Ringkasan Cloud TPU Multislice
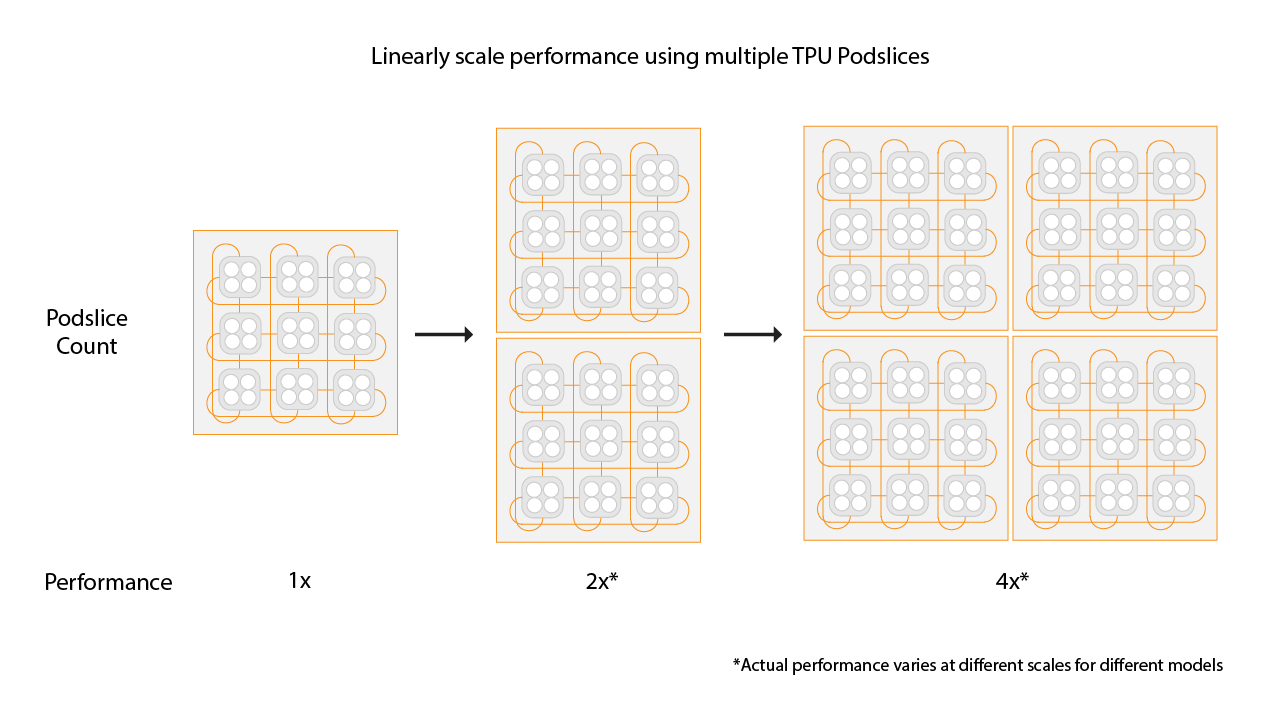
Cloud TPU Multislice adalah teknologi penskalaan performa full stack yang memungkinkan tugas pelatihan menggunakan beberapa slice TPU dalam satu slice atau pada slice di beberapa Pod dengan paralelisme data standar. Dengan chip TPU v4, tugas pelatihan dapat menggunakan lebih dari 4.096 chip dalam satu proses. Untuk tugas pelatihan yang memerlukan kurang dari 4.096 chip, satu slice dapat menawarkan performa terbaik. Namun, beberapa slice yang lebih kecil lebih mudah tersedia, sehingga memungkinkan waktu mulai yang lebih cepat saat Multislice digunakan dengan slice yang lebih kecil.
Saat di-deploy dalam konfigurasi Multislice, chip TPU di setiap slice berkomunikasi melalui interkoneksi antar-chip (ICI). Chip TPU di slice yang berbeda berkomunikasi dengan mentransfer data ke CPU (host) yang pada gilirannya mengirimkan data melalui jaringan pusat data (DCN). Untuk mengetahui informasi selengkapnya tentang penskalaan dengan Multislice, lihat Cara menskalakan pelatihan AI hingga puluhan ribu chip Cloud TPU dengan Multislice.
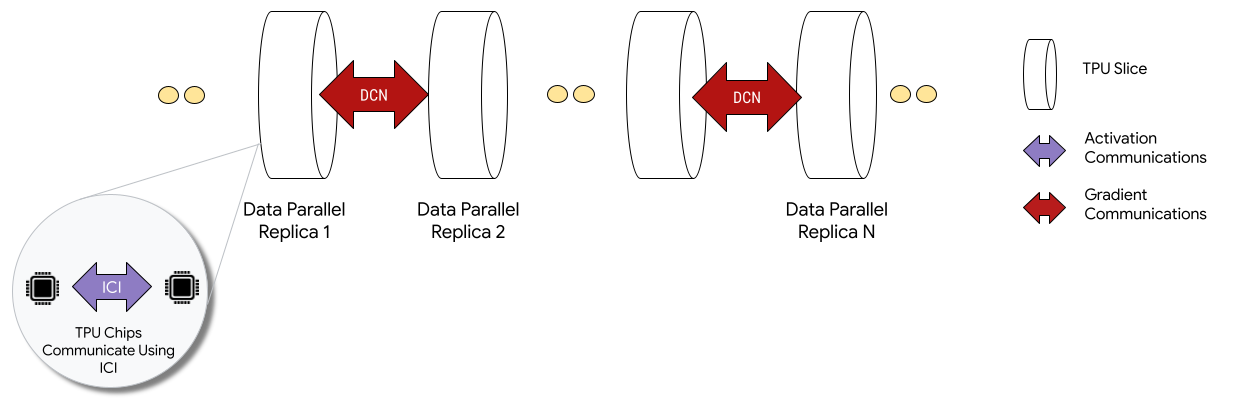
Developer tidak perlu menulis kode untuk menerapkan komunikasi DCN antar-slice. Compiler XLA menghasilkan kode tersebut untuk Anda dan tumpang-tindih komunikasi dengan komputasi untuk performa maksimum.
Konsep
- Jenis akselerator
- Bentuk setiap slice TPU
yang terdiri dari Multislice. Setiap slice dalam permintaan multislice memiliki jenis akselerator yang sama. Jenis akselerator
terdiri dari jenis TPU (v4 atau yang lebih baru) yang diikuti dengan jumlah TensorCore.
