Este guia oferece uma compreensão e uma visão geral dos recursos de confiabilidade do Pub/Sub.
Por que usar o Pub/Sub?
Como um paradigma de mensagens, a publicação/assinatura foi projetada para separar os produtores das mensagens dos consumidores delas. Em vez de enviar solicitações diretas aos consumidores com os dados, os produtores publicam esses dados em um serviço do Pub/Sub. O serviço entrega essas mensagens de forma assíncrona aos consumidores interessados que fizeram uma assinatura.
O resultado é que o serviço absorve todas as complexidades de encontrar consumidores interessados nos dados. O serviço também gerencia a taxa em que os consumidores recebem os dados, com base na capacidade deles. A separação permite que os produtores de dados escrevam mensagens em grande escala com baixa latência, independente do comportamento dos consumidores.
O Pub/Sub oferece entrega de mensagens altamente escalonável e confiável. Embora o serviço processe grande parte disso automaticamente, você tem controle sobre diferentes aspectos dos seus editores e assinantes que podem afetar a disponibilidade e a performance. O restante deste guia fornece alguns detalhes sobre esses aspectos.
Isolamento
Por padrão, o Pub/Sub é um serviço global: os tópicos e as assinaturas não estão vinculados a regiões específicas, e as mensagens fluem dentro do serviço Pub/Sub entre regiões quando necessário. Ao usar o endpoint global, pubsub.googleapis.com, editores e assinantes se conectam à região mais próxima da rede em que o Pub/Sub é executado. Ao usar os endpoints regionais, como us-central1-pubsub.googleapis.com, ou os endpoints de localização, como pubsub.us-central1.rep.googleapis.com, os editores e assinantes se conectam ao Pub/Sub na região especificada. Ao executar
editores ou assinantes fora de Google Cloud, é melhor usar
endpoints regionais ou de localização para garantir que as mensagens fluam entre as
regiões esperadas de maneira consistente.
Isolamento regional
Para minimizar a infraestrutura de que as operações de publicação e inscrição dependem fora de uma única região e garantir que todos os dados permaneçam isolados nessa região, siga estas etapas:
Crie um tópico por região.
Embora o namespace do Pub/Sub seja global e não seja possível vincular tópicos e assinaturas a uma região específica, os metadados de todos os recursos são replicados em repositórios de dados locais na região. Portanto, depois de criar um recurso, a configuração dele fica disponível mesmo que haja um problema em outra região. As atualizações nas configurações de tópico ou assinatura podem não ser propagadas imediatamente em caso de interrupção.
Evite usar endpoints globais.
Em vez disso, use endpoints regionais quando disponíveis e endpoints de localização quando não houver endpoints regionais. Os endpoints regionais oferecem mais isolamento regional, mas ainda não estão disponíveis em todas as regiões.
Use uma política de armazenamento de mensagens e defina
enforceInTransitcomoTrue.Com a opção Aplicar em trânsito ativada, os dados nunca saem da região, e todos os clientes que se conectam ao tópico em uma região específica definem a política de armazenamento de mensagens para essa região.
Com os tópicos configurados dessa forma, você pode ter certeza de que todas as operações de publicação e assinatura gravam e leem dados exclusivamente na região. Em caso de falhas do editor, do assinante ou do Pub/Sub em uma única região, a entrega de mensagens é interrompida nessa região. A entrega de mensagens em tópicos e assinaturas de outras regiões não é afetada.
Se você também precisar que as operações administrativas e o namespace dos seus tópicos e assinaturas sejam isolados regionalmente, use o Serviço gerenciado para Apache Kafka.
Failover
Se você não precisar de isolamento regional, aproveite a capacidade do Pub/Sub de entregar mensagens com eficiência em várias regiões para alcançar recursos de failover multirregional. O restante desta seção fala sobre como criar tópicos e assinaturas e colocar editores e assinantes para oferecer suporte a diferentes tipos de failover e redundância de dados.
