监控 Cloud TPU 节点
。本指南介绍了如何使用 Google Cloud Monitoring 监控 Cloud TPU 节点。 Google Cloud Monitoring 会自动从 Cloud TPU 及其主机 Compute Engine 收集指标和日志。这些数据可用于监控 Cloud TPU 和 Compute Engine 的运行状况。
借助指标,您可以跟踪一段时间内的数值量,例如 CPU 利用率、网络使用情况或 MXU 利用率。日志可捕获特定时间点的事件。日志条目由您自己的代码、 Google Cloud 服务、第三方应用和 Google Cloud 基础架构编写。您还可以通过创建基于日志的指标,根据日志条目中的数据生成指标。您还可以根据指标值或日志条目设置提醒政策。
本指南介绍了 Google Cloud 监控功能,并向您展示了如何执行以下操作:
- 查看 Cloud TPU 指标
- 设置 Cloud TPU 指标提醒政策
- 查询 Cloud TPU 日志
- 创建基于日志的指标,用于设置提醒和直观显示信息中心。
前提条件
本文假定您对 Google Cloud Monitoring 有一些基本了解。您必须先创建 Compute Engine 虚拟机和 Cloud TPU 资源,才能开始生成和使用 Google Cloud Monitoring。如需了解详情,请参阅 Cloud TPU 快速入门。
指标
Google Cloud 指标由 Compute Engine 虚拟机和 Cloud TPU 运行时自动生成。Cloud TPU 节点会生成以下指标:
cpu/utilizationmemory/usagenetwork/received_bytes_countnetwork/sent_bytes_counttpu/mxu/utilizationtpu/tensorcore/idle_duration
CPU 利用率
cpu/utilization 指标用于跟踪 Cloud TPU 工作器的当前 CPU 利用率(以百分比表示)。值通常介于 0.0 到 100.0 之间,但可能会超过 100.0。每 60 秒采样一次。从生成值到显示值可能需要最多 180 秒。
内存使用量
memory/usage 指标以字节为单位跟踪 Cloud TPU VM 当前使用的内存。系统每 60 秒对此指标进行一次采样。从生成值到显示值可能需要最多 180 秒。
网络接收的字节数
network/received_bytes_count 指标用于跟踪 Cloud TPU VM 在某个时间点通过网络接收的数据的累计字节数。从生成值到显示值可能需要最多 180 秒。
网络发送的字节数
network/sent_bytes_count 指标用于跟踪 Cloud TPU VM 在某个时间点通过网络发送的累计字节数。从生成值到显示值可能需要最多 180 秒。
TensorCore 空闲时长
tpu/tensorcore/idle_duration 指标用于跟踪每个 TPU 芯片的 TensorCore 处于空闲状态的秒数。此指标适用于所有正在使用的 TPU 上的每个芯片。如果 TensorCore 正在使用中,空闲时长值会重置为零。当 TensorCore 不再使用时,空闲时长值会开始增加。
下图显示了具有一个工作器的 v2-8 Cloud TPU VM 的 tpu/tensorcore/idle_duration 指标。每个工作器有四个芯片。在此示例中,所有四个条状标签的 tpu/tensorcore/idle_duration 值相同,因此图表会相互叠加。
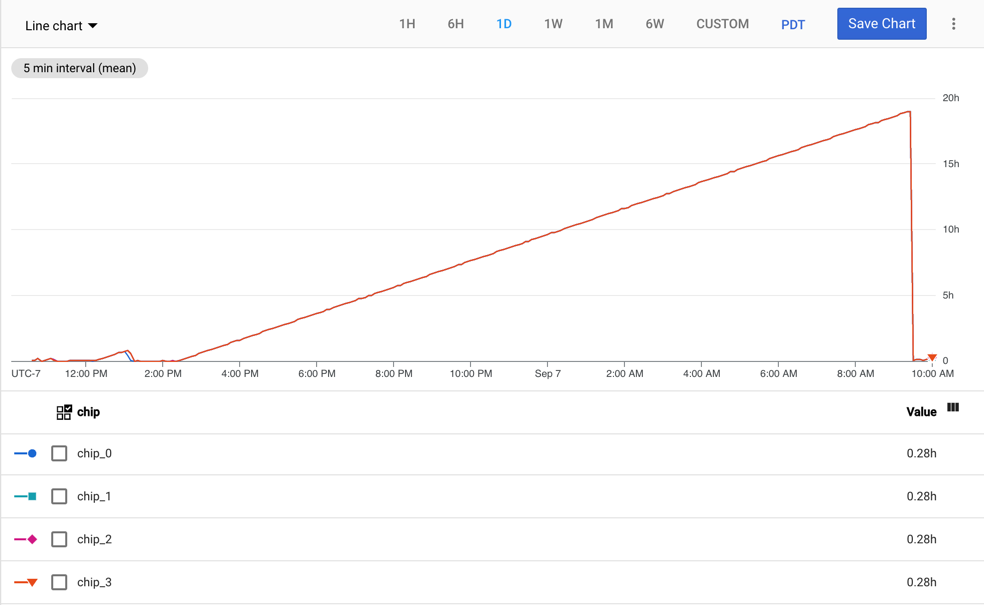
MXU 利用率
tpu/mxu/utilization 指标用于跟踪 TPU 工作器的当前 MXU 利用率(以百分比表示)。值通常是介于 0.0 到 100.0 之间的数字。每 60 秒采样一次。采样后,数据在最长 180 秒的时间内不会显示。
如需查看 Cloud TPU 生成的指标的完整列表,请参阅 Cloud TPU 指标。
查看指标
您可以使用 Google Cloud 控制台中的 Metrics Explorer 查看指标。
