Profile your model on Cloud TPU Nodes
Profiling your model enables you to optimize training performance on Cloud TPUs. To profile your model you use TensorBoard and the Cloud TPU TensorBoard plug-in. For installation instructions, see TensorBoard installation instructions.
For more information about using TensorBoard with one of the supported frameworks, see the following documents:
Prerequisites
TensorBoard is installed as part of TensorFlow. TensorFlow is installed by default in Cloud TPU Nodes. You can also install TensorFlow manually. Either way, some additional dependencies may be required. Install these by running:
(vm)$ pip3 install --user -r /usr/share/models/official/requirements.txt
Install Cloud TPU TensorBoard Plugin
SSH into your TPU Node:
$ gcloud compute ssh your-vm --zone=your-zone
Run the following commands:
pip3 install --upgrade "cloud-tpu-profiler>=2.3.0" pip3 install --user --upgrade -U "tensorboard>=2.3" pip3 install --user --upgrade -U "tensorflow>=2.3"
Capturing a profile
You can capture a profile using the TensorBoard UI or programmatically.
Capture a profile using TensorBoard
When you start TensorBoard, it starts a web server. When you point your browser to the TensorBoard URL, it displays a web page. The web page enables you to manually capture a profile and view the profile data.
Start the TensorFlow Profiler server
tf.profiler.experimental.server.start(6000)
This starts up the TensorFlow profiler server on your TPU VM.
Start your training script
Run your training script and wait until you see output indicating your model is
actively training. What this looks like depends on your code and model. Look for
output like Epoch 1/100. Alternatively, you can navigate to the Cloud TPU page
in the Google Cloud console, select your TPU and view the CPU utilization graph. While
this does not show TPU utilization, it is a good indication that the TPU is
training your model.
Start the TensorBoard server
Open a new terminal window and ssh into your TPU VM with port forwarding. This allows your local browser to communicate with the TensorBoard server running on your TPU VM.
gcloud compute tpus execution-groups ssh your-vm --zone=us-central1-a --ssh-flag="-4 -L 9001:localhost:9001"
Run TensorBoard in the terminal window you just opened and specify the directory
where TensorBoard can write profiling data with the --logdir flag. For example:
TPU_LOAD_LIBRARY=0 tensorboard --logdir your-model-dir --port 9001
TensorBoard starts a web server and displays its URL:
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all TensorBoard 2.3.0 at http://localhost:9001/ (Press CTRL+C to quit)
Open a web browser and go to the URL displayed in the TensorBoard output. Make sure TensorBoard has fully loaded the profiling data by clicking the reload button in the upper right hand corner of the TensorBoard page. By default the TensorBoard page comes up with the Scalars tab selected.
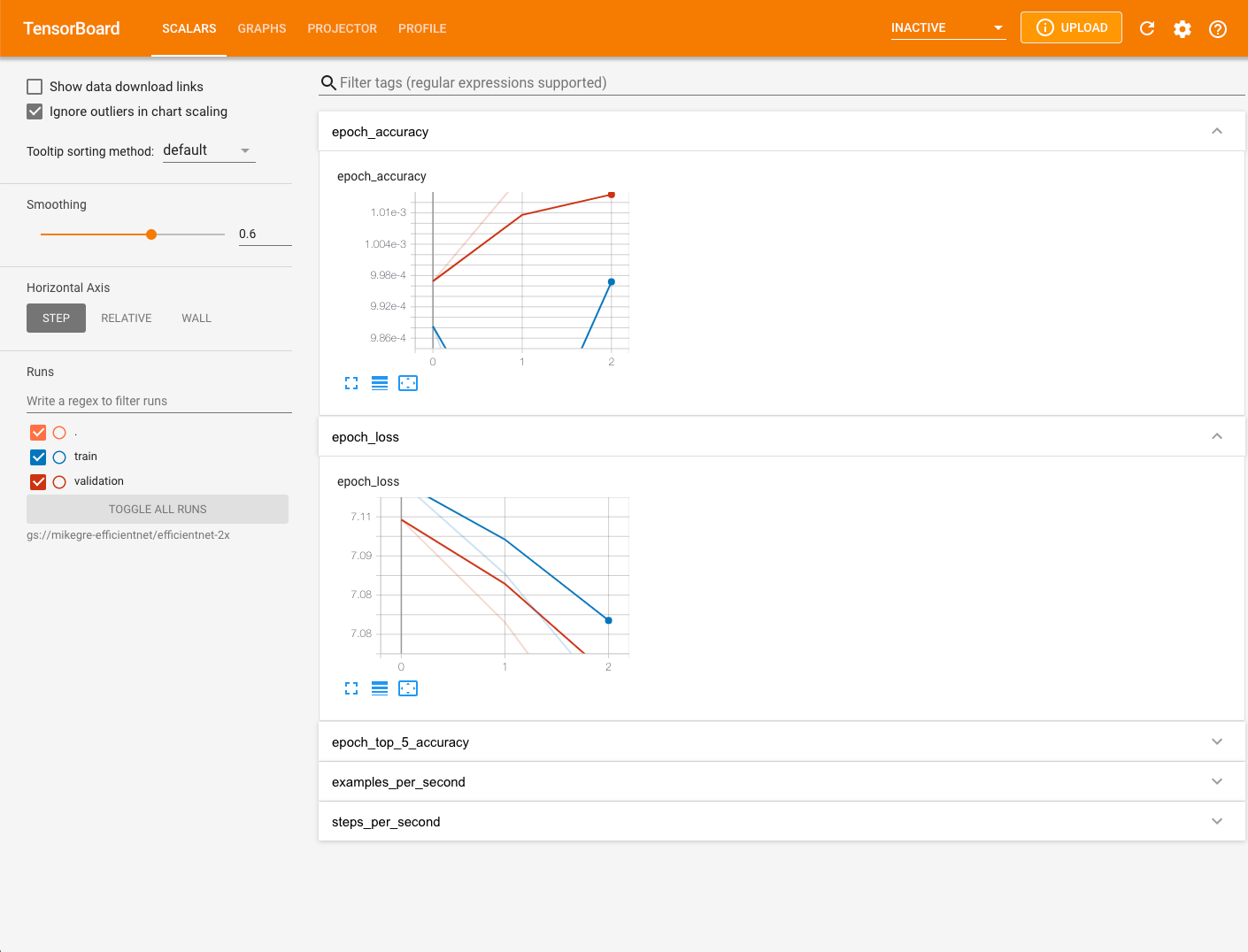
Capture a profile on TPU Nodes
- Select PROFILE from the dropdown menu at the top of the screen
- Select the CAPTURE PROFILE button
- Select the TPU Name radio button
- Type your TPU name
- Select the CAPTURE button
Capture a profile programmatically
How you programmatically capture a profile depends on what ML framework you are using.
If you are using TensorFlow, you start and stop the profiler using
tf.profiler.experimental.start() and tf.profiler.experimental.stop()
respectively. For more information, see TensorFlow performance guide.
If you are using JAX, use jax.profiler.start_trace() and jax.profiler.stop_trace()
to start and stop the profiler respectively. For more information, see Profiling JAX programs.
Capture profile common problems
Sometimes when you try to capture a trace you might see messages like the following:
No trace event is collected after xx attempt(s). Perhaps, you want to try again
(with more attempts?).Tip: increase number of attempts with --num_tracing_attempts.
Failed to capture profile: empty trace result
This can occur if the TPU is not actively performing calculations, a training step is taking too long, or other reasons. If you are seeing this message, try the following:
- Try to capture a profile after a few epochs have run.
- Try increasing the profiling duration in the TensorBoard Capture Profile dialog. It's possible that a training step is taking too long.
- Make sure both VM and TPU have the same TF version.
View profile data with TensorBoard
The Profile tab is displayed after you have captured some model data. You may need to click the reload button in the upper right hand corner of the TensorBoard page. Once data is available, clicking on the Profile tab presents a selection of tools to help with performance analysis:
- Overview page
- Trace viewer (Chrome browser only)
- Streaming trace viewer (Chrome browser only)
Trace viewer
Trace viewer is a Cloud TPU performance analysis tool available under Profile. The tool uses the Chrome trace event profiling viewer so it only works in the Chrome browser.
Trace viewer displays a timeline that shows:
- Durations for the operations that were executed by your TensorFlow model .
- Which part of the system (TPU or host machine) executed an operation. Typically, the host machine executes infeed operations, which preprocesses training data and transfers it to the TPU, whereas the TPU executes the actual model training.
Trace viewer allows you to identify performance problems in your model, then take steps to resolve them. For example, at a high level, you can identify whether infeed or model training is taking the majority of the time. Drilling down, you can identify which TensorFlow operations are taking the longest to execute.
Note that trace viewer is limited to 1M events per Cloud TPU. If you need to assess more events, use the streaming trace viewer instead.
Trace viewer interface
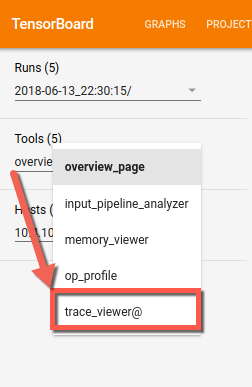
To open trace viewer, go to TensorBoard, click on the Profile tab at the top of the screen, and choose trace_viewer from the Tools dropdown. The viewer appears displaying your most recent run:

