이 문서는 Google Cloud에서 AI Platform을 사용하여 고객평생가치(CLV)를 예측하는 방법을 설명하는 4부로 구성된 시리즈 중 두 번째 문서입니다.
이 시리즈의 문서는 다음과 같습니다.
- 1부: 소개. CLV와 CLV를 예측하는 2가지 모델링 기법을 소개합니다.
- 2부: 모델 학습(이 문서). 데이터를 준비하고 모델을 학습시키는 방법을 설명합니다.
- 3부: 프로덕션에 배포. 2부에서 설명된 모델을 프로덕션 시스템에 배포하는 방법을 설명합니다.
- 4부: AutoML Tables 사용. AutoML Tables를 사용하여 모델을 빌드하고 배포하는 방법을 보여줍니다.
이 시스템을 구현하는 코드는 GitHub 저장소에 있습니다. 이 시리즈에서는 이 코드의 용도와 사용 방법을 설명합니다.
소개
이 문서는 고객평생가치(CLV)를 예측하는 다음 2가지 모델을 살펴본 1부에 이어지는 문서입니다.
- 확률 모델
- 머신러닝 모델의 일종인 심층신경망(DNN) 모델
1부에서 언급한 것처럼 이 시리즈의 목표 중 하나는 CLV를 예측하는 이 모델들을 비교하는 것입니다. 시리즈의 이 부분에서는 CLV를 예측하기 위해 데이터를 준비하고 이 2가지 모델을 빌드하고 학습시키는 방법을 설명하고, 몇 가지 비교 정보를 제공합니다.
코드 설치
이 문서에 설명된 절차를 따르려면 GitHub에서 샘플 코드를 설치해야 합니다.
gcloud CLI가 설치되었으면 컴퓨터에서 터미널 창을 열어 이 명령어를 실행합니다. gcloud CLI가 설치되지 않았으면 Cloud Shell 인스턴스를 엽니다.
샘플 코드 저장소를 클론합니다.
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
README 파일의 설치 섹션에 있는 설치 안내에 따라 환경을 설정합니다.
데이터 준비
이 섹션에서는 데이터를 가져오고 정리하는 방법을 설명합니다.
소스 데이터 세트 가져오기 및 정리
CLV를 계산하려면 먼저 소스 데이터에 적어도 다음이 포함되어 있는지 확인해야 합니다.
- 개별 고객을 식별하는 데 사용되는 고객 ID.
- 고객이 특정 시간에 지출한 액수를 보여 주는 고객당 구매 금액.
- 각 구매 날짜.
이 문서에서는 공개적으로 사용 가능한 UCI Machine Learning Repository[1]의 Online Retail Data Set의 이전 판매 데이터를 사용하여 모델을 학습시키는 방법을 살펴봅니다.
첫 번째 단계는 데이터 세트를 CSV 파일로 Cloud Storage에 복사하는 것입니다.
그런 다음 BigQuery용 로딩 도구 중 하나를 사용하여 data_source라는 테이블을 만듭니다. 임의의 이름이지만 GitHub 저장소의 코드는 이 이름을 사용합니다. 데이터 세트는 이 시리즈에 연결된 공개 버킷에서 제공되며, 이미 CSV 형식으로 변환되었습니다.
- 컴퓨터 또는 Cloud Shell에서 GitHub 저장소에 있는 README 파일의 설정 섹션에 설명된 명령어를 실행합니다.
예시 데이터 세트에는 다음 표에 나열된 필드가 포함되어 있습니다. 이 문서에서 설명하는 방식의 경우 사용됨 열이 예로 설정된 필드만 사용합니다. 일부 필드는 직접 사용되지 않지만 새 필드를 만드는 데 도움이 됩니다. 예를 들어 UnitPrice와 Quantity는 order_value를 만듭니다.
| 사용됨 | 필드 | 유형 | 설명 |
|---|---|---|---|
| 아니요 | InvoiceNo |
STRING |
명목. 각 트랜잭션에 고유하게 할당된 6자리 정수입니다.
