경합니다. |
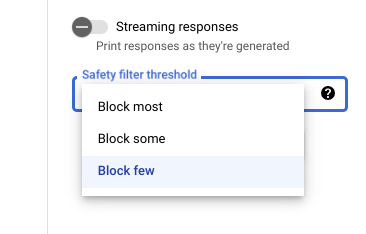
Vertex AI Studio의 안전 설정
조정 가능한 안전 필터 기준을 사용하면 유해할 수 있는 응답이 표시될 가능성을 조정할 수 있습니다. 모델 응답은 괴롭힘, 증오심 표현, 위험한 콘텐츠 또는 음란물을 포함할 확률에 따라 차단됩니다. 안전 필터 설정은 Vertex AI Studio의 프롬프트 필드 오른쪽에 있습니다. block most, block some, block few 등 3가지 옵션 중에서 선택할 수 있습니다.