Última actualización: septiembre de 2020
Notas de la versión
Este documento forma parte de una serie en la que se analiza la migración de datos y esquemas de Teradata a BigQuery en Google Cloud. Esta parte es una guía de inicio rápido (un instructivo de prueba de concepto) que te guía a través del proceso de conversión de varias instrucciones de SQL de Teradata no estándar en SQL estándar, que puedes usar en BigQuery.
La serie que analiza aspectos específicos de la transición de Teradata consta de las siguientes partes:
- Guía de inicio rápido para la transferencia de datos y esquemas
- Descripción general de traducción de consultas
- Guía de inicio rápido de la traducción de consultas (este documento)
- Referencia de traducción de SQL
Para obtener una descripción general de la transición desde un almacén de datos local hacia BigQuery en Google Cloud, consulta la serie que comienza con Migra almacenes de datos a BigQuery: introducción y descripción general.
Objetivos
- Traducir consultas de SQL de Teradata a SQL estándar
- Comenzar con un enfoque manual para casos simples y proceder con un enfoque automatizado mediante el uso de plantillas
- Explorar traducciones más complejas en las que se necesita refactorizar las consultas
Costos
En esta guía de inicio rápido, se usan los siguientes componentes facturables de Google Cloud:
- BigQuery: en este instructivo, se almacena casi 1 GB de datos en BigQuery y se procesan menos de 2 GB cuando se ejecutan las consultas una vez. Como parte del nivel gratuito de Google Cloud, BigQuery ofrece algunos recursos de forma gratuita hasta alcanzar un límite específico. Estos límites de uso sin cargo están disponibles durante y luego el período de prueba gratuita. Si superas estos límites de uso y ya no te encuentras en el período de prueba gratuito, se te cobrará según los precios de la página de precios de BigQuery.
Puedes usar la calculadora de precios para realizar una estimación de costos según el uso previsto.
Antes de comenzar
- Ejecuta primero la guía de inicio rápido de transferencia de datos y esquemas a fin de crear el esquema y los datos necesarios para esta guía de inicio rápido en tu base de datos de Teradata y en BigQuery. Se usa el mismo proyecto en ambas guías de inicio rápido.
- Asegúrate de que tu computadora tenga instalado Teradata BTEQ y pueda conectarse a una base de datos de Teradata. Si necesitas instalar la herramienta BTEQ, puedes descargarla del sitio web de Teradata.
Consulta al administrador del sistema para obtener detalles sobre la instalación, configuración y ejecución de BTEQ. Como alternativa, o de forma suplementaria a BTEQ, puedes hacer lo siguiente:
- Instalar una herramienta con una interfaz gráfica como DBeaver
- Instalar el módulo de Python provisto por Teradata para las interacciones de secuencias de comandos con la base de datos de Teradata
- Instala Jinja2 en tu computadora si aún no está presente en tu entorno de Python. Jinja2 es un motor de plantillas para Python. Recomendamos usar un administrador de entornos, como virtualenvwrapper, para aislar los entornos de Python.
- Asegúrate de tener acceso a la consola de BigQuery.
Introducción
En esta guía de inicio rápido, se detalla la traducción de algunas consultas de muestra de SQL de Teradata a SQL estándar, que se puede usar en BigQuery. Comienza con un método simple de búsqueda y reemplazo. Luego, pasa a una reestructuración automatizada con secuencias de comandos. Por último, analiza las traducciones más complejas en las que los expertos en la materia del dominio deben participar para asegurarse de que la consulta traducida conserve la semántica del original.
Esta guía de inicio rápido está destinada a los administradores, desarrolladores y profesionales de datos del almacén de datos que estén interesados en una experiencia práctica con la traducción de consultas de SQL de Teradata a SQL estándar ISO:2011.
Reemplaza operadores y funciones
Debido a que el SQL de Teradata se ajusta a ANSI/ISO SQL, muchas consultas se pueden migrar con facilidad con cambios mínimos. Sin embargo, Teradata también admite extensiones SQL no estándar. Para los casos simples en los que se usan operadores y funciones no estándar en Teradata, a menudo se puede usar el proceso de búsqueda y reemplazo a fin de traducir una consulta.
