Le modèle de reconnaissance vocale universel (USM, Universal Speech Model) est la nouvelle génération de modèles Speech-to-Text de Google. Ces modèles représentent l'aboutissement de nombreuses années de travail réalisées par les équipes de recherche de Google. Nous proposons désormais notre première itération de l'USM. Toutefois, les modèles actuels ne sont que le début d'un nouvel ensemble de modèles et de recherches prometteurs qui nous permettront d'exploiter de nouvelles fonctionnalités. Il est possible que des mises à jour du modèle et des identifiants supplémentaires associés à l'USM s'affichent au fur et à mesure de la progression de l'offre.
Les modèles vocaux universels sont entraînés avec une architecture différente de celle de nos modèles vocaux actuels. Un modèle unique contient des données provenant de nombreuses langues différentes. Malgré l'unification des données et du modèle d'entraînement, il est toujours nécessaire de spécifier la langue dans laquelle le modèle doit essayer de reconnaître la voix. L'USM n'est pas compatible avec certaines des fonctionnalités Google Speech d'autres modèles. Consultez la liste ci-dessous pour en obtenir la liste complète. Le modèle peut également produire des résultats différents de ceux d'autres modèles Google Speech.
Identifiants de modèle
L'USM est disponible dans l'API Cloud Speech-to-Text v2. Vous pouvez l'exploiter comme n'importe quel autre modèle.
L'identifiant du modèle USM est le suivant : usm
Vous pouvez spécifier ce modèle lors de la création d'un outil de reconnaissance afin d'exploiter le modèle de reconnaissance vocale universel (USM, Universal Speech Model).
Tarifs
En version bêta privée, l'utilisation de l'USM est gratuite. Nous communiquerons les tarifs du modèle ultérieurement.
Méthodes d'API disponibles
Les modèles de reconnaissance vocale universels traitent les données vocales par lots beaucoup plus volumineux. Cela signifie qu'elle peut ne pas être adaptée à une utilisation en temps réel, comme le sont les autres modèles Google Speech-to-Text. Le modèle de reconnaissance vocale universelle est disponible via les méthodes d'API suivantes :
v2Speech.Recognize(compatible avec les contenus audio courts < 1 min)v2Speech.BatchRecognize(compatible avec les contenus audio longs de 1 à 8 min)
Le modèle de reconnaissance vocale universelle n'est pas disponible dans les méthodes d'API suivantes :
v2Speech.StreamingRecognizev1Speech.StreamingRecognizev1Speech.Recognizev1Speech.LongRunningRecognizev1p1beta1Speech.StreamingRecognizev1p1beta1Speech.Recognizev1p1beta1Speech.LongRunningRecognize
Langages
Vous pouvez transmettre les codes de langue suivants :
af-ZAam-ETar-EGaz-AZbe-BYbg-BGbn-BDca-ESzh-Hans-CNcs-CZda-DKde-DEel-GRen-AUen-GBen-INen-USes-USet-EEeu-ESfa-IRfi-FIfil-PHfr-CAfr-FRgl-ESgu-INiw-ILhi-INhu-HUhy-AMid-IDis-ISit-ITja-JPjv-IDka-GEkk-KZkm-KHkn-INko-KRlo-LAlt-LTlv-LVmk-MKml-INmn-MNmr-INms-MYmy-MMno-NOne-NPnl-NLpa-Guru-INpl-PLpt-BRro-ROru-RUsi-LKsk-SKsl-SIsq-ALsr-RSsu-IDsv-SEswta-INte-INth-THtr-TRuk-UAur-PKuz-UZvi-VNyue-Hant-HKzu-ZAas-INast-ESbs-BAceb-PHckb-IQcy-GBha-NGhr-HRkam-KEkea-CVky-KGlb-LUln-CDluo-KEmi-NZmt-MTnso-ZAny-MWoc-FRor-INps-AFsd-INsn-ZWso-SOtg-TJwo-SNyo-NG
Compatibilité des fonctionnalités et limites
Actuellement, le modèle de reconnaissance vocale n'est pas compatible avec un grand nombre des fonctionnalités de l'API STT. Pour en savoir plus, consultez les sections ci-dessous.
- Scores de confiance : l'API renvoie une valeur, mais ce n'est pas réellement un score de confiance.
