Einführung
Die Prognose und Anomalieerkennung für Milliarden von Zeitreihen ist rechenintensiv. Die meisten bestehenden Systeme führen Prognosen und Anomalieerkennung als Batchjobs aus (z. B. Risikopipelines, Traffic-Prognose, Nachfrageplanung usw.). Das schränkt die Art der Analysen ein, die Sie online durchführen können, z. B. die Entscheidung, ob eine Benachrichtigung aufgrund eines plötzlichen Anstiegs oder Rückgangs bei einer Reihe von Ereignisdimensionen ausgelöst werden soll.
Die Hauptziele der Timeseries Insights API sind:
- Skalieren Sie auf Milliarden von Zeitreihen, die dynamisch aus Rohereignissen und ihren Eigenschaften basierend auf Abfrageparametern erstellt werden.
- Bereitstellung von Echtzeitprognosen und Ergebnissen der Anomalieerkennung. Das bedeutet, dass innerhalb weniger Sekunden Trends und saisonale Schwankungen in allen Zeitreihen erkannt und entschieden werden kann, ob es bei einzelnen Segmenten zu unerwarteten Spitzen oder Rückgängen kommt.
API-Funktionen
- Datasets verwalten
- Indexieren und Laden eines Datasets aus mehreren Datenquellen, die in Cloud Storage gespeichert sind. Das Anhängen neuer Ereignisse in Streaming-Manier zulassen.
- Nicht mehr benötigte Datensätze auslagern
- Sie können den Verarbeitungsstatus eines Datensatzes anfordern.
- Datasets abfragen
- Ruft die Zeitreihe ab, die den angegebenen Property-Werten entspricht. Die Zeitreihe wird bis zu einem bestimmten Zeithorizont prognostiziert. Die Zeitreihe wird auch auf Anomalien geprüft.
- Kombinationen von Property-Werten werden automatisch auf Anomalien geprüft.
- Datasets aktualisieren
- Neue Ereignisse, die vor Kurzem stattgefunden haben, werden nahezu in Echtzeit (mit einer Verzögerung von Sekunden bis Minuten) aufgenommen und in den Index eingefügt.
Notfallwiederherstellung
Die Timeseries Insights API dient nicht als Sicherung für Cloud Storage und gibt keine Roh-Streaming-Aktualisierungen zurück. Kunden sind dafür verantwortlich, Daten separat zu speichern und zu sichern.
Nach einem regionalen Ausfall wird der Dienst nach dem Best-Effort-Prinzip wiederhergestellt. Metadaten (Informationen zum Datensatz und zum Betriebsstatus) und gestreamte Nutzerdaten, die innerhalb von 24 Stunden nach Beginn der Störung aktualisiert wurden, können möglicherweise nicht wiederhergestellt werden.
Während der Wiederherstellung sind Abfragen und Streaming-Aktualisierungen für Datensätze möglicherweise nicht verfügbar.
Eingabedaten
Es ist üblich, dass numerische und kategorische Daten im Zeitverlauf erhoben werden. Die folgende Abbildung zeigt beispielsweise die CPU-Auslastung, die Arbeitsspeichernutzung und den Status eines einzelnen laufenden Jobs in einem Rechenzentrum jede Minute über einen bestimmten Zeitraum hinweg. Die CPU- und Arbeitsspeichernutzung sind numerische Werte und der Status ist ein kategorischer Wert.