Por ejemplo, puedes comenzar el trabajo con una consulta en Teradata para encontrar el número de clientes que realizaron compras superiores a $10,000 en 1994.
En una computadora donde esté instalado BTEQ, abre el cliente de Teradata BTEQ:
bteqAccede a Teradata. Reemplaza teradata-ip y teradata-user por los valores correspondientes de tu entorno.
.LOGON teradata-ip/teradata-user
En la ventana de BTEQ, ejecuta la siguiente consulta de SQL de Teradata:
SELECT COUNT(DISTINCT(O_CUSTKEY)) AS num_customers FROM tpch.orders WHERE O_TOTALPRICE GT 10000 AND EXTRACT(YEAR FROM O_ORDERDATE) = 1994;El resultado es similar al siguiente:
num_customers ------------- 86101
Ahora, ejecuta la misma consulta en BigQuery:
Dirígete a la consola de BigQuery:
Copia la consulta en el editor de consultas.
El operador
GT(mayor que) no es SQL estándar, por lo que el editor de consultas muestra un mensaje de error de sintaxis: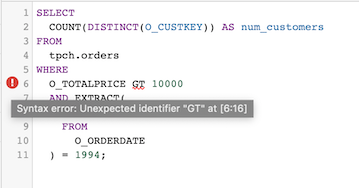
Reemplaza
GTpor el operador>.Haz clic en Ejecutar.
El resultado numérico es el mismo que el de Teradata.
Usa una secuencia de comandos para buscar y reemplazar elementos SQL
El cambio que acabas de hacer es trivial y fácil de hacer a mano. Sin embargo, la búsqueda y el reemplazo de forma manual se vuelve un método engorroso y propenso a errores cuando se deben procesar secuencias de comandos SQL de gran tamaño o en grandes cantidades. Por lo tanto, es mejor automatizar esta tarea, que es lo que harás en esta sección.
En la consola, ve a Cloud Shell:
Usa un editor de texto para crear un archivo nuevo llamado
num-customers.sql. Por ejemplo, usa vi para crear el archivo:vi num-customers.sqlCopia la secuencia de comandos SQL de la sección anterior en el archivo.
Guarda y cierra el archivo.
Reemplaza
GTpor el operador>:sed -i 's/GT/>/' num-customers.sqlVerifica que
GTse haya reemplazado por>en el archivo:cat num-customers.sql
Puedes aplicar la secuencia de comandos sed que acabas de usar en un conjunto de archivos masivo. También se pueden manejar muchos reemplazos en cada archivo.
En Cloud Shell, usa un editor de texto para abrir el archivo llamado
num-customers.sql:vi num-customers.sqlReemplaza el contenido del archivo por la secuencia de comandos siguiente:
SELECT COUNT(DISTINCT(O_CUSTKEY)) AS num_customers FROM tpch.orders WHERE O_TOTALPRICE GT 10000 AND O_ORDERPRIORITY EQ '1-URGENT' AND EXTRACT(YEAR FROM O_ORDERDATE) = 1994;La secuencia de comandos es casi idéntica a la anterior, pero se le agregó una línea para incluir solo los pedidos urgentes. La secuencia de comandos SQL ahora tiene dos operadores SQL no estándar:
GTyEQ.Guarda y cierra el archivo.
Haz 99 copias del archivo:
for i in {1..99}; do cp num-customers.sql "num-customers$i.sql"; doneCuando el comando esté listo, tendrás 100 versiones del archivo de secuencia de comandos.
Reemplaza
GTpor>en todos los archivos en una sola operación:sed -i 's/GT/>/g;s/EQ/=/g' *.sqlUsar una secuencia de comandos para modificar los 100 archivos es mucho más eficiente que modificarlos de forma manual uno por uno.
Crea una lista de los archivos que incluyen el operador
GT:grep GT *.sqlEl comando no devuelve ningún resultado, porque todas las apariciones del operador
GTse reemplazaron por el operador>.Elige cualquiera de los archivos y verifica que los operadores se reemplazaron por sus homólogos estándar:
cat num-customers33.sql
Los siguientes son casos en los que este método de búsqueda y reemplazo es adecuado:
- Algunas funciones de fecha, como el cambio de:
- Algunas funciones de string, como el cambio de:
- Algunas funciones matemáticas, como el cambio de:
NULLIFZEROaNULLIFRANDOMaRANDZEROIFNULLaIFNULL
- Abreviaturas, como cambiar
SELaSELECT.