- Adaptation vocale : aucune fonctionnalité d'adaptation n'est compatible.
- Identification : l'identification automatique n'est pas compatible. La séparation des canaux n'est pas disponible.
- Ponctuation : la ponctuation énoncée n'est pas acceptée. La ponctuation automatique n'est pas disponible.
- Normalisation forcée : non compatible.
- Confiance au niveau du mot : non compatible.
- Détection de la langue : non compatible.
- Temps de chargement du mot : non compatible.
Remarque sur la ponctuation
L'USM disponible en aperçu privé ne produit aucun signe de ponctuation. Vous devez en tenir compte lors des évaluations. Nous travaillons à l'ajout de la ponctuation automatique dès que possible, car nous savons qu'il est important pour de nombreux cas d'utilisation adaptés à l'USM.
Premiers pas avec l'interface utilisateur de la console Cloud
- Assurez-vous d'avoir créé un compte Google Cloud et d'avoir créé un projet. Vous devez utiliser le projet et le compte autorisés pour l'USM.
- Accédez à Speech dans la console Google Cloud.
- Si ce n'est pas déjà fait, activez l'API.
Créer un outil de reconnaissance de STT qui utilise le modèle de reconnaissance vocale universel
Accédez à l'onglet des outils de reconnaissance, puis cliquez sur "Créer".
Sur la page Créer un outil de reconnaissance, saisissez les champs nécessaires pour l'USM.
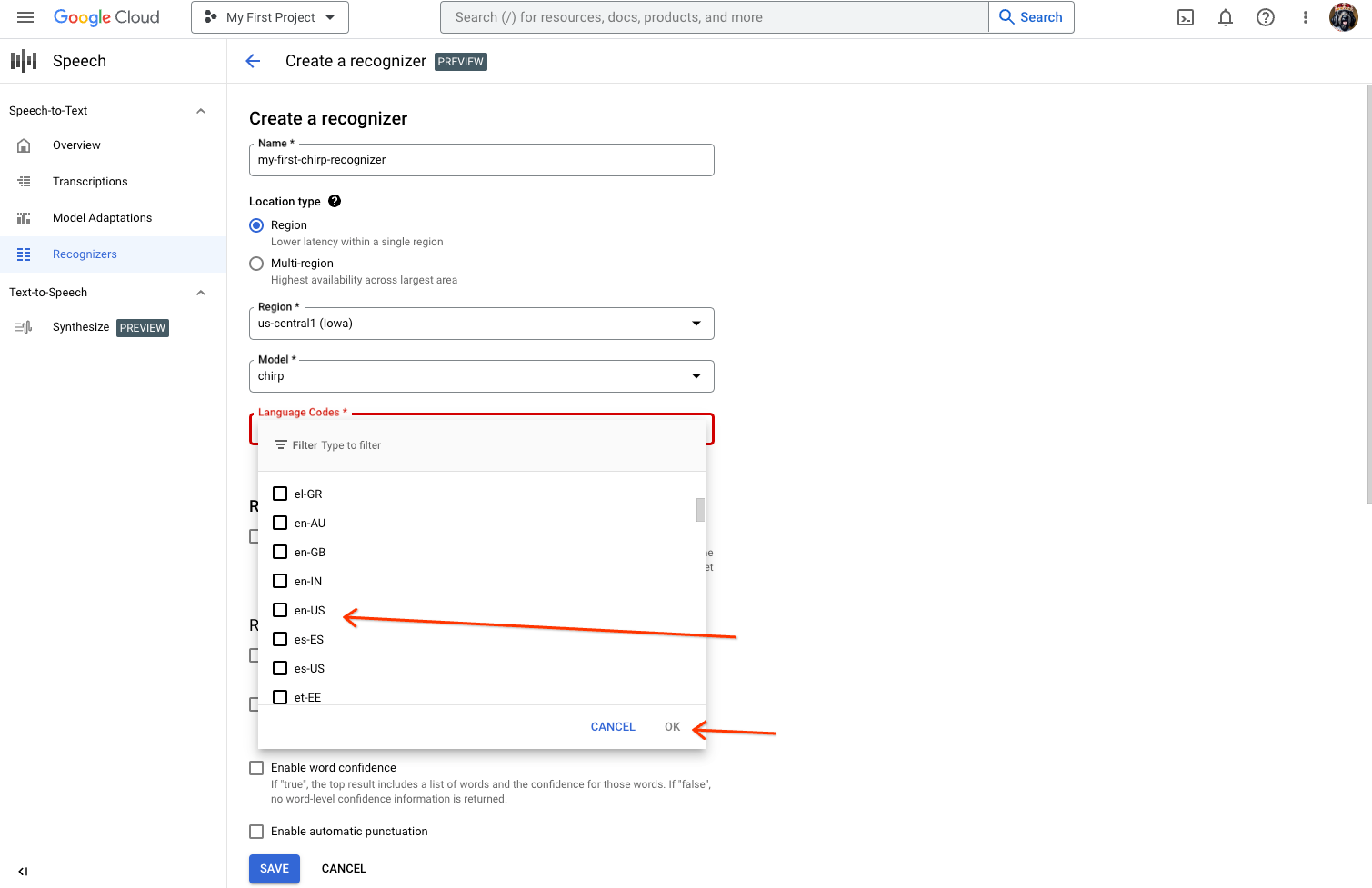
- Attribuez un nom à votre outil de reconnaissance.