Semântica de failover padrão
Considere um caso em que há um único tópico e uma única assinatura. Os editores estão localizados em regiões dos Estados Unidos e da Austrália, e os assinantes estão localizados nas regiões Google Cloud da Europa e da Austrália. Se todos os assinantes tiverem capacidade suficiente para receber mensagens, o fluxo será assim:
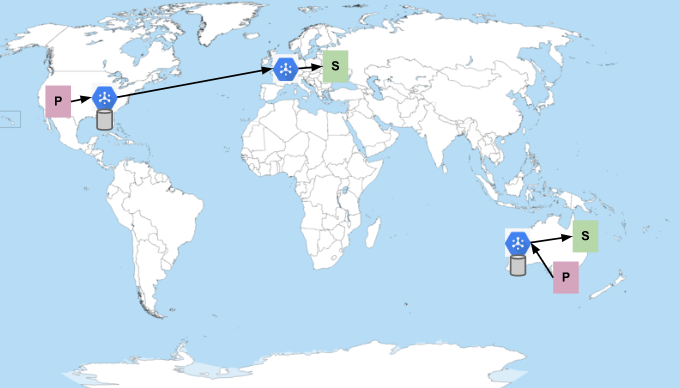
Os Ps representam publishers, e os Ss representam assinantes. O hexágono azul representa o serviço Pub/Sub. Os cilindros representam os lugares em que as mensagens são armazenadas (elas são sempre persistidas em várias zonas na região em que são publicadas). O Pub/Sub prefere enviar mensagens na mesma região em que foram publicadas quando os assinantes estão disponíveis. Caso contrário, ele envia as mensagens para a região mais próxima da rede com assinantes que têm capacidade. Portanto, como mostrado na imagem anterior, as mensagens publicadas nos Estados Unidos são entregues aos assinantes na Europa, e as mensagens publicadas na Austrália permanecem no país.
As seções a seguir discutem o que acontece em diferentes cenários de falha.
Os inscritos na Europa não estão disponíveis
Suponha que os assinantes na Europa foram recusados ou estão falhando com frequência e não conseguem manter uma conexão com o Pub/Sub. Se isso acontecesse, o serviço começaria a entregar mensagens aos assinantes na Austrália:
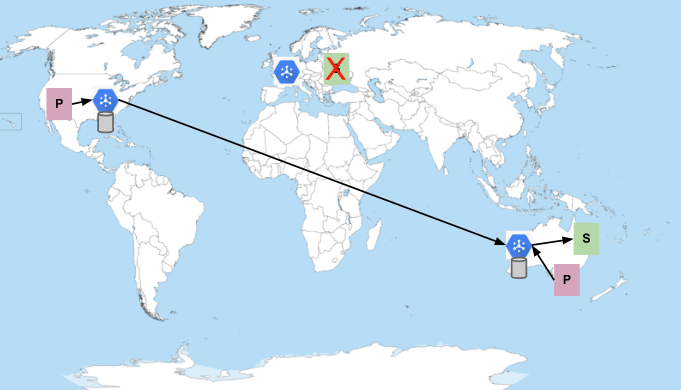
Os assinantes na Europa e na Austrália não estão disponíveis
Se todos os assinantes estiverem indisponíveis, o Pub/Sub armazenará as mensagens até a duração da retenção de mensagens configurada.
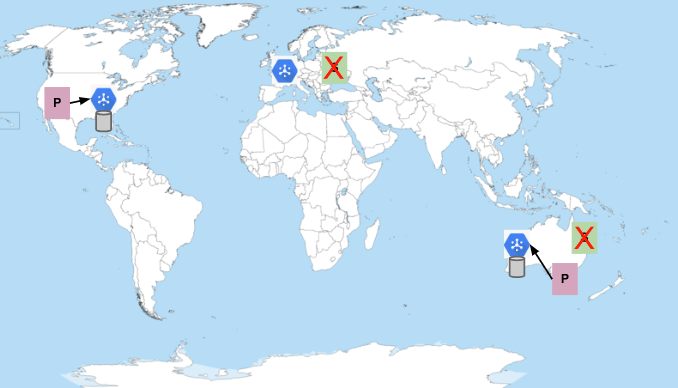
Quando os assinantes se reconectam, as mensagens são entregues, a menos que a interrupção dure mais do que o período de retenção de mensagens configurado. Por padrão, a retenção de mensagens de assinatura é definida como 7 dias. Também é possível configurar a retenção de mensagens em um tópico por até 31 dias. Não escolha uma duração de retenção de mensagens menor do que a interrupção máxima esperada ou que você está disposto a tolerar.
