TPU 아키텍처
TPU(Tensor Processing Unit)는 Google에서 머신러닝 워크로드를 빠르게 처리하기 위해 설계한 ASIC(Application-Specific Integrated Circuit)입니다. Cloud TPU는 TPU를 확장 가능한 리소스로 제공하는 Google Cloud 서비스입니다.
TPU는 행렬 작업을 빠르게 수행하도록 설계되어 머신러닝 워크로드에 적합합니다. Pytorch 및 JAX와 같은 프레임워크를 사용하여 TPU에서 머신러닝 워크로드를 실행할 수 있습니다.
TPU는 어떻게 작동하나요?
다른 가속기가 ML 모델 학습의 연산 문제를 어떻게 처리하는지를 알면 TPU의 작동 원리를 이해하는 데 도움이 됩니다.
CPU의 작동 원리
CPU는 폰 노이만 구조에 기반한 범용 프로세서입니다. 따라서 CPU는 다음과 같이 소프트웨어 및 메모리와 연동합니다.
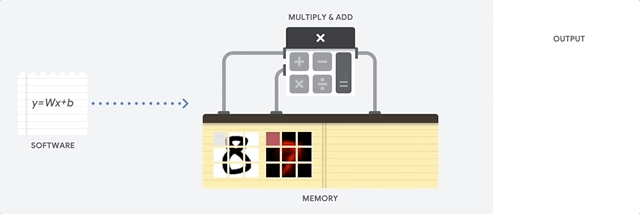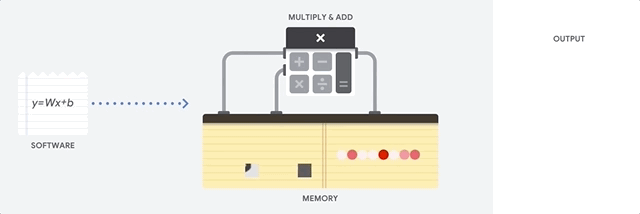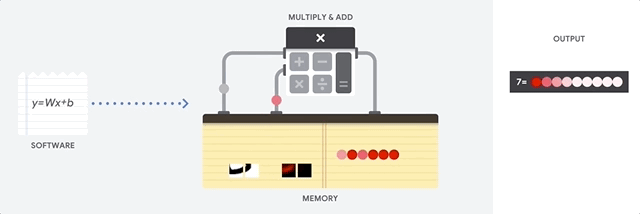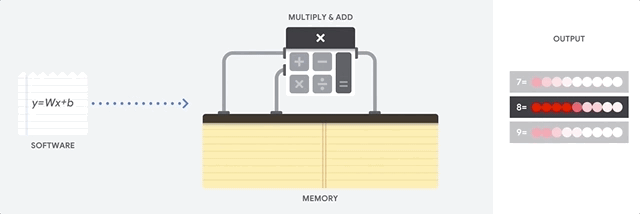
CPU의 최대 장점은 유연성입니다. 다양한 유형의 애플리케이션에 대해 CPU에서 모든 종류의 소프트웨어를 로드할 수 있습니다. 예를 들어 PC에서 워드 프로세싱, 로켓 엔진을 제어, 은행 거래 실행 또는 신경망으로 이미지 분류에 CPU를 사용할 수 있습니다.
CPU는 메모리에서 값을 로드하고, 값에 대한 계산을 수행하고, 모든 계산의 결과를 메모리에 다시 저장합니다. 메모리 액세스 속도는 계산 속도에 비해 느리므로 메모리 액세스 속도가 CPU의 총 처리량을 제한할 수 있습니다. 이를 폰 노이만 병목 현상이라고 합니다.
GPU의 작동 원리
처리량을 높이기 위해 GPU에는 단일 프로세서에 수천 개의 산술 논리 장치(ALU)가 포함되어 있습니다. 최신 GPU에는 일반적으로 2,500개~5,000개의 ALU가 포함됩니다. 이렇게 많은 수의 프로세서가 있으므로 수천 개의 곱셈과 덧셈을 동시에 실행할 수 있습니다.

이 GPU 아키텍처는 신경망의 행렬 연산과 같은 대규모 병렬처리 애플리케이션에 적합합니다. 실제로 일반적인 딥 러닝 학습 워크로드에서 GPU는 CPU보다 훨씬 더 많은 처리량을 제공할 수 있습니다.