- L'USM n'est actuellement disponible que dans la région us-central1. Sélectionnez
region, puisus-central1. - Sélectionnez "usm" comme modèle. Si vous ne voyez pas "usm" dans la liste des modèles, votre projet n'est pas autorisé.
- Sélectionnez le langage que vous souhaitez utiliser. Vous aurez besoin d'un outil de reconnaissance par langue que vous prévoyez de tester.
- Ne sélectionnez aucune autre fonctionnalité.
Assurez-vous de disposer d'un espace de travail d'UI STT dans la région
us-central1. Vous devrez peut-être créer un espace de travail.- Accédez à la page des transcriptions à l'adresse console.cloud.google.com/speech/transcriptions.
- Sur la page "Transcriptions", cliquez sur Nouvelle transcription.
- Ouvrez la liste déroulante
Workspaceet cliquez sur "Nouvel espace de travail" pour créer un espace de travail pour la transcription. - Dans le menu de navigation
Create a new workspace, cliquez surBrowse. - Cliquez sur l'icône de nouveau bucket pour créer un bucket Cloud Storage représentant l'espace de travail.
- Saisissez un nom pour ce bucket, puis cliquez sur "Continuer".
- [IMPORTANT] Sélectionnez
regionetus-central1dans la liste déroulante pour vous assurer que le modèle de reconnaissance vocale universel peut traiter vos données audio. - Cliquez sur
createpour créer votre bucket Cloud Storage. - Une fois le bucket créé, cliquez sur
selectpour le sélectionner. - Cliquez sur
createpour terminer la création de votre espace de travail pour l'UI de reconnaissance vocale.
Effectuez une transcription de votre contenu audio.
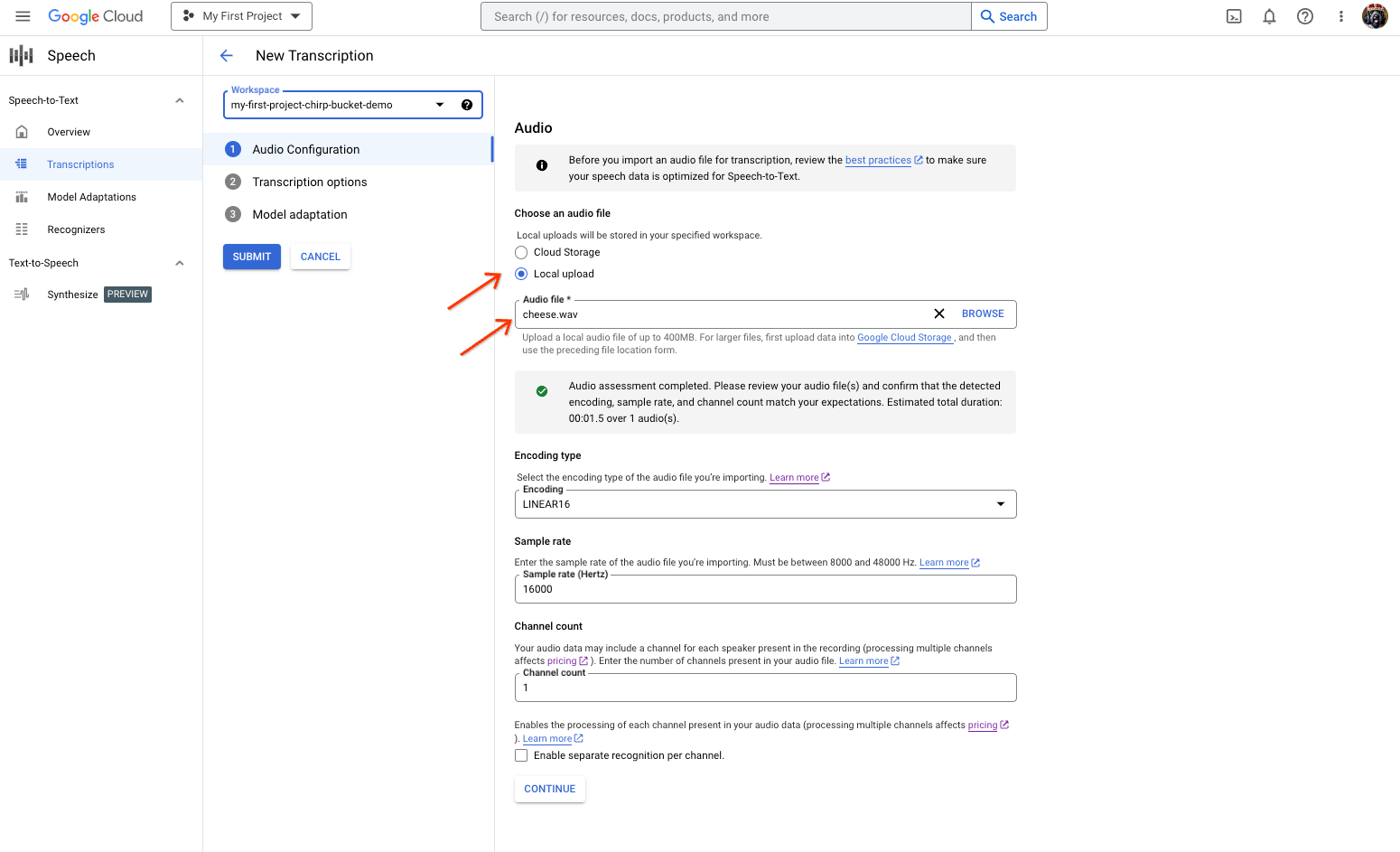
