Chirp は、Google の次世代の Speech-to-Text モデルです。長年にわたる研究の成果として、Chirp の最初のバージョンが Speech-to-Text で利用できるようになりました。Google では、Chirp の改善と他の言語およびドメインへの展開を予定しています。詳しくは、Google USM の論文をご覧ください。
Chirp モデルは、現在の音声モデルとは異なるアーキテクチャでトレーニングされています。1 つのモデルに複数の言語のデータが統合されています。ただし、モデルで音声認識を行う言語はユーザーが指定します。Chirp では、他のモデルが提供している Google の音声認識機能の一部がサポートされていません。一覧については、機能のサポートと制限事項をご覧ください。
モデル ID
Chirp は Speech-to-Text API v2 で使用できます。他のモデルと同様に利用できます。
Chirp のモデル ID は chirp です。
このモデルは、同期またはバッチ認識リクエストで指定できます。
利用可能な API メソッド
Chirp は、他のモデルよりもはるかに大きなチャンクで音声を処理します。そのため、リアルタイムでの使用には適さない場合があります。Chirp は次の API メソッドを介して利用できます。
v2Speech.Recognize(1 分未満の短い音声信号に適しています)v2Speech.BatchRecognize(1 分から 8 時間までの長い音声信号に適しています)
次の API メソッドでは Chirp を利用できません。
v2Speech.StreamingRecognizev1Speech.StreamingRecognizev1Speech.Recognizev1Speech.LongRunningRecognizev1p1beta1Speech.StreamingRecognizev1p1beta1Speech.Recognizev1p1beta1Speech.LongRunningRecognize
リージョン
Chirp は、次のリージョンで利用できます。
us-central1europe-west4asia-southeast1
詳しくは言語ページをご覧ください。
言語
サポートされている言語については、言語のリストをご覧ください。
機能のサポートと制限事項
Chirp では、STT API の一部の機能がサポートされていません。
- 信頼スコア: API は値を返しますが、実際には信頼スコアではありません。
- 音声適応: 適応機能はサポートされていません。
- ダイアライゼーション: 自動ダイアライゼーションはサポートされていません。
- 正規化の強制: サポートされていません。
- 単語レベルの信頼: サポートされていません。
- 言語検出: サポートされていません。
Chirp は、次の機能をサポートしています。
- 句読点の自動入力: 句読点はモデルによって予測されます。無効にすることもできます。
- ワード タイミング: 必要に応じて返されます。
- 言語に依存しない音声文字変換: モデルは、音声ファイルの音声言語を自動的に推測して結果に追加します。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Speech-to-Text APIs.
-
Make sure that you have the following role or roles on the project: Cloud Speech Administrator
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
IAM に移動 - プロジェクトを選択します。
- [ アクセスを許可] をクリックします。
-
[新しいプリンシパル] フィールドに、ユーザー ID を入力します。 これは通常、Google アカウントのメールアドレスです。
- [ロールを選択] リストでロールを選択します。
- 追加のロールを付与するには、 [別のロールを追加] をクリックして各ロールを追加します。
- [保存] をクリックします。
Install the Google Cloud CLI.
外部 ID プロバイダ(IdP)を使用している場合は、まずフェデレーション ID を使用して gcloud CLI にログインする必要があります。
gcloud CLI を初期化するには、次のコマンドを実行します。
gcloud init -
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Speech-to-Text APIs.
-
Make sure that you have the following role or roles on the project: Cloud Speech Administrator
Check for the roles
-
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
Grant the roles
-
In the Google Cloud console, go to the IAM page.
IAM に移動 - プロジェクトを選択します。
- [ アクセスを許可] をクリックします。
-
[新しいプリンシパル] フィールドに、ユーザー ID を入力します。 これは通常、Google アカウントのメールアドレスです。
- [ロールを選択] リストでロールを選択します。
- 追加のロールを付与するには、 [別のロールを追加] をクリックして各ロールを追加します。
- [保存] をクリックします。
Install the Google Cloud CLI.