Misalnya,
v5litepod-128menentukan TPU v5e dengan 128 TensorCore. - Perbaikan otomatis
- Saat slice mengalami peristiwa pemeliharaan, penghentian sementara, atau kegagalan hardware, Cloud TPU akan membuat slice baru. Jika tidak ada resource yang cukup untuk membuat slice baru, pembuatan tidak akan selesai hingga hardware tersedia. Setelah slice baru dibuat, semua slice lain di lingkungan Multislice akan dimulai ulang sehingga pelatihan dapat dilanjutkan. Dengan skrip startup yang dikonfigurasi dengan benar, skrip pelatihan dapat diluncurkan ulang secara otomatis tanpa intervensi pengguna, memuat dan melanjutkan dari checkpoint terbaru.
- Jaringan Pusat Data (DCN)
- Jaringan dengan latensi lebih tinggi dan throughput lebih rendah (jika dibandingkan dengan ICI) yang menghubungkan slice TPU dalam konfigurasi Multislice.
- Penjadwalan grup
- Saat semua slice TPU disediakan bersama-sama, pada saat yang sama, menjamin bahwa semua atau tidak ada slice yang berhasil disediakan.
- Interchip interconnect (ICI)
- Link internal berkecepatan tinggi dan latensi rendah yang menghubungkan TPU dalam Pod TPU.
- Multislice
- Dua atau beberapa slice chip TPU yang dapat berkomunikasi melalui DCN.
- Node
- Dalam konteks Multislice, node mengacu pada slice TPU tunggal. Setiap slice TPU dalam Multislice diberi ID node.
- Skrip startup
- Skrip startup Compute Engine standar yang dijalankan setiap kali VM di-booting atau di-reboot. Untuk Multislice, parameter ini ditentukan dalam permintaan pembuatan QR. Untuk mengetahui informasi selengkapnya tentang skrip startup Cloud TPU, lihat Mengelola resource TPU.
- Tensor
- Struktur data yang digunakan untuk merepresentasikan data multidimensi dalam model machine learning.
- Jenis kapasitas Cloud TPU
TPU dapat dibuat dari berbagai jenis kapasitas (lihat Opsi Penggunaan di Cara kerja harga TPU):
Reservasi: Untuk menggunakan reservasi, Anda harus memiliki perjanjian reservasi dengan Google. Gunakan tanda
--reservedsaat membuat resource.Spot: Menargetkan kuota yang dapat di-preempt menggunakan Spot VM. Resource Anda mungkin dihentikan untuk memberi ruang bagi permintaan pekerjaan dengan prioritas yang lebih tinggi. Gunakan tanda
--spotsaat membuat resource.On-demand: Menargetkan kuota on-demand, yang tidak memerlukan reservasi dan tidak akan di-preempt. Permintaan TPU akan dimasukkan ke dalam antrean kuota on-demand yang ditawarkan oleh Cloud TPU, dan ketersediaan resource tidak dijamin. Dipilih secara default, tidak memerlukan tanda.
Mulai
Siapkan lingkungan Cloud TPU Anda.
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
ici_data_parallelismici_fsdp_parallelismici_tensor_parallelismSiapkan lingkungan:
$ gcloud auth login $ export QR_ID=your-queued-resource-id $ export TPU_NAME=your-tpu-name $ export PROJECT=your-project-name $ export ZONE=us-central1-a $ export NETWORK_NAME=your-network-name $ export SUBNETWORK_NAME=your-subnetwork-name $ export RUNTIME_VERSION=v2-alpha-tpuv5-lite $ export ACCELERATOR_TYPE=v5litepod-16 $ export EXAMPLE_TAG_1=your-tag-1 $ export EXAMPLE_TAG_2=your-tag-2 $ export SLICE_COUNT=4 $ export STARTUP_SCRIPT='#!/bin/bash\n'
Deskripsi variabel
Input Deskripsi QR_ID ID yang ditetapkan pengguna dari resource yang diantrekan. TPU_NAME Nama yang ditetapkan pengguna untuk TPU Anda. PROJECT Google Cloud nama project ZONE Menentukan zona tempat resource akan dibuat. NETWORK_NAME Nama jaringan VPC. SUBNETWORK_NAME Nama subnet di jaringan VPC RUNTIME_VERSION Versi software Cloud TPU. ACCELERATOR_TYPE v4-16 EXAMPLE_TAG_1, EXAMPLE_TAG_2 … Tag yang digunakan untuk mengidentifikasi sumber atau target yang valid untuk firewall jaringan SLICE_COUNT Jumlah irisan. Dibatasi hingga maksimum 256 irisan. STARTUP_SCRIPT Jika Anda menentukan skrip startup, skrip akan berjalan saat slice TPU disediakan atau dimulai ulang. Buat kunci SSH untuk
gcloud. Sebaiknya biarkan sandi kosong (tekan enter dua kali setelah menjalankan perintah berikut). Jika Anda diminta untuk mengganti filegoogle_compute_engineyang sudah ada, ganti versi yang ada.$ ssh-keygen -f ~/.ssh/google_compute_engine
Lakukan penyediaan TPU:
gcloud
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-id=${TPU_NAME} \ --zone=${ZONE} \ [--reserved |--spot]
Google Cloud CLI tidak mendukung semua opsi pembuatan QR, seperti tag. Untuk mengetahui informasi selengkapnya, lihat Membuat QR.
Konsol
Di konsol Google Cloud , buka halaman TPU:
Klik Buat TPU.
Di kolom Name, masukkan nama untuk TPU Anda.
Di kotak Zone, pilih zona tempat Anda ingin membuat TPU.
Di kotak TPU type, pilih jenis akselerator. Jenis akselerator menentukan versi dan ukuran Cloud TPU yang ingin Anda buat. Untuk mengetahui informasi selengkapnya tentang jenis akselerator yang didukung untuk setiap versi TPU, lihat versi TPU.
Di kotak Versi software TPU, pilih versi software. Saat membuat VM Cloud TPU, versi software TPU menentukan versi runtime TPU yang akan diinstal. Untuk mengetahui informasi selengkapnya, lihat Versi software TPU.
Klik tombol Aktifkan antrean.
Di kolom Queued resource name, masukkan nama untuk permintaan resource yang diantrekan.
Klik Buat untuk membuat permintaan resource dalam antrean.
Tunggu hingga resource dalam antrean berada dalam status
ACTIVEyang berarti node pekerja berada dalam statusREADY. Setelah penyediaan resource dalam antrean dimulai, mungkin perlu waktu satu hingga lima menit untuk menyelesaikannya, bergantung pada ukuran resource dalam antrean. Anda dapat memeriksa status permintaan resource yang diantrekan menggunakan gcloud CLI atau konsol Google Cloud :gcloud
$ gcloud compute tpus queued-resources \ list --filter=${QR_ID} --zone=${ZONE}
Konsol
Di konsol Google Cloud , buka halaman TPU:
Klik tab Sumber daya dalam antrean.
Klik nama permintaan resource yang diantrekan.
