Questa pagina descrive come utilizzare un server Zipkin per ricevere le tracce dai client Zipkin e inoltrarle a Cloud Trace per l'analisi.
Ti consigliamo di utilizzare un server Zipkin se la tua applicazione è instrumentata con Zipkin e non vuoi eseguire il tuo backend di traccia o vuoi accedere agli strumenti di analisi avanzati di Cloud Trace.
Questa pagina descrive diversi modi per configurare il server Zipkin:
- Utilizzare un'immagine container
- Esecuzione al di fuori di Google Cloud
- Modificare un server Zipkin esistente
Utilizzo di un'immagine del contenitore per configurare il server
Su GitHub è disponibile un'immagine del contenitore dell'agente di raccolta Zipkin di Cloud Trace. Questo repository contiene la definizione della build Docker e applica il supporto di Google Cloud all'immagine Docker Zipkin di base, oltre ai passaggi di configurazione dettagliati.
Puoi eseguire questa immagine sull'host container che preferisci, incluso Google Kubernetes Engine.
Per eseguire l'immagine:
$ docker run -d -p 9411:9411 \
-e STORAGE_TYPE=stackdriver \
-e GOOGLE_APPLICATION_CREDENTIALS=/root/.gcp/credentials.json \
-e STACKDRIVER_PROJECT_ID=your_project \
-v $HOME/.gcp:/root/.gcp:ro \
openzipkin/zipkin-gcp
Se esegui questo contenitore in Google Cloud, ad esempio su un'istanza Compute Engine o un cluster Google Kubernetes Engine, le credenziali predefinite dell'ambiente vengono acquisite automaticamente e le tracce vengono inviate automaticamente a Cloud Trace.
Per la procedura di configurazione completa, vai al repository GitHub dell'immagine Docker di Zipkin.
Come descritto in questa pagina, devi anche configurare i tracer Zipkin.
Eseguire il server all'esterno di Google Cloud
Se vuoi creare ed eseguire il raccoglitore all'esterno di Google Cloud, ad esempio su un server fisico on-premise, completa i seguenti passaggi:
Crea o seleziona un progetto
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Non è richiesto un account di fatturazione perché il raccoglitore non è in esecuzione su Google Cloud.
Crea un account di servizio
Per consentire al tuo servizio di autenticarsi nell'Cloud Trace API:
- Crea un account di servizio.
- Assicurati che al nuovo account di servizio sia stato conferito il ruolo di editor del progetto in modo che possa scrivere dati nell'API Trace.
- Seleziona Fornisci una nuova chiave privata e scegli JSON.
- Salva il file delle credenziali JSON in una directory del computer su cui verrà eseguito il servizio di raccolta.
Configura il firewall
Configura la configurazione di rete in modo da consentire il passaggio del traffico TCP sulla porta 9411 alla macchina su cui è in esecuzione il collector Zipkin.
Se le tue applicazioni sono ospitate al di fuori del firewall, tieni presente che il traffico dal tracer a Zipkin al collector non è criptato o autenticato. Le connessioni tra il collector Zipkin di Cloud Trace e l'Cloud Trace API sono criptate e autenticate, così come le connessioni provenienti dalle librerie di strumenti di Cloud Trace.
Configura il server con l'immagine del contenitore
Per ulteriori informazioni, consulta Utilizzare un'immagine contenitore.
Configurare i tracer di Zipkin
Segui le istruzioni nella sezione comune Configura i tracer Zipkin di questa pagina.
Modificare un server Zipkin esistente
Il progetto Zipkin fornisce istruzioni su come utilizzare Cloud Trace come destinazione di archiviazione per un server Zipkin esistente. Queste istruzioni sono disponibili nel repository GitHub dell'immagine Docker di Zipkin.
Come configurare i tracer di Zipkin
Indipendentemente da come ospiti l'agente di raccolta Zipkin di Cloud Trace, devi configurare gli utility di traccia Zipkin in modo che inviino dati all'agente.
