Arquitectura de las TPU
Las unidades de procesamiento tensorial (TPU) son circuitos integrados específicos de aplicaciones (ASIC) diseñados por Google para acelerar las cargas de trabajo de aprendizaje automático. Cloud TPU es un servicio Google Cloud que pone las TPU a disposición como un recurso escalable.
Las TPU están diseñadas para realizar operaciones de matrices rápidamente, lo que las hace ideales para las cargas de trabajo de aprendizaje automático. Puedes ejecutar cargas de trabajo de aprendizaje automático en las TPU con frameworks como PyTorch y JAX.
¿Cómo funcionan las TPU?
Para comprender cómo funcionan las TPU, es útil saber cómo otros aceleradores abordan los desafíos computacionales del entrenamiento de modelos de AA.
Cómo funciona una CPU
La CPU es un procesador de propósito general basado en la arquitectura de von Neumann. Eso significa que una CPU funciona con software y memoria, de la siguiente manera:
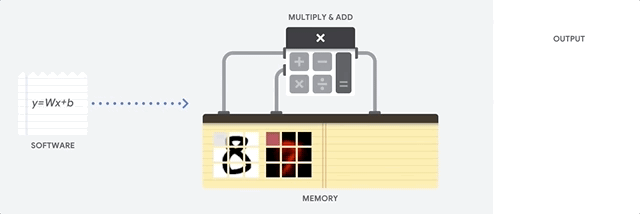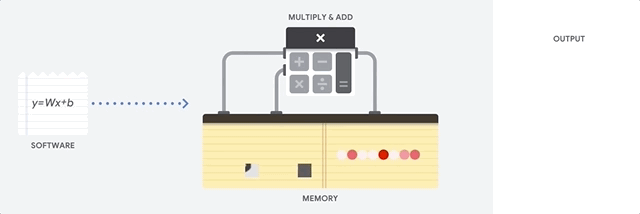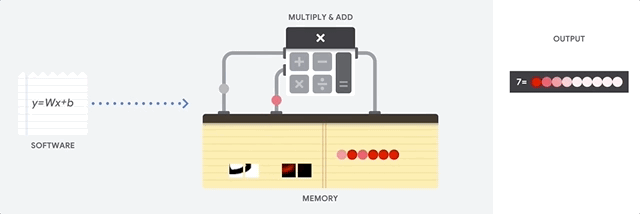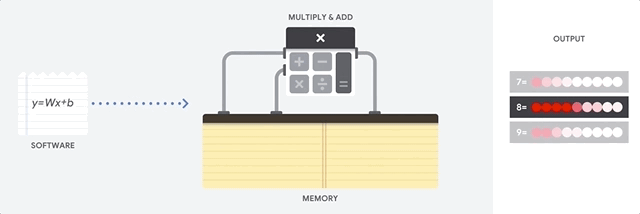
La mayor ventaja de las CPU es su flexibilidad. Puedes cargar cualquier tipo de software en una CPU para muchos tipos diferentes de aplicaciones. Por ejemplo, puedes usar una CPU para procesar textos en una PC, controlar motores de cohetes, ejecutar transacciones bancarias o clasificar imágenes con una red neuronal.
Una CPU carga valores de la memoria, realiza un cálculo sobre los valores y almacena el resultado en la memoria para cada cálculo. El acceso a la memoria es lento en comparación con la velocidad de cálculo y puede limitar el rendimiento total de las CPU. Esto se conoce a menudo como el cuello de botella de von Neumann.
Cómo funciona una GPU
Para aumentar la capacidad de procesamiento, las GPUs contienen miles de unidades aritméticas y lógicas (ALU) en un solo procesador. Una GPU moderna suele contener entre 2,500 y 5,000 ALU. La gran cantidad de procesadores permite ejecutar miles de multiplicaciones y sumas de manera simultánea.

Esta arquitectura de GPU funciona bien en aplicaciones con paralelismo masivo, como las operaciones de matrices en una red neuronal. De hecho, en una carga de trabajo de entrenamiento típica para el aprendizaje profundo, una GPU puede proporcionar un pedido de capacidad de procesamiento de magnitud mayor que una CPU.