Para obtener una lista más completa de traducciones comunes, consulta el documento de referencia de traducción de Teradata a BigQuery SQL.
Usa una secuencia de comandos para reestructurar instrucciones de SQL y secuencias de comandos
Hasta ahora solo automatizaste el reemplazo de operadores y funciones que asignan uno a uno entre TeradataSQL y SQL estándar. Sin embargo, la complejidad de la traducción de elementos SQL es mayor para funciones no estándar. La secuencia de comandos de traducción necesita reemplazar palabras clave y, también, debe agregar o mover otros elementos como argumentos, paréntesis y otras llamadas a funciones.
En esta sección, trabajarás con una consulta en Teradata para encontrar los valores más altos que pidió un grupo de clientes al final de cada mes.
En la computadora en la que tienes BTEQ instalado, cambia o abre el símbolo del sistema de BTEQ. Si cerraste BTEQ, ejecuta este comando:
bteqEn la ventana de BTEQ, ejecuta la siguiente consulta de SQL de Teradata:
SELECT O_CUSTKEY, SUM(O_TOTALPRICE) as total, TD_MONTH_END(O_ORDERDATE) as month_end FROM tpch.orders WHERE O_CUSTKEY < 5 GROUP BY O_CUSTKEY, month_end ORDER BY total DESC;La consulta usa la función no estándar
TD_MONTH_ENDde Teradata para obtener la fecha de finalización del mes que le sigue de inmediato a la fecha del pedido. Por ejemplo, si el pedido fue el día 16/05/1996,TD_MONTH_ENDmuestra 1996-05-31. Se necesita un argumento de fecha, es decir, la fecha del pedido. Los resultados se agrupan por estas fechas de fin de mes y por la clave del cliente a fin de obtener el valor total para un mes determinado y un cliente determinado.El resultado es similar al siguiente:
O_CUSTKEY total month_end ----------- ----------------- --------- 4 379593.37 96/06/30 4 323004.15 96/08/31 2 312692.22 97/02/28 4 311722.87 92/04/30
Para ejecutar una consulta que muestre los mismos resultados en BigQuery, tendrías que reemplazar la función TD_MONTH_END no estándar por su SQL estándar equivalente. Sin embargo, no existe una asignación uno a uno para esta función. Por lo tanto, debes crear una función que use una plantilla de Jinja2 para realizar esta tarea.
En Cloud Shell, crea un archivo nuevo con el nombre
month-end.jinja2:vi month-end.jinja2Copia el fragmento siguiente de SQL en el archivo:
DATE_SUB( DATE_TRUNC( DATE_ADD( {{ date }}, INTERVAL 1 MONTH ), MONTH ), INTERVAL 1 DAY )Este archivo es una plantilla de Jinja2. Representa el equivalente a la función
TD_MONTH_ENDen SQL estándar. Tiene un marcador de posición llamado{{ date }}que se reemplazará por el argumento de la fecha, en este casoO_ORDERDATE.Guarda y cierra el archivo.
Crea un archivo nuevo llamado
translate-query.py:translate-query.pyCopia la secuencia de comandos siguiente de Python en el archivo:
"""Translates a sample using a template.""" import re from jinja2 import Environment from jinja2 import PackageLoader env = Environment(loader=PackageLoader('translate-query', '.')) regex = re.compile(r'(.*)TD_MONTH_END\(([A-Z_]+)\)(.*)') with open('month-end.td.sql', 'r') as td_sql: with open('month-end.sql', 'w') as std_sql: for line in td_sql: match = regex.search(line) if match: argument = match.group(2) template = env.get_template('month-end.jinja2') std_sql.write(match.group(1) + template.render(date=argument) \ + match.group(3) + '\n') else: std_sql.write(line)Esta secuencia de comandos de Python abre el archivo que ya se creó (
month-end.td.sql), lee el SQL de Teradata como entrada y escribe una secuencia de comandos SQL estándar traducida en el archivomonth-end.sql.Ten en cuenta los detalles siguientes:
- La secuencia de comandos hace coincidir la expresión regular
(.*)TD_MONTH_END\(([A-Z_]+)\)(.*)con cada línea leída del archivo de entrada. La expresión buscaTD_MONTH_ENDy captura tres grupos:- Cualquier carácter
(.*)antes de la función comogroup(1). - El argumento
([A-Z_]+)enviado a la funciónTD_MONTH_ENDcomogroup(2). - Cualquier carácter
(.*)después de la función comogroup(3).
