TPU 유형 및 토폴로지
TPU 구성
TPU를 만들 때는 TPU 구성을 지정해야 합니다. TensorCore 또는 TPU 칩을 기준으로 TPU 구성을 지정할 수 있습니다. 칩을 기준으로 한 TPU 구성 지정은 대규모 모델을 학습시키고 성능을 조정하는 고급 시나리오에서만 필요합니다.
TensorCore 기반 구성
v2 - v4 TPU에서 TensorCore 기반 구성을 사용할 수 있습니다. TensorCore 기반 구성을 TPU 버전과 사용하려는 TensorCore의 개수로 설명합니다. 예를 들어 v4-128은 v4 TPU 및 128개의 TensorCore로 구성을 지정합니다. gcloud compute tpus tpu-vm create 명령어의 --accelerator-type 플래그를 사용하여 TensorCore 기반 구성을 지정합니다.
$ gcloud compute tpus tpu-vm create tpu-name --zone=zone --accelerator-type=v3-128 --version=tpu-vm-tf-2.12.0
칩 기반 TPU 구성
v4 TPU 이상 TPU 버전으로 TPU 칩 기반 구성을 사용할 수 있습니다.
TPU 버전 및 토폴로지(TPU 칩의 물리적 배열)를 사용하여 칩 기반 구성을 설명합니다. TPU 버전을 'v4'와 같은 문자열로 지정합니다. 칩이 3차원에서 배열되는 방식을 설명하는 3튜플로 토폴로지를 지정합니다. gcloud compute tpus tpu-vm create 명령어의 --version 및 --topology 플래그로 칩 기반 구성을 지정합니다. 예를 들어 다음 명령어는 TPU v4를 TPU 버전으로 지정하고 2x2x4(16개의 칩, 각 TensorCore 2개)를 토폴로지로 지정합니다.
$ gcloud compute tpus tpu-vm create tpu-name --zone=zone --type=v4 --topology=2x2x4 --version=tpu-vm-tf-2.12.0
다양한 Cloud TPU 버전 및 토폴로지에 대한 자세한 내용은 시스템 아키텍처에서 확인할 수 있습니다.
v4 토폴로지의 표현은 AxBxC이며, 여기서 A<=B<=C이고 A, B, C는 모두 <=4이거나 4의 모든 정수 배수입니다. A, B, C 값은 각각 3차원의 칩 수입니다. 2A=B=C 또는 2A=2B=C인 토폴로지에는 전체 통신에 최적화된 변이(예: 4×4×8, 8×8×16, 12×12×24)도 있습니다.
v4 토폴로지에 대한 자세한 내용은 TPU v4 구성을 참조하세요.
토폴로지 변이
지정된 칩 수와 연결된 기본 토폴로지는 큐브와 가장 유사한 토폴로지입니다(토폴로지 형태 참조). 이 형태는 데이터 병렬 ML 학습에 가장 적합할 수 있습니다. 다른 토폴로지는 여러 종류의 동시 로드가 있는 워크로드(예: 모델 및 데이터 동시 로드 또는 시뮬레이션의 공간 분할)에 유용할 수 있습니다. 이러한 워크로드는 토폴로지가 사용된 동시 로드와 일치할 때 최고의 성능을 발휘합니다. 예를 들어 X 차원에 4방향 모델 동시 로드를 배치하고 Y 및 Z차원에 256방향 데이터 동시 로드를 배치하면 4x16x16 토폴로지와 일치합니다.
여러 차원의 동시 로드가 있는 모델은 TPU 토폴로지 차원에 매핑된 동시 로드 차원에서 가장 잘 작동합니다. 일반적으로 데이터+모델 병렬 대규모 언어 모델(LLM)이 여기에 해당합니다. 예를 들어 토폴로지 8x16x16이 있는 TPU v4 포드 슬라이스의 경우 토폴로지 차원은 8, 16, 16입니다. 8방향 또는 16방향 모델 동시 로드(물리적 토폴로지 차원 중 하나에 매핑)를 사용하면 성능이 더 개선됩니다. 4방향 모델 동시 로드는 TPU 토폴로지 차원에 맞게 정렬되지 않으므로 이 토폴로지의 차선입니다. 칩 수가 동일한 4x16x32 토폴로지를 사용하는 것이 최적의 방법입니다.
작은 v4 토폴로지
Cloud TPU는 64개 칩이 있는 4x4x4 큐브보다 작은 다음 TPU v4 슬라이스를 지원합니다. 다음과 같은 TensorCore 기반 이름(예: v4-32) 또는 토폴로지(예: 2x2x4)를 사용하여 이러한 작은 v4 토폴로지를 만들 수 있습니다.
| 이름(TensorCore 수 기반) | 칩 수 | 토폴로지 |
| v4-8 | 4 | 2x2x1 |
| v4-16 | 8 | 2x2x2 |
| v4-32 | 16 | 2x2x4 |
| v4-64 | 32 | 2x4x4 |
큰 v4 토폴로지
TPU v4 슬라이스는 64개의 칩 단위로 제공되며, 세 차원 모두에서 4의 배수인 형태를 띱니다. 차원도 오름차순이어야 합니다. 다음 표에 몇 가지 예시가 나와 있습니다. 이러한 토폴로지 중 일부는 토폴로지 API를 통해서만 실행할 수 있는 '커스텀' 토폴로지입니다. 일반적으로 사용되는 토폴로지와 칩 수가 동일하기 때문입니다.
| 이름(TensorCore 수 기반) | 칩 수 | 토폴로지 |
| v4-128 | 64 | 4x4x4 |
| v4-256 | 128 | 4x4x8 |
| v4-512 | 256 | 4x8x8 |
| 토폴로지 API 보기 | 256 | 4x4x16 |
| v4-1024 | 512 | 8x8x8 |
| v4-1536 | 768 | 8x8x12 |
| v4-2048 | 1024 | 8x8x16 |
| 토폴로지 API 보기 | 1024 | 4x16x16 |
| v4-4096 | 2048 | 8x16x16 |
| … | … | … |
토폴로지 API
커스텀 토폴로지로 Cloud TPU Pod 슬라이스를 만들려면 다음과 같이 gcloud TPU API를 사용하면 됩니다.
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=us-central2-b \ --subnetwork=tpusubnet \ --type=v4 \ --topology=4x4x16 \ --version=runtime-version
토폴로지 형태
다음 이미지는 가능한 3가지 토폴로지 형태와 관련 topology 플래그 설정을 보여줍니다.
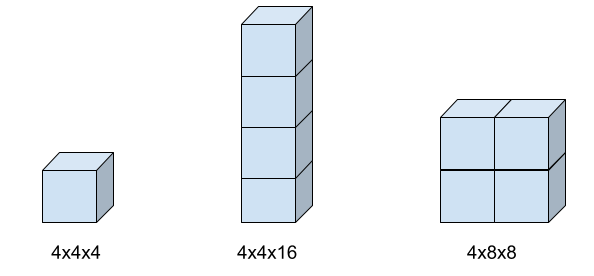
TPU 유형 호환성
TPU 유형을 TensorCore 또는 칩 수가 동일한 다른 TPU 유형(예: v3-128 및 v4-128)으로 변경하고 코드 변경 없이 학습 스크립트를 실행할 수 있습니다.
하지만 칩 또는 TensorCore 수가 더 많거나 적은 TPU 유형으로 변경하는 경우 상당한 조정과 최적화 수행이 필요합니다.
자세한 내용은 TPU Pod에서 학습을 참조하세요.