Sin embargo, la GPU sigue siendo un procesador de propósito general que tiene que prestar servicio a muchas aplicaciones y software diferentes. Por lo tanto, las GPU presentan el mismo problema que las CPU. Para cada cálculo en los miles de ALU, una GPU debe acceder a los registros o a la memoria compartida para leer los operandos y almacenar los resultados del cálculo intermedio.
Cómo funciona una TPU
Google diseñó Cloud TPU como un procesador matricial especializado para cargas de trabajo de redes neuronales. Las TPU no pueden ejecutar procesadores de texto, controlar motores de cohetes ni ejecutar transacciones bancarias, pero pueden manejar operaciones de matrices masivas que se usan en redes neuronales a velocidades rápidas.
La tarea principal de las TPU es el procesamiento de matrices, que es una combinación de operaciones de multiplicación y acumulación. Las TPU contienen miles de acumuladores multiplicadores que están conectados directamente entre sí para formar una gran matriz física. Esto se conoce como arquitectura de arreglo sistólico. Las Cloud TPU v3 contienen dos arreglos sistólicos de ALU de 128 x 128 en un solo procesador.
El host de la TPU transmite datos a una cola de entrada. La TPU carga datos de la cola de entrada y los almacena en la memoria HBM. Cuando se completa el cálculo, la TPU carga los resultados en la cola de salida. Luego, el host de la TPU lee los resultados de la cola de salida y los almacena en la memoria del host.
Para realizar las operaciones de matrices, la TPU carga los parámetros de la memoria HBM en la unidad de multiplicación de matrices (MXU).

Luego, la TPU carga datos de la memoria HBM. A medida que se ejecuta cada multiplicación, el resultado se pasa al siguiente multiplicador-acumulador. El resultado es la suma de todos los resultados de multiplicación entre los datos y los parámetros. No se requiere acceso a la memoria durante el proceso de multiplicación de matrices.
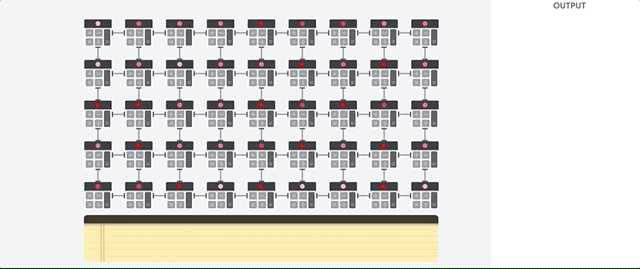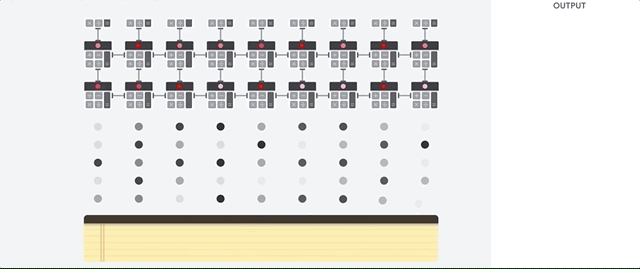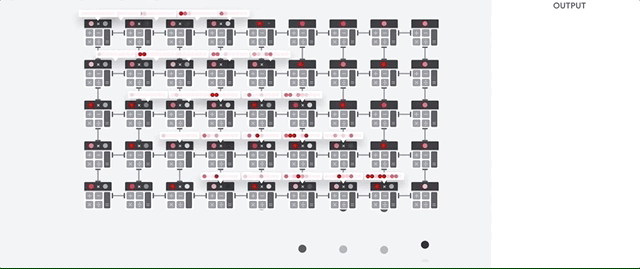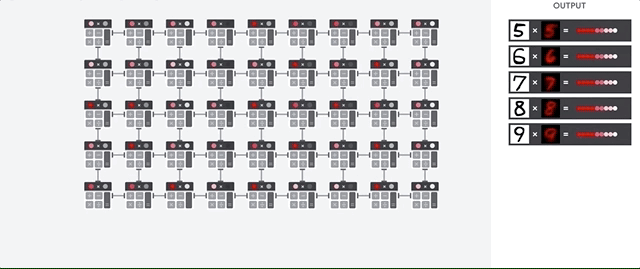
Como resultado, las TPU pueden lograr una alta capacidad de procesamiento computacional en los cálculos de redes neuronales.