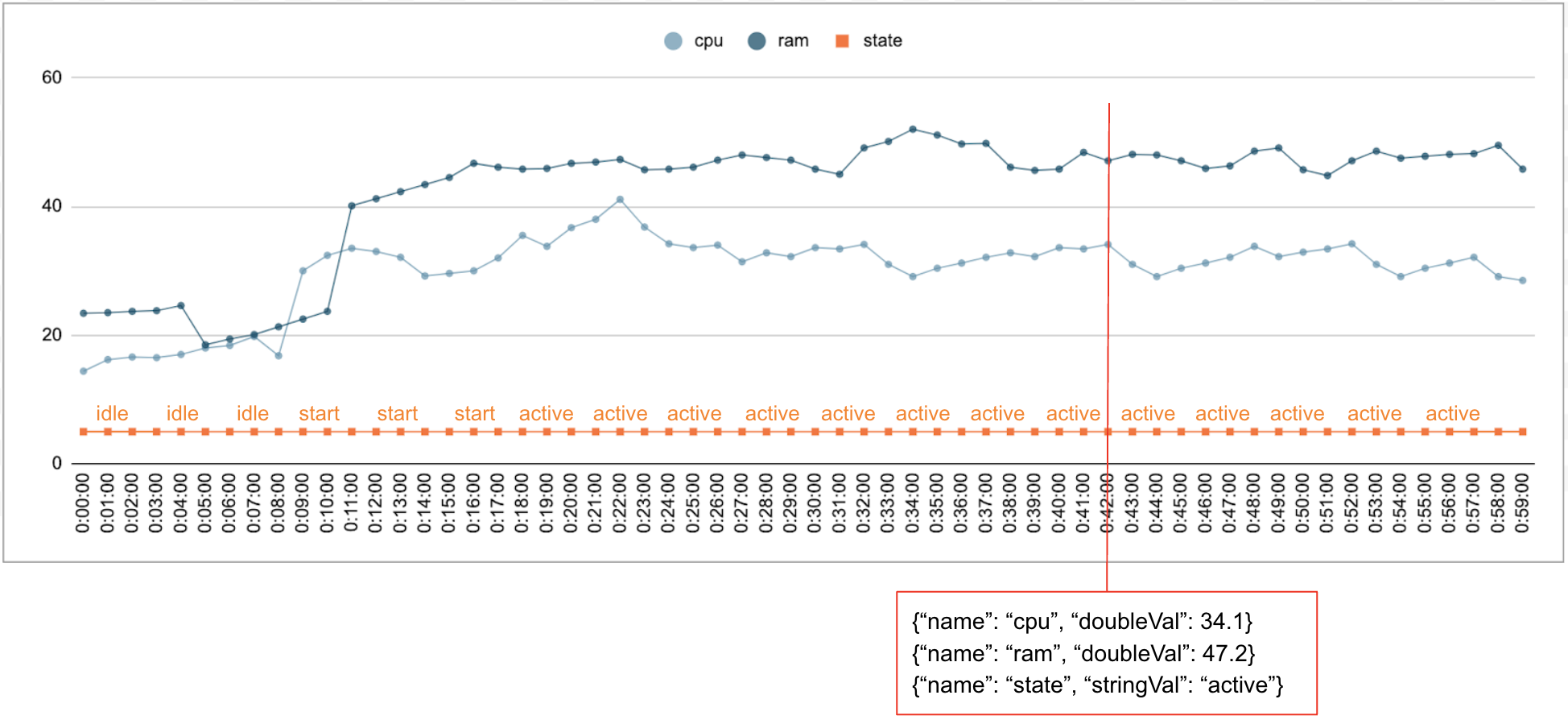
Ereignis
Die Timeseries Insights API verwendet Ereignisse als grundlegende Dateneingabe. Jedes Ereignis hat einen Zeitstempel und eine Sammlung von Dimensionen, also Schlüssel/Wert-Paare, bei denen der Schlüssel der Dimensionsname ist. Diese einfache Darstellung ermöglicht es uns, Daten im Billionenbereich zu verarbeiten. So werden beispielsweise der Name des Rechenzentrums, des Nutzers, des Jobs und die Aufgabennummer erfasst, um ein einzelnes Ereignis vollständig zu repräsentieren. Die Abbildung oben zeigt eine Reihe von Ereignissen, die für einen einzelnen Job aufgezeichnet wurden. Dabei wird eine Teilmenge der Dimensionen dargestellt.