O Pub/Sub não está disponível na Europa
Embora seja raro, talvez você também queira lidar com casos em que o próprio Pub/Sub não está disponível. A indisponibilidade do Pub/Sub se manifesta como períodos prolongados de erros inesperados em solicitações de publicação ou assinatura ou a incapacidade de entregar mensagens publicadas aos assinantes. Por exemplo, se o Pub/Sub estiver inativo na região da Europa, o cenário será muito parecido com quando os assinantes estão inativos:
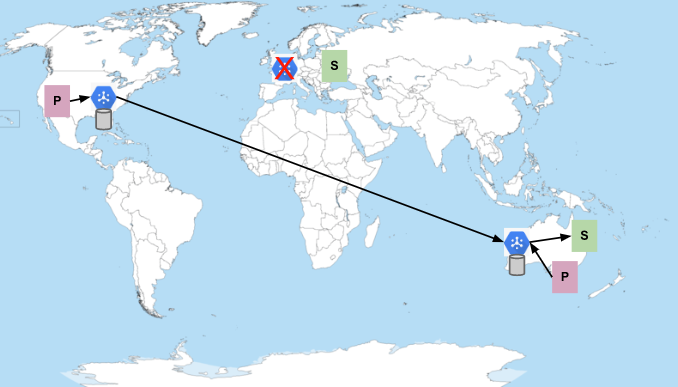
Nesse caso, os assinantes na Europa não fazem failover para outra região, mesmo que usem o endpoint global. O Pub/Sub não faz failover automaticamente. Imagine que os próprios assinantes estão causando um problema inesperado no Pub/Sub que resulta em indisponibilidade. Esse tipo de problema é tratado como uma interrupção grave. No entanto, o escopo do impacto da interrupção pode ser limitado à região a que os assinantes se conectaram. Se o serviço permitisse o failover para outra região, os assinantes também poderiam causar indisponibilidade lá, resultando em uma falha em cascata em todo o serviço.
Editores na Austrália não estão disponíveis
Se os editores em uma região ficarem indisponíveis, as mensagens já publicadas ainda serão entregues aos assinantes mais próximos:
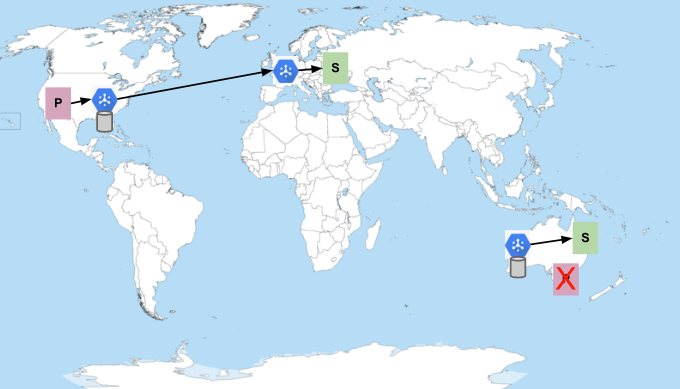
Eventualmente, todas as mensagens são consumidas e confirmadas pelos assinantes. Ao enviar mensagens, o Pub/Sub tenta minimizar a distância da rede. Portanto, os assinantes na região da Austrália podem parar de receber mensagens se os assinantes na Europa tiverem capacidade suficiente para processar todas as mensagens publicadas nos Estados Unidos.
O Pub/Sub não está disponível nos Estados Unidos
O Pub/Sub grava mensagens de forma síncrona em várias zonas dentro de uma região. Portanto, uma interrupção zonal não é suficiente para impedir a entrega de mensagens. A região inteira precisa estar indisponível. Se o Pub/Sub ficar indisponível em uma região em que os editores estão enviando mensagens, elas não serão entregues até que o serviço seja totalmente restaurado:
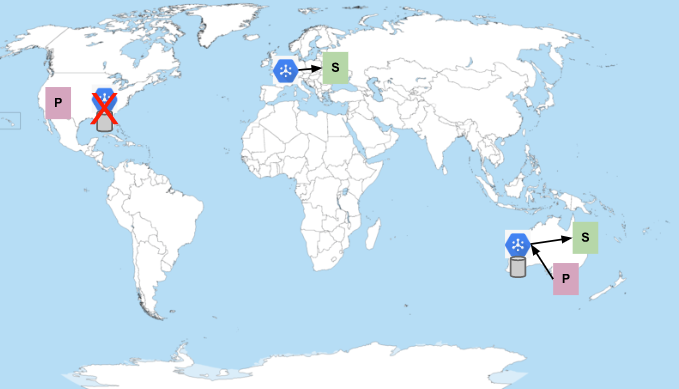
A mensagem ainda é entregue (supondo que o período de retenção não tenha passado), mas com um atraso igual à duração da interrupção. Assim como os assinantes, os publishers nos Estados Unidos também não fazem failover para outra região quando o serviço falha. Esse comportamento ajuda a evitar a probabilidade de falhas em cascata em várias regiões devido a um editor ou assinante com falha.