이 코드가 문자 c로 시작되면 취소를 나타냅니다. |
| 아니요 | StockCode |
STRING |
제품(품목) 코드입니다. 각 고유 제품에 고유하게 할당된 명목적 5자리 정수입니다. |
| 아니요 | Description |
STRING |
제품(품목) 이름입니다. 명목. |
| 예 | Quantity |
INTEGER |
트랜잭션당 각 제품(품목)의 수량입니다. 숫자. |
| 예 | InvoiceDate |
STRING |
mm/dd/yy hh:mm 형식의 인보이스 날짜 및 시간입니다. 각 트랜잭션이 생성된 날짜와 시간입니다. |
| 예 | UnitPrice |
FLOAT |
단가입니다. 숫자. 파운드로 표시한 제품 단가입니다. |
| 예 | CustomerID |
STRING |
고객 번호입니다. 명목. 각 고객에 고유하게 할당된 5자리 정수입니다. |
| 아니요 | Country |
STRING |
국가 이름입니다. 명목. 각 고객이 거주하는 국가의 이름입니다. |
데이터 정리
사용하는 모델에 상관없이 모든 모델에 공통적인 준비 및 정리 단계를 수행해야 합니다. 작업 가능한 필드와 레코드 세트를 얻으려면 다음 작업이 필요합니다.
- 이 솔루션의 확률 모델이 사용하는 최소 시간 단위는 하루이므로
InvoiceNo를 사용하는 대신 일별로 주문을 그룹화합니다. - 확률 모델에 유용한 필드만 유지합니다.
- 구매와 같이 주문 수량과 금전적 가치가 양수인 레코드만 유지합니다.
- 반품과 같이 주문 수량이 음수인 레코드만 유지합니다.
- 고객 ID가 있는 레코드만 유지합니다.
- 지난 90일 동안 물건을 구매한 고객만 유지합니다.
- 특성 생성에 사용되는 기간에 2회 이상 구입한 고객만 유지합니다.
이 모든 작업은 다음 BigQuery 쿼리를 사용하여 수행할 수 있습니다. (이전 명령어처럼 GitHub 저장소를 클론할 때마다 이 코드를 실행합니다.) 데이터가 오래되었기 때문에 이 문서의 목적상 2011년 12월 12일을 오늘 날짜로 간주합니다.
이 쿼리는 다음 2가지 작업을 수행합니다. 먼저 작업 데이터 세트가 큰 경우에 쿼리가 데이터 세트를 축소합니다. (이 솔루션의 작업 데이터 세트는 상당히 작지만 이 쿼리는 엄청나게 큰 데이터 세트를 몇 초 안에 두 자리 줄일 수 있습니다.)
둘째, 다음과 같이 작업할 기본 데이터세트를 만듭니다.
customer_id
|
order_date
|
order_value
|
order_qty_articles
|
|---|---|---|---|
| 16915 | 2011-08-04 | 173.7 | 6 |
| 15349 | 2011-07-04 | 107.7 | 77 |
| 14794 | 2011-03-30 | -33.9 | -2 |
정리된 데이터세트에는 order_qty_articles 필드도 포함됩니다. 이 필드는 다음 섹션에서 설명하는 심층신경망(DNN)에서 사용하기 위해서만 포함되었습니다.
학습 간격 및 목표 간격 정의
모델 학습을 준비하려면 기준일을 선택해야 합니다. 이 날짜는 주문을 다음 두 파티션으로 분리합니다.
- 기준일 이전의 주문은 모델 학습에 사용됩니다.
- 기준일 이후의 주문은 목푯값을 계산하는 데 사용됩니다.

Lifetimes 라이브러리에는 데이터 사전 처리를 위한 메서드가 포함되어 있습니다. 하지만 CLV에 사용하는 데이터 세트는 상당히 클 수 있으므로 단일 머신에서 데이터를 사전 처리하기가 현실적으로 어렵습니다. 이 문서에서 설명하는 방식은 BigQuery에서 직접 실행되는 쿼리를 사용하여 주문을 2개의 세트로 나누는 것입니다 ML 모델과 확률 모델은 동일한 쿼리를 사용하므로 두 모델 모두 동일한 데이터에서 작동할 수 있습니다.