Hubungkan ke VM TPU menggunakan SSH:
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} --zone=${ZONE}
Clone MaxText (yang mencakup
shardings.py) ke VM TPU Anda:$ git clone https://github.com/AI-Hypercomputer/maxtext && cd maxtext
Instal Python 3.10:
$ sudo apt-get update $ sudo apt install python3.10 $ sudo apt install python3.10-venv
Buat dan aktifkan lingkungan virtual:
$ python3 -m venv your-venv-name $ source your-venv-name/bin/activate
Dalam direktori repositori MaxText, jalankan skrip penyiapan untuk menginstal JAX dan dependensi lainnya di slice TPU Anda. Skrip penyiapan memerlukan waktu beberapa menit untuk dijalankan.
$ bash setup.sh
Jalankan perintah berikut untuk menjalankan
shardings.pydi slice TPU Anda.$ python3 -m pedagogical_examples.shardings \ --ici_fsdp_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
Anda dapat melihat hasilnya di log. TPU Anda harus mencapai sekitar 260 TFLOP per detik atau pemanfaatan FLOP yang mengesankan sebesar 90%+. Dalam hal ini, kita telah memilih batch maksimum yang sesuai dengan Memori Bandwidth Tinggi (HBM) TPU.
Jangan ragu untuk menjelajahi strategi sharding lainnya melalui ICI. Misalnya, Anda dapat mencoba kombinasi berikut:
$ python3 -m pedagogical_examples.shardings \ --ici_tensor_parallelism 4 \ --batch_size 131072 \ --embedding_dimension 2048
Hapus resource yang diantrekan dan slice TPU setelah selesai. Anda harus menjalankan langkah-langkah pembersihan ini dari lingkungan tempat Anda menyiapkan slice (jalankan
exitterlebih dahulu untuk keluar dari sesi SSH). Penghapusan akan memerlukan waktu dua hingga lima menit untuk diselesaikan. Jika menggunakan gcloud CLI, Anda dapat menjalankan perintah ini di latar belakang dengan flag--asyncopsional.gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --force (--async)
Konsol
Di konsol Google Cloud , buka halaman TPU:
Klik tab Sumber daya dalam antrean.
Centang kotak di samping permintaan resource yang diantrekan.
Klik Delete.
- dcn_data_parallelism
- dcn_fsdp_parallelism
- dcn_tensor_parallelism
Clone MaxText di mesin runner Anda:
$ git clone https://github.com/AI-Hypercomputer/maxtext
Buka direktori repositori.
$ cd maxtext
Buat kunci SSH untuk
gcloud, sebaiknya biarkan sandi kosong (tekan enter dua kali setelah menjalankan perintah berikut). Jika Anda diminta bahwa filegoogle_compute_enginesudah ada, pilih untuk tidak mempertahankan versi yang ada.$ ssh-keygen -f ~/.ssh/google_compute_engine
Tambahkan variabel lingkungan untuk menetapkan jumlah slice TPU ke
2.$ export SLICE_COUNT=2
Buat lingkungan Multislice menggunakan perintah
queued-resources createatau konsol Google Cloud .gcloud
Perintah berikut menunjukkan cara membuat TPU Multislice v5e. Untuk menggunakan versi TPU yang berbeda, tentukan
accelerator-typedanruntime-versionyang berbeda.$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --node-count=${SLICE_COUNT} \ --node-prefix=${TPU_NAME} \ --zone=${ZONE} \ [--reserved|--spot]
Konsol
Di konsol Google Cloud , buka halaman TPU:
Klik Buat TPU.
Di kolom Name, masukkan nama untuk TPU Anda.
Di kotak Zone, pilih zona tempat Anda ingin membuat TPU.
Di kotak TPU type, pilih jenis akselerator. Jenis akselerator menentukan versi dan ukuran Cloud TPU yang ingin Anda buat. Multislice hanya didukung di Cloud TPU v4 dan versi TPU yang lebih baru. Untuk mengetahui informasi selengkapnya tentang versi TPU, lihat Versi TPU.
Di kotak Versi software TPU, pilih versi software. Saat membuat VM Cloud TPU, versi software TPU menentukan versi runtime TPU yang akan diinstal di VM TPU. Untuk mengetahui informasi selengkapnya, lihat versi software TPU.
Klik tombol Aktifkan antrean.
Di kolom Queued resource name, masukkan nama untuk permintaan resource yang diantrekan.
Centang kotak Make this a Multislice TPU.
Di kolom Jumlah slice, masukkan jumlah slice yang ingin Anda buat.
Klik Buat untuk membuat permintaan resource dalam antrean.
Saat penyediaan resource dalam antrean dimulai, penyelesaiannya dapat memerlukan waktu hingga lima menit, bergantung pada ukuran resource dalam antrean. Tunggu hingga resource yang diantrekan berada dalam status
ACTIVE. Anda dapat memeriksa status permintaan resource dalam antrean menggunakan gcloud CLI atau konsol Google Cloud :gcloud
$ gcloud compute tpus queued-resources list \ --filter=${QR_ID} --zone=${ZONE} --project=${PROJECT}
Ini akan menghasilkan output yang terlihat seperti:
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central2-b 4 v5litepod-16 ACTIVE ...
Konsol
Di konsol Google Cloud , buka halaman TPU:
Klik tab Sumber daya dalam antrean.
Klik nama permintaan resource yang diantrekan.
Hubungi perwakilan akun Google Cloud Anda jika status QR berada dalam status
WAITING_FOR_RESOURCESatauPROVISIONINGselama lebih dari 15 menit.Instal dependensi.
$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="bash setup.sh"
Jalankan
shardings.pydi setiap pekerja menggunakanmultihost_runner.py.$ python3 multihost_runner.py \ --TPU_PREFIX=${TPU_NAME} \ --ZONE=${ZONE} \ --COMMAND="python3 -m pedagogical_examples.shardings \ --dcn_data_parallelism ${SLICE_COUNT} \ --ici_fsdp_parallelism 16 \ --batch_size 131072 \ --embedding_dimension 2048"
Anda akan melihat performa sekitar 230 TFLOP per detik dalam file log.
Untuk mengetahui informasi selengkapnya tentang cara mengonfigurasi paralelisme, lihat Sharding multislice menggunakan paralelisme DCN dan
shardings.py.Bersihkan TPU dan resource dalam antrean setelah selesai. Penghapusan akan memerlukan waktu dua hingga lima menit. Jika menggunakan gcloud CLI, Anda dapat menjalankan perintah ini di latar belakang dengan flag
--asyncopsional.- Gunakan jax.experimental.mesh_utils.create_hybrid_device_mesh alih-alih jax.experimental.mesh_utils.create_device_mesh saat membuat mesh.
