이 문서는 Google Cloud에서 AI Platform을 사용하여 고객평생가치(CLV)를 예측하는 방법을 설명하는 4부로 구성된 시리즈 중 네 번째 문서입니다. 이 문서에서는 AutoML Tables를 사용하여 예측을 수행하는 방법을 보여줍니다.
이 시리즈의 문서는 다음과 같습니다.
- 1부: 소개. CLV와 CLV를 예측하는 2가지 모델링 기법을 소개합니다.
- 2부: 모델 학습 데이터를 준비하고 모델을 학습시키는 방법을 설명합니다.
- 3부: 프로덕션에 배포. 2부에서 설명된 모델을 프로덕션 시스템에 배포하는 방법을 설명합니다.
- 4부: AutoML Tables 사용(본 문서). AutoML Tables를 사용하여 모델을 빌드 및 배포하는 방법을 설명합니다.
이 문서에서 설명하는 프로세스에서는 이 시리즈의 2부에서 설명된 단계와 동일한 BigQuery의 데이터 처리 단계를 사용합니다. 이 문서에서는 BigQuery 데이터 세트를 AutoML Tables에 업로드하여 모델을 만드는 방법을 보여줍니다. 또한 3부에 설명된 대로 AutoML 모델을 프로덕션 시스템에 통합하는 방법도 보여줍니다.
이 시스템을 구현하는 코드는 원래 시리즈와 동일한 GitHub 저장소에 있습니다. 이 문서에서는 해당 저장소에서 AutoML Tables의 코드 사용 방법에 대해 설명합니다.
AutoML Tables의 이점
해당 시리즈의 이전 파트에서는 TensorFlow에서 구현된 통계 모델과 DNN 모델을 모두 사용하여 CLV를 예측하는 방법을 살펴보았습니다. AutoML Tables에는 다른 두 가지 방법에 비해 다음과 같은 몇 가지 이점이 있습니다.
- 모델을 만들기 위해 코딩이 필요하지 않습니다. 데이터 세트와 모델을 생성, 학습, 관리, 배포할 수 있는 콘솔 UI가 있습니다.
- 기능 추가 또는 변경이 간단하고 콘솔 인터페이스에서 직접 수행할 수 있습니다.
- 초매개변수 조정을 포함한 학습 프로세스가 자동화됩니다.
- AutoML Tables는 데이터 세트에 가장 적합한 아키텍처를 검색하므로 이용 가능한 많은 옵션 중에서 선택해야 하는 부담을 줄여줍니다.
- AutoML Tables는 기능의 중요성을 포함하여 학습된 모델의 성능에 대한 상세 분석을 제공합니다.
따라서 AutoML Tables를 사용하여 완전히 최적화된 모델을 개발하고 학습시키는 데 소요되는 시간과 비용을 줄일 수 있습니다.
AutoML Tables 솔루션의 프로덕션 배포를 수행하려면 Python 클라이언트 API를 사용하여 모델을 만들어서 배포하고 예측을 실행해야 합니다. 이 문서에서는 클라이언트 API를 사용하여 AutoML Tables 모델을 만들고 학습시키는 방법을 보여줍니다. AutoML Tables 콘솔을 사용하여 이 단계를 수행하는 방법은 AutoML Tables 문서를 참조하세요.
코드 설치
원래 시리즈의 코드를 설치하지 않은 경우 원래 시리즈의 2부에 설명된 것과 동일한 단계에 따라 코드를 설치합니다. GitHub 저장소의 README 파일은 환경을 준비하고 코드를 설치하며 프로젝트에서 AutoML Tables를 설정하는 데 필요한 모든 단계를 설명합니다.
이전에 코드를 설치한 경우 다음 추가 단계를 수행하여 이 문서용 설치를 완료해야 합니다.
- 프로젝트에서 AutoML Tables API를 사용 설정합니다.
- 이전에 설치한 miniconda 환경을 활성화합니다.