This screen contains the following main elements (marked with numbers above):
- Runs dropdown. Contains all of the runs for which you've captured trace information. The default view is your most recent run, but you can open the dropdown to select a different run.
- Tools dropdown. Selects different profiling tools.
- Host dropdown. Selects a host that contains a Cloud TPU set.
- Timeline pane. Shows operations that Cloud TPU and the host machine executed over time.
- Details pane. Shows additional information for operations selected in the Timeline pane.
Here's a closer look at the timeline pane:

The Timeline pane contains the following elements:
- Top bar. Contains various auxiliary controls.
- Time axis. Shows time relative to the beginning of the trace.
- Section and track labels. Each section contains multiple tracks and has a triangle on the left that you can click to expand and collapse the section. There is one section for every processing element in the system.
- Tool selector. Contains various tools for interacting with the trace viewer.
- Events. These show the time during which an operation was executed or the duration of meta-events, such as training steps.
- Vertical tab bar. This does not have a useful purpose for Cloud TPU. The bar is part of the general purpose trace viewer tool provided by Chrome that is used for a variety of performance analysis tasks.
Sections and tracks
Trace viewer contains the following sections:
- One section for each TPU node, labeled with the number of the TPU chip
and the TPU node within the chip (for example, "Chip 2: TPU Core 1"). Each
TPU node section contains the following tracks:
- Step. Shows the duration of the training steps that were running on the TPU.
- TensorFlow Ops. Shows TensorFlow operations executed on the TPU.
- XLA Ops. Shows XLA operations that ran on the TPU. (Each operation is translated into one or several XLA operations. The XLA compiler translates the XLA operations into code that runs on the TPU.)
- One section for threads running on the host machine's CPU, labeled "Host Threads". The section contains one track for each CPU thread. Note: You can ignore the information displayed alongside the section labels.
Timeline tool selector
You can interact with the timeline view using the timeline tool selector in TensorBoard. You can click on a timeline tool or use the following keyboard shortcuts to activate and highlight a tool. To move the timeline tool selector, click in the dotted area at the top and then drag the selector to where you want it.
Use the timeline tools as follows:
|
Selection tool Click on an event to select it or drag to select multiple events. Additional information about the selected event or events (name, start time, and duration) will be displayed in the details pane. |
|
Pan tool Drag to pan the timeline view horizontally and vertically. |
|
Zoom tool Drag up to zoom in or drag down to zoom out along the horizontal (time) axis. The horizontal position of the mouse cursor determines the center around which the zoom takes place. Note: The zoom tool has a known bug where zoom remains active if you release the mouse button while the mouse cursor is outside the timeline view. If this happens to you, just click briefly on the timeline view to stop zooming. |
|
Timing tool Drag horizontally to mark a time interval. The length of the interval appears on the time axis. To adjust the interval, drag its ends. To clear the interval, click anywhere inside the timeline view. Note that the interval remains marked if you select one of the other tools. |




