TPU v6e
Ce document décrit l'architecture et les configurations compatibles de Cloud TPU v6e (Trillium).
Trillium est la dernière génération d'accélérateurs d'IA Cloud TPU. Sur toutes les surfaces techniques, telles que l'API et les journaux, et tout au long de ce document, Trillium sera désigné par le terme "v6e".
Avec une empreinte de 256 puces par pod, v6e présente de nombreuses similitudes avec v5e. Ce système est optimisé pour être le produit le plus performant pour l'entraînement, l'affinage et la mise en service des transformateurs, des conversions de texte en image et des réseaux de neurones convolutifs (CNN).
Architecture du système
Chaque puce v6e contient un TensorCore. Chaque TensorCore comporte deux unités de multiplication matricielle (MXU), une unité vectorielle et une unité scalaire. Le tableau suivant présente les principales spécifications et leurs valeurs pour les TPU v6e par rapport aux TPU v5e.
| Spécification | v5e | v6e |
|---|---|---|
| Performances/coût total de possession (TCO) (attendu) | x 0,65 | 1 |
| Puissance de calcul maximale par puce (bf16) | 197 TFLOPS | 918 TFLOPS |
| Puissance de calcul maximale par puce (Int8) | 393 TOPS | 1 836 TOPS |
| Capacité de mémoire HBM par puce | 16 Go | 32 Go |
| Bande passante HBM par puce | 800 Gbit/s | 1 600 Gbit/s |
| Bande passante d'interconnexion entre puces (ICI) | 1 600 Gbit/s | 3 200 Gbit/s |
| Ports ICI par puce | 4 | 4 |
| DRAM par hôte | 512 Gio | 1 536 Gio |
| Puces par hôte | 8 | 8 |
| Taille du pod TPU | 256 puces | 256 puces |
| Topologie d'interconnexion | Tore 2D | Tore 2D |
| Puissance de calcul maximale BF16 par pod | 50,63 PFLOPS | 234,9 PFLOPS |
| Bande passante All-Reduce par pod | 51,2 To/s | 102,4 To/s |
| Bande passante bissectionnelle par pod | 1,6 To/s | 3,2 To/s |
| Configuration des cartes d'interface réseau par hôte | 2 cartes d'interface réseau 100 Gbit/s | 4 cartes d'interface réseau 200 Gbit/s |
| Bande passante réseau de centre de données par pod | 6,4 Tbit/s | 25,6 Tbit/s |
| Fonctionnalités spéciales | - | SparseCore |
Configurations compatibles
Le tableau suivant présente les formes de tranche 2D compatibles avec v6e :
| Topologie | Puces TPU | Hôtes | VM | Type d'accélérateur (API TPU) | Type de machine (API GKE) | Champ d'application |
|---|---|---|---|---|---|---|
| 1x1 | 1 | 1/8 | 1 | v6e-1 |
ct6e-standard-1t |
Sous-hôte |
| 2x2 | 4 | 1/2 | 1 | v6e-4 |
ct6e-standard-4t |
Sous-hôte |
| 2x4 | 8 | 1 | 1 | v6e-8 |
ct6e-standard-8t |
Hôte unique |
| 2x4 | 8 | 1 | 2 | - | ct6e-standard-4t |
Hôte unique |
| 4x4 | 16 | 2 | 4 | v6e-16 |
ct6e-standard-4t |
Multi-hôtes |
| 4x8 | 32 | 4 | 8 | v6e-32 |
ct6e-standard-4t |
Multi-hôtes |
| 8x8 | 64 | 8 | 16 | v6e-64 |
ct6e-standard-4t |
Multi-hôtes |
| 8x16 | 128 | 16 | 32 | v6e-128 |
ct6e-standard-4t |
Multi-hôtes |
| 16x16 | 256 | 32 | 64 | v6e-256 |
ct6e-standard-4t |
Multi-hôtes |
Les tranches avec huit puces (v6e-8) associées à une seule VM sont optimisées pour l'inférence, ce qui permet d'utiliser les huit puces dans une même charge de travail de diffusion. Vous pouvez effectuer une inférence multi-hôtes à l'aide de Pathways on Cloud. Pour en savoir plus, consultez Effectuer une inférence multihôte à l'aide de Pathways.
Pour en savoir plus sur le nombre de VM pour chaque topologie, consultez Types de VM.