ML 모델과 확률 모델의 최적 기준일은 다를 수 있습니다. SQL 문 안에서 직접 이 날짜 값을 업데이트할 수 있습니다. 최적 기준일을 초매개변수로 생각하세요. 데이터를 탐색하고 몇 가지 테스트 학습을 실행하여 가장 적절한 값을 찾을 수 있습니다.
기준일은 정리된 데이터 테이블에서 학습 데이터를 선택하는 SQL 쿼리의 WHERE 절에 사용됩니다. 다음 예시를 참조하세요.
데이터 집계
데이터를 학습 간격과 목표 간격으로 나눈 후 집계해 각 고객의 실제 특성과 목표를 생성합니다. 확률 모델의 경우 집계는 최근 구매일, 빈도, 금액(RFM) 필드로 제한됩니다. DNN 모델도 RFM 특성을 사용하지만 추가 특성을 사용하여 예측을 개선할 수 있습니다.
다음 쿼리는 DNN 모델과 확률 모델의 특성을 동시에 생성하는 방법을 설명합니다.
다음 표는 쿼리가 생성하는 특성을 나타냅니다.
| 특성 이름 | 설명 | 확률 | DNN |
|---|---|---|---|
monetary_dnn
|
특성 기간 동안 고객별 모든 주문의 금전적 가치 합계입니다. | x | |
monetary_btyd
|
특성 기간 동안 각 고객의 모든 주문의 금전적 가치 평균입니다. 확률 모델은 첫 주문의 값이 0이라고 가정합니다. 이는 쿼리에 의해 적용됩니다. | x | |
recency
|
특성 기간 동안 고객의 첫 번째 주문과 마지막 주문 사이의 시간입니다. | x | |
frequency_dnn
|
특성 기간 동안 고객의 주문 수입니다. | x | |
frequency_btyd
|
특성 기간 동안 고객의 주문 수에서 첫 번째 주문을 뺀 값입니다. | x | |
T
|
고객의 첫 번째 주문과 특성 기간의 종료 시점 사이의 시간입니다. | x | x |
time_between
|
특성 기간 동안 고객의 주문 사이의 평균 시간입니다. | x | |
avg_basket_value
|
특성 기간 동안 고객 바스켓의 금전적 가치 평균입니다. | x | |
avg_basket_size
|
특성 기간 동안 고객의 바스켓에 있는 평균 품목 수입니다. | x | |
cnt_returns
|
특성 기간 동안 고객이 반품한 주문 수입니다. | x | |
has_returned
|
특성 기간 동안 고객이 1개 이상의 주문을 반품했는지 여부입니다. | x | |
frequency_btyd_clipped
|
frequency_btyd와 같지만 상한 이상점에 의해 잘립니다. |
x | |
monetary_btyd_clipped
|
monetary_btyd와 같지만 상한 이상점에 의해 잘립니다. |
x | |
target_monetary_clipped
|
target_monetary와 같지만 상한 이상점에 의해 잘립니다. |
x | |
target_monetary
|
학습 및 목표 기간을 포함하여 고객이 지출한 총 금액입니다. | x |
이러한 열의 선택은 코드에서 이루어집니다. 확률 모델에서는 Pandas DataFrame을 사용하여 선택합니다.
DNN 모델의 경우 TensorFlow 특성은 context.py 파일에 정의됩니다. 이러한 모델에서 다음은 특성으로 무시됩니다.
customer_id: 특성으로 유용하지 않은 고유한 값입니다.target_monetary: 모델이 예측해야 하는 목표이므로 입력으로는 사용되지 않습니다.
DNN을 위한 학습, 평가, 테스트 세트 만들기
이 섹션은 DNN 모델에만 적용됩니다. ML 모델을 학습시키려면 겹치지 않는 다음 3가지 데이터세트를 사용해야 합니다.