在 Metrics Explorer 中,点击选择指标,然后搜索 Cloud TPU Worker。如果仅显示活跃的资源和指标处于开启状态,则系统只会显示当前正在生成的指标。点击 Cloud TPU Worker 以显示可用指标。
您还可以使用 curl HTTP 调用访问指标:
使用 projects.timeSeries.query 文档中的 Try it! 按钮,即可检索指定时间范围内指标的值。
- 请按照以下格式填写名称:projects/{project-name}
- 在请求正文部分中添加查询。以下是用于检索指定区域过去 5 分钟内的空闲时长指标的查询示例
fetch tpu_worker | filter zone = 'us-central2-b' | metric tpu.googleapis.com/tpu/tensorcore/idle_duration | within 5m" - 点击执行以检索 HTTP POST 消息的结果
如需详细了解如何自定义此查询,请参阅 Monitoring Query Language 参考文档。
您可以创建提醒政策,指示 Google Cloud Monitoring 在满足某个条件时发送提醒。
创建提醒
本部分中的步骤显示了如何为 TensorCore Idle Duration 指标添加提醒政策的示例。每当此指标超过 24 小时时,Cloud Monitoring 都会向注册的电子邮件地址发送电子邮件。
- 前往 Monitoring 控制台
- 在导航窗格中,点击提醒
- 点击修改通知渠道
- 在电子邮件下,点击添加新地址
- 输入电子邮件地址和显示名称,然后点击保存
- 点击创建政策
- 点击选择指标,选择 Tensorcore 空闲时长,然后点击应用
- 点击下一步,然后点击阈值
- 对于提醒触发器,选择任何违反时序的情况
- 在阈值位置部分,选择高于阈值
- 在阈值部分,输入
86400000 - 点击下一步
- 在通知渠道下,选择您的电子邮件通知渠道,然后点击确定
- 输入提醒政策的名称
- 依次点击下一步和创建政策
当 TensorCore 空闲时长超过 24 小时时,系统会向您指定的电子邮件地址发送电子邮件。
日志记录
日志条目由 Google Cloud 服务、第三方服务、机器学习框架或您的代码编写。您可以使用日志查看器或 Logs API 查看日志。如需详细了解 Google Cloud 日志记录,请参阅 Google Cloud Logging。
在日志浏览器中,您可以选择资源类型:
- Cloud TPU Worker -> 可用区 -> 节点 ID
- 受审核资源 -> Cloud TPU -> API (
google.cloud.tpu.v1.Tpu.CreateNode、google.cloud.tpu.v1.Tpu.DeleteNode、google.cloud.tpu.v1.Tpu.UpdateNode)
Cloud TPU 工作器日志包含特定区域中特定 Cloud TPU 工作器的相关信息,例如 Cloud TPU 工作器 (system_available_memory_GiB) 上可用的内存量。
经过审核的资源日志包含有关特定 Cloud TPU API 的调用时间和调用者的信息。例如 CreateNode、UpdateNode 和 DeleteNode。
机器学习框架可以将日志生成到 stdout 和 stderr。这些日志由环境变量控制,并由训练脚本读取。
您的代码可以将日志写入 Google Cloud Logging。如需了解详情,请参阅写入标准日志和写入结构化日志。
查看 Cloud TPU 日志
- 前往 Google Cloud 日志查看器
- 点击资源下拉菜单
- 点击 Cloud TPU 工作器
- 选择区域
- 选择您感兴趣的 Cloud TPU
- 点击应用。日志会显示在查询结果中
如需查看“已审核的资源”日志,请执行以下操作:
- 前往 Google Cloud 日志查看器
- 点击资源下拉菜单
- 依次点击已审核的资源和 Cloud TPU
- 选择您感兴趣的 Cloud TPU API
- 点击应用。日志会显示在查询结果中
- 选择以
google.cloud.tpu.v1.Tpu开头的 API
查询 Google Cloud 日志
当您在 Google Cloud 控制台中查看日志时,该页面会执行默认查询。您可以通过选择 Show query 切换开关来查看查询。您可以修改默认查询或创建新的查询。如需了解详情,请参阅在日志浏览器中构建查询。