外部 ID プロバイダ(IdP)を使用している場合は、まずフェデレーション ID を使用して gcloud CLI にログインする必要があります。
gcloud CLI を初期化するには、次のコマンドを実行します。
gcloud init -
-
If you're using a local shell, then create local authentication credentials for your user account:
gcloud auth application-default login
You don't need to do this if you're using Cloud Shell.
If an authentication error is returned, and you are using an external identity provider (IdP), confirm that you have signed in to the gcloud CLI with your federated identity.
- Google Cloud アカウントを登録して、プロジェクトを作成していることを確認します。
- Google Cloud コンソールで [Speech] に移動します。
- API が有効になっていない場合は有効にします。
- [音声文字変換] サブページに移動します。
- [新しい音声文字変換] をクリックします。
STT ワークスペースがあることを確認します。ない場合は作成します。
[ワークスペース] プルダウンを開き、[新しいワークスペース] をクリックします。
[新しいワークスペースの作成] ナビゲーション サイドバーで [参照] をクリックします。
クリックしてバケットを作成します。
バケットの名前を入力して、[続行] をクリックします。
[作成] をクリックします。
バケットが作成されたら、[選択] をクリックしてバケットを選択します。
[作成] をクリックして、Speech-to-Text 用のワークスペースの作成を完了します。
音声文字変換を行います。
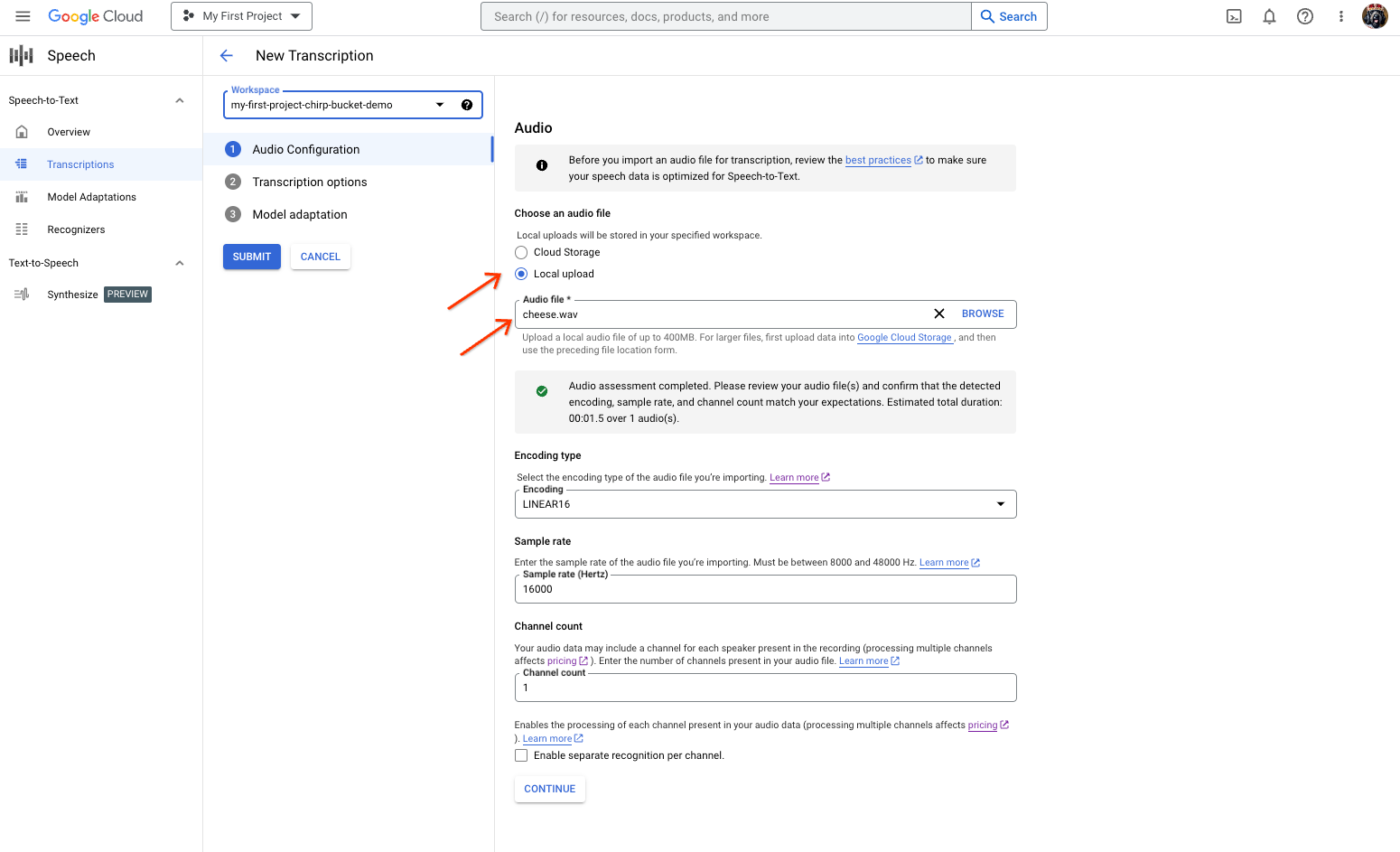
- [新しい音声文字変換] ページで、音声ファイルを選択するオプションを選択します。
- [ローカル アップロード] をクリックしてアップロードします。
- [Cloud Storage] をクリックして、既存の Cloud Storage ファイルを指定します。
- [続行] をクリックします。
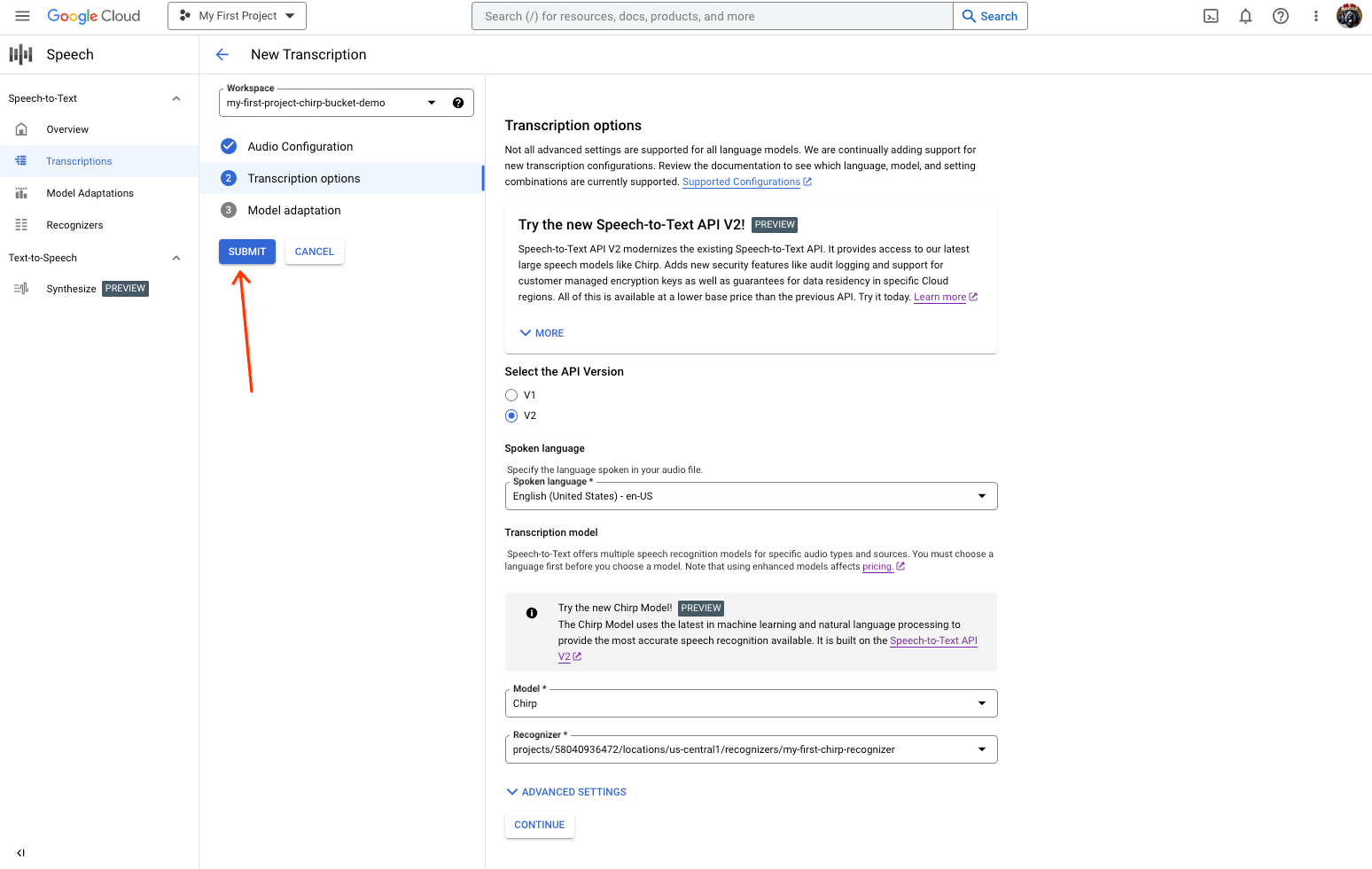
[音音声文字変換のオプション] セクションで、以前に作成した認識ツールから、Chirp で認識に使用する音声言語を選択します。
[モデル]* プルダウンで [Chirp] を選択します。
[リージョン] プルダウンで、リージョン(us-central1 など)を選択します。
[続行] をクリックします。
Chirp を使用して最初の認識リクエストを実行するには、メイン セクションで [送信] をクリックします。
- [新しい音声文字変換] ページで、音声ファイルを選択するオプションを選択します。
Chirp の音声文字変換の結果を表示します。
[音声文字変換] ページで、音声文字変換の名前をクリックします。
[音声文字変換の詳細] ページで、音声文字変換の結果を表示し、必要に応じてブラウザで音声を再生します。
-
Optional: Revoke the authentication credentials that you created, and delete the local credential file.