학습(70~80%) 데이터 세트는 손실 함수를 줄이기 위해 가중치를 학습하는 데 사용됩니다. 학습은 손실 함수가 더 이상 감소하지 않을 때까지 계속됩니다.
평가(10~15%) 데이터 세트는 모델이 학습 데이터에서는 잘 작동하지만 일반화가 잘 되지 않는 과적합을 방지하기 위해 학습 도중에 사용됩니다.
테스트(10~15%) 데이터 세트는 모든 학습과 평가가 완료된 후 모델 성능을 최종적으로 측정하기 위해 한 번만 사용해야 합니다. 이 데이터 세트는 학습 과정 중 모델에서 보이지 않는 데이터 세트이므로 통계적으로 타당한 모델 정확성 척도를 제공합니다.
다음 쿼리는 약 70%의 데이터로 학습 세트를 생성합니다. 이 쿼리는 다음 기법을 사용하여 데이터를 분리합니다.
- 고객 ID의 해시가 계산되어 정수를 생성합니다.
- 특정 임계값 이하의 해시 값을 선택하기 위해 모듈로 연산이 사용됩니다.
평가 세트와 테스트 세트에도 동일한 개념이 사용되어 임계값 이상의 데이터가 유지됩니다.
학습
이전 섹션에서 보았듯이 다른 모델을 사용하여 CLV를 예측할 수도 있습니다. 이 문서에 사용된 코드는 사용할 모델을 결정하는 것을 돕기 위한 것입니다. 다음 학습 셸 스크립트에 전달하는 model_type 매개변수를 사용하여 모델을 선택합니다. 나머지는 코드가 처리합니다.
학습의 첫 번째 목표는 두 모델 모두 아래에서 정의하는 나이브(naive) 벤치마크를 능가하는 것입니다. 두 모델 유형 모두 벤치마크를 능가할 수 있다면(또한 능가해야 한다면) 각 유형의 성능을 서로 비교할 수 있습니다.
모델 벤치마킹
이 시리즈의 목적상 나이브 벤치마크는 다음 매개변수를 통해 정의됩니다.
- 평균 바스켓 값. 이는 기준일 이전에 이루어지는 모든 주문에서 계산됩니다.
- 주문 수. 이는 기준일 이전에 이루어지는 모든 주문에서 학습 간격에 대해 계산됩니다.
- 카운트 승수. 이는 기준일 이전의 일수와 기준일과 현재 사이의 일수의 비율에 기초하여 계산됩니다.
이 벤치마크는 학습 간격 동안 고객의 구매 비율이 목표 간격 내내 일정하게 유지된다고 단순하게 가정합니다. 따라서 고객이 40일 동안 6회 구입했다면 60일 동안에는 9회 구입한다고 가정합니다(60/40 * 6 = 9). 각 고객의 카운트 승수, 주문 수, 평균 바스켓 값을 곱하면 해당 고객의 단순 예측 목표 값이 나옵니다.
벤치마크 오류는 평균 제곱근 오차(RMSE), 즉 모든 고객의 예상 목표 값과 실제 목표 값의 절대차 평균입니다. RMSE는 BigQuery에서 다음 쿼리를 사용하여 계산됩니다.
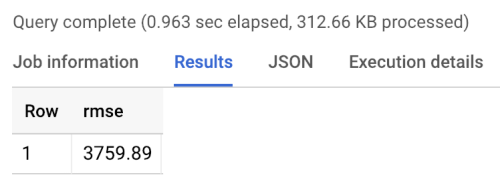
벤치마크는 다음과 같은 벤치마크 실행 결과에 나타난 것처럼 3760의 RMSE를 반환합니다. 모델은 이 값을 능가해야 합니다.
확률 모델
이 시리즈의 1부에서 설명한 것처럼 이 시리즈에서는 파레토/음이항 분포(NBD) 및 베타-지오메트릭 BG/NBD 모델을 비롯한 다양한 모델을 지원하는 Lifetimes라는 Python 라이브러리를 사용합니다. 다음 샘플 코드는 Lifetimes 라이브러리를 사용하여 확률 모델로 평생가치 예측을 수행하는 방법을 보여줍니다.