Graphs
TensorBoard provides a number of visualizations, or graphs, of your model and its performance. Use the graphs together with the trace viewer or streaming trace viewer to fine tune your models and improve their performance on Cloud TPU.
Model graph
The modeling framework may generate a
graph from your model. The data for the graph is stored in the MODEL_DIR
directory in the storage bucket you specify with the --logdir
parameter. You can view this graph without running capture_tpu_profile.
To view a model's graph, select the Graphs tab in TensorBoard.
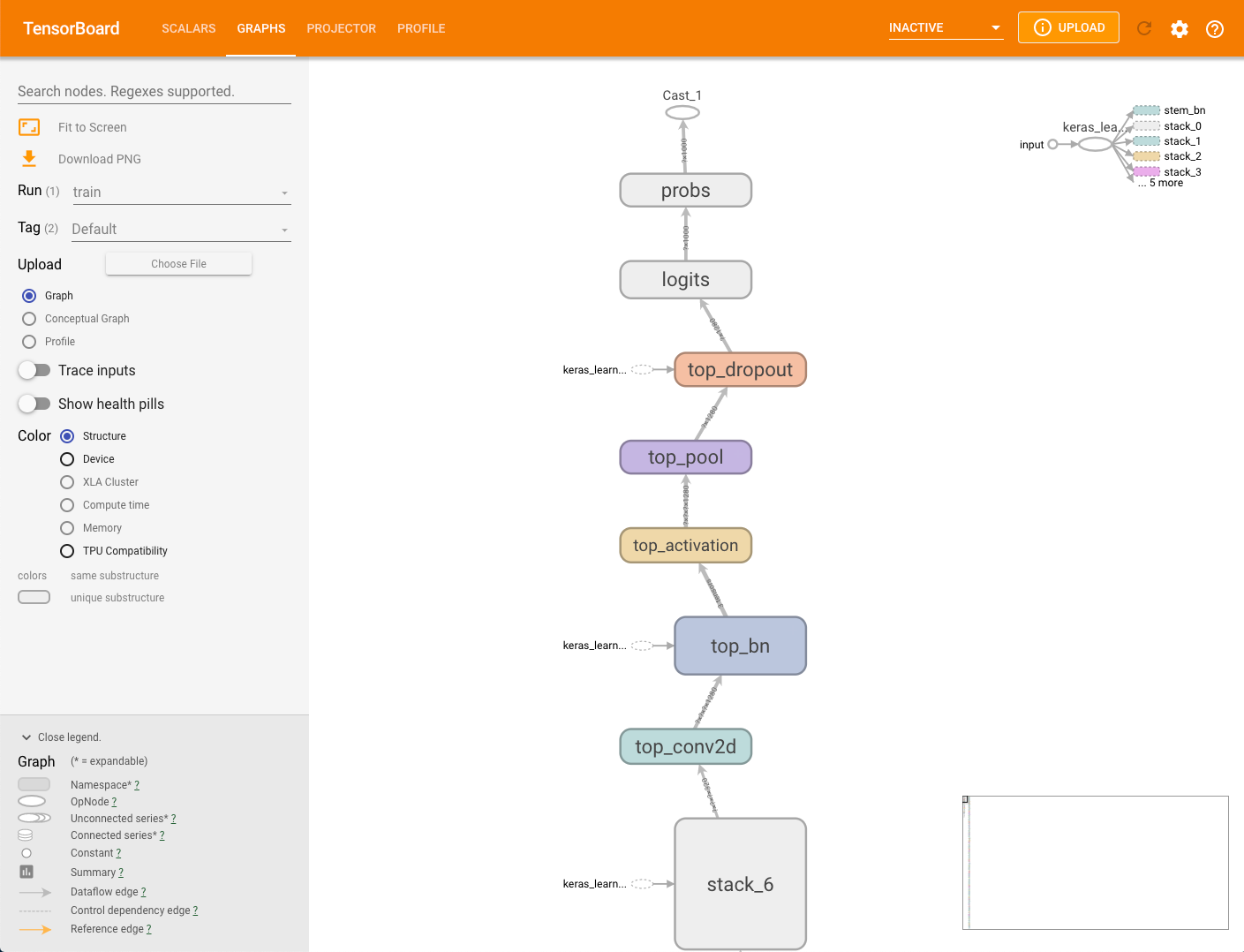
A single node in the structure graph represents a single operation.
TPU compatibility graph
The Graphs tab includes a compatibility checker module which checks for and displays ops that can potentially cause issues when a model is run.
To view a model's TPU compatibility graph, select the Graphs tab in TensorBoard and then select the TPU Compatibility option. The graph presents the compatible (valid) operations in green and the incompatible (invalid) operations in red.
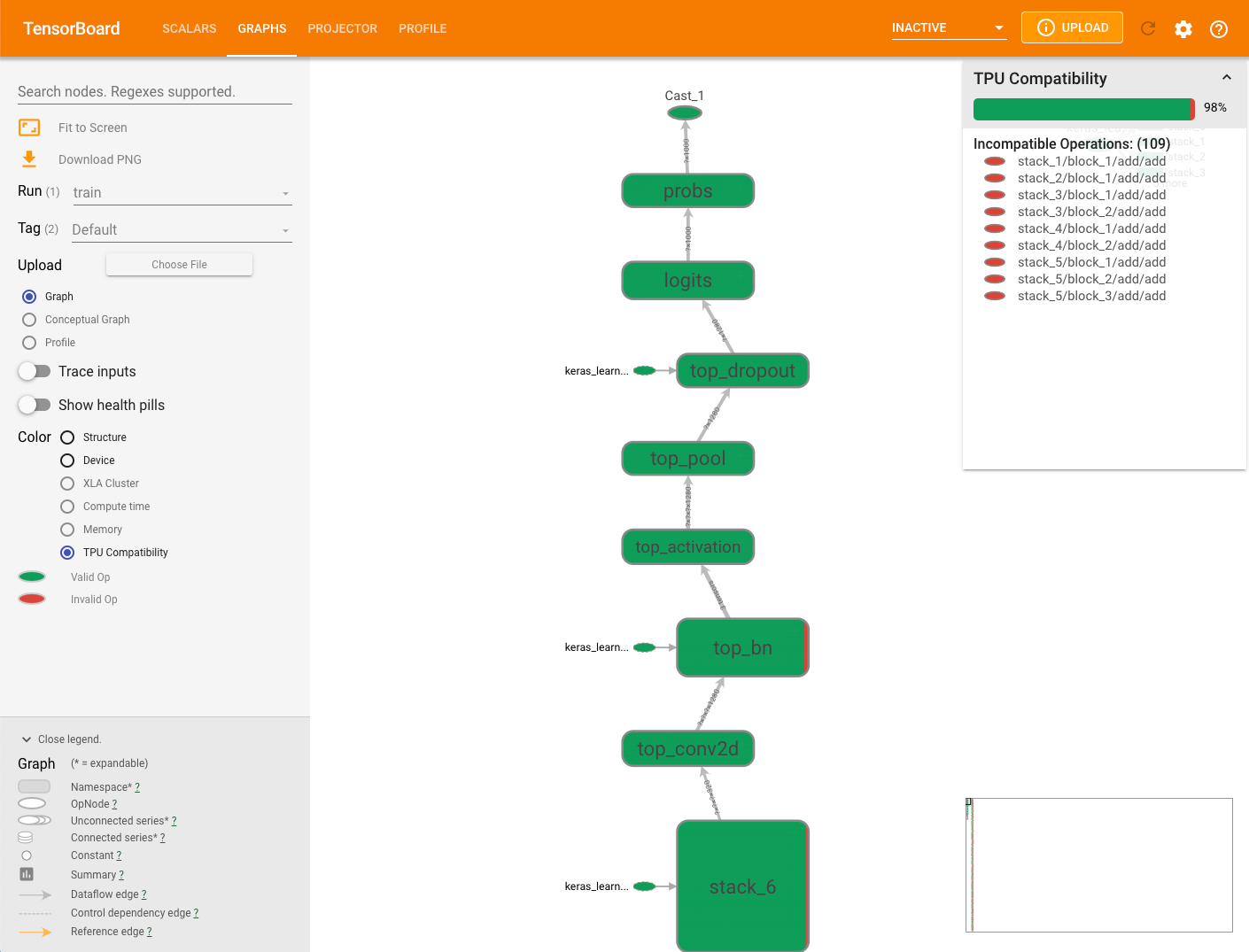
A given node can display both colors, each as a percentage of the Cloud TPU compatibility operations for that node. See Interpreting compatibility results for an example.
The compatibility summary panel displayed to the right of the graph shows the percentage of all Cloud TPU-compatible operations, their attributes and a list of incompatible operations for a selected node.
Click on any operation in the graph to display its attributes in the summary panel.
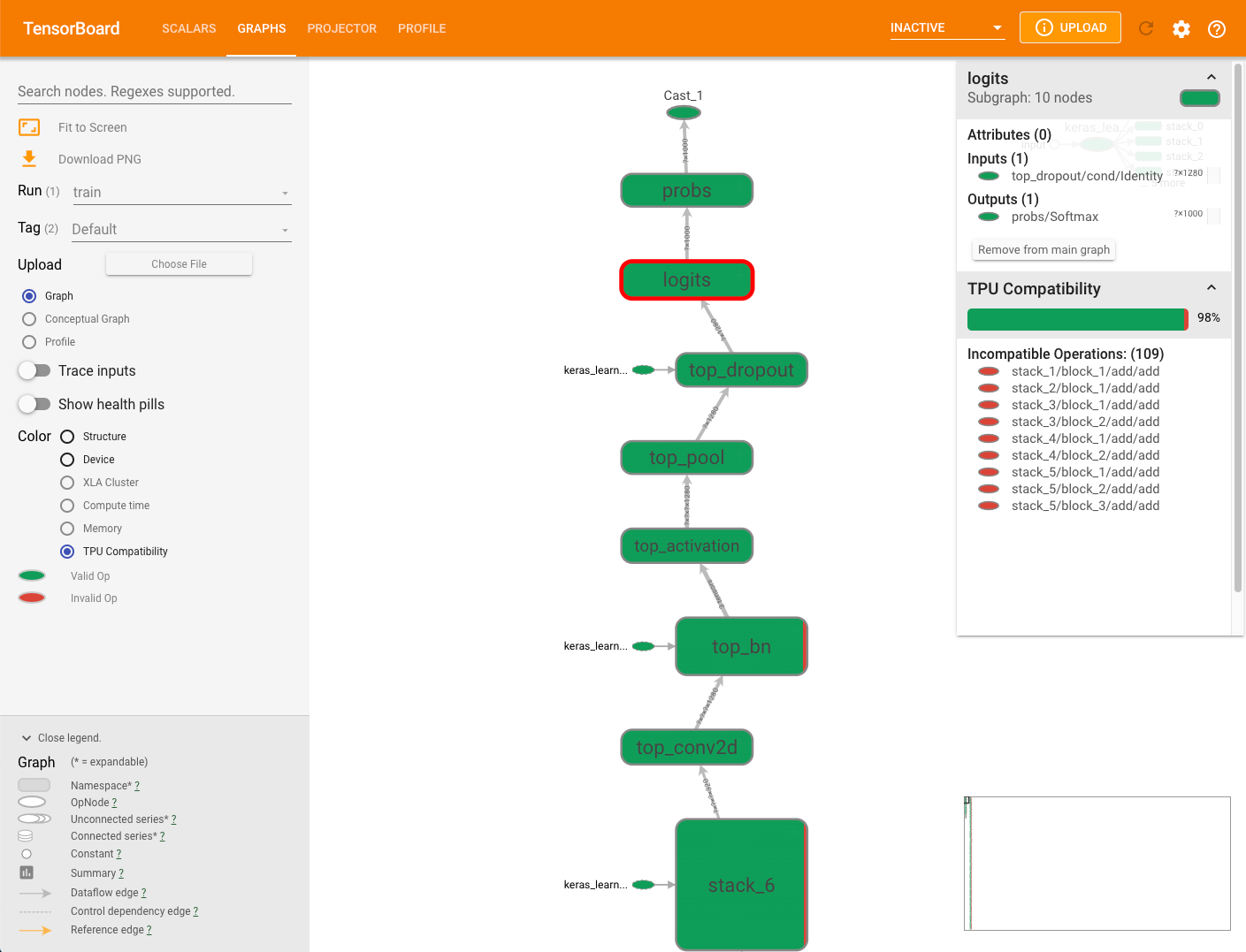
Note that compatibility checker does not assess any operations that are explicitly assigned to a non-TPU device using manual device placement. In addition, the checker does not actually compile the model for execution, so be sure to interpret the results as an estimate of compatibility.
Interpreting compatibility results
Profile
The Profile tab, is displayed after you have captured some model data. You may need to click the reload button in the upper right hand corner of the TensorBoard page. Once data is available, clicking on the Profile tab presents a selection of tools to help with performance analysis:
- Overview page
- Input pipeline analyzer
- XLA Op profile
- Trace viewer (Chrome browser only)
- Memory viewer
- Pod viewer
- Streaming trace viewer (Chrome browser only)
Profile overview page
The overview page (overview_page), available under Profile, provides a top level view of how your model performed during a capture run. The page shows you an aggregated overview page for all the TPUs, as well as an overall input pipeline analysis. There is an option for selecting individual TPUs in the Host drop-down.
The page displays data in the following panels:

Performance summary
- Average Step Time - The step time averaged over all sampled steps
- Host Idle Time - The percentage of time the Host was idle
- TPU Idle Time - The percentage of time the TPU was idle
- FLOPS Utilization - The percentage utilization of the TPU matrix units
- Memory Bandwidth Utilization - The percentage of memory bandwidth used
Step-time graph. Displays a graph of device step time (in milliseconds) over all the steps sampled. The blue area corresponds to the portion of the step time the TPUs were sitting idle waiting for input data from the host. The red area shows how much of time the Cloud TPU was actually working.
Top 10 TensorFlow operations on TPU. Displays the TensorFlow operations that consumed the most time:
Each row displays an operation's self time (as the percentage of time taken by all operations), cumulative time, category, name, and the FLOPS rate achieved.
Run environment
- Number of hosts used
- Type of TPU used
- Number of TPU cores
- Training batch size
Recommendation for next steps. Reports when a model is input bound and whenever issues with Cloud TPU occur. Suggests tools you can use to locate performance bottlenecks in performance.
Input pipeline analyzer
The input pipeline analyzer provides insights into your performance results. The
tool displays performance results from the input_pipeline.json file
that is collected by the capture_tpu_profile tool.
The tool tells you immediately whether your program is input bound and can walk you through device and host-side analysis to debug whatever stage(s) of the pipeline are creating bottlenecks.
See the guidance on input pipeline performance for deeper insight into optimizing pipeline performance.
Input pipeline
When a TensorFlow program reads data from a file it begins at the top of the TensorFlow graph in a pipelined manner. The read process is divided into multiple data processing stages connected in series, where the output of one stage is the input to the next one. This system of reading is called the input pipeline.
A typical pipeline for reading records from files has the following stages:
- File reading
- File preprocessing (optional)
- File transfer from the host machine to the device
An inefficient input pipeline can severely slow down your application. An application is considered input bound when it spends a significant portion of time in its input pipeline. Use the input pipeline analyzer to understand where the input pipeline is inefficient.
Input pipeline dashboard
To open the input pipeline analyzer, select Profile, then select input_pipeline_analyzer from the Tools dropdown.
The dashboard contains three sections:
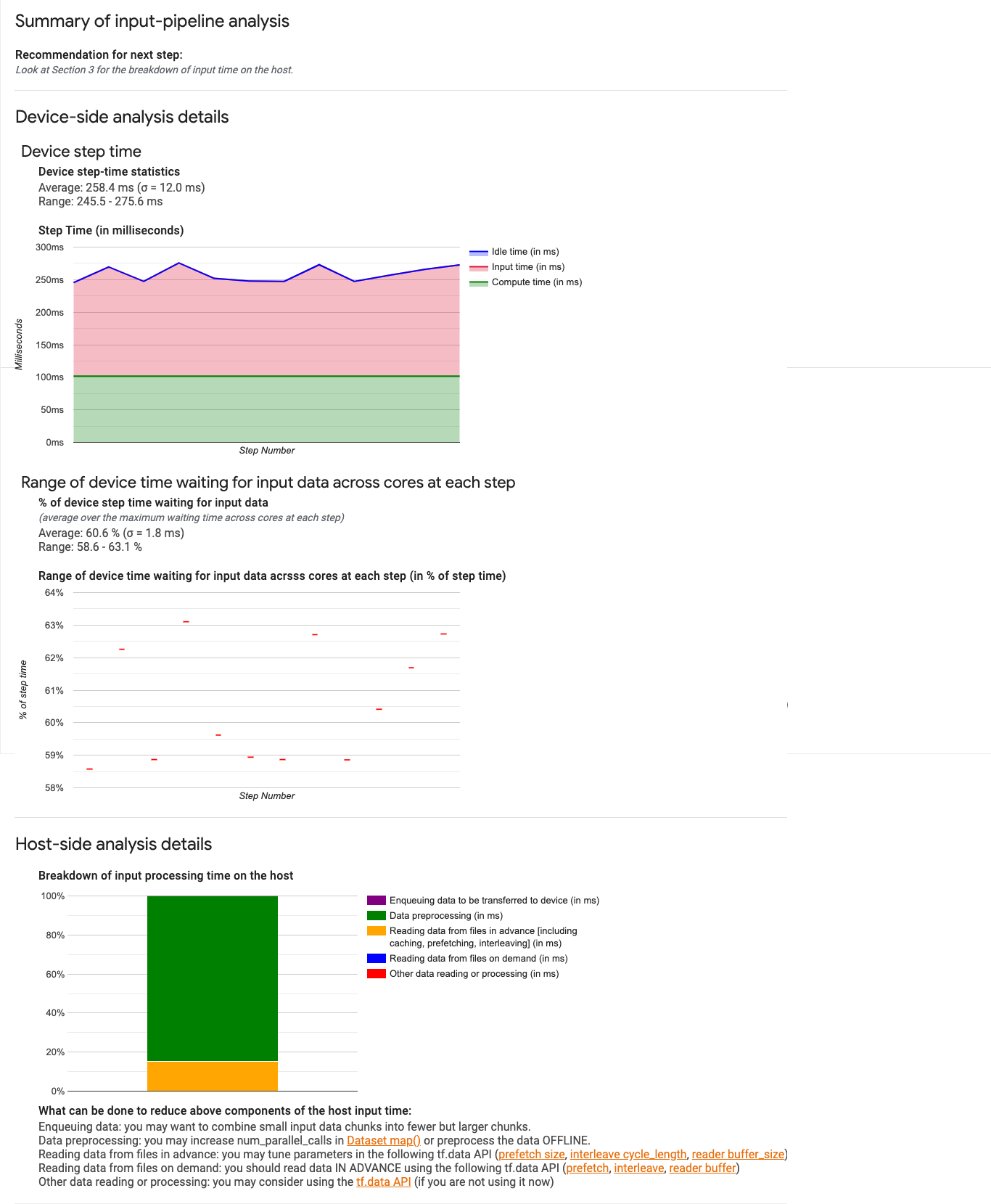
- Summary. Summarizes the overall input pipeline with information on whether your application is input bound and, if so, by how much.
- Device-side analysis. Displays detailed, device-side analysis results, including the device step-time and the range of device time spent waiting for input data across cores at each step.
- Host-side analysis. Shows a detailed analysis on the host side, including a breakdown of input processing time on the host.
Input pipeline summary
The first section reports if your program is input bound by presenting the percentage of device time spent on waiting for input from the host. If you are using a standard input pipeline that has been instrumented, the tool reports where most of the input processing time is spent. For example:

Device-side analysis
The second section details the device-side analysis, providing insights on time spent on the device versus on the host and how much device time was spent waiting for input data from the host.
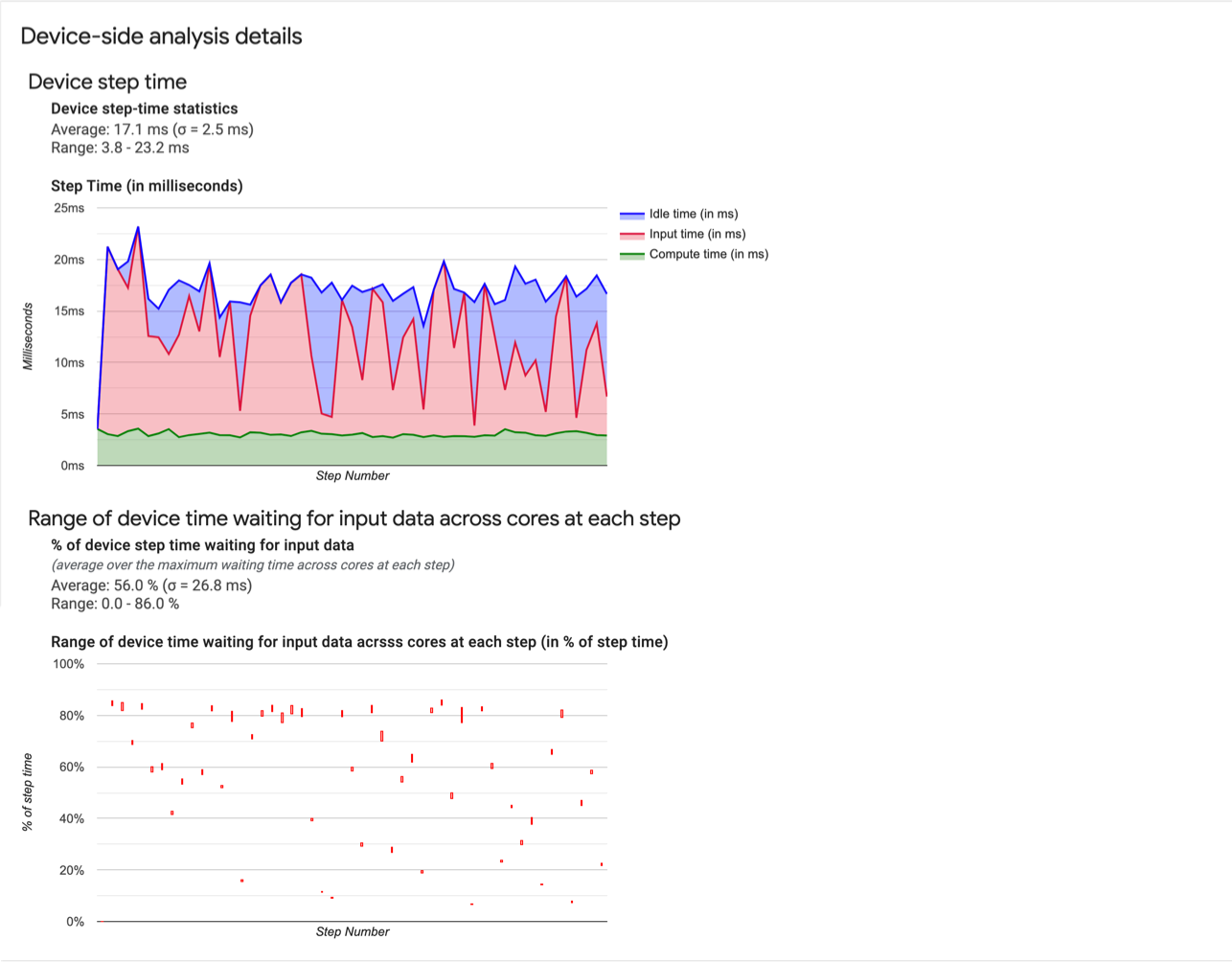
- Device step time statistics. Reports the average, standard deviation, and range (minimum, maximum) of the device step time.
- Step time. Displays a graph of device step time (in milliseconds) over all the steps sampled. The blue area corresponds to the part of the step time Cloud TPUs sat idle waiting for input data from the host. The red area shows how much of time the Cloud TPU was actually working.
- Percentage of time waiting for input data. Reports the average, standard deviation and the range (minimum, maximum) of the fraction of time spent on a device waiting for the input data normalized to the total device step time.
- Range of device time across cores spent waiting for input data, by step number. Displays a line chart showing the amount of device time (expressed as a percentage of total device step time) spent waiting for input data processing. The fraction of time spent varies from core to core, so the range of fractions for each core is also plotted for each step. Since the time a step takes is determined by the slowest core, you want the range to be as small as possible.
Host-side analysis
Section 3 shows the details of host-side analysis, reporting of the input processing time (the time spent on Dataset API operations) on the host broken into several categories:
- Enqueuing data to be transferred to device Time spent putting data into an infeed queue before transferring the data to the device.
- Data preprocessing. Time spent on preprocessing operations, such as image decompression.
- Reading data from files in advance. Time spent reading files, including caching, prefetching, and interleaving.
- Reading data from files on demand. Time spent on reading data from files without caching, prefetching, and interleaving.
- Other data reading or processing. Time spent on other input related operations
not using
tf.data.

