Auf dieser Seite wird beschrieben, wie Sie mit einem Zipkin-Server Traces von Zipkin-Clients empfangen und zur Analyse an Cloud Trace weiterleiten.
Sie können einen Zipkin-Server verwenden, wenn Ihre Anwendung mit Zipkin ausgestattet ist und Sie entweder kein eigenes Trace-Back-End ausführen oder auf die erweiterten Analysetools von Cloud Trace zugreifen möchten.
Auf dieser Seite werden mehrere Möglichkeiten zum Einrichten eines Zipkin-Servers beschrieben:
Server mit einem Container-Image einrichten
Auf GitHub ist ein Container-Image von Cloud Zipkin Collector verfügbar. Dieses Repository enthält neben detaillierten Einrichtungsschritten die Definition des Docker-Builds und die Google Cloud -Unterstützung für das Basis-Docker-Image von Zipkin.
Sie können dieses Image auf einem Container-Host Ihrer Wahl ausführen, einschließlich Google Kubernetes Engine.
So führen Sie das Image aus:
$ docker run -d -p 9411:9411 \
-e STORAGE_TYPE=stackdriver \
-e GOOGLE_APPLICATION_CREDENTIALS=/root/.gcp/credentials.json \
-e STACKDRIVER_PROJECT_ID=your_project \
-v $HOME/.gcp:/root/.gcp:ro \
openzipkin/zipkin-gcp
Wenn Sie diesen Container in der Google Cloudausführen, z. B. auf einer Compute Engine-Instanz oder einem Google Kubernetes Engine-Cluster, werden die Standardanmeldedaten der Umgebung automatisch erfasst und Traces automatisch an Cloud Trace gesendet.
Die vollständige Einrichtung finden Sie im GitHub-Repository für das Zipkin-Docker-Image.
Wie auf dieser Seite beschrieben, müssen Sie auch Ihre Zipkin-Tracer konfigurieren.
Server außerhalb von Google Cloudausführen
Wenn Sie den Collector außerhalb von Google Clouderstellen und ausführen möchten, z. B. auf einem physischen Server, der lokal ausgeführt wird, führen Sie die folgenden Schritte aus:
Projekt erstellen oder auswählen
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Ein Rechnungskonto ist nicht erforderlich, da der Collector nicht aufGoogle Cloudausgeführt wird.
Dienstkonto erstellen
So ermöglichen Sie Ihrem Dienst die Authentifizierung bei der Cloud Trace API:
- Erstellen Sie ein Dienstkonto.
- Weisen Sie dem neuen Dienstkonto eine Projektbearbeiterrolle zu, damit es Daten in die Trace API schreiben kann.
- Wählen Sie Neuen privaten Schlüssel bereitstellen und "JSON" aus.
- Speichern Sie die Datei mit den JSON-Anmeldedaten in einem Verzeichnis auf dem Computer, auf dem der Collector-Dienst ausgeführt wird.
Firewall konfigurieren
Gestalten Sie Ihre Netzwerkkonfiguration so, dass der gesamte TCP-Traffic über den Port 9411 an den Computer weitergeleitet wird, auf dem der Zipkin-Collector ausgeführt wird.
Wenn Ihre Anwendungen außerhalb der Firewall gehostet werden, ist der Traffic zwischen Zipkin Tracer und Collector nicht verschlüsselt oder authentifiziert. Verbindungen zwischen dem Cloud Trace Zipkin-Collector und der Cloud Trace API werden ebenso wie Verbindungen von den Cloud Trace-Instrumentierungsbibliotheken verschlüsselt und authentifiziert.
Server mit Container-Image einrichten
Weitere Informationen finden Sie unter Container-Image verwenden.
Zipkin Tracer konfigurieren
Folgen Sie der Anleitung im allgemeinen Abschnitt Zipkin Tracer konfigurieren auf dieser Seite.
Vorhandenen Zipkin-Server ändern
Das Zipkin-Projekt enthält Anleitungen zur Verwendung von Cloud Trace als Speicherziel für einen vorhandenen Zipkin-Server. Diese Anleitung finden Sie im GitHub-Repository für das Zipkin-Docker-Image.
Zipkin-Tracer konfigurieren
Unabhängig davon, wie Sie den Cloud Trace Zipkin-Collector hosten, müssen Sie Ihre Zipkin-Tracer so konfigurieren, dass Daten an sie gesendet werden.