- Menggunakan skrip runner eksperimen,
multihost_runner.py - Menggunakan skrip runner produksi,
multihost_job.py - Menggunakan pendekatan manual
Buat permintaan resource dalam antrean menggunakan perintah berikut:
$ gcloud compute tpus queued-resources \ create ${QR_ID} \ --project=${PROJECT} \ --zone=${ZONE} \ --node-count=${SLICE_COUNT} \ --accelerator-type=${ACCELERATOR_TYPE} \ --runtime-version=${RUNTIME_VERSION} \ --network=${NETWORK_NAME} \ --subnetwork=${SUBNETWORK_NAME} \ --tags=${EXAMPLE_TAG_1},${EXAMPLE_TAG_2} \ --metadata=startup-script="${STARTUP_SCRIPT}" \ [--reserved|--spot]
Buat file bernama
queued-resource-req.jsondan salin JSON berikut ke dalamnya.{ "guaranteed": { "reserved": true }, "tpu": { "node_spec": [ { "parent": "projects/your-project-number/locations/your-zone", "node": { "accelerator_type": "accelerator-type", "runtime_version": "tpu-vm-runtime-version", "network_config": { "network": "your-network-name", "subnetwork": "your-subnetwork-name", "enable_external_ips": true }, "tags" : ["example-tag-1"] "metadata": { "startup-script": "your-startup-script" } }, "multi_node_params": { "node_count": slice-count, "node_id_prefix": "your-queued-resource-id" } } ] } }
Ganti nilai berikut:
- your-project-number - Google Cloud Nomor project Anda
- your-zone - Zona tempat Anda ingin membuat resource dalam antrean
- accelerator-type - Versi dan ukuran satu irisan. Multislice hanya didukung di Cloud TPU v4 dan versi TPU yang lebih baru.
- tpu-vm-runtime-version - Versi runtime VM TPU yang ingin Anda gunakan.
- your-network-name - Opsional, jaringan yang akan menjadi tempat resource dalam antrean
- your-subnetwork-name - Opsional, subnetwork tempat resource yang diantrekan akan dilampirkan
- example-tag-1 - Opsional, string tag arbitrer
- your-startup-script - Skrip startup yang akan dijalankan saat resource dalam antrean dialokasikan
- slice-count - Jumlah slice TPU di lingkungan Multislice Anda
- your-queued-resource-id - ID yang disediakan pengguna untuk resource yang diantrekan
Untuk mengetahui informasi selengkapnya, lihat dokumentasi REST Queued Resource API untuk semua opsi yang tersedia.
Untuk menggunakan kapasitas Spot, ganti:
"guaranteed": { "reserved": true }dengan"spot": {}Hapus baris untuk menggunakan kapasitas on-demand default.
Kirim permintaan pembuatan resource yang diantrekan dengan payload JSON:
$ curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d @queuedresourcereq.json \ https://tpu.googleapis.com/v2alpha1/projects/your-project-id/locations/your-zone/queuedResources\?queued_resource_id\=your-queued-resource-id
Ganti nilai berikut:
- your-project-id - ID project Google Cloud Anda
- your-zone - Zona tempat Anda ingin membuat resource dalam antrean
- your-queued-resource-id - ID yang disediakan pengguna untuk resource yang diantrekan
Di konsol Google Cloud , buka halaman TPU:
Klik Buat TPU.
Di kolom Name, masukkan nama untuk TPU Anda.
Di kotak Zone, pilih zona tempat Anda ingin membuat TPU.
Di kotak TPU type, pilih jenis akselerator. Jenis akselerator menentukan versi dan ukuran Cloud TPU yang ingin Anda buat. Multislice hanya didukung di Cloud TPU v4 dan versi TPU yang lebih baru. Untuk mengetahui informasi selengkapnya tentang jenis akselerator yang didukung untuk setiap versi TPU, lihat Versi TPU.
Di kotak Versi software TPU, pilih versi software. Saat membuat VM Cloud TPU, versi software TPU menentukan versi runtime TPU yang akan diinstal. Untuk mengetahui informasi selengkapnya, lihat Versi software TPU.
Klik tombol Aktifkan antrean.
Di kolom Queued resource name, masukkan nama untuk permintaan resource yang diantrekan.
Centang kotak Make this a Multislice TPU.
Di kolom Jumlah slice, masukkan jumlah slice yang ingin Anda buat.
Klik Buat untuk membuat permintaan resource dalam antrean.
Di konsol Google Cloud , buka halaman TPU:
Klik tab Sumber daya dalam antrean.
Klik nama permintaan resource yang diantrekan.
Di konsol Google Cloud , buka halaman TPU:
Klik tab Sumber daya dalam antrean.
Di konsol Google Cloud , buka halaman TPU:
Klik tab Sumber daya dalam antrean.
Centang kotak di samping permintaan resource yang diantrekan.
Klik Delete.
- B adalah ukuran batch dalam token
- P adalah jumlah parameter
- Hal ini menyebabkan "gelembung pipeline" saat chip tidak aktif karena menunggu data.
- Hal ini memerlukan pengelompokan mikro yang mengurangi ukuran tumpukan efektif, intensitas aritmatika, dan pada akhirnya penggunaan FLOP model.
Untuk menggunakan Multislice, resource TPU Anda harus dikelola sebagai resource dalam antrean.
Contoh pengantar
Tutorial ini menggunakan kode dari repositori GitHub MaxText. MaxText adalah LLM dasar berperforma tinggi, dapat diskalakan secara arbitrer, open source, dan telah diuji dengan baik yang ditulis dalam Python dan Jax. MaxText dirancang untuk dilatih secara efisien di Cloud TPU.
Kode di shardings.py
dirancang untuk membantu Anda mulai bereksperimen dengan berbagai opsi paralelisme. Misalnya, paralelisme data, paralelisme data yang sepenuhnya di-shard (FSDP),
dan paralelisme tensor. Kode ini dapat diskalakan dari lingkungan slice tunggal hingga Multislice.
Paralelisme ICI
ICI mengacu pada interkoneksi berkecepatan tinggi yang menghubungkan TPU dalam satu slice. Sharding ICI sesuai dengan sharding dalam slice. shardings.py
menyediakan tiga parameter paralelisme ICI:
Nilai yang Anda tentukan untuk parameter ini menentukan jumlah shard untuk setiap metode paralelisme.
Input ini harus dibatasi sehingga
ici_data_parallelism * ici_fsdp_parallelism * ici_tensor_parallelism sama dengan
jumlah chip dalam slice.