Failover e redundância controlados pelo cliente
A semântica de failover padrão do Pub/Sub pode não garantir totalmente que as mensagens sempre possam fluir dos editores para os assinantes se houver uma interrupção em qualquer lugar entre eles. As interrupções podem ocorrer em vários lugares diferentes, incluindo seus clientes, o serviço em que seus editores ou assinantes são executados, a rede ou até mesmo, raramente, no próprio Pub/Sub. Se você precisar que seus serviços sejam resilientes a essas interrupções, implemente suas próprias redundâncias. Normalmente, essas redundâncias incluem o uso de várias instâncias de clientes de editor e assinante, em que cada uma usa um endpoint de local diferente.
Talvez você queira resiliência para dois escopos de impacto diferentes: zonal ou regional. Confira as opções de configuração para cada uma delas.
Resiliência zonal
O Pub/Sub tem replicação entre zonas integrada. Não é necessário fazer nada especial para lidar com interrupções de zona única que afetam o serviço em si. No entanto, para ter resiliência a interrupções para seus clientes ou rede, é melhor executar editores e assinantes com capacidade suficiente em várias zonas dentro da região. Se uma única zona estiver inativa, os clientes na outra zona poderão captar o tráfego e processar as mensagens. É uma prática recomendada não publicar mudanças nesses clientes simultaneamente para que, se um bug for introduzido, as outras zonas intactas possam continuar processando mensagens.
Resiliência regional
Para ter resiliência a falhas regionais, configure redundâncias extras nos seus editores e assinantes. É possível executar editores e assinantes em várias regiões para lidar com a possibilidade de interrupções nesses clientes ou na rede.
Se você quiser ter resiliência contra possíveis falhas do Pub/Sub em uma região, é necessário ter um mecanismo de failover pronto para lidar com uma interrupção desse tipo. As abordagens possíveis são uma compensação entre a latência de entrega de mensagens de ponta a ponta e o custo.
Para minimizar a latência caso o custo não seja um problema, a melhor estratégia é sempre publicar e assinar simultaneamente em regiões diferentes. Primeiro, escolha o número de regiões em que você quer redundância. Em seguida, embora não seja estritamente necessário, você pode configurar um tópico e uma assinatura para cada uma dessas regiões.
Cada editor cria quantos clientes forem necessários para cada região (um para cada região) e usa um endpoint de localização diferente para garantir que as mensagens sejam direcionadas a regiões distintas. Se você usar tópicos separados, cada cliente editor precisará publicar no tópico correspondente por região. Para cada mensagem, o editor chama "publish" em cada cliente. Com as publicações redundantes, não é necessário tentar de novo se uma delas falhar.
Da mesma forma, cada assinante cria esse número de clientes assinantes (um para cada região) e usa um endpoint de localização para se conectar a uma região diferente. Se você usar assinaturas diferentes para cada região, cada cliente assinante precisará usar a assinatura correspondente. As regiões usadas para publishers e assinantes não precisam ser as mesmas. Os assinantes recebem mensagens nas três assinaturas e as processam.
Essa configuração tem vários recursos e requisitos principais:
- Uma falha de região única não afeta o processamento de mensagens já publicadas nem as publicadas durante a falha. Como as mensagens foram publicadas em várias regiões, elas ainda estão disponíveis em outras regiões caso uma delas fique inativa. Durante a interrupção, as chamadas de publicação falham na região afetada, mas são bem-sucedidas nas outras.
- A latência de processamento de mensagens não é afetada enquanto qualquer uma das regiões pelas quais as mensagens estão fluindo estiver disponível.
- O processamento de mensagens precisa ser idempotente. Como cada mensagem será entregue várias vezes, o processamento de mensagens precisa ser resiliente a duplicatas. Em caso de interrupção regional, alguns desses duplicados podem chegar muito depois da primeira entrega da mensagem. Esses duplicados provavelmente vieram de uma região diferente que não estava com uma falha.
