Panoramica
Text-to-Speech crea dati audio non elaborati del parlato naturale e umano. In altre parole, crea un audio simile a quello di una persona che parla. Quando invii una richiesta di sintesi a Text-to-Speech, devi specificare una voce in grado di "pronunciare" le parole.
È disponibile un'ampia selezione di voci tra cui scegliere per Text-to-Speech. Le voci differiscono per lingua, genere e accento (per alcune lingue). Per alcune lingue è possibile scegliere più voci. Consulta la pagina Voci supportate per un elenco completo delle voci disponibili nella tua lingua. Puoi indicare a Text-to-Speech di
utilizzare una voce specifica di questo elenco impostando i campi
VoiceSelectionParams
quando invii una richiesta all'API. Consulta le Guide rapide per Text-to-Speech per maggiori dettagli su come inviare una richiesta synthesize.
Voci Neural2
L'API Text-to-Speech fornisce un livello voce premium chiamato Neural2. Le voci Neural2 si basano sulla stessa tecnologia utilizzata per creare una voce personalizzata. Neural2 rappresenta l'ultima generazione di voci sintetiche e consente a chiunque di utilizzare la tecnologia della voce personalizzata senza addestrare la propria voce. Sono disponibili negli endpoint globali e di una singola area geografica.
Esempio 1. Voce Neural2
Voci di Studio (anteprima)
L'API Text-to-Speech fornisce voci di Studio. Questo tipo di voce è progettato specificamente per l'utilizzo con testi di lunga durata come narrazione e lettura di notizie.
Esempio 1. La voce di en-US-Studio-O che legge il Grande Gatsby.
Voci del viaggio
Le voci del percorso (sperimentale) sono supportate dai progressi della modellazione linguistica di grandi dimensioni (LLM), che ne migliorano la ricchezza prosodica. Le voci del percorso gestiscono una gamma più ampia di tono, volume, timbro e durata. Hanno anche meccaniche vocali avanzate, che li migliorano nella gestione di disfluenze e interruzioni rispetto alle altre opzioni vocali. Ti consigliamo di sperimentare queste voci per casi d'uso del parlato.
Voci standard
Le voci offerte da Text-to-Speech differiscono nel modo in cui sono prodotte, la tecnologia di sintesi vocale utilizzata per creare il modello di macchina della voce. Una tecnologia di riconoscimento vocale comune, la sintesi vocale parametrica, in genere genera dati audio passando gli output tramite algoritmi di elaborazione dei segnali noti come vocoder. Molte delle voci standard disponibili in Text-to-Speech utilizzano una variante di questa tecnologia.
Voci WaveNet
L'API Text-to-Speech offre anche un gruppo di voci premium generate utilizzando un modello WaveNet, la stessa tecnologia utilizzata per produrre il parlato per l'Assistente Google, la Ricerca Google e Google Traduttore. La tecnologia WaveNet offre molto di più di una serie di voci sintetiche: rappresenta un nuovo modo di creare voce sintetica.
WaveNet genera una sintesi vocale più naturale di altri sistemi di sintesi vocale. Sintetizza il parlato con un'enfasi più simile a quella umana e un'inflessione su sillabe, fonemi e parole.