Tabel berikut menunjukkan contoh input pengguna untuk paralelisme ICI untuk empat chip yang tersedia di v4-8:
| ici_data_parallelism | ici_fsdp_parallelism | ici_tensor_parallelism | |
| FSDP 4 arah | 1 | 4 | 1 |
| Paralelisme Tensor 4 arah | 1 | 1 | 4 |
| Paralelisme Tensor 2 arah + FSDP 2 arah | 1 | 2 | 2 |
Perhatikan bahwa ici_data_parallelism harus dibiarkan sebagai 1 dalam sebagian besar kasus karena jaringan ICI cukup cepat untuk hampir selalu lebih memilih FSDP daripada paralelisme data.
Contoh ini mengasumsikan bahwa Anda sudah terbiasa menjalankan kode di satu slice TPU
seperti dalam Menjalankan penghitungan di VM Cloud TPU menggunakan JAX.
Contoh ini menunjukkan cara menjalankan shardings.py pada satu slice.
Sharding multiris menggunakan paralelisme DCN
Skrip shardings.py menggunakan tiga parameter yang menentukan paralelisme DCN,
yang sesuai dengan jumlah shard dari setiap jenis paralelisme data:
Nilai parameter ini harus dibatasi sehingga
dcn_data_parallelism * dcn_fsdp_parallelism * dcn_tensor_parallelism sama dengan
jumlah irisan.
Sebagai contoh untuk dua slice, gunakan --dcn_data_parallelism = 2.
| dcn_data_parallelism | dcn_fsdp_parallelism | dcn_tensor_parallelism | # irisan | |
| Paralelisme data 2 arah | 2 | 1 | 1 | 2 |
dcn_tensor_parallelism harus selalu disetel ke 1 karena DCN tidak cocok untuk sharding tersebut. Untuk beban kerja LLM umum pada chip v4, dcn_fsdp_parallelism juga harus ditetapkan ke 1 dan oleh karena itu, dcn_data_parallelism harus ditetapkan ke jumlah slice, tetapi hal ini bergantung pada aplikasi.
Saat Anda meningkatkan jumlah slice (dengan asumsi Anda mempertahankan ukuran slice dan batch per slice tetap konstan), Anda akan meningkatkan jumlah paralelisme data.
Menjalankan shardings.py di lingkungan Multislice
Anda dapat menjalankan shardings.py di lingkungan Multislice menggunakan
multihost_runner.py atau dengan menjalankan shardings.py di setiap VM TPU. Di sini kita menggunakan
multihost_runner.py. Langkah-langkah berikut sangat mirip dengan langkah-langkah di
Memulai: Eksperimen Cepat pada Beberapa slice
dari repositori MaxText, kecuali di sini kita menjalankan shardings.py, bukan
LLM yang lebih kompleks di train.py.
Alat multihost_runner.py dioptimalkan untuk eksperimen cepat, dengan berulang kali menggunakan TPU yang sama. Karena skrip multihost_runner.py bergantung pada koneksi SSH yang berjalan lama, sebaiknya jangan gunakan skrip ini untuk tugas yang berjalan lama.
Jika Anda ingin menjalankan tugas yang lebih lama (misalnya, berjam-jam atau berhari-hari), sebaiknya gunakan multihost_job.py.
Dalam tutorial ini, kita menggunakan istilah runner untuk menunjukkan mesin tempat Anda
menjalankan skrip multihost_runner.py. Kami menggunakan istilah pekerja untuk menunjukkan VM TPU yang membentuk slice Anda. Anda dapat menjalankan multihost_runner.py di mesin lokal atau VM Compute Engine mana pun dalam project yang sama dengan slice Anda. Menjalankan
multihost_runner.py di pekerja tidak didukung.
multihost_runner.py otomatis terhubung ke TPU worker menggunakan SSH.
Dalam contoh ini, Anda menjalankan shardings.py di dua slice v5e-16, dengan total empat
VM dan 16 chip TPU. Anda dapat mengubah contoh untuk dijalankan di lebih banyak TPU.
Menyiapkan lingkungan Anda
Menskalakan workload ke Multislice
Sebelum menjalankan model di lingkungan Multislice, lakukan perubahan kode berikut:
Ini harus menjadi satu-satunya perubahan kode yang diperlukan saat beralih ke Multislice. Untuk mencapai performa tinggi, DCN perlu dipetakan ke sumbu paralel data, paralel data yang sepenuhnya di-shard, atau paralel pipeline. Pertimbangan performa dan strategi sharding dibahas lebih mendetail di Sharding Dengan Multislice untuk Performa Maksimal.
Untuk memvalidasi bahwa kode Anda dapat mengakses semua perangkat, Anda dapat menegaskan bahwa
len(jax.devices()) sama dengan jumlah chip di lingkungan Multislice Anda. Misalnya, jika Anda menggunakan empat slice v4-16, Anda memiliki
delapan chip per slice * 4 slice, sehingga len(jax.devices()) harus menampilkan 32.
Memilih ukuran slice untuk lingkungan Multislice
Untuk mendapatkan peningkatan kecepatan linier, tambahkan slice baru dengan ukuran yang sama dengan slice yang ada. Misalnya, jika Anda menggunakan irisan v4-512, Multislice akan
mencapai performa sekitar dua kali lipat dengan menambahkan irisan v4-512 kedua
dan menggandakan ukuran batch global Anda. Untuk mengetahui informasi selengkapnya, lihat
Sharding dengan Multislice untuk Performa Maksimum.
Menjalankan Tugas di beberapa slice
Ada tiga pendekatan berbeda untuk menjalankan workload kustom di lingkungan Multislice:
Skrip runner eksperimen
Skrip multihost_runner.py
mendistribusikan kode ke lingkungan Multislice yang ada, dan menjalankan
perintah Anda di setiap host, menyalin kembali log Anda, dan melacak status
error setiap perintah. Skrip multihost_runner.py didokumentasikan dalam
README MaxText.
Karena multihost_runner.py mempertahankan koneksi SSH yang persisten, alat ini hanya
cocok untuk eksperimen berukuran sedang yang berjalan relatif singkat. Anda dapat
menyesuaikan langkah-langkah dalam tutorial multihost_runner.py
dengan konfigurasi workload dan hardware Anda.
Skrip runner produksi
Untuk tugas produksi yang memerlukan ketahanan terhadap kegagalan hardware dan penghentian sementara lainnya, sebaiknya integrasikan langsung dengan Create Queued Resource API. Gunakan multihost_job.py sebagai contoh kerja
yang memicu panggilan API Created Queued Resource dengan skrip startup yang sesuai
untuk menjalankan pelatihan dan melanjutkan pada penghentian sementara. Skrip multihost_job.py
didokumentasikan dalam
README MaxText.
Karena multihost_job.py harus menyediakan resource untuk setiap proses, siklus iterasi yang diberikannya tidak secepat multihost_runner.py.
