Présentation
Text-to-Speech crée des données audio brutes de voix humaines naturelles. Cela veut dire que cette API génère des contenus audio qui font penser qu'une personne parle. Lorsque vous envoyez une requête de synthèse à Text-to-Speech, vous devez spécifier une voix qui "prononce" les mots.
Une large sélection de voix personnalisées est disponible dans Text-to-Speech. Celles-ci diffèrent selon la langue, le genre et l'accent (pour certaines langues). Vous pouvez également avoir le choix entre plusieurs voix. Consultez la page Voix disponibles pour obtenir la liste complète des voix disponibles dans votre langue. Vous pouvez indiquer à Text-to-Speech d'utiliser une voix spécifique de cette liste en définissant les champs VoiceSelectionParams lorsque vous envoyez une requête à l'API. Pour en savoir plus sur l'envoi d'une requête synthesize, consultez les guides de démarrage rapide de Text-to-Speech.
Voix Neural2
L'API Text-to-Speech fournit un niveau de voix haut de gamme appelé Neural2. Les voix Neural2 sont basées sur la même technologie que celle utilisée pour créer une voix personnalisée. Neural2 représente la dernière génération de voix synthétiques et permet à n'importe quel utilisateur d'utiliser la technologie de voix personnalisée sans avoir à entraîner sa propre voix personnalisée. Elles sont disponibles dans des points de terminaison mondiaux et de région unique.
Exemple 1. Voix Neural2
Voix Studio (preview)
L'API Text-to-Speech fournit des voix Studio. Ce type de voix est spécialement conçu pour être utilisé avec des textes longs, tels que la narration et la lecture d'actualités.
Exemple 1. Lecture de Gatsby le Magnifique par la voix en-US-Studio-O.
Voix standards
Les voix proposées par Text-to-Speech peuvent différer selon la façon dont elles sont produites, c'est-à-dire selon la technologie de synthèse vocale utilisée pour créer le modèle de machine de la voix. La synthèse vocale paramétrique est une technologie vocale courante qui génère habituellement des données audio en transmettant des sorties à des algorithmes de traitement du signal, appelés vocodeurs. La plupart des voix standards disponibles dans Text-to-Speech utilisent une variante de cette technologie.
Voix WaveNet
L'API Text-to-Speech offre également un éventail de voix haut de gamme générées à l'aide d'un modèle WaveNet, à savoir la technologie utilisée pour produire de la parole dans l'Assistant Google, la recherche Google et Google Traduction. La technologie WaveNet ne se limite pas à une série de voix synthétiques : elle représente une nouvelle façon de créer un discours synthétique.