Arquitectura del sistema de TPU
En las siguientes secciones, se describen los conceptos clave de un sistema de TPU. Para obtener más información sobre los términos comunes del aprendizaje automático, consulta el Glosario de aprendizaje automático.
Si no conoces Cloud TPU, consulta la página principal de la documentación de TPU.
Chip de TPU
Un chip de TPU contiene uno o más TensorCores. La cantidad de TensorCores depende de la versión del chip de TPU. Cada TensorCore consta de una o más unidades de multiplicación de matrices (MXU), una unidad vectorial y una unidad escalar. Para obtener más información sobre los TensorCores, consulta Una supercomputadora específica del dominio para entrenar redes neuronales profundas.
Una MXU se compone de 256 x 256 (TPU v6e) o 128 x 128 (versiones de TPU anteriores a la v6e) acumuladores multiplicadores en un arreglo sistólico. Las MXU proporcionan la mayor parte de la potencia de procesamiento en un TensorCore. Cada MXU puede realizar 16,000 operaciones de multiplicación y acumulación por ciclo. Todas las multiplicaciones toman entradas de bfloat16, pero todas las acumulaciones se realizan en formato de número FP32.
La unidad vectorial se usa para el cálculo general, como las activaciones y el softmax. La unidad escalar se usa para el flujo de control, el cálculo de direcciones de memoria y otras operaciones de mantenimiento.
pod de TPU
Un pod de TPU es un conjunto contiguo de TPU agrupadas en una red especializada. La cantidad de chips TPU en un Pod de TPU depende de la versión de TPU.
Porción
Una porción es una colección de chips ubicados dentro del mismo pod de TPU y conectados por interconexiones entre chips (ICI) de alta velocidad. Las porciones se describen en términos de chips o TensorCores, según la versión de TPU.
Forma del chip y topología del chip también hacen referencia a las formas de las porciones.
Multislice frente a una sola porción
Multislice es un grupo de porciones que extiende la conectividad de la TPU más allá de las conexiones de interconexión entre chips (ICI) y aprovecha la red del centro de datos (DCN) para transmitir datos más allá de una porción. El ICI sigue transmitiendo los datos dentro de cada segmento. Con esta conectividad híbrida, Multislice permite el paralelismo entre las porciones y te permite usar una mayor cantidad de núcleos de TPU para un solo trabajo de lo que puede admitir una sola porción.
Las TPU se pueden usar para ejecutar un trabajo en una sola porción o en varias. Consulta la Introducción a Multislice para obtener más detalles.
Cubo de TPU
Topología de 4x4x4 de chips de TPU interconectados. Esto solo se aplica a las topologías 3D (a partir de la TPU v4).
SparseCore
Los SparseCores son procesadores de Dataflow que aceleran los modelos con operaciones dispersas. Un caso de uso principal es la aceleración de los modelos de recomendación, que dependen en gran medida de los embeddings. La versión 5p incluye cuatro SparseCores por chip, y la versión 6e incluye dos SparseCores por chip. Para obtener una explicación detallada sobre cómo se pueden usar los SparseCores, consulta Análisis detallado de SparseCore para modelos de embedding grandes (LEM). Controlas cómo el compilador de XLA usa SparseCores con marcas de XLA. Para obtener más información, consulta Marcas de XLA de TPU.