To see the statistics for individual input operations and their categories broken down by execution time, expand the "Show Input Op statistics" section.
A source data table like the following appears:

Each table entry contains the following information:
- Input Op. Shows the TensorFlow op name of the input operation.
- Count. Shows the total number of instances of the operation executed during the profiling period.
- Total Time (in ms). Shows the cumulative sum of time spent on each of operation instances.
- Total Time %. Shows the total time spent on an operation as a fraction of the total time spent in input processing.
- Total Self Time (in ms). Shows the accumulative sum of the self time
spent on each of those instances. The self time measures the time spent
inside the function body, excluding the time spent in the function it calls.
For example, the
Iterator::PaddedBatch::Filter::ForeverRepeat::Mapis called byIterator::PaddedBatch::Filter, therefore it's total self time is excluded from the total self time of the latter. - Total Self Time %. Shows the total self time as a fraction of the total time spent on input processing.
- Category. Shows the processing category of the input operation.
Op profile
Op profile is a Cloud TPU tool that displays the performance statistics of XLA operations executed during a profiling period. The op profile shows:
- How well your application uses the Cloud TPU as a percentage of time spent on operations by category and of TPU FLOPS utilization.
- The most time-consuming operations. Those operations are potential targets for optimization.
- Details of individual operations, including shape, padding and expressions that use the operation.
You can use op profile to find good targets for optimization. For example, if your model achieves only 5% of the TPU peak FLOPS, you can use the tool to identify which XLA operations are taking the longest time to execute and how many TPU FLOPS they consume.
Using op profile
During profile collection, capture_tpu_profile also creates
a op_profile.json file that contains performance statistics of XLA operations.
You can view the data from op_profile in TensorBoard by clicking on the Profile tab at the top of the screen and then selecting op_profile from the Tools dropdown. You will see a display like this:

- Overview section. Shows Cloud TPU utilization and provides suggestions for optimization.
- Control panel. Contains controls that allow you to set the number of operations displayed in the table, which operations are displayed, and how they are sorted.
- Op table. A table that lists the top TensorFlow operation categories associated with the XLA ops. These operations are sorted by percentage of Cloud TPU usage.
- Op details cards. Details about the op that appear when you hover over an op in the table. These include the FLOPS utilization, the expression in which the op is used, and the op layout (fit).
XLA Op table
The Op table lists XLA operation categories in order from the highest to lowest percentage of Cloud TPU usage. Initially, the table shows the percentage of time taken, the op category name, the associated TensorFlow op name, and the percentage of FLOPS utilization for the category. To display (or hide) the 10 most time-consuming XLA operations for a category, click the triangle next to the category name in the table.

- Time. Shows the total percentage of time spent by all the operations in that category. You can click to expand the entry and see the breakdown of time spent by each individual operation.
- Top10 Ops. The toggle next to a category's name displays/hides the top 10 time-consuming operations within the category. If a fusion operation entry is displayed in the operations list, you can expand it to see the non-fusion, elementwise operations it contains.
- TensorFlow Op. Shows the TensorFlow op name associated with the XLA operation.
- FLOPS. Shows the FLOPS utilization, which is the measured number of FLOPS expressed as a percentage of the Cloud TPU peak FLOPS. The higher the FLOPS utilization percentage, the faster operations run. The table cell is color coded: green for high FLOPS utilization (good) and red for low FLOPS utilization (bad).
Op details cards
When you select a table entry, a card appears on the left displaying details about the XLA op or the operation category. A typical card looks like this:

- Name and Category. Shows the highlighted XLA operation name and category.
- FLOPS utilization. Displays FLOPS utilization as a percentage of total FLOPS possible.
- Expression. Shows the XLA expression containing the operation.
- Memory Utilization. Displays the percentage of peak memory usage by your program.
- Layout (Convolution operations only.) Shows the shape and layout of a tensor, including whether the shape of the tensor is an exact fit for the matrix units and how the matrix is padded.
Interpreting results
For convolution operations, TPU FLOPS utilization can be low due to one or both of the following reasons:
- padding (matrix units are partially used)
- convolution op is memory bound
This section gives an interpretation of some numbers from a different model in which FLOPs were low. In this example, output fusion and convolution dominated the execution time and there was a long tail of vector or scalar operations that had very low FLOPS.
One optimization strategy for this type of profile is to transform the vector or scalar operations to convolution operations.
In the following example, %convolution.399 shows lower FLOPS and memory utilization than %convolution.340 in the previous example.