WaveNet génère des voix qui sonnent plus naturelles que celles d'autres systèmes de synthèse vocale. Il synthétise la voix avec une emphase et une inflexion plus humaines sur les syllabes, les phonèmes et les mots.
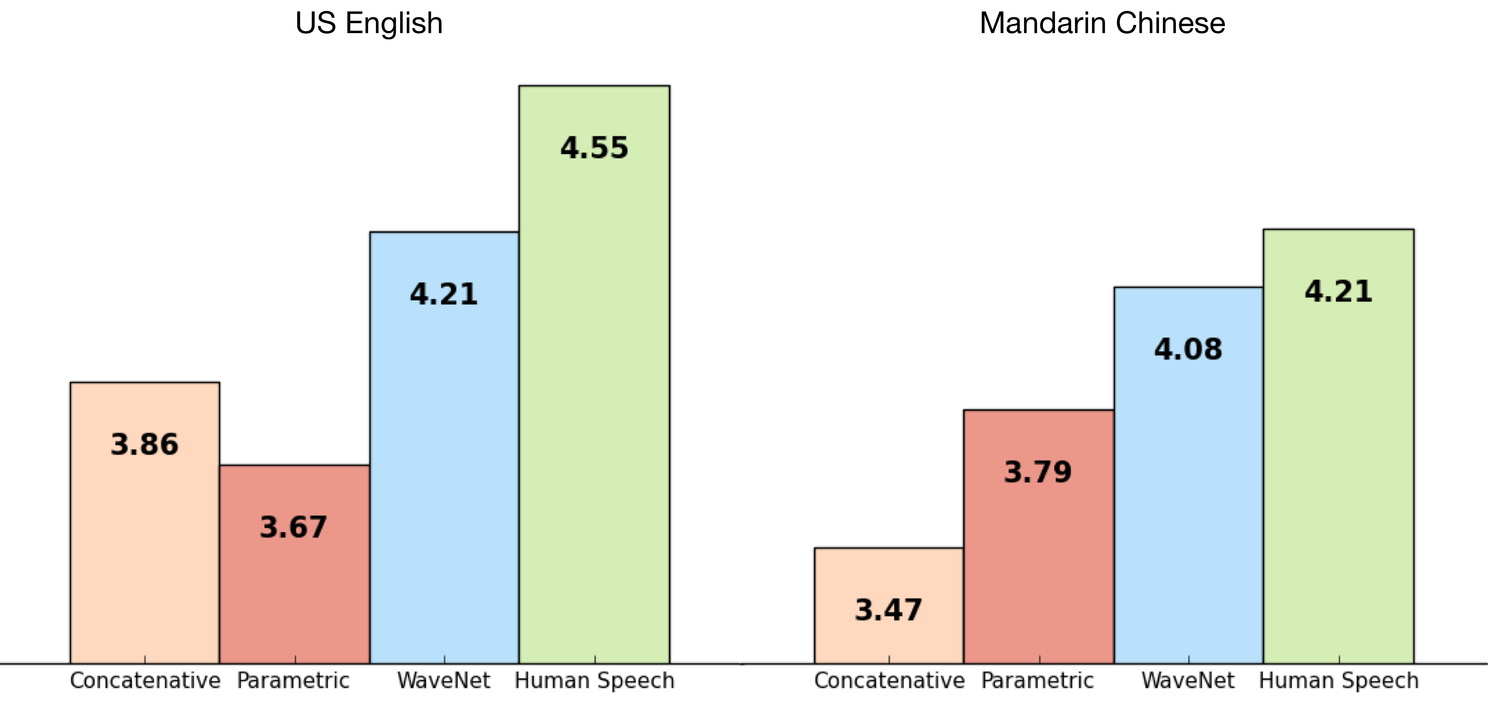 Figure 1. Graphique comparant WaveNet à d'autres voix synthétiques et à la voix humaine Les valeurs de l'axe des ordonnées représentent le score MOS (ou note moyenne d'opinion) pour chaque voix.
Les sujets de test ont classé chaque voix sur une échelle de 1 à 5 en fonction du son émis par la voix naturelle. Pour en savoir plus sur les scores MOS et la technologie WaveNet, consultez la page DeepMind WaveNet.
Figure 1. Graphique comparant WaveNet à d'autres voix synthétiques et à la voix humaine Les valeurs de l'axe des ordonnées représentent le score MOS (ou note moyenne d'opinion) pour chaque voix.
Les sujets de test ont classé chaque voix sur une échelle de 1 à 5 en fonction du son émis par la voix naturelle. Pour en savoir plus sur les scores MOS et la technologie WaveNet, consultez la page DeepMind WaveNet.
Contrairement à la plupart des systèmes de synthèse vocale, un modèle WaveNet crée des formes d'ondes sonores brutes à partir de zéro. Il fait appel à un réseau de neurones entraîné à l'aide d'un grand nombre d'échantillons vocaux. Pendant l'entraînement, le réseau extrait la structure sous-jacente de la parole, par exemple quelles tonalités se succèdent et à quoi ressemble une forme d'onde vocale réaliste. Lorsqu'il reçoit une entrée de texte, le modèle WaveNet entraîné peut générer les formes d'ondes vocales correspondantes à partir de zéro, un échantillon à la fois, et ce, en traitant jusqu'à 24 000 échantillons par seconde et en réalisant des transitions fluides entre chaque son.
Pour entendre la différence entre un extrait audio généré par WaveNet et un extrait généré par un autre processus de synthèse vocale, comparez les deux extraits audio ci-dessous.
Exemple 1. Voix non-WaveNet de haute qualité
Exemple 2. Voix WaveNet
Faites l'essai
Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de Text-to-Speech en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits offerts pour exécuter, tester et déployer des charges de travail.
Profiter d'un essai gratuit de Text-to-Speech