Types de VM
Chaque VM TPU v6e peut contenir une, quatre ou huit puces. Les tranches de quatre puces ou moins ont le même nœud NUMA (Non-Uniform Memory Access). Pour en savoir plus sur les nœuds NUMA, consultez Non-uniform memory access sur Wikipédia.
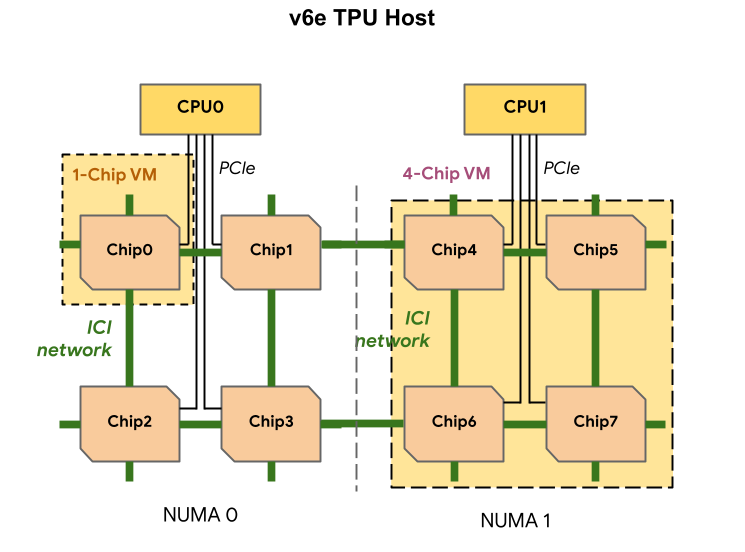
Les tranches v6e sont créées à l'aide de VM à demi-hôte, chacune avec quatre puces TPU. Il existe deux exceptions à cette règle :
v6e-1: VM avec une seule puce, principalement destinée aux testsv6e-8: VM à hôte complet optimisée pour un cas d'utilisation d'inférence avec l'intégralité des huit puces associées à une seule VM.
Le tableau suivant présente une comparaison des types de VM TPU v6e :
| Type de VM | Nombre de processeurs virtuels par VM | RAM (Go) par VM | Nombre de nœuds NUMA par VM |
|---|---|---|---|
| VM à une seule puce | 44 | 176 | 1 |
| VM à quatre puces | 180 | 720 | 1 |
| VM à huit puces | 180 | 1440 | 2 |
Spécifier la configuration v6e
Lorsque vous allouez une tranche TPU v6e à l'aide de l'API TPU, vous spécifiez sa taille et sa forme à l'aide du paramètre AcceleratorType.
Si vous utilisez GKE, utilisez le flag --machine-type pour spécifier un type de machine compatible avec le TPU que vous souhaitez utiliser. Pour en savoir plus, consultez Planifier des TPU dans GKE dans la documentation GKE.
Utiliser AcceleratorType
Lorsque vous allouez des ressources TPU, vous utilisez AcceleratorType pour spécifier le nombre de TensorCores dans une tranche. La valeur que vous spécifiez pour AcceleratorType est une chaîne au format v$VERSION-$TENSORCORE_COUNT.
Par exemple, v6e-8 spécifie une tranche TPU v6e avec huit TensorCores.
L'exemple suivant montre comment créer une tranche TPU v6e avec 32 TensorCores à l'aide de AcceleratorType :
gcloud
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=zone \ --accelerator-type=v6e-32 \ --version=v2-alpha-tpuv6e
Console
Dans la console Google Cloud , accédez à la page TPU :
Cliquez sur Créer un TPU.
Dans le champ Nom, saisissez un nom pour votre TPU.
Dans le champ Zone, sélectionnez la zone dans laquelle vous souhaitez créer le TPU.
Dans le champ Type de TPU, sélectionnez
v6e-32.Dans le champ Version logicielle du TPU, sélectionnez
v2-alpha-tpuv6e. Lorsque vous créez une VM Cloud TPU, la version logicielle du TPU spécifie la version de l'environnement d'exécution TPU à installer. Pour en savoir plus, consultez Images de VM TPU.Cliquez sur le bouton Activer la mise en file d'attente.
Dans le champ Nom de la ressource mise en file d'attente, saisissez un nom pour votre demande de ressource mise en file d'attente.
Cliquez sur Créer.