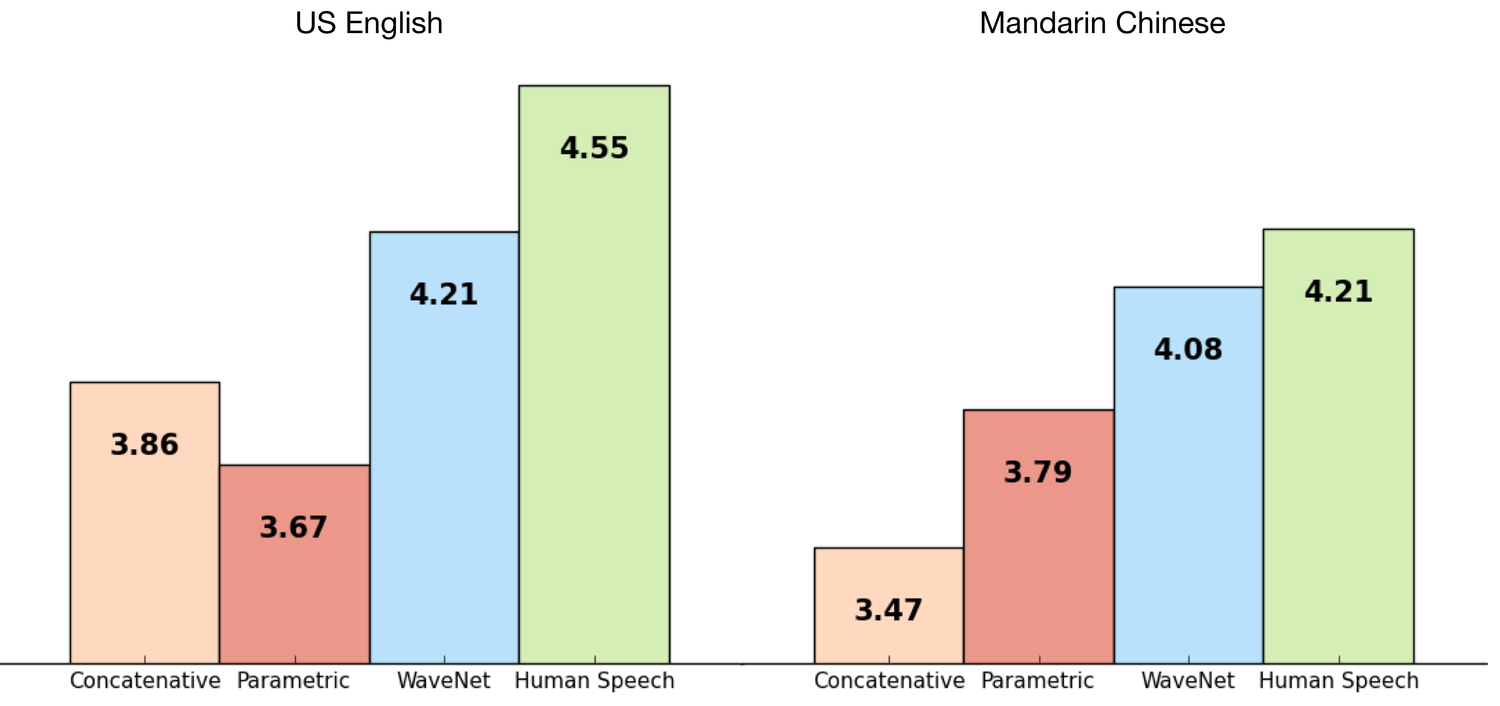 Figura 1. Il grafico mostra il confronto tra WaveNet e altre voci sintetiche, ossia il parlato. I valori dell'asse y rappresentano il punteggio medio delle opinioni (MOS) per ciascuna voce.
I soggetti di test hanno classificato ciascuna voce su una scala da 1 a 5 in base a quanto sembrava naturale. Per ulteriori informazioni sui punteggi MOS e sulla tecnologia WaveNet, consulta la pagina DeepMind WaveNet.
Figura 1. Il grafico mostra il confronto tra WaveNet e altre voci sintetiche, ossia il parlato. I valori dell'asse y rappresentano il punteggio medio delle opinioni (MOS) per ciascuna voce.
I soggetti di test hanno classificato ciascuna voce su una scala da 1 a 5 in base a quanto sembrava naturale. Per ulteriori informazioni sui punteggi MOS e sulla tecnologia WaveNet, consulta la pagina DeepMind WaveNet.
A differenza della maggior parte degli altri sistemi di sintesi vocale, un modello WaveNet crea forme d'onda audio non elaborate da zero. Il modello usa una rete neurale che è stata addestrata con un grande volume di campioni vocali. Durante l'addestramento, la rete estrae la struttura sottostante del discorso, ad esempio i toni che si seguono e l'aspetto di una forma d'onda del parlato realistica. Quando viene fornito un input di testo, il modello WaveNet addestrato è in grado di generare da zero le forme d'onda vocali corrispondenti, un campione alla volta, con fino a 24.000 campioni al secondo e transizioni fluide tra i singoli suoni.
Per sentire la differenza tra un clip audio generato da Wavenet e un clip generato da un altro processo di sintesi vocale, confronta i due clip audio di seguito.
Esempio 1. Voce di alta qualità non WaveNet
Esempio 2. Voce WaveNet
Provalo
Se non hai mai utilizzato Google Cloud, crea un account per valutare le prestazioni di Text-to-Speech in scenari reali. I nuovi clienti ricevono anche 300 $ di crediti gratuiti per l'esecuzione, il test e il deployment dei carichi di lavoro.
Prova Text-to-Speech gratuitamente