- AutoML Tables 문서의 설명대로 Python 클라이언트 라이브러리를 설치합니다.
- API 키 파일을 만들고 다운로드한 후 나중에 클라이언트 라이브러리에서 사용할 수 있도록 알려진 위치에 저장합니다.
코드 실행
이 문서의 많은 단계에서 Python 명령어를 실행합니다. 환경을 준비하고 코드를 설치하면 다음 옵션을 사용하여 코드를 실행할 수 있습니다.
Jupyter 노트북에서 코드를 실행합니다. 활성화된 miniconda 환경의 터미널 창에서 다음 명령어를 실행합니다.
$ (clv) jupyter notebook
이 문서의 각 단계에 대한 코드는
notebooks/clv_automl.ipynb라는 코드 저장소의 노트북에 있습니다. Jupyter 인터페이스에서 이 노트북을 엽니다. 그런 다음 가이드에 따라 진행하면서 각 단계를 실행할 수 있습니다.코드를 Python 스크립트로 실행합니다. 이 가이드의 코드 단계는
clv_automl/clv_automl.py파일의 코드 저장소에 있습니다. 스크립트는 명령줄에서 프로젝트 ID, API 키 파일의 위치, Google Cloud 리전, BigQuery 데이터 세트의 이름과 같은 구성 가능한 매개변수에 대한 인수를 사용합니다. 활성화된 miniconda 환경의 터미널 창에서 스크립트를 실행하여[YOUR_PROJECT]를 Google Cloud 프로젝트 이름으로 바꿉니다.$ (clv) cd clv_automl $ (clv) python clv_automl.py --project_id [YOUR_PROJECT]
매개변수와 기본값의 전체 목록은 스크립트의
create_parser메서드를 참조하거나, 인수 없이 스크립트를 실행하여 사용법 문서를 참조합니다.README에 설명된 대로 Cloud Composer 환경을 설치한 후, DAG 실행의 후반부에 설명된 대로 DAG를 실행하여 코드를 실행합니다.
데이터 준비
이 문서에서는 원래 시리즈 2부에 설명된 것과 동일한 BigQuery의 데이터 세트 및 데이터 준비 단계를 사용합니다. 해당 문서의 설명대로 데이터 집계를 완료하면 AutoML Tables에서 사용할 수 있는 데이터 세트를 만들 준비가 된 것입니다.
AutoML Tables 데이터 세트 만들기
시작하려면 BigQuery에서 준비한 데이터를 AutoML Tables에 업로드하세요.
클라이언트를 시작하려면 키 파일 이름을 설치 단계에서 다운로드한 목록의 이름으로 설정합니다.
keyfile_name = "mykey.json" client = automl_v1beta1.AutoMlClient.from_service_account_file(keyfile_name)데이터 세트를 만듭니다.
create_dataset_response = client.create_dataset( location_path, {'display_name': dataset_display_name, 'tables_dataset_metadata': {}}) dataset_name = create_dataset_response.name
BigQuery에서 데이터 가져오기
데이터 세트를 만든 후 BigQuery에서 데이터를 가져올 수 있습니다.
BigQuery의 데이터를 AutoML Tables 데이터 세트로 가져옵니다.
dataset_bq_input_uri = 'bq://{}.{}.{}'.format(args.project_id, args.bq_dataset, args.bq_table) input_config = { 'bigquery_source': { 'input_uri': dataset_bq_input_uri}} import_data_response = client.import_data(dataset_name, input_config)
모델 학습
CLV 데이터의 AutoML 데이터 세트를 만든 후 AutoML Tables 모델을 만들 수 있습니다.
각 열의 AutoML Tables 열 사양을 데이터 세트로 가져옵니다.
list_table_specs_response = client.list_table_specs(dataset_name) table_specs = [s for s in list_table_specs_response] table_spec_name = table_specs[0].name list_column_specs_response = client.list_column_specs(table_spec_name) column_specs = {s.display_name: s for s in list_column_specs_response}열 사양은 이후 단계에서 필요합니다.