Executar com esse tipo de redundância oferece a maior capacidade de recuperação para qualquer tipo de interrupção. Para serviços internos do Google que dependem do Pub/Sub e exigem a maior disponibilidade, essa configuração é preferível. No entanto, essa configuração tem a desvantagem de multiplicar o custo da entrega de mensagens pelo número de regiões usadas. Há também o custo adicional do uso da rede inter-regional para mensagens que precisam ser movidas entre regiões.
Outra abordagem para redundância é fazer failover apenas quando as solicitações falham ou as mensagens não fluem dos editores para os assinantes como esperado. Nesse cenário, você tem uma região principal para onde direciona seus editores e assinantes por endpoints de localização. Como antes, essas regiões não precisam ser iguais. Você também tem uma região de substituição para editores e assinantes que é usada quando a região principal não está disponível.
Os editores publicam apenas na região principal (pelo endpoint de local) quando as solicitações são enviadas com sucesso. Sempre que a região é considerada inativa, os publishers começam a publicar na região de substituição. Determinar que a região está inativa e fazendo failover pode ser feito de duas maneiras. Isso pode ser feito por um processo manual, e a configuração é atualizada dinamicamente nos publishers. Os publishers também podem atualizar a configuração por conta própria se a taxa de erros nas solicitações de publicação for alta o suficiente.
Os assinantes precisam sempre se conectar à região principal pelo endpoint de localidade. Você pode decidir que o assinante pode usar a região de substituição com um ou mais dos seguintes gatilhos:
- Sempre assine a região de substituição. Nesse caso, o assinante mantém uma conexão com a região principal e a de fallback em todos os momentos. As mesmas regiões podem ser usadas para o principal e o substituto de editores e assinantes. Nesse caso, o assinante só vai receber mensagens pela região de backup se o editor fizer failover.
- Detecte e mude manualmente os assinantes para a região de substituição usando uma configuração. Se você detectar uma interrupção, faça o failover para a região de substituição e volte para a região principal quando a interrupção diminuir.
- Failover em erros de assinante. Se as solicitações do assinante retornarem erros, isso pode indicar que você precisa fazer failover para a região de substituição. As bibliotecas de cliente do Pub/Sub repetem internamente as solicitações de extração de streaming em erros temporários. Por isso, talvez não seja possível detectar longos períodos de erros inesperados. Além disso, a taxa de erros de extração de streaming deve ser de 100%, mesmo durante a operação normal.
- Faça failover se o assinante passar um tempo inesperadamente longo sem receber mensagens. Supondo que haja uma publicação consistente de mensagens, os assinantes podem sempre receber mensagens. Se eles passarem um longo período sem receber mensagens, talvez haja um problema do lado da assinatura no Pub/Sub na região principal. Isso é corrigido fazendo failover para a região de substituição.
De todas as quatro opções, a primeira é a ideal. Uma conexão de assinante não custa nada se não houver mensagens fluindo nela. O único custo está na pegada da instância adicional da biblioteca de cliente assinante, que pode ser insignificante. Também é necessário prestar atenção à cota de número de conexões de extração de streaming abertas por região.
A vantagem desse segundo modelo é que não há um multiplicador no custo do Pub/Sub, já que as mensagens são publicadas apenas uma vez. No entanto, a desvantagem é que, para determinados tipos de interrupções, as mensagens publicadas antes do início da interrupção podem não estar disponíveis até que o problema seja resolvido. As mensagens armazenadas na região indisponível podem não ser entregues aos assinantes, não importa onde eles estejam conectados. As mensagens publicadas durante a interrupção na região de failback podem estar disponíveis. Além disso, pode haver um período de indisponibilidade com aumento nas taxas de erro para os publishers ou assinantes. Isso depende do método usado para detectar uma interrupção e do tempo necessário para fazer failover para a região de fallback.
Não importa qual opção você escolha, saiba como isso pode interagir com recursos do Pub/Sub. A entrega ordenada e a entrega exatamente uma vez oferecem garantias em uma região. Por exemplo, se você usar a técnica de redundância de failover, a entrega de mensagens só será garantida na ordem para mensagens publicadas na mesma região. O assinante pode receber mensagens publicadas na região de failback antes das mensagens publicadas na região principal, mesmo que as mensagens tenham sido publicadas primeiro na região principal.