了解“已审核的资源”日志的日志输出
点击任意日志条目将其展开,您都将会看到名为 protoPayload 的字段。
展开 protoPayload,您会看到多个子字段:
- logName:日志的名称
- protoPayload -> @type:日志的类型
- resourceName:Cloud TPU 的名称
- methodName:所调用方法的名称(仅限审核日志)
- request -> @type:请求类型
- 请求 -> 节点:Cloud TPU 节点的详细信息
- request -> node_id:TPU 的名称
- severity:日志的严重级别
了解 Cloud TPU Worker 日志的日志输出
点击任意日志条目将其展开,您都将会看到名为 jsonPayload 的字段。
展开 jsonPayload,您会看到多个子字段:
- accelerator_type:加速器类型
- consumer_project:Cloud TPU 所在的项目
- evententry_timestamp:日志生成的时间
- system_available_memory_GiB:Cloud TPU 工作器上的可用内存(0~350 GB)
创建基于日志的指标
本部分介绍如何创建用于设置监控信息中心和提醒的基于日志的指标。如需了解如何以编程方式创建基于日志的指标,请参阅使用 Cloud Logging REST API 以编程方式创建基于日志的指标。
以下示例使用 system_available_memory_GiB 子字段来演示如何创建用于监控 Cloud TPU 工作器可用内存的基于日志的指标。
- 前往 Logs Explorer
在查询框中,输入以下查询以提取为主要 Cloud TPU 工作器定义了 system_available_memory_GiB 的所有日志条目:
resource.type=tpu_worker resource.labels.project_id=your-project resource.labels.zone=your-tpu-zone resource.labels.node_id=your-tpu-name resource.labels.worker_id=0 logName=projects/your-project/logs/tpu.googleapis.com%2Fruntime_monitor jsonPayload.system_available_memory_GiB:*
点击创建指标以显示指标编辑器
在指标类型下,选择分布
为指标输入名称、可选说明和衡量单位。在名称和说明字段中分别输入“matrix_unit_utilization_percent”和“MXU utilization”
过滤条件中会预先填充您在 Logs Explorer 中输入的脚本
点击创建指标
点击探索指标可查看新指标。您的指标可能需要几分钟才能显示
使用 Cloud Logging REST API 以编程方式创建基于日志的指标
您还可以通过 Cloud Logging API 创建基于日志的指标。如需了解详情,请参阅创建分布指标。
使用基于日志的指标创建信息中心和提醒
信息中心有助于直观显示指标(预计会延迟大约 2 分钟);提醒有助于您在出现错误时收到通知。如需了解详情,请参阅管理自定义信息中心和创建基于指标的提醒政策。
创建信息中心
如需在 Cloud Monitoring 中为 Tensorcore 空闲时长指标创建信息中心,请执行以下操作:
- 前往 Monitoring 控制台
- 在导航窗格中,点击信息中心
- 依次点击创建信息中心和添加图表
- 选择要添加的图表类型。在此示例中,选择线条
- 为信息中心输入标题
- 点击资源和指标下方的按钮
- 向下滚动资源/指标列表,然后依次选择 Cloud TPU Worker -> Tpu -> Tensorcore 空闲时长
- 点击应用
- 如需过滤信息中心内容,请点击创建信息中心过滤条件
- 在标签字段中,将 project_id 设置为您的项目
- 点击添加,然后将可用区设置为您创建 TPU 时所在的可用区
- 为 node_id 添加另一个过滤条件,并指定您的 Cloud TPU 名称