Usa un modelo entrenado de Speech-to-Text personalizado en tus flujos de trabajo de aplicación de producción o de comparativas. Debes implementar y exponer el modelo a través de un extremo dedicado, creado en parte para implementar el modelo en la región que elegiste. Obtienes automáticamente acceso programático a través de un objeto reconocedor. Se usa directamente a través de la API V2 o en la consola de Google Cloud . Puedes implementar tu modelo en una región diferente de donde se entrenó, pero se crea una copia del modelo en la región que especifica el extremo.
Para usar un modelo de voz personalizado, debes implementarlo y exponerlo a través de un extremo dedicado. Cuando creas un extremo, implementas el modelo en la región que elijas. Se te otorga automáticamente acceso programático a través de un objeto de reconocimiento que se usará directamente a través de la API V2 para la inferencia o en la Google Cloud consola.
Antes de comenzar
Asegúrate de haberte registrado en una cuenta de Google Cloud , de haber creado un proyecto y de haber entrenado un modelo de voz personalizado.
- Ve a Speech en la Google Cloud consola y navega a Speech-to-Text.
- Navega dentro de la sección Modelos personalizados de la barra de navegación que se encuentra a la izquierda.
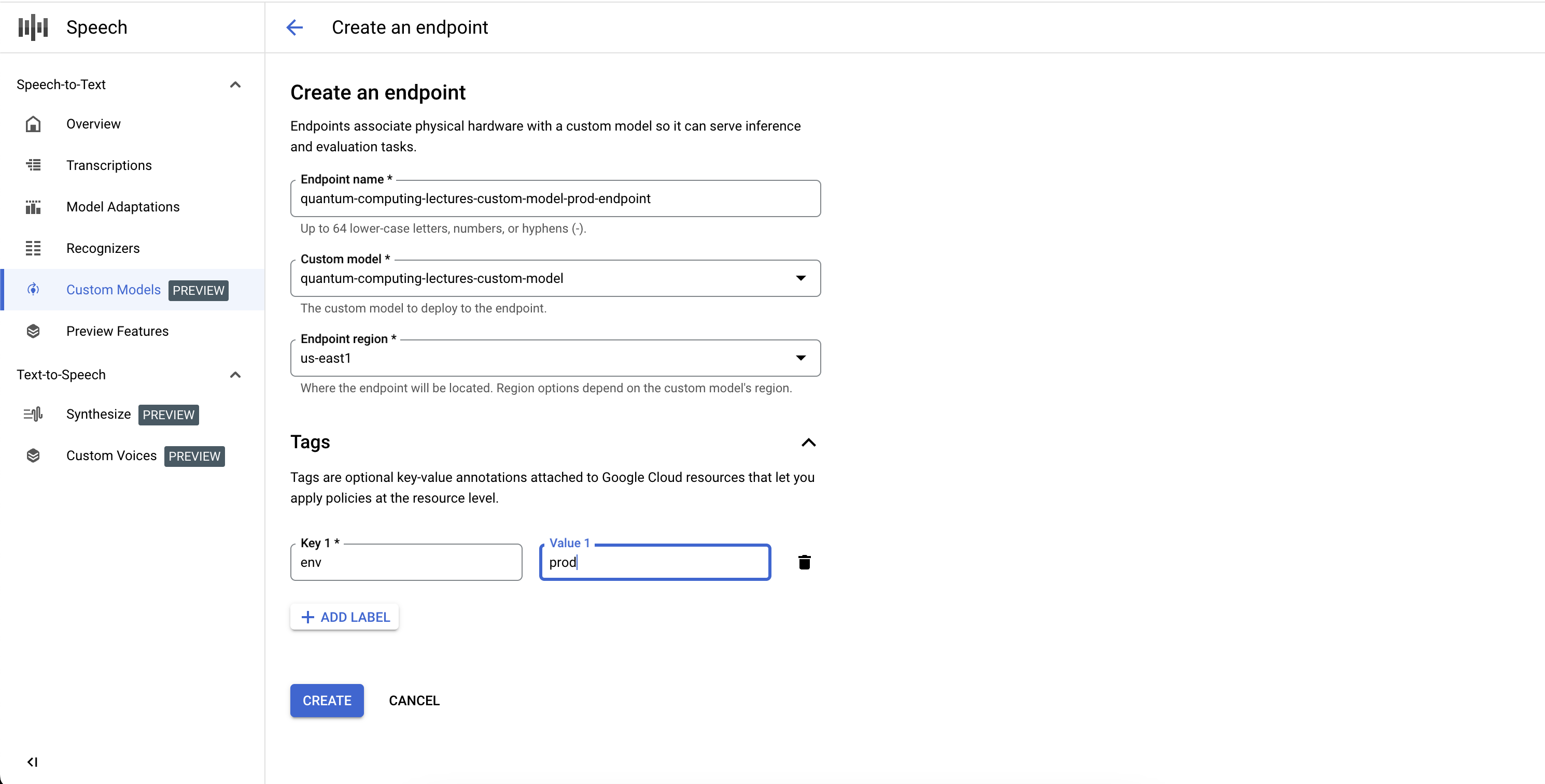
Crea un extremo
- Ve a la pestaña Extremos de la sección Modelos personalizados.
- Haz clic en Nuevo extremo.