Examine the layout and note that batch size 16 is being padded to 128 and feature size 3 is being padded to 8, which indicates that only 5% of the matrix units are being effectively used. (The calculation for this instance of percent utilization is (((batch_time * num_of_features) / padding_size ) / num_of_cores). Compare the FLOPS in this example to the %convolution.340 in the previous example which has an exact fit to the matrix.
Pod viewer
The Pod viewer tool provides performance visualizations for every core in a slice and displays the status of the communications channels across the cores in a slice. Pod viewer can identify and highlight potential bottlenecks and areas that need optimization. The tool works for full Pods and all v2 and v3 slices.
To display the Pod viewer tool:
- Select Profile from the menu button at the top right side of the TensorBoard window.
- Click the Tools menu on the left side of the window and select pod_viewer.
The Pod viewer user interface includes:
- A step slider, which lets you to select which step you want to examine.
- A topology graph, which interactively visualizes your TPU cores in the whole TPU system.
- A communication links chart, which visualizes the send and receive (recv) channels in the topology graph.
- A latency of send and recv channels bar chart. Hovering over a bar in this chart activates the communication links in the communication links chart. A channel details card appears on the left-hand bar, providing detailed information of the channel, such as the size of data transferred, latency, and bandwidth.
- A step breakdown chart, which visualizes a breakdown of a step for all cores. This can be used to track system bottlenecks and whether a particular core is slowing down the system.
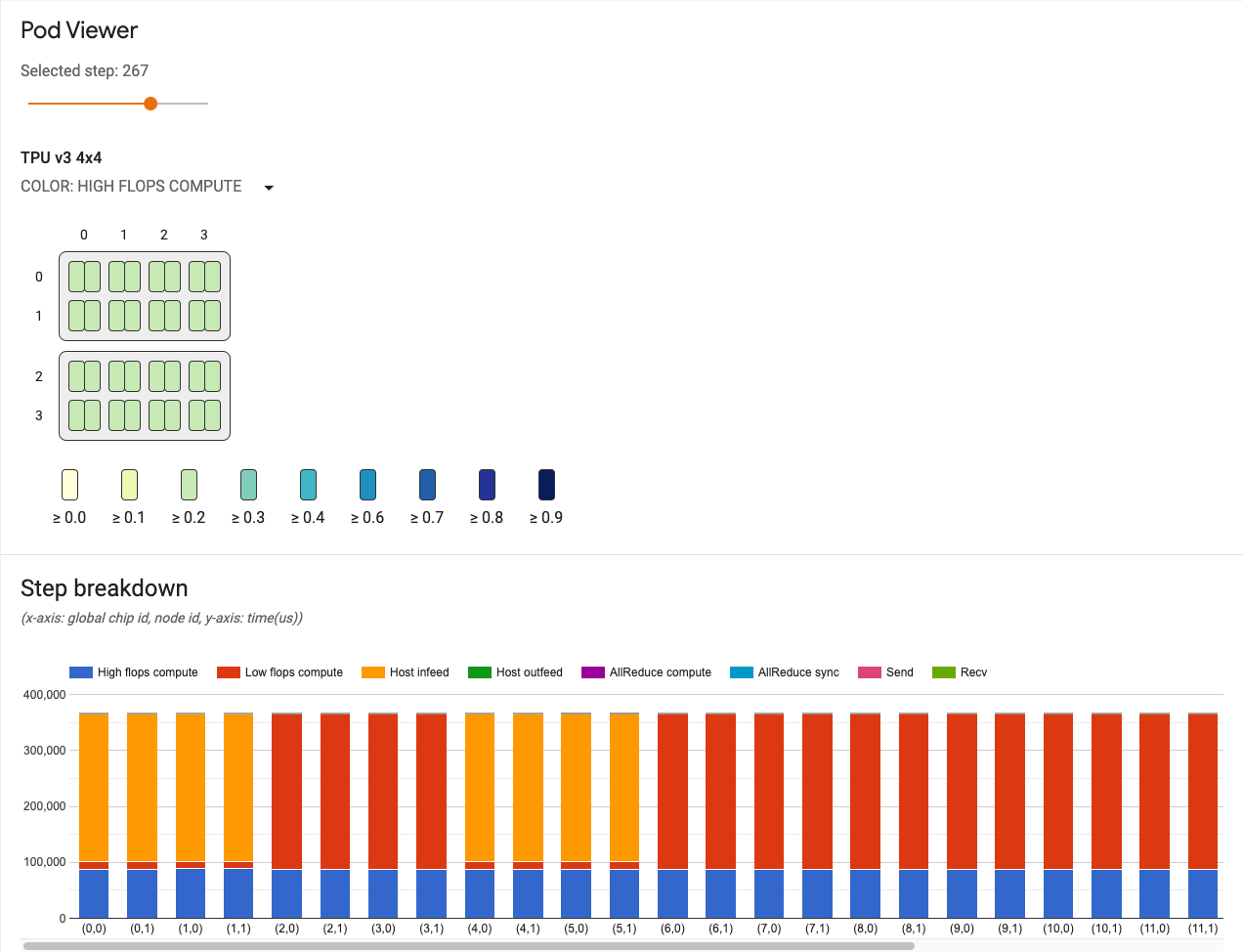
Step slider
Use the slider to select a step. The rest of the tool displays statistics, such as step breakdown and communication links, for that step.
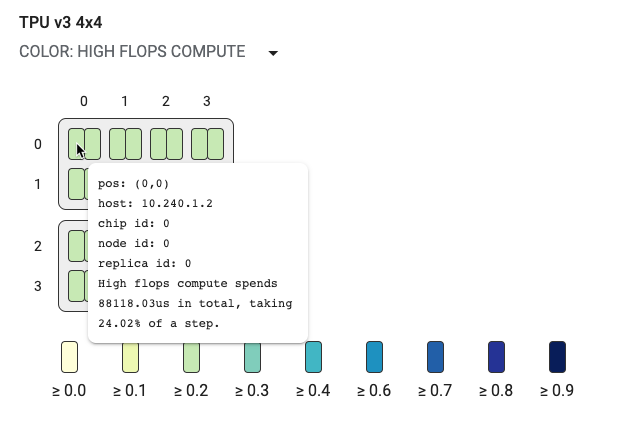
Topology graph
The topology graph is organized hierarchically by host, chip and core. The smallest rectangles are TPU cores. Two cores together indicate a TPU chip and four chips together indicate a host.
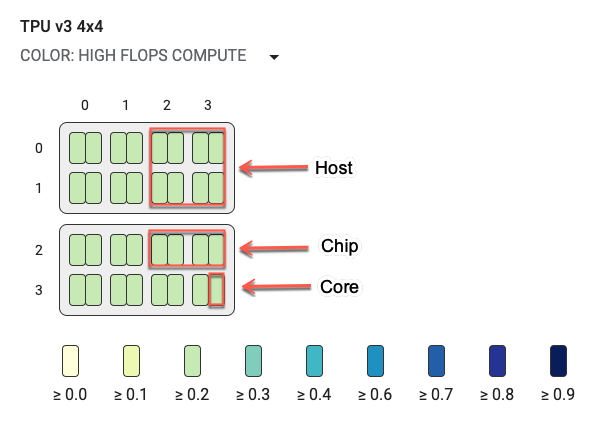
The topology graph is also a heatmap, color coded by the percentage of time a particular breakdown (for example, High flops compute, infeed, send, etc.) takes in the selected step. The bar just below the topology graph (shown in the following graphic) shows a color coding for core and chip usage. The color of the cores show the utilization ranging from yellow to blue. For High flops compute, larger numbers (darker color) indicate more time spent doing compute. For all other breakdowns, smaller numbers (lighter colors) indicate smaller wait times. Potential problem areas, or hotspots, are indicated when a core is darker than the others.
Click the pulldown menu selector next to the system name (circled in the diagram) to choose the particular type of breakdown you want to examine.
Hold the pointer over any of the small rectangles (single cores) to display a techtip showing the core's position in the system, its global chip ID, and its hostname. The techtip also includes the duration of the selected breakdown category, for example High flops, and its utilization percentage out of a step.
Communication channels
This tool helps visualize send and recv links if your model uses them to communicate between cores. When your model contains send and recv ops, you can use a channel ID selector to select a channel ID. A link from the source (src) core and destination (dst) core, represents the communication channel. It is rendered on the topology graph by hovering your mouse over the bars on the chart showing the latency of send and recv channels.

A card appears on the left-hand bar giving you more details about the communication channel. A typical card looks like this:
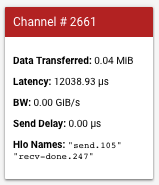
- Data Transferred, which shows the data transferred by the send and recv channel in memibytes (MiB).
- Latency, which shows the duration, in microseconds, from the start of the send event to the end of the recv-done event.
- BW, which shows the amount of data transferred, in gibibites (GiB), from the source core to the destination core in the duration of time.
- Send Delay, which is the duration from the beginning of the recv-done to the beginning of send in microseconds. If the recv-done op starts after the beginning of the send op, the delay is zero.
- Hlo Names, which displays the XLA hlo ops names associated with this channel. These hlo names are associated with the statistics displayed in other TensorBoard tools such as op_profile and memory_viewer.
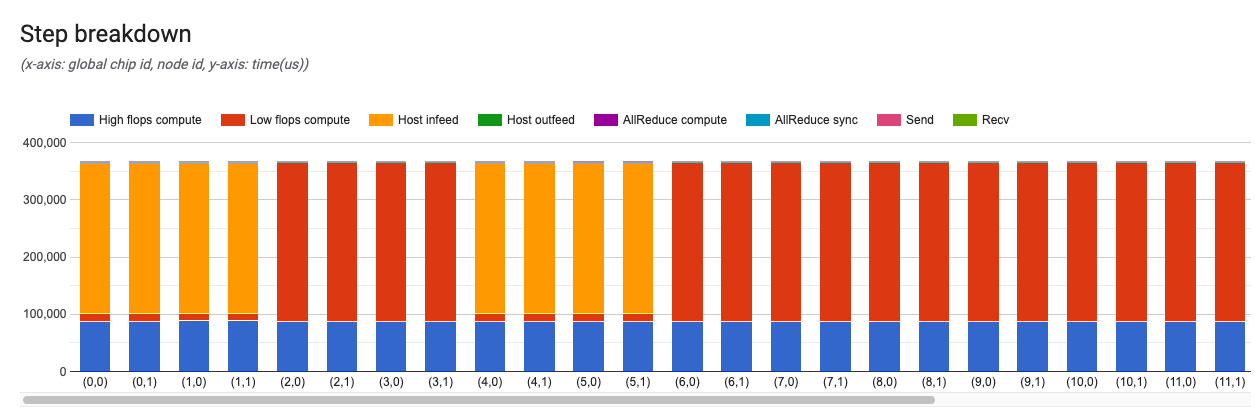
Step breakdown chart
This chart provides details for each training or evaluation step.
The x-axis is the global chip ID and the y-axis is the time in microseconds. From this chart, you can see where the time is used in a particular training step, where any bottlenecks are, and whether there is a load imbalance across all chips.
A card appears on the left-hand bar giving you more details about the step breakdown. A typical card looks like this:
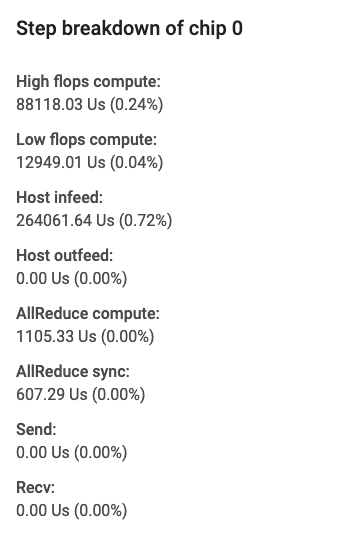
The fields in the card specify the following:
- High Flops Compute, which is the time spent on convolution or output fusion operations (ops).
- Low flops compute, which is calculated by deducting all other breakdowns from the total duration.
- Infeed, which is the time the TPU spends waiting on the host.
- Outfeed, which is the time the host spends waiting on output from the TPU.
- AllReduce sync, which is the portion of time spent on CrossReplicaSum ops that is waiting to synchronize with other cores. CrossReplicaSum ops computes the sum across replicas.
- AllReduce compute, which is the actual compute time spent on CrossReplicaSum ops.
- Chip to chip send ops, which is the time spent on send operations.
- Chip to chip recv-done ops, which is the time spent on recv operations.
Trace viewer
Trace viewer is a Cloud TPU performance analysis tool available under Profile. The tool uses the Chrome trace event profiling viewer so it only works in the Chrome browser.
Trace viewer displays a timeline that shows:
- Durations for the operations that were executed by your TensorFlow model.
- Which part of the system (TPU or host machine) executed an operation. Typically, the host machine executes infeed operations, which preprocesses training data and transfers it to the TPU, whereas the TPU executes the actual model training.
Trace viewer lets you to identify performance problems in your model, then take steps to resolve them. For example, at a high level, you can identify whether infeed or model training is taking the majority of the time. Drilling down, you can identify which TensorFlow operations are taking the longest to execute.
Note that trace viewer is limited to 1M events per Cloud TPU. If you need to assess more events, use the streaming trace viewer instead.
Trace viewer interface
To open trace viewer, go to TensorBoard, click the Profile tab at the top of the screen, and choose trace_viewer from the Tools drop-down. The viewer appears displaying your most recent run:
This screen contains the following main elements (marked with numbers above):
- Runs dropdown. Contains all of the runs for which you've captured trace information. The default view is your most recent run, but you can open the dropdown to select a different run.
- Tools dropdown. Selects different profiling tools.
- Host dropdown. Selects a host that contains a Cloud TPU set.
- Timeline pane. Shows operations that Cloud TPU and the host machine executed over time.
- Details pane. Shows additional information for operations selected in the Timeline pane.
Here's a closer look at the timeline pane:
The Timeline pane contains the following elements:
- Top bar. Contains various auxiliary controls.
- Time axis. Shows time relative to the beginning of the trace.
- Section and track labels. Each section contains multiple tracks and has a triangle on the left that you can click to expand and collapse the section. There is one section for every processing element in the system.
- Tool selector. Contains various tools for interacting with the trace viewer.
- Events. These show the time during which an operation was executed or the duration of meta-events, such as training steps.
- Vertical tab bar. This does not have a useful purpose for Cloud TPU. The bar is part of the general purpose trace viewer tool provided by Chrome that is used for a variety of performance analysis tasks.
Sections and tracks
Trace viewer contains the following sections:
- One section for each TPU node, labeled with the number of the TPU chip
and the TPU node within the chip (for example, "Chip 2: TPU Core 1"). Each
TPU node section contains the following tracks:
- Step. Shows the duration of the training steps that were running on the TPU.
- TensorFlow Ops. Shows TensorFlow operations executed on the TPU.
- XLA Ops. Shows XLA operations that ran on the TPU. (Each operation is translated into one or several XLA operations. The XLA compiler translates the XLA operations into code that runs on the TPU.)
- One section for threads running on the host machine's CPU, labeled "Host Threads". The section contains one track for each CPU thread. Note: You can ignore the information displayed alongside the section labels.
Timeline tool selector
You can interact with the timeline view using the timeline tool selector in TensorBoard. You can click on a timeline tool or use the following keyboard shortcuts to activate and highlight a tool. To move the timeline tool selector, click in the dotted area at the top and then drag the selector to where you want it.
Use the timeline tools as follows:
|
Selection tool Click on an event to select it or drag to select multiple events. Additional information about the selected event or events (name, start time, and duration) will be displayed in the details pane. |
|
Pan tool Drag to pan the timeline view horizontally and vertically. |
|
Zoom tool Drag up to zoom in or drag down to zoom out along the horizontal (time) axis. The horizontal position of the mouse cursor determines the center around which the zoom takes place. Note: The zoom tool has a known bug where zoom remains active if you release the mouse button while the mouse cursor is outside the timeline view. If this happens to you, just click briefly on the timeline view to stop zooming. |
|
Timing tool Drag horizontally to mark a time interval. The length of the interval appears on the time axis. To adjust the interval, drag its ends. To clear the interval, click anywhere inside the timeline view. Note that the interval remains marked if you select one of the other tools. |
Events
Events within the timeline are displayed in different colors; the colors themselves have no specific meaning.
Timeline top bar
The top bar of the Timeline pane contains several auxiliary controls:

- Metadata display. Not used for TPUs.
- View Options. Not used for TPUs.
- Search box. Enter text to search for all events whose name contains the text. Click the arrow buttons to the right of the search box to move forwards and backwards through the matching events, selecting each event in turn.
- Console button. Not used for TPUs.
- Help button. Click to display a help summary.
Keyboard shortcuts
Following are the keyboard shortcuts you can use in trace viewer. Click the help button (?) in the top bar to see more keyboard shortcuts.
w Zoom in
s Zoom out
a Pan left
d Pan right
f Zoom to selected event(s)
m Mark time interval for selected event(s)
1 Activate selection tool
2 Activate pan tool
3 Activate zoom tool
4 Activate timing toolThe f shortcut can be highly useful. Try selecting a step and pressing f to zoom into the step quickly.
Characteristic events
Following are some of the event types that can be very useful when analyzing TPU performance.

InfeedDequeueTuple. This TensorFlow operation runs on a TPU and receives input data coming from the host. When infeed takes a long time, it can mean that the TensorFlow operations which preprocess the data on the host machine cannot keep up with the TPU data consumption rate. You can see corresponding events in the host traces called InfeedEnqueueTuple. To view a more detailed input-pipeline analysis, use the Input Pipeline Analyzer tool.
CrossReplicaSum. This TensorFlow operation runs on a TPU and computes a sum across replicas. Because each replica corresponds to a different TPU node, the operation must wait for all TPU nodes to be finished with a step. If this operation is taking a long time, it might not mean that the summing operation itself is slow but that a TPU node is waiting for another TPU node with a slow data infeed.

- Dataset Ops. Trace viewer visualizes dataset operations performed when
data is loaded using the Dataset API.
The
Iterator::Filter::Batch::ForeverRepeat::Memoryin the example is compiled and it corresponds to thedataset.map()operation. Use trace viewer to examine the loading operations as you work through debugging and mitigating input pipeline bottlenecks.
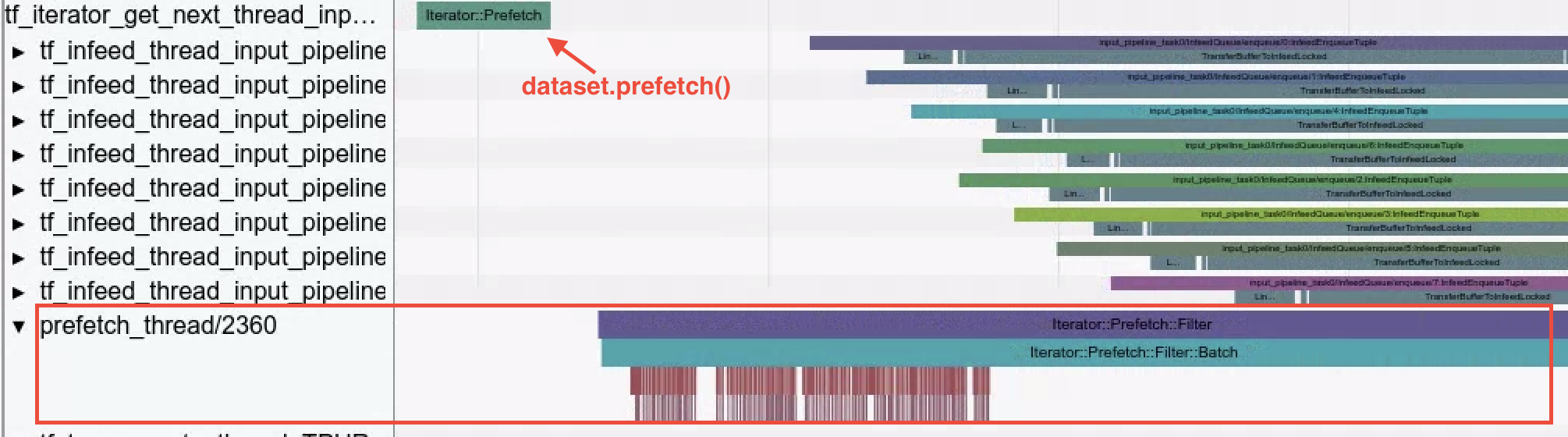
- Prefetch Threads. Using
dataset.prefetch()to buffer input data can prevent sporadic slowdowns in file access that create bottlenecks in the input pipeline.
What can go wrong
Here are some potential issues to be aware of when using trace viewer:
- Event display limit. Trace viewer displays a maximum of 1 million
events. If you captured more events, only the earliest 1 million events are
displayed; later events are dropped. To capture more TPU events, you can
use the
--include_dataset_ops=Falseflag to explicitly requirecapture_tpu_profileto exclude the dataset ops. - Very long events. Events that begin before a capture starts or that end after a capture is finished are not visible in trace viewer. Consequently, very long events can be missed.
When to start trace capture. Be sure to start trace capture after you know the Cloud TPU is running. If you start before then, you may see only a few events or no events at all in trace viewer. You can increase the profile time using the
--duration_msflag and you can set automatic retries using the--num_tracing_attemptsflag. For example:(vm)$ capture_tpu_profile --tpu=$TPU_NAME --logdir=${MODEL_DIR} --duration_ms=60000 --num_tracing_attempts=10
Memory viewer
Memory viewer allows you to visualize the peak memory usage for your program, and memory usage trends over the program's lifetime.
The memory viewer UI looks like this:

- Host dropdown. Selects for a TPU host and XLA High Level Optimizer (HLO) modules to visualize.
- Memory overview. Displays peak memory allocation and size without padding.
- Working space chart. Displays peak memory use and a plot of memory usage trends over the program's lifetime. Hovering over a buffer in one of the buffer charts adds an annotation for the buffer lifetime and the buffer details card.
- Buffer charts. Two charts that display buffer allocation at the point of peak memory usage, as indicated by the vertical line in the working space plot. Hovering over a buffer in one of the buffer charts displays the buffer's lifetime bar in the working space chart and a details card on the left.
- Buffer allocation details card. Displays allocation details for a buffer.
Memory overview panel
The memory overview (top) panel shows you the module name and the peak memory allocation set when the total buffer allocation size reaches the maximum. The unpadded peak allocation size is also shown for comparison.