그러나 GPU도 수많은 애플리케이션과 소프트웨어를 지원해야 하는 범용 프로세서입니다. 따라서 GPU는 CPU와 동일한 문제를 겪습니다. 수천 개의 ALU에서 이루어지는 각각의 연산에서 GPU는 레지스터 또는 공유 메모리에 액세스하여 피연산자를 읽고 중간 계산 결과를 저장해야 합니다.
TPU의 작동 원리
Google이 설계한 Cloud TPU는 신경망 작업 부하에 특화된 행렬 프로세서입니다. TPU는 문서 작성, 로켓 엔진 제어, 은행 거래 처리에 사용할 수는 없지만 신경망에 사용되는 대규모 행렬 연산을 고속으로 처리할 수 있습니다.
TPU의 주 임무는 승산 누적 연산이 조합된 행렬 처리입니다. TPU에는 수천 개의 누산기가 포함되어 있어 서로 직접 연결되어 대규모 실제 행렬을 형성합니다. 이 방식을 시스톨릭 배열 아키텍처라고 합니다. Cloud TPU v3에는 단일 프로세서에 128x128 ALU로 이루어진 시스톨릭 배열 2개가 포함됩니다.
TPU 호스트가 데이터를 인피드 큐로 스트리밍합니다. TPU는 인피드 큐에서 데이터를 로드하고 HBM 메모리에 저장합니다. 계산이 완료되면 TPU가 결과를 아웃피드 큐에 로드합니다. 그런 다음 TPU 호스트는 아웃피드 큐에서 결과를 읽고 호스트 메모리에 저장합니다.
행렬 작업을 수행하기 위해 TPU는 HBM 메모리의 매개변수를 행렬 곱셈 단위(MXU)로 로드합니다.

그런 다음 TPU가 HBM 메모리에서 데이터를 로드합니다. 각 곱셈이 실행된 결과가 다음 누산기로 전달됩니다. 출력은 데이터와 매개변수 간의 모든 곱셈 결과의 합입니다. 행렬 곱셈 연산 중에는 메모리 액세스가 필요하지 않습니다.
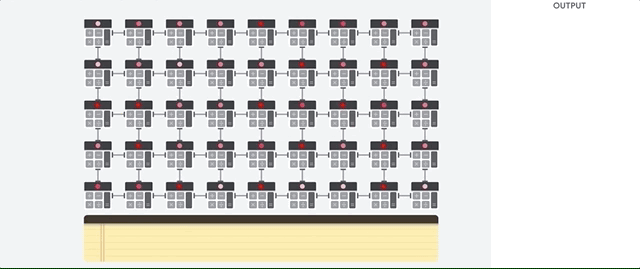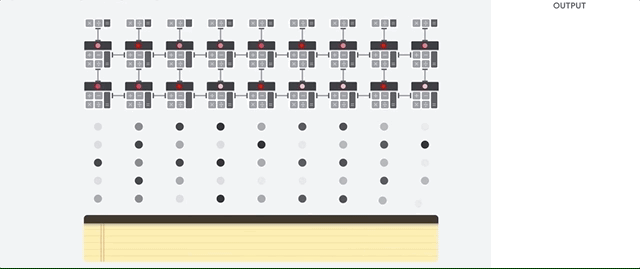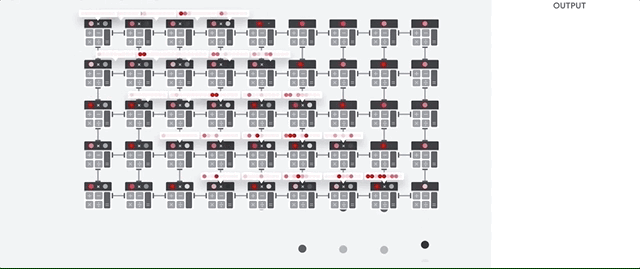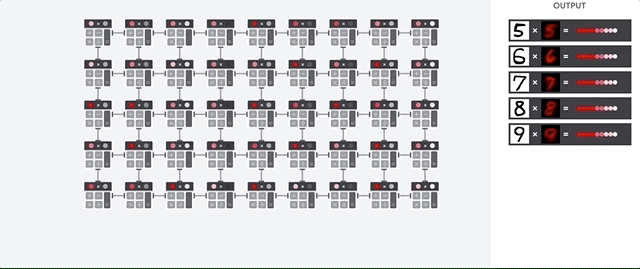
따라서 TPU는 신경망 연산 시 탁월한 연산 처리량을 달성할 수 있습니다.
