En este documento se explica cómo colaboran el equipo de Asistencia y el equipo de ingeniería de producto para resolver un incidente y proporcionarte novedades. Google Cloud
En el siguiente diagrama se muestran las responsabilidades de los equipos de ingeniería de producto y de asistencia.

En las siguientes secciones se explican estas responsabilidades.
Detección
Google Cloud usa la monitorización interna y sintética para detectar incidentes. Para obtener más información, consulta el capítulo 6 del libro Site Reliability Engineering.
Respuesta inicial
Cuando se detecta un incidente, el equipo de Google Cloud Estado del servicio gestiona las comunicaciones con los clientes. La notificación inicial de un incidente suele ser escasa y, a menudo, solo menciona el producto en cuestión. Esto se debe a que priorizamos la rapidez de las notificaciones sobre los detalles. Se pueden proporcionar detalles en actualizaciones posteriores.
Para proporcionarte la mayor cantidad de información posible sin abrumarte con problemas que no te afecten, se utilizan diferentes canales de comunicación en función del alcance y la gravedad de un problema:
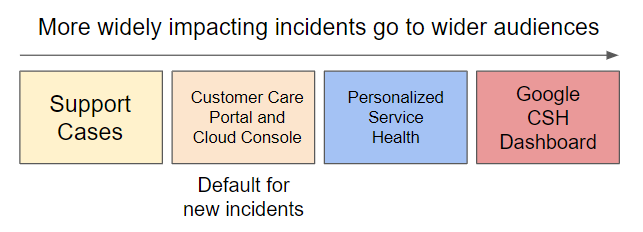
Examinar
Los equipos de ingeniería de producto se encargan de investigar las causas de los incidentes. La gestión de incidentes suele llevarla a cabo el equipo de Site Reliability Engineering, pero también pueden encargarse los ingenieros de software u otros profesionales, en función de la situación y del producto. Para obtener más información, consulta el capítulo 12 del libro Site Reliability Engineering.
Mitigación y solución
Se considera que un problema se ha solucionado cuando Google tiene la certeza de que los cambios que se han hecho acabarán con el impacto de forma indefinida. Por ejemplo, la solución podría ser revertir un cambio que haya provocado un incidente.
Mientras un incidente está en curso, Service Health y el equipo del producto intentan mitigar el problema. La mitigación se da cuando el impacto o el alcance de un problema se puede reducir, por ejemplo, proporcionando temporalmente recursos adicionales a un producto que sufre una sobrecarga.
Si no se ha encontrado ninguna medida de mitigación, el equipo de estado del servicio busca y comunica soluciones alternativas siempre que sea posible. Las soluciones alternativas son pasos que puedes seguir para solucionar la necesidad subyacente que se produce a pesar del incidente. Una solución alternativa puede ser usar ajustes diferentes para una llamada a la API y evitar así una ruta de código problemática.
Seguimiento
Mientras el incidente continúa, el equipo de estado del servicio proporciona actualizaciones periódicas. Las actualizaciones suelen proporcionar lo siguiente:
Más información sobre el incidente, como mensajes de error, zonas o regiones afectadas, funciones afectadas o porcentajes de impacto.
Progreso de la mitigación, incluidas las soluciones alternativas.
Plazos de comunicación adaptados al incidente.
Cambios de estado, como cuando se soluciona un incidente.
Retrospectiva
Todos los incidentes se someten a una retrospectiva interna para comprenderlos en profundidad e identificar las mejoras de fiabilidad que puede implementar Google. Estas mejoras se monitorizan y se implementan. Para obtener más información, consulta el capítulo 15 del libro Site Reliability Engineering.
Informe de incidentes
Cuando los incidentes tienen un impacto muy amplio y grave, Google proporciona informes de incidentes que describen los síntomas, el impacto, la causa principal, la solución y la prevención de incidentes futuros. Al igual que en las retrospectivas, prestamos especial atención a las medidas que tomamos para aprender del problema y mejorar la fiabilidad. El objetivo de Google al escribir y publicar retrospectivas es ser transparente y demostrar nuestro compromiso de crear productos estables para nuestros clientes.