Working space chart
This chart displays peak memory use and a plot of memory usage trends over the program's lifetime. The line drawn from top to bottom of the plot indicates peak memory utilization for the program. This point determines whether or not a program can fit into the available global memory space.

Each point on the overlying line plot represents a "program point" in XLA's HLO program as scheduled by the compiler. The line provides a sense of the spikiness leading to and from the peak usage.
Interaction with buffer chart elements
When you hover over a buffer displayed in one of the buffer charts below the working space chart, a horizontal lifetime line for that buffer appears in the working space chart. The horizontal line is the same color as the highlighted buffer.

The horizontal line thickness indicates the relative magnitude of the buffer size relative to the peak memory allocation. The line length corresponds to the life of the buffer, starting at the point in the program where buffer space was allocated and ending where the space was freed.
Buffer charts
Two charts show the breakdown of memory usage at the peak usage point (indicated by the vertical line in the plot above the charts).

By Program Order. Displays the buffers from left to right in the order in which they were active during program execution. Buffers active for the longest time are on the left side of the chart.
By Size. Displays the buffers that were active during program execution in descending size order. Buffers that had the largest impact at the point of peak memory usage are on the left.
Buffer allocation details card
When you hover over a buffer displayed in one of the buffer charts, a buffer allocation details card appears (in addition to the lifetime line displayed in the working chart). A typical details card looks like this:

- Name. Name of the XLA operation.
- Category. Operation category.
- Size. Size of the buffer allocation (including padding).
- Unpadded size. Size of the buffer allocation without padding.
- Expansion. Relative magnitude of padded buffer size versus the unpadded size.
- Extra memory. Indicates how much extra memory is used for padding.
- Shape. Describes the rank, size, and data type of the N-dimensional array.
- TensorFlow op name. Shows the name of the TensorFlow operation associated with the buffer allocation.
- Allocation type. Indicates buffer allocation category. Types are: Parameter, Output, Thread-local, and Temporary (for example, buffer allocation within a fusion).
"Out of memory" errors
If you run a model and get an "out of memory error", use the following command to capture a memory profile and view it in the memory viewer. Make sure to set appropriate duration_ms so that the profiling period overlaps with your program compilation time. The output can help you understand what caused the error:
(vm)$ capture_tpu_profile --tpu=$TPU_NAME --logdir=${MODEL_DIR} --duration_ms=60000
Streaming trace viewer
Streaming trace viewer (trace_viewer) is a Cloud TPU
performance analysis tool, available for
TensorFlow 2.18.0 or later, that provides dynamic trace
renderings. The tool uses the Chrome trace event profiling viewer
so it works only in the Chrome browser.
When you use capture_tpu_profile to
capture a profile, a .tracetable file is saved to your Google Cloud storage
bucket. The file contains a large number of trace events that can be viewed in
in both trace viewer and streaming trace viewer.
Using streaming trace viewer
To use the streaming trace viewer, trace_viewer, you must shut down your
existing TensorBoard session and then relaunch TensorBoard using the IP address
of the TPU you want to examine. Streaming trace viewer requires TensorBoard to
make a Google Remote Procedure Call (GRPC) to an IP address for the
Cloud TPU. The GRPC channel is not encrypted.
You can find the IP address for a Cloud TPU host on the Cloud TPU page. Find your Cloud TPU and look in the Internal IP column for the IP address.
In your VM, run TensorBoard as follows replacing tpu-ip with your TPU's IP address:
(vm)$ tensorboard --logdir=${MODEL_DIR} \ --master_tpu_unsecure_channel=tpu-ip
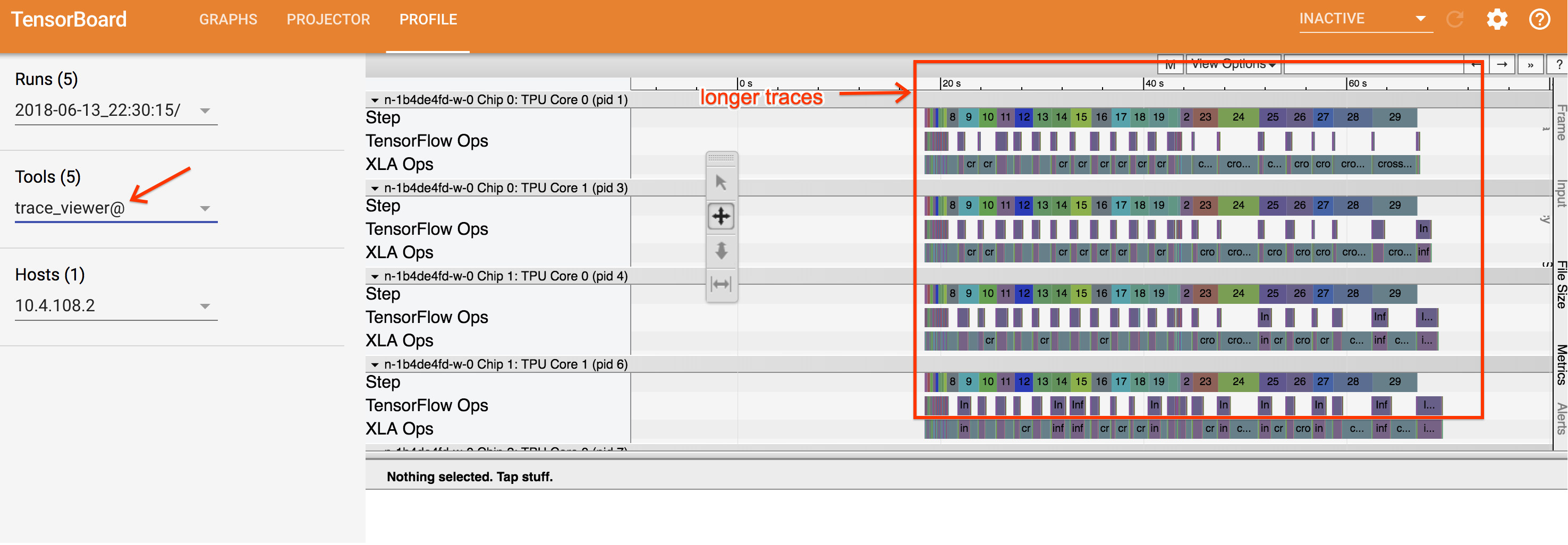
The in TensorBoard tool appears in the Tools dropdown list.
In the timeline, you can zoom in and out to see trace events load dynamically into your browser.
Monitoring your Cloud TPU job
This section describes how to use capture_tpu_profile to capture a
single profile or continuously monitor your Cloud TPU job on the
command-line interface in real time. By setting the --monitoring_level
option to 0 (the default), 1, or 2, you
get a single profile, basic monitoring, or detailed monitoring, respectively.
Open a new Cloud Shell and ssh to your VM (replace vm-name in the command with your VM name):
(vm)$ gcloud compute ssh vm-name \ --ssh-flag=-L6006:localhost:6006
In the new Cloud Shell, run capture_tpu_profile with the
--monitoring_levelflag set to either 1 or 2, such as:
(vm)$ capture_tpu_profile --tpu=$TPU_NAME \ --monitoring_level=1
Setting monitoring_level=1 produces output similar to the following:
TPU type: TPU v2
Utilization of TPU Matrix Units is (higher is better): 10.7%Setting monitoring_level=2 displays more detailed information:
TPU type: TPU v2
Number of TPU Cores: 8
TPU idle time (lower is better): 0.091%
Utilization of TPU Matrix Units is (higher is better): 10.7%
Step time: 1.95 kms (avg), 1.90kms (minute), 2.00 kms (max)
Infeed percentage: 87.5% (avg). 87.2% (min), 87.8 (max)Monitoring flags
--tpu(required) specifies the name of the Cloud TPU you want to monitor.--monitoring_level. Change the behavior ofcapture_tpu_profilefrom producing a single profile, to basic or detailed continuous monitoring. There are three available levels: Level 0 (the default): Produces a single profile, then exits. Level 1: Shows TPU version and TPU utilization. Level 2: Shows the TPU utilization, TPU idle time, and number of TPU cores used. Also provides min, avg, and max step times along with the infeed percentage contribution.--duration_ms(optional, default is 1000ms) specifies how long to profile the TPU host during each cycle. Generally, this should be long enough to capture at least one training step worth of data. 1 second captures a training step in most models but if your model step time is very large, you can set the value to 2xstep_time(in ms).--num_queriesspecifies how many cycles to runcapture_tpu_profile. To continuously monitor your TPU job, set the value to a high number. To quickly check your model's step time set the value to a low number.