TPU 시스템 아키텍처
다음 섹션에서는 TPU 시스템의 주요 개념을 설명합니다. 일반적인 머신러닝 용어에 대한 자세한 내용은 머신러닝 용어집을 참조하세요.
Cloud TPU를 처음 사용하는 경우 TPU 문서 홈페이지를 확인하세요.
TPU 칩
TPU 칩에는 하나 이상의 TensorCore가 포함됩니다. TensorCore 수는 TPU 칩 버전에 따라 다릅니다. 각 TensorCore는 하나 이상의 행렬 곱셈 단위(MXU), 벡터 단위, 스칼라 단위로 구성됩니다. TensorCore에 대한 자세한 내용은 심층신경망 학습용 도메인별 슈퍼컴퓨터를 참조하세요.
MXU는 시스톨릭 배열에서 256 x 256(TPU v6e) 또는 128 x 128(v6e 이전 TPU 버전)의 곱셈-누산기로 구성됩니다. MXU는 TensorCore에서 대량의 연산 성능을 제공합니다. 각 MXU는 주기당 곱셈-누산 작업 16,000개를 수행할 수 있습니다. 모든 곱셈은 bfloat16 입력을 사용하지만 모든 누적은 FP32 숫자 형식으로 수행됩니다.
벡터 단위는 활성화 및 소프트맥스와 같은 일반 계산에 사용됩니다. 스칼라 단위는 제어 흐름, 메모리 주소 계산, 기타 유지보수 작업에 사용됩니다.
TPU Pod
TPU Pod는 특수 네트워크를 통해 그룹화된 연속된 TPU 집합입니다. TPU Pod의 TPU 칩 수는 TPU 버전에 따라 다릅니다.
슬라이스
슬라이스는 고속 칩 간 상호 연결(ICI)을 통해 연결된 동일한 TPU Pod 내에 모두 위치한 칩 모음입니다. 슬라이스는 TPU 버전에 따라 칩 또는 TensorCore 단위로 표현됩니다.
칩 형태 및 칩 토폴로지는 슬라이스 형태도 지칭합니다.
멀티슬라이스와 단일 슬라이스 비교
멀티슬라이스는 칩 간 상호 연결(ICI) 연결 이상으로 TPU 연결을 확장하고 슬라이스 이상으로 데이터를 전송하기 위해 데이터 센터 네트워크(DCN)를 활용하는 슬라이스 그룹입니다. 각 슬라이스 내의 데이터는 여전히 ICI에 의해 전송됩니다. 이 하이브리드 연결을 사용하면 멀티슬라이스를 통해 슬라이스 간에 동시 로드를 지원하고 단일 슬라이스에 수용할 수 있는 것보다 더 많은 수의 TPU 코어를 단일 작업에 사용할 수 있습니다.
TPU는 단일 슬라이스 또는 여러 슬라이스에서 작업을 실행하는 데 사용할 수 있습니다. 자세한 내용은 멀티슬라이스 소개를 참조하세요.
TPU 큐브
상호 연결된 TPU 칩의 4x4x4 토폴로지입니다. 이는 3D 토폴로지(TPU v4부터)에만 적용됩니다.
SparseCore
SparseCore는 희소 작업을 사용하는 모델을 가속화하는 Dataflow 프로세서입니다. 주요 사용 사례는 임베딩에 크게 의존하는 추천 모델을 가속화하는 것입니다. v5p에는 칩당 4개의 SparseCore가, v6e에는 칩당 2개의 SparseCore가 포함되어 있습니다. SparseCore 사용 방법에 관한 자세한 설명은 대규모 임베딩 모델 (LEM)용 SparseCore 심층 분석을 참고하세요. XLA 플래그를 사용하여 XLA 컴파일러가 SparseCore를 사용하는 방식을 제어할 수 있습니다. 자세한 내용은 TPU XLA 플래그를 참고하세요.
