このページでは、組織またはフォルダの BigQuery データをプロファイリングする際の費用を見積もる方法について説明します。プロジェクトの見積もりを作成する場合は、単一プロジェクトのデータ プロファイリング費用を見積もるをご覧ください。
BigQuery データのプロファイリングの詳細については、BigQuery データのデータ プロファイルをご覧ください。
概要
データ プロファイルの生成を開始する前に、見積もりを実行して、BigQuery データの量とそのデータのプロファイリングにかかる費用を把握できます。見積もりを実行するには、見積もりを作成します。
見積もりを作成するときは、プロファイリングするデータを含むリソース(組織、フォルダ、またはプロジェクト)を指定します。フィルタを設定してデータ選択を微調整できます。機密データの保護がテーブルをプロファイリングする前に満たす必要がある条件も設定できます。機密データの保護は、見積もりの作成時にデータの形状、サイズ、型に基づいて見積もりを行います。
各見積もりには、リソース内で検出された一致するテーブルの数、それらすべてのテーブルの合計サイズ、リソースを 1 回だけプロファイリングする場合と毎月プロファイリングする場合の推定費用などの詳細が含まれます。
料金の計算方法の詳細については、データ プロファイリングの料金をご覧ください。
見積もりの料金
見積もりの作成に料金は発生しません。
維持率
各見積もりは 28 日後に自動的に削除されます。
制限事項
組織またはフォルダに VPC Service Controls サービス境界によって保護されているプロジェクトがある場合、機密データの保護はリソース内の BigQuery データの量を過小評価する可能性があります。サービス境界がある場合は、サービス境界ごとに独立して見積もりを作成します。
始める前に
データ プロファイリングの費用見積もりを作成、管理するために必要な権限を取得するには、組織またはフォルダに対する DLP 管理者 (roles/dlp.admin)の IAM ロール付与を管理者に依頼してください。ロールの付与については、プロジェクト、フォルダ、組織に対するアクセス権の管理をご覧ください。
必要な権限は、カスタムロールや他の事前定義ロールから取得することもできます。
見積もりを作成する
[データ プロファイルの見積もりの作成] ページに移動します。
組織を選択する。
以降のセクションでは、[データ プロファイルの見積もりの作成] ページの手順についてさらに詳しく説明します。各セクションの最後で、[続行] をクリックします。
スキャンするリソースの選択
次のいずれかを行います。- 組織の見積もりを作成するには、[組織全体をスキャン] を選択します。
- フォルダの見積もりを作成するには、[選択したフォルダをスキャン] を選択します。[参照] をクリックしてフォルダを選択します。
フィルタと条件を入力する
組織またはフォルダ内にあるすべての BigQuery テーブルを見積もりに含める場合は、このセクションをスキップできます。このセクションでは、フィルタを作成して、見積もりに含めるデータまたは除外するデータの特定のサブセットを指定します。見積もりに含めるサブセットについては、サブセット内のテーブルが見積もりに含まれるために満たすべき条件も指定します。
フィルタと条件を設定する手順は次のとおりです。
- [フィルタと条件を追加] をクリックします。
[フィルタ] セクションで、見積もりのスコープに含まれるテーブルを指定する 1 つ以上のフィルタを定義します。
次のうち少なくとも 1 つを指定します。
- 1 つ以上のプロジェクトを指定するプロジェクト ID または正規表現。
- 1 つ以上のデータセットを指定するデータセット ID または正規表現。
- 1 つ以上のテーブルを指定するテーブル ID または正規表現。
正規表現は RE2 構文に基づく必要があります。
たとえば、プロジェクト内のすべてのテーブルをフィルタに含めるには、そのプロジェクトの ID を指定し、他の 2 つのフィールドを空白のままにします。
さらにフィルタを追加する場合は、[フィルタを追加] をクリックし、前述の手順を繰り返します。
フィルタで定義されたデータのサブセットを見積もりから除外する場合は、[一致するテーブルを見積もりに含める] をオフにします。このオプションをオフにすると、このセクションの残りの部分で説明する条件が非表示になります。
省略可: [条件] セクションで、一致するテーブルが見積もりに含まれるために満たす必要のある条件を指定します。この手順をスキップすると、機密データの保護には、フィルタに一致するすべてのサポートされているテーブルがサイズや年齢に関係なく含まれるようになります。
次のオプションを構成します。
最小条件: 小さいテーブルまたは新しいテーブルを見積もりから除外するには、最小行数またはテーブルの経過時間を設定します。
時間条件: 古いテーブルを除外するには、時間条件をオンにします。次に、日付と時刻を選択します。この日付以前に作成されたテーブルは見積もりから除外されます。
たとえば、時間条件を 5/4/22 11:59 PM に設定した場合、2022 年 5 月 4 日午後 11 時 59 分以前に作成されたテーブルは機密データの保護の見積もりから除外されます。
プロファイリングするテーブル: 見積もりに含めるテーブルのタイプを指定するには、[指定したタイプのテーブルのみを含める] を選択します。含めるテーブルのタイプを選択します。
この条件をオンにしない場合、またはテーブルタイプを選択しない場合、機密データの保護はサポートされているすべてのテーブルを見積もりに含めます。
次の構成があるとします。
最小条件
- 最小行数: 10 行
- 最小期間: 24 時間
時間条件
