本页面从概念上简要介绍了如何使用 Cloud Trace 导出跟踪记录数据。由于以下原因,您可能需要导出跟踪记录数据:
- 为了将跟踪记录数据存储比默认保留期限(30 天)更长的时段。
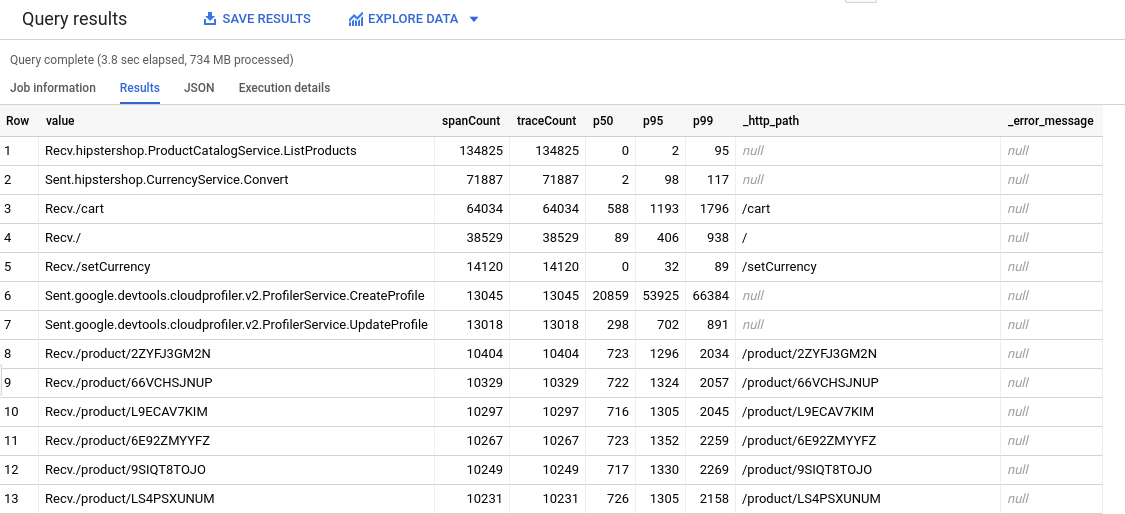
为了让您能够使用 BigQuery 工具分析跟踪记录数据。例如,使用 BigQuery 时,您可以识别 span 计数和分位数。如需了解用于生成下表的查询,请参阅 HipsterShop 查询。
导出的工作原理
导出操作包括为 Google Cloud 项目创建接收器。接收器将 BigQuery 数据集定义为目标。
您可以使用 Cloud Trace API 或 Google Cloud CLI 创建接收器。
接收器属性和术语
接收器是为 Google Cloud 项目定义的,具有以下属性:
名称:接收器的名称。例如,名称可以是:
"projects/PROJECT_NUMBER/traceSinks/my-sink"
其中,
PROJECT_NUMBER是接收器的 Google Cloud 项目编号,my-sink是接收器标识符。父级:您在其中创建接收器的资源。父级必须是 Google Cloud 项目:
"projects/PROJECT_ID"
PROJECT_ID可以是 Google Cloud 项目标识符或编号。目标位置:表示要将跟踪记录 span 发送到哪个位置。Trace 支持将跟踪记录导出到 BigQuery。目标位置可以是接收器的 Google Cloud 项目或同一组织中的任何其他 Google Cloud 项目。
例如,有效目标为:
bigquery.googleapis.com/projects/DESTINATION_PROJECT_NUMBER/datasets/DATASET_ID
其中
DESTINATION_PROJECT_NUMBER是目标的Google Cloud 项目编号,DATASET_ID是 BigQuery 数据集标识符。写入者身份:服务账号名称。导出目标位置的所有者必须为此服务账号授予对导出目标位置的写入权限。导出跟踪记录时,Trace 会使用此身份进行授权。为了提高安全性,新接收器将获得唯一的服务账号:
export-PROJECT_NUMBER-GENERATED_VALUE@gcp-sa-cloud-trace.iam.gserviceaccount.com
其中
PROJECT_NUMBER是您的 Google Cloud 项目编号(采用十六进制格式),GENERATED_VALUE是随机生成的值。您不会创建、拥有或管理由接收器的写入者身份标识的服务账号。创建接收器时,Trace 会创建接收器所需的服务账号。此服务账号至少具有一个 Identity and Access Management 绑定后,才会包含在项目的服务账号列表中。您可以在配置接收器目标位置时添加此绑定。
如需了解如何使用写入者身份,请参阅目标位置权限。
接收器的工作原理
每当跟踪记录 span 到达项目时,Trace 就会导出该 span 的副本。
无法导出在创建接收器之前 Trace 接收的跟踪记录。
访问权限控制
如要创建或修改接收器,您必须具有以下 Identity and Access Management 角色之一:
- Trace Admin