Cloud TPU ICI 복원력
ICI 복원력은 큐브 간에 TPU를 연결하는 광 연결 및 광학 회로 스위치(OCS)의 내결함성을 개선하는 데 도움이 됩니다. (큐브 내의 ICI 연결은 영향을 받지 않는 구리 연결을 사용합니다.) ICI 복원력은 OCS 및 광 ICI 결함에 대해 ICI 연결을 라우팅할 수 있게 해줍니다. 그 결과 ICI 성능에 일시적인 성능 저하가 발생하는 대신 TPU 슬라이스의 예약 가용성이 향상됩니다.
Cloud TPU v4 및 v5p에서는 ICI 복원력이 기본적으로 사용 설정되어 있으며, 슬라이스가 1 큐브 이상인 경우에 적용됩니다. 예를 들면 다음과 같습니다.
- 가속기 유형 지정 시 v5p-128
- 가속기 구성 지정 시 4x4x4
TPU 버전
TPU 칩의 정확한 아키텍처는 사용 중인 TPU 버전에 따라 다릅니다. 또한 각 TPU 버전은 서로 다른 슬라이스 크기와 구성을 지원합니다. 시스템 아키텍처 및 지원되는 구성에 대한 자세한 내용은 다음 페이지를 참조하세요.
TPU 클라우드 아키텍처
Google Cloud 는 TPU를 TPU VM을 통한 컴퓨팅 리소스로 제공합니다. 사용자는 TPU VM을 직접 워크로드에 사용할 수 있으며, Google Kubernetes Engine 또는 Vertex AI를 통해서도 사용할 수 있습니다. 다음 섹션에서는 TPU 클라우드 아키텍처의 핵심 구성요소를 설명합니다.
TPU VM 아키텍처
TPU VM 아키텍처를 사용하면 SSH를 사용하여 TPU 기기에 물리적으로 연결된 VM에 직접 연결할 수 있습니다. 작업자라고도 부르는 TPU VM은 기본 TPU에 액세스할 수 있는 리눅스 기반의 가상 머신입니다. 임의 코드를 실행할 수 있도록 VM에 대해 루트 액세스 권한을 얻습니다. 컴파일러 및 런타임 디버그 로그 및 오류 메시지에 액세스할 수 있습니다.

단일 호스트, 멀티 호스트, 하위 호스트
TPU 호스트는 TPU 하드웨어에 연결된 물리적 컴퓨터에서 실행되는 VM입니다. TPU 워크로드는 하나 이상의 호스트를 사용할 수 있습니다.
단일 호스트 워크로드는 1개의 TPU VM으로 제한됩니다. 멀티 호스트 워크로드는 여러 TPU VM에 학습을 분산합니다. 하위 호스트 워크로드는 TPU VM의 모든 칩을 사용하지 않습니다.
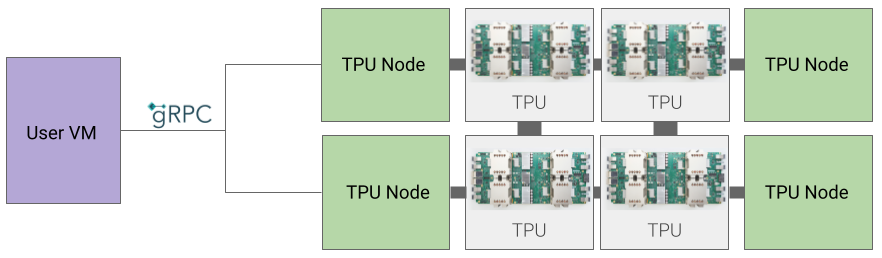
TPU 노드 아키텍처(지원 중단됨)
TPU 노드 아키텍처는 gRPC를 통해 TPU 호스트와 통신하는 사용자 VM으로 구성됩니다. 이 아키텍처를 사용하면 TPU 호스트에 직접 액세스할 수 없으므로 학습 및 TPU 오류를 디버깅하기가 어렵습니다.
TPU 노드에서 TPU VM 아키텍처로 이동
TPU 노드 아키텍처를 사용하는 TPU가 있는 경우 다음 단계에 따라 TPU를 식별 및 삭제하고 TPU VM으로 다시 프로비저닝합니다.
TPU 페이지로 이동합니다.
아키텍처 제목 아래에서 TPU와 아키텍처를 찾습니다. 아키텍처가 'TPU VM'인 경우 별도의 조치를 취하지 않아도 됩니다. 아키텍처가 'TPU 노드'인 경우 TPU를 삭제하고 다시 프로비저닝해야 합니다.
TPU를 삭제하고 다시 프로비저닝합니다.