Pendekatan manual
Sebaiknya gunakan atau sesuaikan multihost_runner.py atau multihost_job.py untuk menjalankan workload kustom dalam konfigurasi Multislice Anda. Namun, jika Anda lebih memilih untuk menyediakan dan mengelola lingkungan menggunakan perintah QR secara langsung, lihat Mengelola Lingkungan Multislice.
Mengelola lingkungan Multislice
Untuk menyediakan dan mengelola QR secara manual tanpa menggunakan alat yang disediakan di repo MaxText, baca bagian berikut.
Membuat resource dalam antrean
gcloud
Pastikan Anda memiliki kuota yang sesuai sebelum memilih --reserved,
--spot, atau kuota sesuai permintaan default. Untuk mengetahui informasi tentang jenis kuota, lihat Kebijakan Kuota.
curl
Responsnya akan terlihat seperti berikut:
{ "name": "projects/<your-project-id>/locations/<your-zone>/operations/operation-<your-qr-guid>", "metadata": { "@type": "type.googleapis.com/google.cloud.common.OperationMetadata", "createTime": "2023-11-01T00:17:05.742546311Z", "target": "projects/<your-project-id>/locations/<your-zone>/queuedResources/<your-qa-id>", "verb": "create", "cancelRequested": false, "apiVersion": "v2alpha1" }, "done": false }
Gunakan nilai GUID di akhir nilai string untuk atribut name guna mendapatkan informasi tentang permintaan resource yang diantrekan.
Konsol
Mengambil status resource dalam antrean
gcloud
$ gcloud compute tpus queued-resources describe ${QR_ID} --zone=${ZONE}
Untuk resource dalam antrean yang berada dalam status ACTIVE, output-nya akan terlihat seperti
berikut:
...
state:
state: ACTIVE
...
curl
$ curl -X GET -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://tpu.googleapis.com/v2/projects/your-project-id/locations/your-zone/queuedResources/${YOUR_QR_ID}
Untuk resource dalam antrean yang berada dalam status ACTIVE, output-nya akan terlihat seperti
berikut:
{
"name": your-queued-res,
"tpu": {
"nodeSpec": [
{
... // node 1
},
{
... // node 2
},
...
]
},
...
"state": "ACTIVE"
}
Konsol
Setelah TPU Anda disediakan, Anda juga dapat melihat detail tentang permintaan resource yang diantrekan dengan membuka halaman TPU, menemukan TPU Anda, dan mengklik nama permintaan resource yang diantrekan yang sesuai.
Dalam skenario yang jarang terjadi, Anda mungkin menemukan resource yang diantrekan dalam status FAILED sementara beberapa slice dalam status ACTIVE. Jika hal ini terjadi, hapus resource yang dibuat,
lalu coba lagi dalam beberapa menit atau hubungi Google Cloud Dukungan.
SSH dan instal dependensi
Menjalankan kode JAX pada slice TPU
menjelaskan cara terhubung ke VM TPU menggunakan SSH dalam satu slice. Untuk terhubung ke semua VM TPU di lingkungan Multislice Anda melalui SSH dan menginstal dependensi, gunakan perintah gcloud berikut:
$ gcloud compute tpus queued-resources ssh ${QR_ID} \ --zone=${ZONE} \ --node=all \ --worker=all \ --command="command-to-run" \ --batch-size=4
Perintah gcloud ini mengirimkan perintah yang ditentukan ke semua pekerja dan node di
QR menggunakan SSH. Perintah dikelompokkan menjadi grup yang terdiri dari empat perintah dan dikirim secara bersamaan. Batch perintah berikutnya dikirim saat batch saat ini selesai dieksekusi. Jika terjadi kegagalan pada salah satu perintah, pemrosesan
berhenti, dan tidak ada batch lebih lanjut yang dikirim. Untuk mengetahui informasi selengkapnya, lihat
Referensi API resource dalam antrean.
Jika jumlah slice yang Anda gunakan melebihi batas threading komputer lokal (juga disebut batas batching), Anda akan mengalami kebuntuan. Sebagai contoh,
asumsikan batas pengelompokan di komputer lokal Anda adalah 64. Jika Anda mencoba menjalankan skrip pelatihan pada lebih dari 64 slice, misalnya 100, perintah SSH akan memecah slice menjadi batch. Proses ini akan menjalankan skrip pelatihan pada batch pertama dari 64 slice dan menunggu hingga skrip selesai sebelum menjalankan skrip pada batch 36 slice yang tersisa. Namun, 64 slice pertama tidak dapat
selesai hingga 36 slice yang tersisa mulai menjalankan skrip, sehingga menyebabkan
kebuntuan.
Untuk mencegah skenario ini, Anda dapat menjalankan skrip pelatihan di latar belakang pada
setiap VM dengan menambahkan ampersan (&) ke perintah skrip yang Anda tentukan
dengan tanda --command. Saat Anda melakukannya, setelah memulai skrip pelatihan
pada batch slice pertama, kontrol akan segera kembali ke
perintah SSH. Kemudian, perintah SSH dapat mulai menjalankan skrip pelatihan pada batch 36 slice yang tersisa. Anda harus menyalurkan aliran stdout dan stderr dengan tepat saat menjalankan perintah di latar belakang. Untuk meningkatkan paralelisme dalam QR yang sama, Anda dapat memilih slice tertentu menggunakan parameter --node.
Penyiapan jaringan
Pastikan slice TPU dapat berkomunikasi satu sama lain dengan menjalankan langkah-langkah berikut.
Instal JAX di setiap slice. Untuk mengetahui informasi selengkapnya, lihat
Menjalankan kode JAX pada slice TPU. Tegaskan bahwa
len(jax.devices()) sama dengan jumlah chip di lingkungan Multislice
Anda. Untuk melakukannya, pada setiap slice, jalankan:
$ python3 -c 'import jax; print(jax.devices())'
Jika Anda menjalankan kode ini pada empat slice v4-16, ada delapan chip per slice dan empat slice, total 32 chip (perangkat) yang akan ditampilkan oleh jax.devices().
Mencantumkan resource dalam antrean
gcloud
Anda dapat melihat status resource yang diantrekan menggunakan perintah queued-resources list:
$ gcloud compute tpus queued-resources list --zone=${ZONE}
Outputnya terlihat mirip dengan yang berikut ini:
NAME ZONE NODE_COUNT ACCELERATOR_TYPE STATE ... que-res-id us-central1-a 4 v5litepod-16 ACTIVE ...
Konsol
Mulai tugas Anda di lingkungan yang disediakan
Anda dapat menjalankan beban kerja secara manual dengan menghubungkan ke semua host di setiap slice melalui SSH dan menjalankan perintah berikut di semua host.