열 중 하나를 AutoML Tables 모델의 라벨로 할당합니다.
TARGET_LABEL = 'target_monetary' ... label_column_name = TARGET_LABEL label_column_spec = column_specs[label_column_name] label_column_id = label_column_spec.name.rsplit('/', 1)[-1] update_dataset_dict = { 'name': dataset_name, 'tables_dataset_metadata': { 'target_column_spec_id': label_column_id } } update_dataset_response = client.update_dataset(update_dataset_dict)이 코드는 2부에 나와 있는 TensorFlow DNN 모델과 동일한 라벨 열(
target_monetary)을 사용합니다.모델을 학습시키기 위한 특성을 정의합니다.
feat_list = list(column_specs.keys()) feat_list.remove('target_monetary') feat_list.remove('customer_id') feat_list.remove('monetary_btyd') feat_list.remove('frequency_btyd') feat_list.remove('frequency_btyd_clipped') feat_list.remove('monetary_btyd_clipped') feat_list.remove('target_monetary_clipped')AutoML Tables 모델을 학습시키는 데 사용된 특성은 원래 시리즈 2부에서 TensorFlow DNN 모델을 학습시키는 데 사용된 특성과 동일합니다. 하지만 AutoML Tables를 사용하면 한결 쉽게 모델에서 특성을 추가하거나 제거할 수 있습니다. BigQuery에서 만들어진 특성은 앞의 코드 스니펫에 표시된 대로 명시적으로 삭제하지 않는 한 자동으로 모델에 포함됩니다.
모델을 만드는 옵션을 정의합니다. 이 데이터 세트에는 매개변수
MINIMIZE_MAE로 표시되는 평균 절대 오차를 최소화하는 최적화 목표가 권장됩니다.model_display_name = args.automl_model model_training_budget = args.training_budget * 1000 model_dict = { 'display_name': model_display_name, 'dataset_id': dataset_name.rsplit('/', 1)[-1], 'tables_model_metadata': { 'target_column_spec': column_specs['target_monetary'], 'input_feature_column_specs': [ column_specs[x] for x in feat_list], 'train_budget_milli_node_hours': model_training_budget, 'optimization_objective': 'MINIMIZE_MAE' } }자세한 내용은 최적화 목표에 관한 AutoML Tables 문서를 참조하세요.
모델을 만들고 학습을 시작합니다.
create_model_response = client.create_model(location_path, model_dict) create_model_result = create_model_response.result() model_name = create_model_result.name클라이언트 호출(
create_model_response)의 반환 값이 즉시 반환됩니다.create_model_response.result()값은 학습이 완료될 때까지 차단하는 프라미스입니다.model_name값은 모델에서 작동하는 추가 클라이언트 호출에 필요한 리소스 경로입니다.
모델 평가
모델 학습이 완료되면 모델 평가 통계를 검색할 수 있습니다. Google Cloud Console 또는 클라이언트 API를 사용할 수 있습니다.
Console을 사용하려면 AutoML Tables 콘솔에서 평가 탭으로 이동합니다.

클라이언트 API를 사용하려면 모델 평가 통계를 검색합니다.
model_evaluations = [e for e in client.list_model_evaluations(model_name)] model_evaluation = model_evaluations[0]다음과 비슷한 출력이 표시됩니다.
name: "projects/595920091534/locations/us-central1/models/TBL3912308662231629824/modelEvaluations/9140437057533851929" create_time { seconds: 1553108019 nanos: 804478000 } evaluated_example_count: 125 regression_evaluation_metrics: { mean_absolute_error: 591.091 root_mean_squared_error: 853.481 mean_absolute_percentage_error: 21.47 r_squared: 0.907 }
853.481의 평균 제곱근 오차가 원래 시리즈에서 사용된 확률 모델 및 TensorFlow 모델에 비해 유리합니다. 그러나 2부에 설명된 대로 제공된 각 기술을 데이터와 함께 사용해 보고 가장 적합한 기술을 확인하는 것이 좋습니다.
