Cette page explique comment utiliser un serveur Zipkin pour recevoir des traces de clients Zipkin et les transférer vers Cloud Trace pour analyse.
Vous pouvez utiliser un serveur Zipkin si votre application est instrumentée avec Zipkin et que vous ne souhaitez pas exécuter votre propre backend de trace ou souhaitez accéder aux outils d'analyse avancée de Cloud Trace.
Cette page décrit plusieurs façons de configurer votre serveur Zipkin :
- Utiliser une image de conteneur
- Exécution en dehors de Google Cloud
- Modifier un serveur Zipkin existant
Utiliser une image de conteneur pour configurer un serveur
Une image de conteneur du collecteur Cloud Trace Zipkin est disponible sur GitHub. Ce dépôt contient la définition de compilation Docker, ainsi que les couches compatibles avec Google Cloud Google Cloud sur l'image Docker Zipkin de base, en plus des étapes de configuration détaillées.
Vous pouvez exécuter cette image sur l'hôte de conteneur de votre choix, y compris sur Google Kubernetes Engine.
Pour exécuter l'image :
$ docker run -d -p 9411:9411 \
-e STORAGE_TYPE=stackdriver \
-e GOOGLE_APPLICATION_CREDENTIALS=/root/.gcp/credentials.json \
-e STACKDRIVER_PROJECT_ID=your_project \
-v $HOME/.gcp:/root/.gcp:ro \
openzipkin/zipkin-gcp
Si vous exécutez ce conteneur dans Google Cloud, par exemple sur une instance Compute Engine ou un cluster Google Kubernetes Engine, les identifiants par défaut de l'environnement sont automatiquement capturés et les traces sont automatiquement envoyées à Cloud Trace.
Pour le processus de configuration complet, accédez au dépôt GitHub pour l'image Docker Zipkin.
Comme décrit sur cette page, vous devez également configurer vos traceurs Zipkin.
Exécuter votre serveur en dehors de Google Cloud
Si vous souhaitez créer et exécuter le collecteur en dehors de Google Cloud, par exemple sur un serveur physique exécuté sur site, procédez comme suit:
Créer ou sélectionner un projet
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Un compte de facturation n'est pas nécessaire, car le collecteur n'est pas exécuté surGoogle Cloud.
Créer un compte de service
Pour autoriser votre service à s'authentifier auprès de l'API Cloud Trace :
- Créez un compte de service.
- Assurez-vous que le nouveau compte de service a reçu le rôle d'éditeur de projet, afin qu'il puisse écrire des données dans l'API Trace.
- Sélectionnez Indiquer une nouvelle clé privée et choisissez JSON.
- Enregistrez le fichier d'identifiants JSON dans un répertoire de l'ordinateur qui exécutera le service de collecte.
Configurer le pare-feu
Définissez la configuration réseau pour permettre au trafic TCP de transiter par la machine qui exécute le collecteur Zipkin, sur le port 9411.
Si vos applications sont hébergées en dehors du pare-feu, notez que le trafic du traceur Zipkin vers le collecteur n'est pas chiffré ou authentifié. Les connexions entre le collecteur Cloud Trace Zipkin et l'API Cloud Trace sont chiffrées et authentifiées, tout comme les connexions provenant des bibliothèques d'instrumentation Cloud Trace.
Configurer le serveur avec l'image du conteneur
Pour en savoir plus, consultez la section Utiliser une image de conteneur.
Configurer les traceurs Zipkin
Suivez les instructions de la section commune Configurer les traceurs Zipkin sur cette page.
Modifier un serveur Zipkin existant
Le projet Zipkin contient des instructions expliquant comment utiliser Cloud Trace en tant que destination de stockage pour un serveur Zipkin existant. Ces instructions sont disponibles dans le dépôt GitHub pour l'image Docker Zipkin.
Procédure de configuration des traceurs Zipkin
Quelle que soit la manière dont vous hébergez le collecteur Cloud Trace Zipkin, vous devez configurer vos traceurs Zipkin pour lui envoyer des données.