$ gcloud compute tpus tpu-vm ssh ${TPU_NAME} \ --zone=${ZONE} \ --worker=all \ --command="command-to-run"
Mereset QR
ResetQueuedResource API dapat digunakan untuk mereset
semua VM dalam QR ACTIVE. Mereset VM akan menghapus memori mesin secara paksa dan mereset VM ke keadaan awal. Semua data yang disimpan secara lokal akan
tetap utuh dan skrip startup akan dipanggil setelah reset. API
ResetQueuedResource dapat berguna saat Anda ingin memulai ulang semua TPU. Misalnya, saat pelatihan macet dan mereset semua VM lebih mudah daripada men-debug.
Reset semua VM dilakukan secara paralel dan operasi ResetQueuedResource
memerlukan waktu satu hingga dua menit untuk diselesaikan. Untuk memanggil API, gunakan perintah berikut:
$ gcloud compute tpus queued-resources reset ${QR_ID} --zone=${ZONE}
Menghapus resource dalam antrean
Untuk melepaskan resource di akhir sesi pelatihan, hapus resource yang diantrekan. Penghapusan akan memerlukan waktu dua hingga lima menit hingga selesai. Jika
menggunakan gcloud CLI, Anda dapat menjalankan perintah ini di latar belakang dengan
flag --async opsional.
gcloud
$ gcloud compute tpus queued-resources \ delete ${QR_ID} --zone=${ZONE} --force [--async]
Konsol
Pemulihan kegagalan otomatis
Jika terjadi gangguan, Multislice menawarkan perbaikan tanpa intervensi pada slice yang terpengaruh dan mereset semua slice setelahnya. Slice yang terpengaruh diganti dengan slice baru dan slice yang sehat lainnya di-reset. Jika tidak ada kapasitas yang tersedia untuk mengalokasikan penggantian slice, pelatihan akan berhenti.
Untuk melanjutkan pelatihan secara otomatis setelah terganggu, Anda harus menentukan skrip startup yang memeriksa dan memuat titik pemeriksaan yang terakhir disimpan. Skrip startup Anda akan otomatis dijalankan setiap kali slice dialokasikan ulang atau VM direset. Anda menentukan skrip startup dalam payload JSON yang Anda kirim ke API permintaan pembuatan QR.
Skrip startup berikut (digunakan di Create QRs) memungkinkan Anda memulihkan diri secara otomatis dari kegagalan dan melanjutkan pelatihan dari titik pemeriksaan yang disimpan di bucket Cloud Storage selama pelatihan MaxText:
{
"tpu": {
"node_spec": [
{
...
"metadata": {
"startup-script": "#! /bin/bash \n pwd \n runuser -l user1 -c 'cd /home/user1/MaxText && python3 -m MaxText.train MaxText/configs/base.yml run_name=run_test_failure_recovery dcn_data_parallelism=4 ici_fsdp_parallelism=8 steps=10000 save_period=10 base_output_directory='gs://user1-us-central2'' EOF"
}
...
}
]
}
}
Clone repo MaxText sebelum mencoba ini.
Pembuatan profil dan proses debug
Pembuatan profil sama di lingkungan slice tunggal dan Multislice. Untuk mengetahui informasi selengkapnya, lihat Membuat profil program JAX.
Mengoptimalkan pelatihan
Bagian berikut menjelaskan cara mengoptimalkan pelatihan Multislice.
Sharding dengan Multislice untuk performa maksimum
Untuk mencapai performa maksimum di lingkungan Multislice, Anda harus mempertimbangkan cara melakukan sharding di beberapa slice. Biasanya ada tiga pilihan (paralelisme data, paralelisme data yang sepenuhnya di-shard, dan paralelisme pipeline). Kami tidak merekomendasikan aktivasi sharding di seluruh dimensi model (terkadang disebut paralelisme tensor) karena memerlukan bandwidth antar-slice yang terlalu besar. Untuk semua strategi ini, Anda dapat mempertahankan strategi sharding yang sama dalam slice yang telah berhasil untuk Anda di masa lalu.
Sebaiknya mulai dengan paralelisme data murni. Penggunaan paralelisme data yang di-shard sepenuhnya berguna untuk membebaskan penggunaan memori. Kekurangannya adalah komunikasi antar-slice menggunakan jaringan DCN dan akan memperlambat workload Anda. Gunakan paralelisme pipeline hanya jika diperlukan berdasarkan ukuran batch (seperti yang dianalisis di bawah).
Kapan harus menggunakan paralelisme data
Paralelisme data murni akan berfungsi dengan baik jika Anda memiliki beban kerja yang berjalan dengan baik, tetapi Anda ingin meningkatkan performanya dengan melakukan penskalaan di beberapa slice.
Untuk mencapai penskalaan yang kuat di beberapa slice, jumlah waktu yang diperlukan untuk melakukan all-reduce melalui DCN harus kurang dari jumlah waktu yang diperlukan untuk melakukan backward pass. DCN digunakan untuk komunikasi antar-slice dan merupakan faktor pembatas dalam throughput beban kerja.
Setiap chip TPU v4 memiliki performa puncak 275 * 1012 FLOPS per detik.
Ada empat chip per host TPU dan setiap host memiliki bandwidth jaringan maksimum sebesar 50 Gbps.
Artinya, intensitas aritmetikanya adalah 4 * 275 * 1012 FLOPS / 50 Gbps = 22000 FLOPS / bit.
Model Anda akan menggunakan bandwidth DCN 32 hingga 64 bit untuk setiap parameter per langkah. Jika Anda menggunakan dua slice, model Anda akan menggunakan bandwidth DCN 32 bit. Jika Anda menggunakan lebih dari dua slice, compiler akan melakukan operasi all-reduce pengacakan penuh dan Anda akan menggunakan bandwidth DCN hingga 64 bit untuk setiap parameter per langkah. Jumlah FLOPS yang diperlukan untuk setiap parameter akan bervariasi bergantung pada model Anda. Secara khusus, untuk model bahasa berbasis Transformer, jumlah FLOPS yang diperlukan untuk meneruskan dan meneruskan mundur kira-kira 6 * B * P dengan:
Jumlah FLOPS per parameter adalah 6 * B dan jumlah FLOPS per parameter
selama proses mundur adalah 4 * B.
Untuk memastikan penskalaan yang kuat di beberapa slice, pastikan intensitas operasional melebihi intensitas aritmatika hardware TPU. Untuk menghitung intensitas operasional, bagi jumlah FLOPS per parameter selama proses mundur dengan bandwidth jaringan (dalam bit) per parameter per langkah:
Operational Intensity = FLOPSbackwards_pass / DCN bandwidth
Oleh karena itu, untuk model bahasa berbasis Transformer, jika Anda menggunakan dua slice:
Operational intensity = 4 * B / 32
Jika Anda menggunakan lebih dari dua irisan: Operational intensity = 4 * B/64
Hal ini menunjukkan ukuran batch minimum antara 176 ribu dan 352 ribu untuk model bahasa berbasis Transformer. Karena jaringan DCN dapat mengalami penurunan paket secara singkat, sebaiknya pertahankan margin error yang signifikan, dan hanya men-deploy paralelisme data jika ukuran batch per Pod minimal 350 ribu (dua Pod) hingga 700 ribu (banyak Pod).