- Cualquier carácter
- Si hay una coincidencia, la secuencia de comandos recupera la plantilla de Jinja2
month-end.jinja2que creaste en un paso anterior. Luego, escribe lo siguiente en el archivo de salida, en este orden:- Los caracteres representados por
group(1). - La plantilla, en la que el marcador de posición
datese reemplazó por el argumento original que se encontró en el SQL de Teradata, que esO_ORDERDATE. - Los caracteres representados por
group(3).
- Los caracteres representados por
- La secuencia de comandos hace coincidir la expresión regular
Guarda y cierra el archivo.
Ejecuta la secuencia de comandos de Python:
python translate-query.pySe creará un archivo con el nombre
month-end.sql.Haz que se muestre el contenido de este archivo nuevo:
cat month-end.sqlCon este comando, se muestra la consulta traducida a SQL estándar mediante la secuencia de comandos:
SELECT O_CUSTKEY, SUM(O_TOTALPRICE) as total, DATE_SUB( DATE_TRUNC( DATE_ADD( O_ORDERDATE, INTERVAL 1 MONTH ), MONTH ), INTERVAL 1 DAY ) as month_end FROM tpch.orders WHERE O_CUSTKEY < 5 GROUP BY O_CUSTKEY, month_end ORDER BY total DESC;La función
TD_MONTH_ENDya no aparece. Se reemplazó por la plantilla y el argumento de fechaO_ORDERDATEen la posición adecuada en la plantilla.
La secuencia de comandos de Python ya usa una plantilla de un archivo externo de Jinja2. Se puede aplicar el mismo método en la expresión regular, es decir, la expresión se puede cargar desde un archivo o un almacén de pares clave-valor. De esta manera, la secuencia de comandos se puede generalizar para manejar una expresión arbitraria y su plantilla de traducción correspondiente.
Por último, ejecuta la secuencia de comandos generada en BigQuery para verificar que sus resultados coincidan con los obtenidos de Teradata:
Dirígete a la consola de BigQuery:
Copia la consulta que usaste antes en el editor de consultas.
Haz clic en Ejecutar.
El resultado es el mismo que el de Teradata.
Escala verticalmente el esfuerzo de traducción de consultas
Durante una migración, necesitas un grupo de personas capacitadas para aplicar un conjunto de traducciones con herramientas como las secuencias de comandos de ejemplo que viste antes. Estas secuencias de comandos evolucionarán a lo largo del esfuerzo de migración. Por lo tanto, te recomendamos que coloques las secuencias de comandos bajo un control de origen. Deberás probar de forma meticulosa los resultados de la ejecución de estas secuencias de comandos.
Te sugerimos que te comuniques con nuestro equipo de ventas, que te podrá comunicar con nuestra Professional Service Organization y nuestros socios para ayudarte durante la migración.
Refactoriza tus consultas
En la sección anterior, usaste secuencias de comandos para buscar y reemplazar operadores de SQL de Teradata por sus equivalentes en SQL estándar. También realizaste una reestructuración automatizada limitada de tus consultas con la ayuda de plantillas.
Para traducir algunas funcionalidades de SQL de Teradata, es necesario realizar una refactorización más profunda de tus consultas de SQL. En esta sección, se exploran dos ejemplos: traducir la cláusula QUALIFY y traducir referencias de columnas cruzadas.
Los ejemplos de esta sección se refactorizan a mano. En la práctica, algunos casos de refactorización más compleja podrían ser candidatos para la automatización. Sin embargo, automatizarlos podría generar rendimientos decrecientes debido a la complejidad de analizar cada caso diferente. Además, es posible que una secuencia de comandos automatizada no tome en cuenta soluciones más óptimas que preserven la semántica de la consulta.