gcloud auth application-default revoke
-
Optional: Revoke credentials from the gcloud CLI.
gcloud auth revoke
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- 短い音声ファイルの文字変換を行う。
- ストリーミング音声を文字に変換する方法を学習する。
- 長い音声ファイルを文字に変換する方法を学習する。
- ベスト プラクティスのドキュメントで、最高のパフォーマンスと精度を実現するための方法やヒントを確認する。
クライアント ライブラリは、アプリケーションのデフォルト認証情報を使用することによって、Google API で簡単に認証を行い、これらの API にリクエストを送信できます。アプリケーションのデフォルト認証情報を使用すると、ベースとなるコードを変更することなく、ローカルでアプリケーションのテストを行ったり、アプリケーションをデプロイしたりできます。詳細については、クライアント ライブラリを使用するための認証をご覧ください。
また、クライアント ライブラリがインストールされていることを確認してください。
Chirp を使用して同期音声認識を実行する
Chirp を使用してローカル音声ファイルに対して同期音声認識を実行する例を次に示します。
Python
言語に依存しない音声文字変換を有効にしてリクエストを行う
次のコードサンプルは、言語に依存しない音声文字変換を有効にしてリクエストを行う方法を示しています。
Python
Google Cloud コンソールで Chirp を使ってみる
クリーンアップ
このページで使用したリソースについて、 Google Cloud アカウントに課金されないようにするには、次の操作を行います。
コンソール
gcloud