Ajuste de publishers
Não importa qual das opções de failover você escolha, há algumas etapas adicionais de ajuste que você precisa realizar nos próprios editores. Ajustar o comportamento do publisher garante o desempenho ideal sob carga alta. Agrupar mensagens em lotes é uma maneira de reduzir a latência em troca de um custo menor, mas não é uma questão de confiabilidade e, portanto, não é abordada aqui. Em vez disso, concentre-se em alguns dos outros parâmetros úteis para ajustar a confiabilidade, incluindo configurações de nova tentativa e de controle de fluxo.
As publicações podem falhar por diferentes motivos, incluindo problemas temporários, como indisponibilidade da rede, ou que exigem intervenção do usuário, como mudanças de permissão. A biblioteca de cliente do Pub/Sub tenta novamente erros temporários usando os parâmetros especificados nas configurações de nova tentativa. Essas configurações controlam o comportamento da espera exponencial em novas tentativas de RPCs de publicação que falham por motivos temporários. Embora as configurações padrão geralmente funcionem bem na maioria dos cenários, há situações em que talvez seja necessário ajustar esses valores.
As duas propriedades que você provavelmente vai querer ajustar são o tempo limite inicial do RPC e o tempo limite total. O tempo limite inicial da RPC é o tempo que a primeira RPC de publicação recebe para ser concluída. Se uma RPC falhar ou atingir o tempo limite, outra será tentada com um tempo limite maior até que o número total de solicitações ou o tempo limite total seja excedido.
O tempo limite inicial pode ser ajustado se o editor tiver restrições de rede ou estiver longe do data center Google Cloud mais próximo que executa o Pub/Sub. As restrições de rede podem ser limitações no throughput da máquina em que o editor está sendo executado ou podem ser o resultado de outros serviços em execução na mesma máquina que exigem muito da rede. Se o tempo limite for muito curto, os RPCs iniciais poderão falhar repetidamente, resultando em mais tentativas (com tempos limite mais longos) necessárias para publicar com sucesso. A necessidade repetida de novas tentativas aumenta a latência de publicação. Nessa situação, aumentar o tempo limite inicial pode resultar em publicações mais rápidas.
Se a conexão de rede não for confiável, aumentar o tempo limite total e o inicial pode ajudar. Um tempo limite total maior dá à RPC de publicação mais tempo para ser concluída. Quando as RPCs de publicação falham consistentemente com erros de prazo excedido, considere ajustar esses valores.
Erros contínuos de prazo excedido na publicação também podem indicar a necessidade de ajustar o controle de fluxo do editor. Com essas configurações, você garante que seus editores sejam resilientes a picos de tráfego de entrada que geram mais mensagens para serem enviadas ao Pub/Sub. Um grande aumento nas solicitações de saída pode sobrecarregar a CPU, a memória ou a capacidade de rede do editor. Quando a publicação está sobrecarregada, ela não consegue processar solicitações ou respostas antes dos tempos limite. Isso resulta em ainda mais solicitações de publicação e, por fim, atinge o tempo limite total. O controle de fluxo do publisher limita o número de mensagens ou bytes que podem ficar pendentes sem uma resposta da solicitação de publicação. Limitar o número de solicitações dessa forma mantém a utilização de recursos em um nível gerenciável, mesmo durante picos. Dependendo de como o publisher opera, você pode permitir que RPCs de publicação subsequentes aguardem a capacidade, permitindo que a publicação bloqueie outras solicitações. Como alternativa, é possível rejeitar os chamadores do serviço fazendo com que o controle de fluxo retorne um erro quando a capacidade for atingida. Você configura como a biblioteca de cliente do editor responde com o comportamento de limite excedido.
Ajuste de inscritos
Também pode ser necessário ajustar os assinantes para garantir que eles funcionem de maneira confiável. Assim como os publishers, é possível ajustar as configurações de controle de fluxo dos assinantes para garantir que eles não fiquem sobrecarregados. A biblioteca de cliente do assinante usa o pull de streaming, em que o cliente abre um stream persistente para o servidor, e o servidor envia mensagens à medida que ficam disponíveis. Se houver um grande aumento nas mensagens publicadas, o assinante poderá receber mais mensagens do que consegue processar. Com o controle de fluxo em vigor, o número de mensagens não confirmadas pendentes para o cliente em um determinado momento é limitado. Isso reduz o número de mensagens processadas simultaneamente e distribui o processamento por um período mais longo. Ao distribuir a carga, os assinantes ficam abaixo de qualquer limitação de recursos que afete o processamento de mensagens, o que pode resultar em um efeito cascata que se desenvolve na incapacidade de processar qualquer mensagem.