- Trace User
- Project Owner
- Project Editor
如需了解详情,请参阅访问权限控制。
如需将跟踪记录导出到目标位置,接收器的写入者服务账号必须具备对目标位置的写入权限。如需详细了解写入者身份,请参阅本页中的接收器属性。
配额和限制
Cloud Trace 利用 BigQuery 流处理 API 将跟踪记录 span 发送到目标位置。Cloud Trace 会对 API 调用进行批处理。Cloud Trace 不会实现重试或限制机制。如果数据量超出目标配额,则跟踪记录 span 可能无法成功导出。
如需详细了解 BigQuery 配额和限制,请参阅配额和限制。
价格
导出跟踪记录不会产生 Cloud Trace 费用。但是,您可能会产生 BigQuery 费用。如需了解详情,请参阅 BigQuery 价格。
估算费用
BigQuery 会针对数据提取和存储收取费用。如需估算每月 BigQuery 费用,请执行以下操作:
估算一个月中提取的跟踪记录 span 的总数。
如需了解如何查看用量,请参阅按结算账号查看用量。
根据提取的跟踪记录 span 数估算流式传输要求。
每个 span 都将写入表中的相应行。BigQuery 中的每一行都至少需要 1024 个字节。因此,BigQuery 流式传输要求的下限是为每个 span 分配 1024 个字节。例如,如果您的 Google Cloud项目提取了 200 个 span,则这些 span 至少需要 20,400 个字节才能进行流式插入。
使用价格计算器估算因存储、流式插入和查询而产生的 BigQuery 费用。
查看和管理您的 BigQuery 使用情况
您可以使用 Metrics Explorer 查看 BigQuery 使用量。您还可以创建提醒政策,以便在 BigQuery 使用量超出预定义限制时收到通知。下表包含创建提醒政策所需的设置。您可以在创建图表或使用 Metrics Explorer 时使用目标窗格表中的设置。
如需创建一项提醒政策,并在注入的 BigQuery 指标超出用户定义的级别时触发,请使用以下设置。
| 新建条件 字段 |
值 |
|---|---|
| 资源和指标 | 在资源菜单中,选择 BigQuery 数据集。 在指标类别菜单中,选择存储空间。 从指标菜单中选择一个指标。特定于使用量的指标包括 Stored bytes、Uploaded bytes 和 Uploaded bytes billed。如需可用指标的完整列表,请参阅 BigQuery 指标。 |
| 过滤 | project_id:您的 Google Cloud 项目 ID。 dataset_id:您的数据集 ID。 |
| 跨时间序列 时间序列分组依据 |
dataset_id:您的数据集 ID |
| 跨时间序列 时间序列聚合 |
sum |
| 滚动窗口 | 1 m |
| 滚动窗口函数 | mean |
| 配置提醒触发器 字段 |
值 |
|---|---|
| 条件类型 | Threshold |
| 提醒触发器 | Any time series violates |
| 阈值位置 | Above threshold |
| 阈值 | 可接受的值由您决定。 |
| 重新测试窗口 | 1 minute |
后续步骤
如需配置接收器,请参阅导出跟踪记录。