로컬 환경에서 확률 모델을 사용하여 CLV 결과를 생성하려면 다음 mltrain.sh 스크립트를 실행하면 됩니다. 학습 분할의 시작일 및 종료일 매개변수와 예측 기간 종료 매개변수를 제공합니다.
./mltrain.sh local data --model_type paretonbd_model --threshold_date [YOUR_THRESHOLD_DATE] --predict_end [YOUR_END_DATE]
DNN 모델
샘플 코드에는 맞춤 에스티메이터 모델뿐 아니라 미리 만든 에스티메이터 DNNRegressor 클래스를 사용한 DNN TensorFlow에서의 구현이 포함되어 있습니다. DNNRegressor 및 맞춤 에스티메이터는 같은 수의 레이어와 각 레이어의 뉴런 수를 사용합니다. 이러한 값은 조정이 필요한 초매개변수입니다. 다음 task.py 파일에서 수동으로 테스트하여 우수한 결과를 얻은 값으로 설정된 일부 초매개변수의 목록을 찾을 수 있습니다.
AI Platform을 사용 중인 경우, yaml 파일에서 정의한 매개변수 범위에 걸쳐 테스트하는 초매개변수 미세 조정 기능을 사용할 수 있습니다. AI Platform은 Bayesian 최적화를 사용하여 초매개변수 공간을 검색합니다.
모델 비교 결과
다음 표는 샘플 데이터 세트로 학습된 각 모델의 RMSE 값을 나타냅니다. 모든 모델은 RFM 데이터로 학습됩니다. 무작위 매개변수 초기화로 인해 RMSE 값은 실행마다 조금씩 다릅니다. DNN 모델은 평균 바스켓 값과 반품 횟수 같은 추가 특성을 사용합니다.
| 모델 | RMSE |
|---|---|
| DNN | 947.9 |
| BG/NBD | 1557 |
| 파레토/NBD | 1558 |
결과는 이 데이터 세트에서 금전적 가치를 예측할 때 DNN 모델이 확률 모델보다 우수함을 보여줍니다. 하지만 UCI 데이터 세트의 크기가 상대적으로 작기 때문에 이러한 결과의 통계적 타당성은 제한적입니다. 어느 모델이 최상의 결과를 제공하는지 알려면 데이터 세트에서 각 기법을 시도해 봐야 합니다. 모든 모델은 동일한 원본 데이터(고객 ID, 주문일, 주문값 등)를 해당 데이터에서 추출한 RFM 값에 사용하여 학습되었습니다. DNN 학습 데이터에는 평균 바스켓 크기와 반품 횟수 같은 일부 추가 특성이 포함되었습니다.
DNN 모델은 전체적인 고객 금전 가치만 출력합니다. 빈도 또는 변동 예측에 관심이 있다면 몇 가지 추가 작업을 수행해야 합니다.
- 목표를 변경하고 기준일도 변경하려면 데이터를 다르게 준비합니다.
- 관심이 있는 목표를 예측하려면 회귀 모델을 다시 학습시킵니다.
- 초매개변수를 조정합니다.
여기서 의도는 동일한 입력 특성에서 2가지 모델 유형을 비교하는 것이었습니다. DNN 사용의 한 가지 장점은 이 예시에서 사용된 것보다 많은 특성을 추가하여 결과를 개선할 수 있다는 것입니다. DNN을 사용하면 클릭스트림 이벤트, 사용자 프로필 또는 제품 기능 같은 소스의 데이터를 활용할 수 있습니다.
감사의 말씀
Dua, D.와 Karra Taniskidou, E. (2017). UCI Machine Learning Repository http://archive.ics.uci.edu/ml. Irvine, CA: University of California, School of Information and Computer Science.
다음 단계
- 이 시리즈의 3부: 프로덕션에 배포를 읽고 이러한 모델의 배포 방법 이해하기
- 다른 예측 솔루션 알아보기
- Google Cloud에 대한 참조 아키텍처, 다이어그램, 권장사항 살펴보기. Cloud 아키텍처 센터 살펴보기