AutoML 모델 배포
원래 시리즈의 Cloud Composer DAG가 학습 및 예측에 AutoML Tables 모델을 포함하도록 업데이트되었습니다. Cloud Composer DAG 기능에 대한 일반 정보는 원래 문서 3부의 솔루션 자동화 섹션을 참조하세요.
README의 안내에 따라 이 솔루션에 대한 Cloud Composer 조정 시스템을 설치할 수 있습니다.
업데이트된 DAG는 모델을 만들고 예측을 실행하기 위해 이전에 표시된 클라이언트 코드 호출을 복제하는 clv_automl/clv_automl.py 스크립트의 메서드를 호출합니다.
학습 DAG
업데이트된 학습용 DAG에는 AutoML Tables 모델을 만드는 태스크가 포함됩니다. 아래 다이어그램은 새로운 학습용 DAG를 보여줍니다.

예측 DAG
업데이트된 예측용 DAG에는 AutoML Tables 모델로 일괄 예측을 실행하는 태스크가 포함됩니다. 아래 다이어그램은 새로운 예측용 DAG를 보여줍니다.
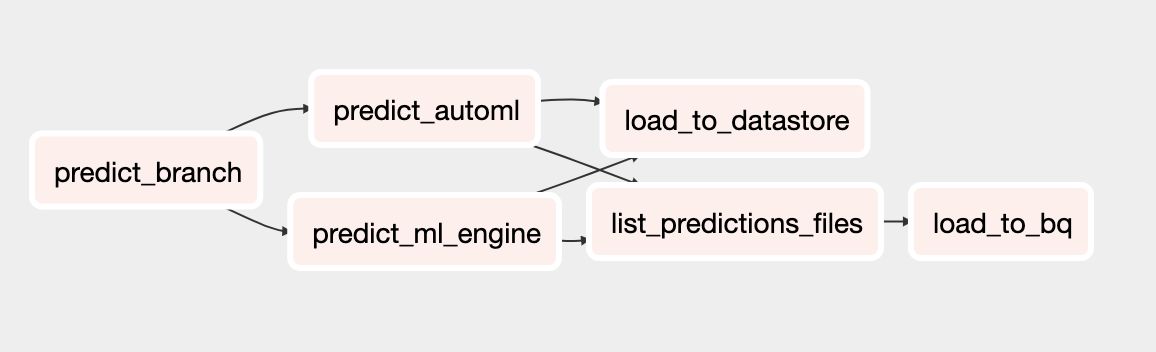
DAG 실행
DAG를 수동으로 트리거하려면 Cloud Shell의 README 파일에 있는 DAG 실행 섹션에서 또는 Google Cloud CLI를 사용하여 명령어를 실행하면 됩니다.
build_train_deployDAG를 실행하려면 다음을 수행합니다.gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ build_train_deploy \ --conf '{"model_type":"automl", "project":"'${PROJECT}'", "dataset":"'${DATASET_NAME}'", "threshold_date":"2011-08-08", "predict_end":"2011-12-12", "model_name":"automl_airflow", "model_version":"v1", "max_monetary":"15000"}'predict_serveDAG를 실행합니다.gcloud composer environments run ${COMPOSER_NAME} \ --project ${PROJECT} \ --location ${REGION} \ dags trigger \ -- \ predict_serve \ --conf '{"model_name":"automl_airflow", "model_version":"v1", "dataset":"'${DATASET_NAME}'"}'
다음 단계
- 전체 CLV 가이드 세트 검토하기
- GitHub 저장소에서 전체 예시 실행하기
- 다른 예측 솔루션 알아보기
- Google Cloud에 대한 참조 아키텍처, 다이어그램, 권장사항 살펴보기. Cloud 아키텍처 센터를 살펴보세요.