- Define un nombre para tu extremo. Este actúa como un identificador único para tu recurso de extremo y se usa a fin de invocar tu modelo de voz personalizado para la inferencia.
- Define la región en la que deseas que se implemente tu modelo de voz personalizado. Si el modelo se entrenó en una región diferente de la definida en la configuración del extremo, se crea una copia del modelo nueva de forma automática.
- Selecciona el modelo de voz entrenado y personalizado de la lista que deseas exponer a través del extremo.
- Haz clic en Crear y, tras unos instantes, se implementará tu modelo de voz personalizado en tu extremo, listo para usarlo en la inferencia y las comparativas.
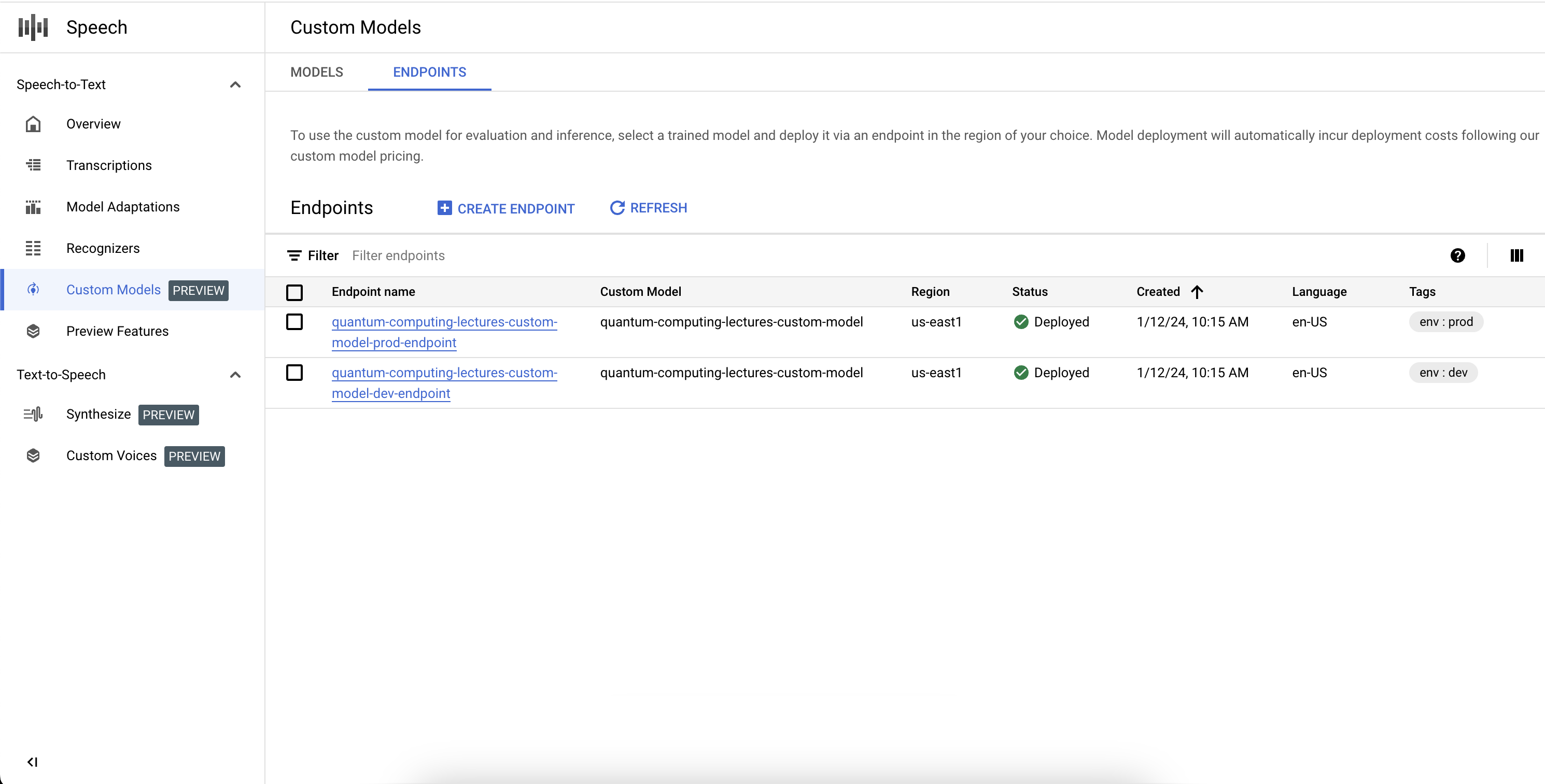
Enumera tus extremos
Para administrar los extremos asociados en la consola, selecciona la pestaña Extremos en la sección Modelos personalizados. También puedes enumerar los extremos que creaste en la consola, junto con su estado actual y el modelo personalizado de Speech-to-Text asociado.
Borra un extremo †
Antes de comenzar, asegúrate de que no se enrute tráfico a través del extremo, ya que, si lo borras, dejará de entregar solicitudes.
- Ve a la pestaña Extremos de la sección Modelos personalizados.
- En la pestaña Extremos, haz clic para expandir las opciones y, luego, haz clic en Borrar. En unos instantes, el extremo se borra y ya no entrega tráfico.
Compara el modelo
Con el modelo personalizado de Speech-to-Text y el conjunto de datos de comparativas para evaluar la exactitud de tu modelo, sigue la Guía de medición y mejora de la exactitud.