Este documento explica como a equipa de apoio técnico e a equipa de engenharia de produtos trabalham em conjunto para resolver um incidente e fornecer-lhe atualizações. Google Cloud
O diagrama seguinte mostra as responsabilidades das equipas de engenharia de produtos e de apoio técnico.

As secções seguintes explicam estas responsabilidades.
Deteção
Google Cloud usa a monitorização interna e sintética para detetar incidentes. Para mais informações, consulte o capítulo 6 do livro Site Reliability Engineering.
Resposta inicial
Quando é detetado um incidente, a Google Cloud equipa de estado do serviço gere as comunicações com os clientes. A notificação inicial de um incidente é frequentemente escassa e, muitas vezes, apenas menciona o produto em questão. Isto deve-se ao facto de priorizarmos a notificação rápida em detrimento dos detalhes. Podemos fornecer detalhes em atualizações subsequentes.
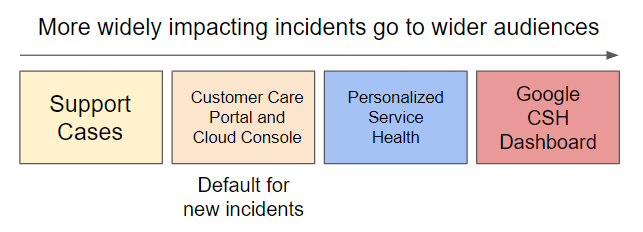
Para lhe fornecer o máximo de informações possível sem o sobrecarregar com problemas que não o afetam, são usados diferentes canais de comunicação consoante o âmbito e a gravidade de um problema:
Investigar
As equipas de engenharia de produtos são responsáveis por investigar a causa principal dos incidentes. A gestão de incidentes é frequentemente realizada por engenheiros de fiabilidade de sites, mas pode ser realizada por engenheiros de software ou outros, consoante a situação e o produto. Para mais informações, consulte o capítulo 12 do livro Site Reliability Engineering.
Mitigação e correção
Um problema é considerado corrigido apenas quando foram feitas alterações que a Google considera que vão terminar o impacto indefinidamente. Por exemplo, a correção pode ser reverter uma alteração que acionou um incidente.
Enquanto um incidente está em curso, o estado do serviço e a equipa do produto tentam mitigar o problema. A mitigação ocorre quando o impacto ou o âmbito de um problema podem ser reduzidos, por exemplo, através da disponibilização temporária de recursos adicionais a um produto que esteja a sofrer uma sobrecarga.
Se não for encontrada nenhuma mitigação, quando possível, a equipa de estado do serviço encontra e comunica soluções alternativas. As soluções alternativas são passos que pode seguir para resolver a necessidade subjacente apesar do incidente. Uma solução alternativa pode ser usar definições diferentes para uma chamada API de modo a evitar um caminho de código problemático.
Seguir
Enquanto um incidente estiver em curso, a equipa de estado do serviço envia atualizações regulares. Normalmente, as atualizações oferecem:
Mais informações sobre o incidente, como mensagens de erro, zonas ou regiões afetadas, funcionalidades afetadas ou percentagens de impacto.
Progresso em relação à mitigação, incluindo soluções alternativas.
Linhas cronológicas de comunicação, adaptadas ao incidente.
Alterações no estado, como quando um incidente é corrigido.
Retrospetiva
Todos os incidentes são sujeitos a uma retrospetiva interna para compreender totalmente o incidente e identificar melhorias de fiabilidade que a Google pode fazer. Estas melhorias são, em seguida, monitorizadas e implementadas. Para mais informações, consulte o Capítulo 15 do livro Site Reliability Engineering.
Relatório de incidentes
Quando os incidentes têm um impacto muito amplo e grave, a Google fornece relatórios de incidentes que descrevem os sintomas, o impacto, a causa principal, a correção e a prevenção futura de incidentes. Tal como nas retrospetivas, prestamos especial atenção aos passos que damos para aprender com o problema e melhorar a fiabilidade. O objetivo da Google ao escrever e publicar retrospetivas é ser transparente e demonstrar o nosso compromisso de criar produtos estáveis para os nossos clientes.