Cláusula QUALIFY
La cláusula QUALIFY de Teradata es una cláusula condicional que se usa en una indicación SELECT para filtrar los resultados de una función analítica ordenada ya calculada.
Las funciones analíticas ordenadas se aplican a un rango de filas y generan un resultado para cada fila. Los clientes de Teradata suelen usar esta función como una forma abreviada de clasificar y mostrar resultados sin la necesidad de realizar una subconsulta adicional.
Para ilustrar esto, puedes usar la cláusula QUALIFY a fin de seleccionar los pedidos de mayor valor de cada cliente en el año 1994.
En la computadora en la que tienes BTEQ instalado, cambia o abre el símbolo del sistema de BTEQ. Si cerraste BTEQ, ejecuta este comando:
bteqCopia la siguiente consulta de SQL de Teradata a la ventana de BTEQ:
SELECT O_CUSTKEY, O_TOTALPRICE FROM tpch.orders QUALIFY ROW_NUMBER() OVER ( PARTITION BY O_CUSTKEY ORDER BY O_TOTALPRICE DESC ) = 1 WHERE EXTRACT(YEAR FROM O_ORDERDATE) = 1994 AND (O_CUSTKEY MOD 10000) = 0;Ten en cuenta lo siguiente sobre esta consulta:
- La consulta divide las filas en particiones. Cada partición corresponde a una clave de cliente (
PARTITION BY O_CUSTKEY). - La cláusula
QUALIFYfiltra las filas solo a la primera (ROW_NUMBER()=1) de cada partición. - Debido a que las filas de cada partición se ordenan según el precio total del pedido descendente (
ORDER BY O_TOTALPRICE DESC), la primera fila corresponde a la que tiene el valor de orden más alto. - La instrucción
SELECTobtiene la clave del cliente y el precio total del pedido (O_CUSTKEY,O_TOTALPRICE), lo que filtra aún más los resultados para incluir solo 1994 mediante una cláusulaWHERE. - El operador de módulo (
MOD) solo recupera un subconjunto de filas para fines de visualización. Se prefiere usar este método de muestreo a la cláusulaSAMPLE, porqueSAMPLEes aleatorio, lo que no permitirá comparar resultados con BigQuery.
- La consulta divide las filas en particiones. Cada partición corresponde a una clave de cliente (
Ejecuta la consulta.
El resultado es similar al siguiente:
O_CUSTKEY O_TOTALPRICE ----------- ----------------- 10000 182742.02 20000 56470.00 40000 211502.51 50000 81584.54 70000 53131.09 80000 15902.64 100000 306639.29 130000 183113.29 140000 250958.13La segunda columna es el valor total más alto de los pedidos de 1994 de las claves de cliente de muestra de la primera columna.
Para ejecutar la misma consulta en BigQuery, debes transformar la secuencia de comandos SQL a fin de que se ajuste a ANSI/ISO SQL.
Dirígete a la consola de BigQuery:
Copia la siguiente consulta traducida al editor de consultas:
SELECT O_CUSTKEY, O_TOTALPRICE FROM ( SELECT O_CUSTKEY, O_TOTALPRICE, ROW_NUMBER() OVER ( PARTITION BY O_CUSTKEY ORDER BY O_TOTALPRICE DESC ) as row_num FROM tpch.orders WHERE EXTRACT(YEAR FROM O_ORDERDATE) = 1994 AND MOD(O_CUSTKEY, 10000) = 0 ) WHERE row_num = 1Esta nueva consulta presenta algunos cambios, ninguno de los cuales se puede hacer con una simple búsqueda y reemplazo. Ten en cuenta lo siguiente:
- Se quita la cláusula
QUALIFYy la función analíticaROW_NUMBER()se mueve como una columna a la instrucciónSELECTy se le asigna un alias (as row_num). - Se crea una consulta de cierre si no existe, y se le agrega una condición
WHERE, con el filtro de valor analítico (row_num = 1). - El operador
MODde Teradata tampoco es estándar y, por lo tanto, lo modifica la funciónMOD().