Untuk arsitektur model lainnya, Anda harus memperkirakan waktu proses backward pass per slice (baik dengan mengukur waktunya menggunakan profiler atau dengan menghitung FLOPS). Kemudian, Anda dapat membandingkannya dengan waktu proses yang diharapkan untuk mengurangi DCN secara keseluruhan dan mendapatkan perkiraan yang baik tentang apakah paralelisme data akan masuk akal bagi Anda.
Kapan harus menggunakan paralelisme data yang sepenuhnya di-shard (FSDP)
Paralelisme data yang sepenuhnya di-shard (FSDP) menggabungkan paralelisme data (membuat shard data di seluruh node) dengan membuat shard bobot di seluruh node. Untuk setiap operasi di pass maju dan mundur, bobot dikumpulkan sehingga setiap slice memiliki bobot yang dibutuhkan. Daripada menyinkronkan gradien menggunakan all-reduce, gradien akan di-reduce-scatter saat dihasilkan. Dengan cara ini, setiap slice hanya mendapatkan gradien untuk bobot yang menjadi tanggung jawabnya.
Mirip dengan paralelisme data, FSDP akan memerlukan penskalaan ukuran batch global secara linear dengan jumlah slice. FSDP akan mengurangi tekanan memori saat Anda meningkatkan jumlah slice. Hal ini karena jumlah bobot dan status pengoptimal per slice berkurang, tetapi dengan harga peningkatan traffic jaringan dan kemungkinan pemblokiran yang lebih besar karena kolektif yang tertunda.
Dalam praktiknya, FSDP di seluruh slice paling baik jika Anda meningkatkan batch per slice, menyimpan lebih banyak aktivasi untuk meminimalkan re-materialisasi selama backward pass, atau meningkatkan jumlah parameter dalam jaringan saraf Anda.
Operasi pengumpulan semua dan pengurangan semua di FSDP berfungsi serupa dengan yang ada di DP, sehingga Anda dapat menentukan apakah workload FSDP Anda dibatasi oleh performa DCN dengan cara yang sama seperti yang dijelaskan di bagian sebelumnya.
Kapan harus menggunakan paralelisme pipeline
Paralelisme pipeline menjadi relevan saat mencapai performa tinggi dengan strategi paralelisme lain yang memerlukan ukuran batch global yang lebih besar daripada ukuran batch maksimum pilihan Anda. Paralelisme pipeline memungkinkan slice yang membentuk pipeline untuk "membagikan" batch. Namun, paralelisme pipeline memiliki dua kekurangan signifikan:
Paralelisme pipeline hanya boleh digunakan jika strategi paralelisme lainnya memerlukan ukuran batch global yang terlalu besar. Sebelum mencoba paralelisme pipeline, sebaiknya lakukan eksperimen untuk melihat secara empiris apakah konvergensi per sampel melambat pada ukuran batch yang diperlukan untuk mencapai FSDP berperforma tinggi. FSDP cenderung mencapai pemanfaatan FLOP model yang lebih tinggi, tetapi jika konvergensi per sampel melambat seiring bertambahnya ukuran batch, paralelisme pipeline mungkin masih menjadi pilihan yang lebih baik. Sebagian besar beban kerja dapat mentoleransi ukuran batch yang cukup besar sehingga tidak mendapatkan manfaat dari paralelisme pipeline, tetapi beban kerja Anda mungkin berbeda.
Jika paralelisme pipeline diperlukan, sebaiknya gabungkan dengan paralelisme data atau FSDP. Hal ini akan memungkinkan Anda meminimalkan kedalaman pipeline sekaligus meningkatkan ukuran batch per pipeline hingga latensi DCN menjadi kurang berpengaruh pada throughput. Secara konkret, jika Anda memiliki N slice, pertimbangkan pipeline dengan kedalaman 2 dan N/2 replika paralelisme data, lalu pipeline dengan kedalaman 4 dan N/4 replika paralelisme data, dan seterusnya dengan cara yang sama, hingga batch per pipeline cukup besar sehingga kolektif DCN dapat disembunyikan di balik aritmetika dalam backward pass. Tindakan ini akan meminimalkan perlambatan yang disebabkan oleh paralelisme pipeline sekaligus memungkinkan Anda melakukan penskalaan di luar batas ukuran batch global.
Praktik terbaik multiris
Bagian berikut menjelaskan praktik terbaik untuk pelatihan Multislice.
Pemuatan data
Selama pelatihan, kita berulang kali memuat batch dari set data untuk dimasukkan ke dalam model. Memiliki pemuat data asinkron yang efisien yang membagi batch di seluruh host penting untuk menghindari kekurangan tugas TPU. Loader data saat ini di MaxText membuat setiap host memuat subset contoh yang sama. Solusi ini memadai untuk teks, tetapi memerlukan perubahan partisi dalam model. Selain itu, MaxText belum menawarkan pengambilan snapshot deterministik yang akan memungkinkan iterator data memuat data yang sama sebelum dan setelah penghentian sementara.
Checkpoint
Library pembuatan titik pemeriksaan Orbax menyediakan primitif untuk membuat titik pemeriksaan PyTree JAX ke penyimpanan lokal atau penyimpanan Google Cloud .
Kami menyediakan integrasi referensi dengan pembuatan titik pemeriksaan sinkron ke MaxText
di checkpointing.py.
Konfigurasi yang didukung
Bagian berikut menjelaskan bentuk slice, orkestrasi, framework, dan paralelisme yang didukung untuk Multi-slice.
Bentuk
Semua irisan harus memiliki bentuk yang sama (misalnya, AcceleratorType yang sama).
Bentuk irisan heterogen tidak didukung.
Orkestrasi
Orkestrasi didukung dengan GKE. Untuk mengetahui informasi selengkapnya, lihat TPU di GKE.
Framework
Multislice hanya mendukung workload JAX dan PyTorch.
Keparalelan
Sebaiknya pengguna menguji Multislice dengan paralelisme data. Untuk mempelajari lebih lanjut cara menerapkan paralelisme pipeline dengan Multislice, hubungi perwakilan akun Anda.Google Cloud
Dukungan dan Masukan
Kami menerima semua masukan. Untuk memberikan masukan atau meminta dukungan, hubungi kami menggunakan formulir Dukungan atau Masukan Cloud TPU.