Per fare riferimento al raccoglitore, utilizza il relativo indirizzo IP interno, indirizzo IP esterno (se riceve tracce da applicazioni ospitate al di fuori di Google Cloud) o nome host. Ogni tracer Zipkin è configurato in modo diverso. Ad esempio, per indirizzare un tracer Brave a un collector con indirizzo IP 1.2.3.4, le seguenti righe devono essere aggiunte al codice di base Java:
Reporter reporter = AsyncReporter.builder(OkHttpSender.create("1.2.3.4:9411/api/v1/spans")).build();
Brave brave = Brave.Builder("example").reporter(reporter).build()
Domande frequenti
D: Quali sono i limiti?
Questa release presenta due limitazioni note:
I tracer di Zipkin devono supportare la semantica corretta di tempo e durata di Zipkin. Per saperne di più, vai a Strumentazione di una libreria e scorri verso il basso fino alla sezione su Timestamp e durata.
I tracer Zipkin e le librerie di strumenti Cloud Trace non possono aggiungere span alle stesse tracce perché utilizzano formati diversi per la propagazione del contesto della traccia tra i servizi. Il risultato è che le tracce acquisite da una libreria non contengono intervalli per i servizi strumentati dall'altra libreria.
Per questo motivo, consigliamo ai progetti che vogliono utilizzare Cloud Trace di utilizzare esclusivamente tracer compatibili con Zipkin insieme a Zipkin Collector o di utilizzare librerie di strumenti compatibili con Cloud Trace. Per ulteriori informazioni sulle librerie Cloud Trace, consulta Node.js, Java e Go.
Ad esempio:
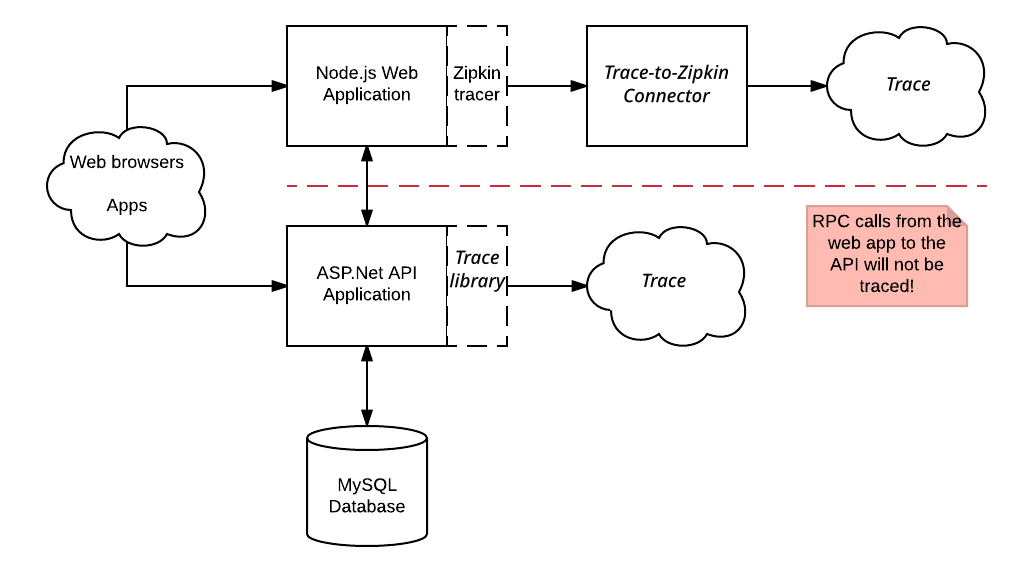
Le richieste inviate all'applicazione web Node.js vengono tracciate con la libreria Zipkin e inviate a Cloud Trace. Tuttavia, queste tracce non contengono gli intervalli generati dall'applicazione API ASP.NET. Inoltre, le tracce acquisite dalla libreria Zipkin non contengono gli span per le chiamate RPC effettuate dall'applicazione API APS.NET al proprio database MySQL.
D: Funziona come un server Zipkin completo?
No, questa funzionalità scrive i dati solo in Cloud Trace.