- Se quita la cláusula
Haz clic en Ejecutar.
El resultado en columnas es el mismo que el de Teradata.
Referencias de columnas cruzadas
Teradata admite referencias cruzadas entre columnas definidas dentro de la misma consulta. En esta sección, se usa una consulta que asigna un alias a una instrucción SELECT anidada y, luego, se hace referencia a ese alias en una expresión CASE.
Para ilustrar esto, puedes ejecutar una consulta que determine si un cliente estuvo activo en un año determinado. Un cliente está activo si realizó al menos un pedido durante el año.
En la computadora en la que tienes BTEQ instalado, cambia o abre el símbolo del sistema de BTEQ. Si cerraste BTEQ, ejecuta este comando:
bteqCopia la siguiente consulta de SQL de Teradata a la ventana de BTEQ:
SELECT ( SELECT COUNT(O_CUSTKEY) FROM tpch.orders WHERE O_CUSTKEY = 2 AND EXTRACT(YEAR FROM O_ORDERDATE) = 1994 ) AS num_orders, CASE WHEN num_orders = 0 THEN 'INACTIVE' ELSE 'ACTIVE' END AS status;Ten en cuenta lo siguiente sobre la consulta:
- Hay una consulta anidada que cuenta la cantidad de veces que aparece la clave de cliente
2en el año 1994. El resultado de esta consulta se muestra en la primera columna y se le asigna el aliasnum_orders. - En la segunda columna, la expresión
CASEgeneraACTIVEsi la cantidad de pedidos que se encontró no es cero; de lo contrario, generaINACTIVE. La expresiónCASEusa de forma interna el alias de la primera columna de la misma consulta (num_orders).
- Hay una consulta anidada que cuenta la cantidad de veces que aparece la clave de cliente
Ejecuta la consulta.
El resultado es similar al siguiente:
num_orders status ----------- -------- 3 ACTIVE
Para ejecutar la misma consulta en BigQuery, debes borrar la referencia entre columnas en la misma consulta.
Dirígete a la consola de BigQuery:
Copia la siguiente consulta traducida en el editor de consultas:
SELECT customer.num_orders, CASE WHEN customer.num_orders = 0 THEN 'INACTIVE' ELSE 'ACTIVE' END AS status FROM ( SELECT COUNT(O_CUSTKEY) AS num_orders FROM tpch.orders WHERE O_CUSTKEY = 2 AND EXTRACT(YEAR FROM O_ORDERDATE) = 1994 ) customer;Ten en cuenta los cambios siguientes respecto a la consulta original:
- La consulta anidada se traslada a la cláusula
FROMde una consulta adjunta. Tiene el aliascustomer, pero este no define una columna de salida porque está en una cláusulaFROMen contraposición a una cláusulaSELECT. - La cláusula
SELECTtiene dos columnas:- La primera columna muestra el número de pedidos (
num_orders) definidos en la consulta anidada (customer). - La segunda columna incluye la instrucción
CASEque hace referencia a la cantidad de pedidos definidos en la consulta anidada.
- La primera columna muestra el número de pedidos (
- La consulta anidada se traslada a la cláusula
Haz clic en Ejecutar.
El resultado en columnas es el mismo que el de Teradata.
Limpia
Para evitar incurrir en cargos en tu cuenta de Google Cloud por los recursos que se usaron en este instructivo, bórralos.
Borra el proyecto
La forma más sencilla de detener los cargos de facturación es borrar el proyecto que creaste para este instructivo.
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que quieres borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrar el proyecto.
¿Qué sigue?
- Consulta la referencia de traducción de SQL de Teradata a BigQuery para obtener una visión detallada de las diferencias y asignaciones entre el SQL de Teradata y el SQL estándar que se usa en BigQuery.
- Continúa con la siguiente parte de esta serie: Administración de datos.
- Consulta las ofertas de la Professional Service Organization de Google y nuestro extenso ecosistema de socios, que consta de empresas que pueden ayudarte en tu proceso de migración.
- Explora arquitecturas de referencia, diagramas, instructivos y prácticas recomendadas sobre Google Cloud. Consulta nuestro Cloud Architecture Center.