- タイムスタンプ: 2022 年 5 月 4 日午後 11 時 59 分
プロファイリングするテーブル
[指定したタイプのテーブルのみを含める] オプションが選択されています。テーブルタイプのリストで、[BigLake テーブルをプロファイルする] のみが選択されています。
この場合、Sensitive Data Protection は 2022 年 5 月 4 日午後 11 時 59 分以前に作成されたテーブルを除外します。この日時の後に作成されたテーブルのうち、10 行または 24 時間以上経過した BigLake テーブルのみが機密データの保護によってプロファイリングされます。
[完了] をクリックします。
さらにフィルタと条件を追加する場合は、[フィルタと条件を追加] をクリックし、前述の手順を繰り返します。
フィルタと条件のリストの最後の項目には、常に [デフォルトのフィルタと条件] というラベルが付加されます。このデフォルト設定は、作成したフィルタと条件のいずれとも一致しない選択したリソース(組織またはフォルダ)内のテーブルに適用されます。
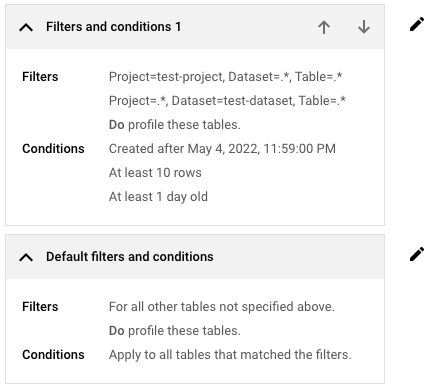
デフォルトのフィルタと条件を調整する場合は、[ フィルタと条件を編集] をクリックして、必要に応じて設定を調整します。
サービス エージェント コンテナと課金の管理
このセクションでは、サービス エージェント コンテナとして使用するプロジェクトを指定します。機密データの保護で新しいプロジェクトを自動的に作成することも、既存のプロジェクトを選択することもできます。
新しく作成したサービス エージェントを使用するか、既存のサービス エージェントを使用するかにかかわらず、プロファイリングするデータへの読み取りアクセス権があることを確認してください。
プロジェクトを自動的に作成する
組織にプロジェクトを作成するために必要な権限がない場合は、既存のプロジェクトを選択するか、必要な権限を取得する必要があります。必要な権限については、組織レベルまたはフォルダレベルでデータ プロファイルを操作するために必要なロールをご覧ください。
サービス エージェント コンテナとして使用するプロジェクトを自動的に作成する手順は次のとおりです。
- [サービス エージェント コンテナ] フィールドで、提案されたプロジェクト ID を確認し、必要に応じて編集します。
- [作成] をクリックします。
- 省略可: デフォルトのプロジェクト名を更新します。
検出に関係のないオペレーションを含め、この新しいプロジェクトに関連するすべての課金対象オペレーションに対して課金されるアカウントを選択します。
[作成] をクリックします。
機密データの保護によって新しいプロジェクトが作成されます。このプロジェクト内のサービス エージェントは、Sensitive Data Protection やその他の API への認証に使用されます。
既存のプロジェクトを選択
既存のプロジェクトをサービス エージェント コンテナとして選択するには、[サービス エージェント コンテナ] フィールドをクリックしてプロジェクトを選択します。
見積もりを保存する場所の設定
[リソース ロケーション] リストで、この見積もりを保存するリージョンを選択します。
見積もりを保存する場所がどこであっても、スキャンされるデータには影響しません。また、以降のデータ プロファイルの保存場所にも影響しません。データは、BigQuery で設定されたとおり、データが保存されているリージョンと同じリージョンでスキャンされます。詳細については、データ所在地に関する検討事項をご覧ください。
設定を確認し、[作成] をクリックします。
機密データの保護で見積りが作成され、見積もりリストに追加されます。その後、見積もりが実行されます。
リソース内のデータ量に応じて、見積もりが完了するまでに最大 24 時間かかることがあります。それまでの間、[機密データの保護] ページを閉じて後で確認できます。見積もりが完了すると、 Google Cloud コンソールに通知が表示されます。
見積もりを表示する
見積もりリストに移動します。
表示する見積もりをクリックします。見積もりには次のものが含まれます。
- リソース内のテーブル数から、フィルタと条件によって除外したテーブル数を引いた数。
- テーブルが対応するデータの合計量。
- この量のデータを毎月プロファイリングするために必要なサブスクリプション ユニットの数。
- 最初に検出された費用。これは、検出されたテーブル プロファイリングの概算費用です。この見積もりは現在のデータのスナップショットのみに基づいており、一定期間に増加するデータの量は考慮されていません。
- 6 か月未満、12 か月未満、または 24 か月未満のテーブルのみをプロファイリングする場合の追加費用の見積もり。これらの追加の見積もりは、データのカバー範囲をさらに制限することで、データ プロファイリングのコストをどのように制御できるかを示しています。
- 毎月の BigQuery の使用量が、今月の使用量と同じであると仮定した場合の、データ プロファイリングの推定月間費用。
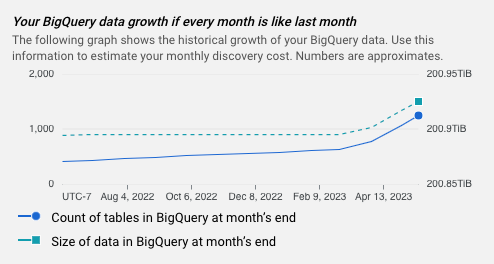
- BigQuery データの経時的な増加を示すグラフ。
- 設定した構成の詳細。
見積もりグラフ
各見積もりには、BigQuery データの過去の増加を示すグラフが含まれます。この情報を使用して、毎月のデータ プロファイリング費用を見積もることができます。
次のステップ
- データ プロファイリングの料金について確認する。
- BigQuery データのデータ プロファイルについて学習します。
- 組織またはフォルダのデータをプロファイリングする方法を学習する。
- 単一プロジェクトのデータをプロファイリングする方法を学習する。