Pour référencer le collecteur, utilisez son adresse IP interne, son adresse IP externe (s'il reçoit des traces d'applications hébergées en dehors deGoogle Cloud) ou son nom d'hôte. Chaque traceur Zipkin est configuré différemment. Par exemple, pour orienter un traceur Brave vers un collecteur dont l'adresse IP est 1.2.3.4, vous devez ajouter les lignes suivantes au code Java :
Reporter reporter = AsyncReporter.builder(OkHttpSender.create("1.2.3.4:9411/api/v1/spans")).build();
Brave brave = Brave.Builder("example").reporter(reporter).build()
Questions fréquentes
Q : Quelles sont les limites ?
Deux limites connues s'appliquent à cette version :
Les traceurs Zipkin doivent être compatibles avec la sémantique appropriée de durée et d'heure de Zipkin. Pour en savoir plus, accédez à la section Instrumenting a library (Configurer une bibliothèque) et faites défiler l'écran jusqu'à la section Timestamps and duration (Horodatages et durée).
Les traceurs Zipkin et les bibliothèques d'instrumentation Cloud Trace ne peuvent pas ajouter de délais aux mêmes traces, car ils utilisent différents formats pour propager le contexte de trace entre les services. Par conséquent, les traces capturées par une bibliothèque ne contiennent pas de délais pour les services instrumentés par l'autre bibliothèque.
Pour cette raison, si vous souhaitez utiliser Cloud Trace pour vos projets, nous vous recommandons d'utiliser, de manière exclusive, soit des traceurs compatibles avec Zipkin, ainsi que le collecteur Zipkin, soit des bibliothèques d'instrumentation qui fonctionnent avec Cloud Trace. Pour en savoir plus sur les bibliothèques Cloud Trace, consultez les pages Node.js, Java et Go.
Exemple :
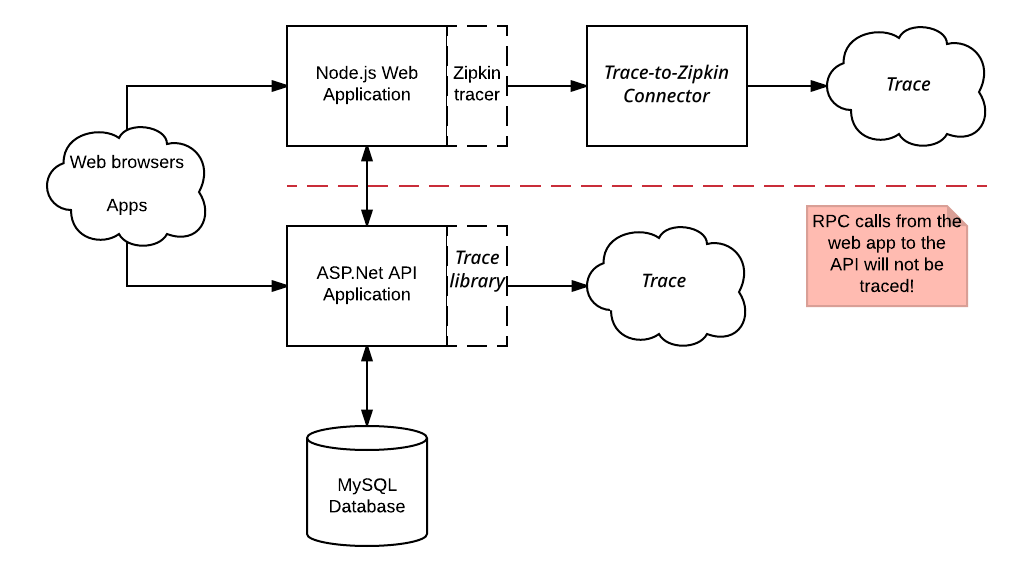
Les requêtes adressées à l'application Web Node.js sont tracées avec la bibliothèque Zipkin et envoyées à Cloud Trace. Toutefois, ces traces ne contiennent pas de délais générés par l'application API ASP.NET. Les traces capturées par la bibliothèque Zipkin ne contiennent pas non plus de délais pour les appels RPC que l'application API APS.NET effectue vers sa base de données MySQL.
Q : Ce fonctionnement correspond-il à un serveur Zipkin complet ?
Non, cette fonctionnalité écrit uniquement des données dans Cloud Trace.