Resistencia de la ICI de Cloud TPU
La resiliencia de la ICI ayuda a mejorar la tolerancia a errores de las conexiones ópticas y los conmutadores de circuitos ópticos (OCS) que conectan las TPU entre cubos. (Las conexiones de ICI dentro de un cubo usan enlaces de cobre que no se ven afectados). La resiliencia de ICI permite que las conexiones de ICI se enruten alrededor de las fallas de OCS y de ICI óptica. Como resultado, mejora la disponibilidad de programación de las porciones de TPU, con la desventaja de una degradación temporal en el rendimiento de la ICI.
En el caso de las Cloud TPU v4 y v5p, la resiliencia de la ICI se habilita de forma predeterminada para las porciones de un cubo o más grandes, por ejemplo:
- v5p-128 cuando se especifica el tipo de acelerador
- 4x4x4 cuando se especifica la configuración del acelerador
Versiones de TPU
La arquitectura exacta de un chip de TPU depende de la versión de TPU que uses. Cada versión de TPU también admite diferentes tamaños y configuraciones de segmentación. Para obtener más información sobre la arquitectura del sistema y las configuraciones compatibles, consulta las siguientes páginas:
Arquitectura de Cloud TPU
Google Cloud pone las TPU a disposición como recursos de procesamiento a través de las VMs de TPU. Puedes usar VMs de TPU directamente para tus cargas de trabajo o a través de Google Kubernetes Engine o Vertex AI. En las siguientes secciones, se describen los componentes clave de la arquitectura de la nube de TPU.
Arquitectura de la VM de TPU
La arquitectura de la VM de TPU te permite conectarte directamente a la VM conectada físicamente al dispositivo de TPU a través de SSH. Una VM de TPU, también conocida como trabajador, es una máquina virtual que ejecuta Linux y tiene acceso a las TPU subyacentes. Tienes acceso raíz a la VM, por lo que puedes ejecutar código arbitrario. Puedes acceder a los registros de depuración y los mensajes de error del compilador y del tiempo de ejecución.

Host único, host múltiple y subhost
Un host de TPU es una VM que se ejecuta en una computadora física conectada al hardware de TPU. Las cargas de trabajo de TPU pueden usar uno o más hosts.
Una carga de trabajo de host único se limita a una VM de TPU. Una carga de trabajo de varios hosts distribuye el entrenamiento en varias VMs de TPU. Una carga de trabajo de subhost no usa todos los chips de una VM de TPU.
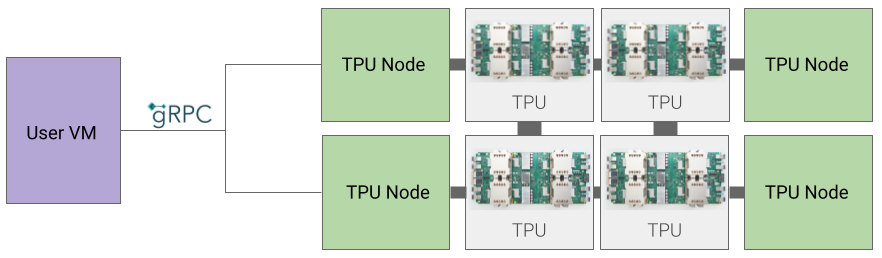
Arquitectura de nodo TPU (obsoleta)
La arquitectura del nodo TPU consta de una VM del usuario que se comunica con el host de la TPU a través de gRPC. Cuando se usa esta arquitectura, no se puede acceder directamente al host de la TPU, lo que dificulta la depuración de los errores de entrenamiento y de la TPU.
Migración de la arquitectura de nodo TPU a la de VM de TPU
Si tienes TPUs que usan la arquitectura de nodo TPU, sigue estos pasos para identificarlas, borrarlas y volver a aprovisionarlas como VMs de TPU.
Ve a la página de TPUs:
Ubica tu TPU y su arquitectura en el encabezado Arquitectura. Si la arquitectura es "VM de TPU", no es necesario que realices ninguna acción. Si la arquitectura es "Nodo TPU", debes borrar y volver a aprovisionar la TPU.
Borra la TPU y vuelve a aprovisionarla.
Consulta Administra TPU para obtener instrucciones sobre cómo borrar y volver a aprovisionar las TPU.