{"name":"user","stringVal":"user_64194"},
{"name":"job","stringVal":"job_45835"},
{"name":"data_center","stringVal":"data_center_30389"},
{"name":"task_num","longVal":19},
{"name":"cpu","doubleVal":3840787.5207877564},
{"name":"ram","doubleVal":1067.01},
{"name":"state","stringVal":"idle"}
Datenpool
Ein DataSet ist eine Sammlung von Ereignissen. Abfragen werden innerhalb desselben Datensatzes ausgeführt. Jedes Projekt kann mehrere Datasets haben.
Ein Datensatz besteht aus Batch- und Streaming-Daten. Beim Erstellen von Batch-Daten werden mehrere Cloud Storage-URIs als Datenquellen gelesen. Nach Abschluss des Batch-Builds kann das Dataset mit Streamingdaten aktualisiert werden. Durch die Verwendung von Batch-Builds für Verlaufsdaten kann das System Kaltstartprobleme vermeiden.
Ein Dataset muss erstellt oder indexiert werden, bevor es abgefragt oder aktualisiert werden kann. Die Indexierung beginnt, wenn das Dataset erstellt wird. Je nach Datenmenge dauert sie in der Regel einige Minuten bis Stunden. Konkret werden die Datenquellen bei der Erstindexierung einmal gescannt. Wenn sich der Inhalt der Cloud Storage-URIs nach Abschluss der anfänglichen Indexierung ändert, werden sie nicht noch einmal gescannt. Verwenden Sie Streaming-Updates für zusätzliche Daten. Streaming-Aktualisierungen werden kontinuierlich und nahezu in Echtzeit indexiert.
Zeitreihen und Anomalieerkennung
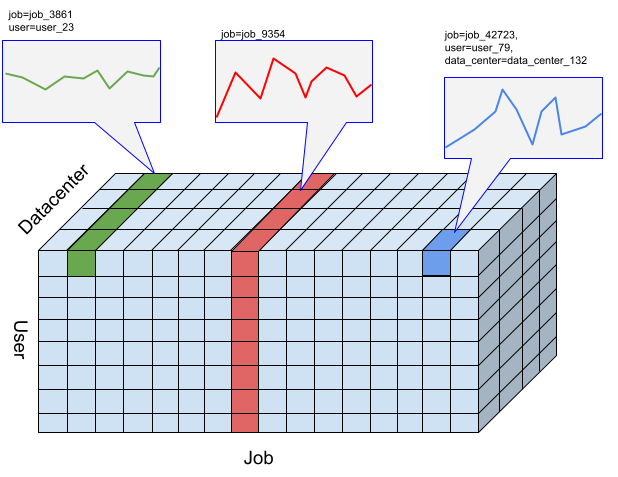
Bei der Timeseries Insights API ist ein Stichprobenbereich eine Sammlung von Ereignissen mit einer bestimmten Kombination von Dimensionswerten. Wir möchten die Anzahl der Ereignisse messen, die in diese Zeiträume fallen.
Für einen bestimmten Ausschnitt werden die Ereignisse in numerische Werte nach der vom Nutzer angegebenen Auflösung von Zeitintervallen zusammengefasst. Das sind die Zeitreihen, in denen Anomalien erkannt werden sollen. Die Abbildung oben zeigt verschiedene Auswahlmöglichkeiten für Segmente, die sich aus verschiedenen Kombinationen der Dimensionen „Nutzer“, „Aufgabe“ und „Rechenzentrum“ ergeben.