O controle de fluxo sozinho é suficiente se você espera apenas picos na quantidade de dados a serem processados que acabam diminuindo. Se o tráfego aumentar com o tempo devido ao maior uso, o controle de fluxo vai proteger os assinantes. No entanto, isso pode resultar em um acúmulo que continua aumentando e impede que as mensagens sejam entregues antes que a duração da retenção de mensagens expire. Nesses casos, talvez seja interessante definir o escalonamento automático para aumentar o número de assinantes em resposta a um número crescente de mensagens não confirmadas. A maneira de configurar isso depende da plataforma de computação que você está usando para seus assinantes. Por exemplo, o escalonador automático do Compute Engine permite escalonar com base em métricas como o número de mensagens não entregues. Usar o escalonamento automático e o controle de fluxo garante que seus assinantes sejam resilientes a outros picos de curto prazo na taxa de transferência de mensagens e ao crescimento de longo prazo que exige mais poder de computação. Siga as práticas recomendadas para usar métricas do Pub/Sub como um indicador de escalonamento.
Use snapshots e procure implantações seguras
A perda de mensagens geralmente é um evento catastrófico. O Pub/Sub oferece entrega pelo menos uma vez para todas as mensagens publicadas. No entanto, o processamento correto dessas mensagens depende do comportamento do assinante. Se as mensagens forem confirmadas com sucesso, o Pub/Sub não as reenviará. Portanto, um bug introduzido no novo código de assinante implantado que confirma mensagens sem processá-las corretamente pode resultar em perda de mensagens induzida pelo assinante. O Pub/Sub oferece o recurso snapshot e busca, que pode ajudar você a garantir o processamento correto de todas as mensagens, mesmo em caso de bugs do assinante.
O padrão para cada implantação de assinante precisa ser o seguinte:
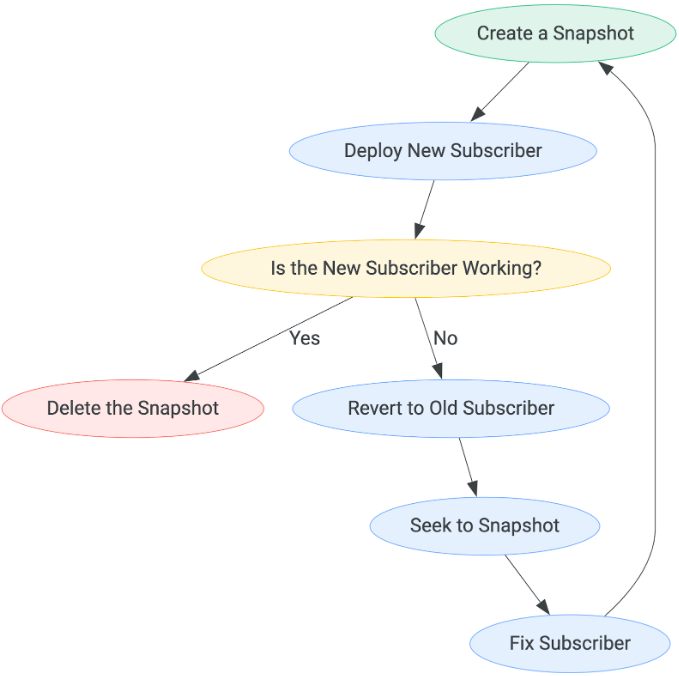
O tempo de espera antes de determinar se o novo assinante está funcionando pode variar de acordo com seu caso de uso. A única maneira de sair do fluxo de etapas é quando um assinante é considerado em funcionamento, momento em que o snapshot pode ser excluído.
O uso de snapshot e busca não substitui as práticas recomendadas de primeiro executar o software em um ambiente que não seja de produção e a implantação gradual na produção. Elas oferecem um nível extra de proteção para garantir o processamento confiável dos dados. A desvantagem é que a busca pelo snapshot pode resultar na entrega duplicada de mensagens que o assinante processou com êxito. No entanto, como o Pub/Sub tem semântica de entrega "pelo menos uma vez" por padrão, seus assinantes já são resilientes ao reenvio de mensagens.