- Sur la page "Nouvelle transcription", sélectionnez votre fichier audio via une importation ("importation locale") ou en spécifiant un fichier Cloud Storage existant ("stockage Cloud"). Notez que l'interface utilisateur essaie automatiquement d'évaluer les paramètres de votre fichier audio.
- Cliquez sur "Continuer" pour passer aux "Options de transcription".

- Sélectionnez la "langue parlée" que vous prévoyez d'utiliser pour la reconnaissance avec le modèle de reconnaissance vocale universel de votre outil de reconnaissance créé précédemment.
- Dans la liste déroulante des modèles, sélectionnez "Modèle de reconnaissance vocale universel".
- Dans la liste déroulante "Outil de reconnaissance", sélectionnez le nouvel outil de reconnaissance.
- Cliquez sur
submitpour exécuter votre première requête de reconnaissance à l'aide du modèle de reconnaissance vocale universel.
Afficher le résultat de transcription du modèle vocal universel
- Sur la page "Transcriptions", cliquez sur le nom de la transcription pour afficher son résultat.
- Sur la page "Détails de la transcription", affichez le résultat de la transcription et éventuellement la lecture du contenu audio dans le navigateur
Premiers pas avec Python Notebook
Ce guide vous aidera à utiliser Python Notebook pour vous lancer avec l'USM sur l'API STT v2.
- Assurez-vous d'avoir créé un compte Google Cloud et d'avoir créé un projet. Vous devez utiliser le projet et le compte autorisés pour l'USM.
- Vérifiez que votre environnement Python Notebook fonctionne
- Consultez notre notebook sur cette page et créez votre propre copie.
- Exécutez le notebook dans l'environnement d'exécution de votre choix. Suivez les instructions du notebook qui vous aideront à configurer l'authentification et les outils de reconnaissance, puis exécutez des requêtes de transcription.