Um auf den Collector zu verweisen, verwenden Sie dessen interne IP-Adresse, die externe IP-Adresse (wenn er Traces von außerhalb vonGoogle Cloudgehosteten Anwendungen erhält) oder den Hostnamen. Jeder Zipkin-Tracer ist anders konfiguriert. Beispielsweise müssen die folgenden Zeilen in Ihre Java-Codebasis eingefügt werden, um einen Brave-Tracer auf einen Collector mit der IP-Adresse 1.2.3.4 zu verweisen:
Reporter reporter = AsyncReporter.builder(OkHttpSender.create("1.2.3.4:9411/api/v1/spans")).build();
Brave brave = Brave.Builder("example").reporter(reporter).build()
Häufig gestellte Fragen
F: Was sind die Einschränkungen?
Dieser Release enthält zwei bekannte Einschränkungen:
Zipkin-Tracer müssen die korrekte Zipkin-Semantik für Zeit und Dauer unterstützen. Weitere Informationen dazu finden Sie unter Eine Bibliothek instrumentieren im Abschnitt Zeitstempel und Dauer.
Zipkin-Tracer und die Cloud Trace-Instrumentierungsbibliotheken können keine Spans an dieselben Traces anhängen, da sie unterschiedliche Formate zum Weiterleiten des Trace-Kontexts zwischen Diensten verwenden. Das hat zur Folge, dass Traces, die von einer Bibliothek erfasst werden, keine Spans für Dienste enthalten, die von der anderen Bibliothek instrumentiert werden.
Daher empfehlen wir Projekte, die Cloud Trace ausschließlich verwenden möchten, entweder Zipkin-kompatible Tracer zusammen mit dem Zipkin-Collector oder Instrumentierungsbibliotheken, die mit Cloud Trace funktionieren. Weitere Informationen zu den Cloud Trace-Bibliotheken finden Sie unter Node.js, Java und Go.
Beispiel:
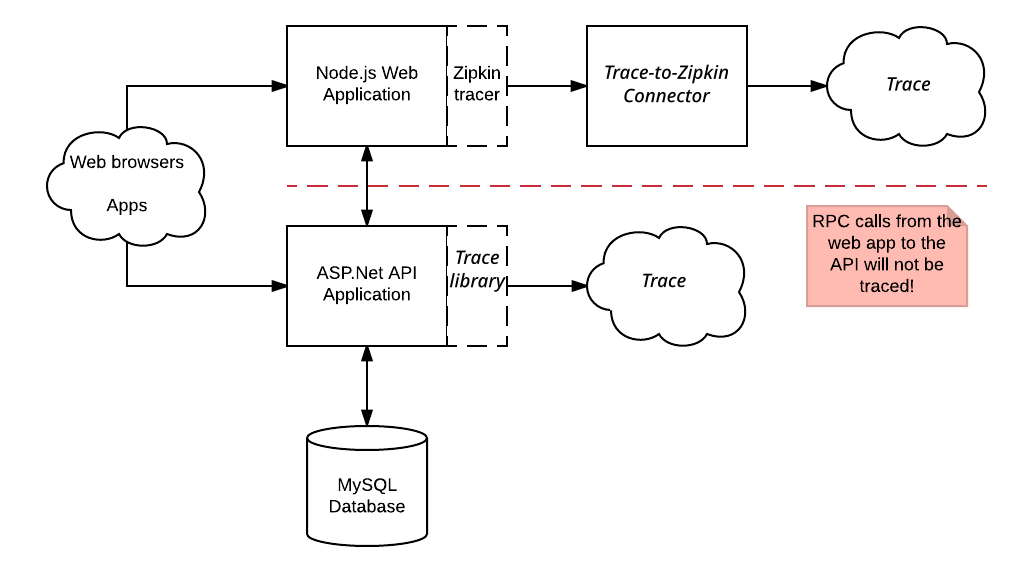
Anfragen an die Webanwendung Node.js werden mit der Zipkin-Bibliothek verfolgt und an Cloud Trace gesendet. Diese Traces enthalten jedoch keine Spans, die von der ASP.NET API-Anwendung generiert wurden. Die von der Zipkin-Bibliothek erfassten Traces enthalten auch keine Spans für die RPC-Aufrufe, die die APS.NET API-Anwendung an ihre MySQL-Datenbank vornimmt.
F: Kann dies als vollständiger Zipkin-Server eingesetzt werden?
Nein, diese Funktion schreibt nur Daten in Cloud Trace.