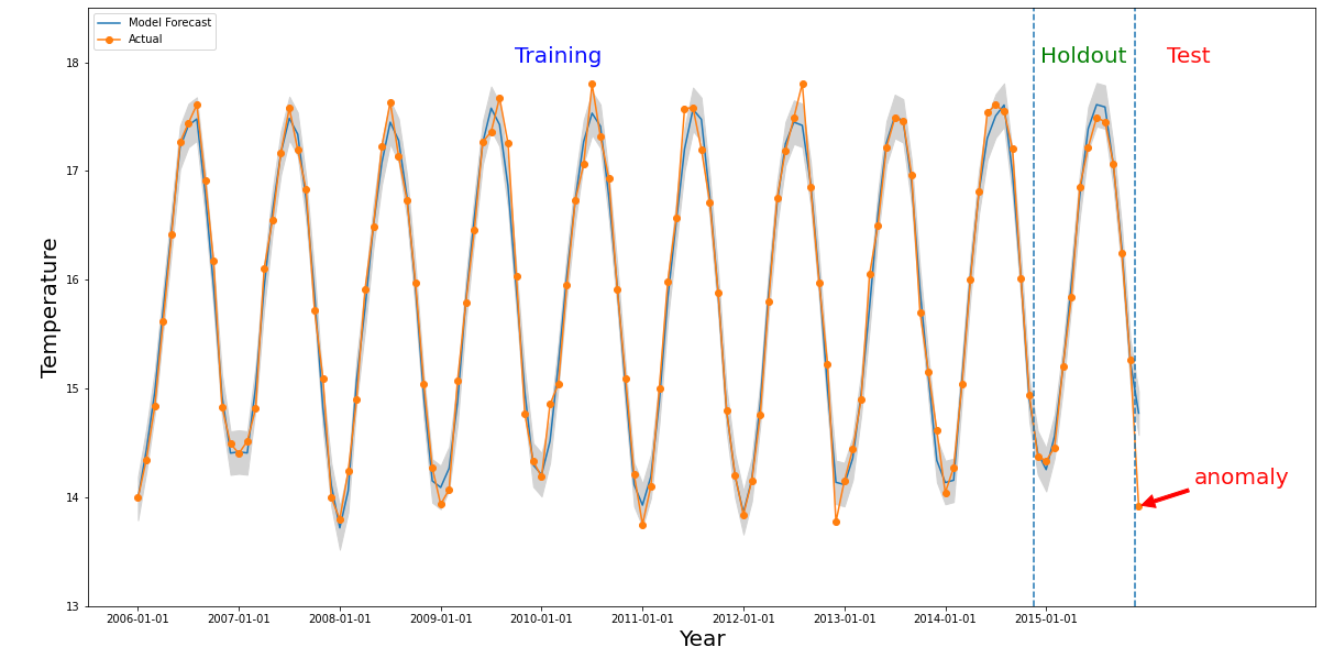
Eine Anomalie tritt für einen bestimmten Ausschnitt auf, wenn sich der numerische Wert aus dem betreffenden Zeitraum deutlich von den Werten in der Vergangenheit unterscheidet. Die Abbildung oben zeigt eine Zeitreihe, die auf Temperaturen basiert, die weltweit über einen Zeitraum von 10 Jahren gemessen wurden. Angenommen, wir möchten wissen, ob der letzte Monat des Jahres 2015 eine Anomalie ist. In einer Abfrage an das System wird der gewünschte Zeitraum, detectionTime, mit „2015-12-01“ und granularity mit „1 Monat“ angegeben. Die abgerufene Zeitreihe vor dem detectionTime wird in einen früheren Trainingszeitraum und einen Hold-out-Zeitraum unterteilt. Das System verwendet Daten aus dem Trainingszeitraum, um ein Modell zu trainieren, und den Holdout-Zeitraum, um zu überprüfen, ob das Modell die nächsten Werte zuverlässig vorhersagen kann. In diesem Beispiel beträgt der Hold-out-Zeitraum ein Jahr. Das Bild zeigt die tatsächlichen Daten und die vorhergesagten Werte aus dem Modell mit Ober- und Untergrenzen. Die Temperatur für 2015/12 ist als Anomalie gekennzeichnet, da der tatsächliche Wert außerhalb der vorhergesagten Grenzen liegt.
Nächste Schritte
- Timeseries Insights API Konzepte
- Detailliertere Anleitung
- Weitere Informationen zur REST API