Dieser Leitfaden bietet ein Verständnis und einen Überblick über die Zuverlässigkeitsfunktionen von Pub/Sub.
Warum Pub/Sub?
Als Messaging-Paradigma ist „Publish/Subscribe“ darauf ausgelegt, die Ersteller von Nachrichten von den Nutzern dieser Nachrichten zu entkoppeln. Anstatt dass Ersteller direkte Anfragen mit den Daten an die Nutzer senden, veröffentlichen sie diese Daten in einem Pub/Sub-Dienst wie Pub/Sub. Der Dienst stellt diese Nachrichten asynchron an interessierte Nutzer zu, die ein Abo abgeschlossen haben.
Der Dienst übernimmt alle Feinheiten der Suche nach Nutzern, die an den Daten interessiert sind. Der Dienst verwaltet auch die Rate, mit der die Daten basierend auf der Kapazität der Nutzer empfangen werden. Durch die Entkopplung können Datenproduzenten Nachrichten in großem Umfang mit geringer Latenz schreiben, unabhängig vom Verhalten der Nutzer.
Pub/Sub bietet eine hochgradig skalierbare und zuverlässige Zustellung von Nachrichten. Der Dienst übernimmt zwar einen Großteil dieser Aufgaben automatisch, Sie haben aber die Möglichkeit, verschiedene Aspekte Ihrer Publisher und Abonnenten zu steuern, die sich auf die Verfügbarkeit und Leistung auswirken können. Im Rest dieses Leitfadens finden Sie einige Details zu diesen Aspekten.
Isolation
Standardmäßig ist Pub/Sub ein globaler Dienst: Themen und Abos sind nicht von Natur aus an bestimmte Regionen gebunden und Nachrichten werden bei Bedarf innerhalb des Pub/Sub-Dienstes zwischen Regionen übertragen. Bei Verwendung des globalen Endpunkts, pubsub.googleapis.com, stellen Publisher und Abonnenten eine Verbindung zur netzwerknahesten Region her, in der Pub/Sub ausgeführt wird. Wenn Sie die regionalen Endpunkte wie us-central1-pubsub.googleapis.com oder die standortbezogenen Endpunkte wie pubsub.us-central1.rep.googleapis.com verwenden, stellen Publisher und Abonnenten eine Verbindung zu Pub/Sub in der angegebenen Region her. Wenn Sie Publisher oder Abonnenten außerhalb von Google Cloudausführen, sollten Sie regionale oder standortbezogene Endpunkte verwenden, um sicherzustellen, dass Nachrichten konsistent zwischen den erwarteten Regionen übertragen werden.
Regionale Isolation
So minimieren Sie die Infrastruktur, von der Veröffentlichungs- und Abonnementsvorgänge außerhalb einer einzelnen Region abhängen, und sorgen dafür, dass alle Daten auf diese Region beschränkt bleiben:
Erstellen Sie ein Thema pro Region.
Der Namespace von Pub/Sub ist global und Sie können Themen und Abos nicht an eine bestimmte Region binden. Metadaten für alle Ressourcen werden jedoch in lokale Datenspeicher innerhalb der Region repliziert. Wenn Sie eine Ressource erstellen, ist ihre Konfiguration daher auch bei einem Problem in einer anderen Region verfügbar. Bei einem Ausfall werden Aktualisierungen der Konfigurationen für Themen oder Abos möglicherweise nicht sofort übernommen.
Verwenden Sie keine globalen Endpunkte.
Verwenden Sie stattdessen regionale Endpunkte, sofern verfügbar, und standortbezogene Endpunkte, wenn keine regionalen Endpunkte verfügbar sind. Regionale Endpunkte bieten eine bessere regionale Isolation, sind aber noch nicht in allen Regionen verfügbar.
Verwenden Sie eine Richtlinie für die Speicherung von Nachrichten und legen Sie
enforceInTransitaufTruefest.Wenn Enforce in transit aktiviert ist, verlassen Daten die Region nie und alle Clients, die sich in einer bestimmten Region mit dem Thema verbinden, legen die Richtlinie für Nachrichtenspeicherung für diese Region fest.
Wenn Themen auf diese Weise konfiguriert sind, können Sie sicher sein, dass bei allen Veröffentlichungs- und Abonnementsvorgängen Daten ausschließlich in der Region geschrieben und gelesen werden. Bei Ausfällen von Publisher, Abonnent oder Pub/Sub in einer einzelnen Region wird die Nachrichtenzustellung in dieser Region beendet. Die Zustellung von Nachrichten zu Themen und Abonnements für andere Regionen ist davon nicht betroffen.
Wenn Sie möchten, dass die administrativen Vorgänge und der Namespace Ihrer Themen und Abos ebenfalls regional isoliert sind, sollten Sie Managed Service for Apache Kafka verwenden.
Failover
Wenn Sie keine regionale Isolation benötigen, können Sie die Möglichkeit von Pub/Sub nutzen, Nachrichten effizient über mehrere Regionen hinweg zu senden, um Failover-Funktionen für mehrere Regionen zu erreichen. Im restlichen Teil dieses Abschnitts wird beschrieben, wie Sie Themen und Abos erstellen und Publisher und Abonnenten platzieren, um verschiedene Arten von Failover und Datenredundanz zu unterstützen.
Standard-Failover-Semantik
Angenommen, es gibt nur ein Thema und ein Abo. Die Publisher befinden sich in Regionen der USA und Australiens und die Abonnenten in den Google Cloud Regionen Europas und Australiens. Wenn alle Abonnenten genügend Kapazität haben, um Nachrichten zu empfangen, sieht der Nachrichtenfluss so aus:

Die Ps stehen für Publisher, die Ss für Abonnenten. Das blaue Sechseck steht für den Pub/Sub-Dienst. Die Zylinder stellen die Orte dar, an denen Nachrichten gespeichert werden. Nachrichten werden immer in mehreren Zonen in der Region gespeichert, in der sie veröffentlicht werden. Pub/Sub sendet Nachrichten vorzugsweise in derselben Region, in der sie veröffentlicht wurden, wenn Abonnenten verfügbar sind. Andernfalls werden die Nachrichten an die Region im Netzwerk gesendet, die Abonnenten mit Kapazitäten hat. Wie im vorherigen Bild zu sehen ist, werden Nachrichten, die in den USA veröffentlicht werden, an Abonnenten in Europa gesendet. Nachrichten, die in Australien veröffentlicht werden, bleiben in Australien.
In den folgenden Abschnitten wird beschrieben, was in verschiedenen Fehlerszenarien passiert.
Abonnenten in Europa sind nicht verfügbar
Angenommen, Abonnenten in Europa wurden abgelehnt oder die App stürzt häufig ab und es kann keine Verbindung zu Pub/Sub aufrechterhalten werden. Wenn dies der Fall wäre, würde der Dienst Nachrichten an Abonnenten in Australien senden:
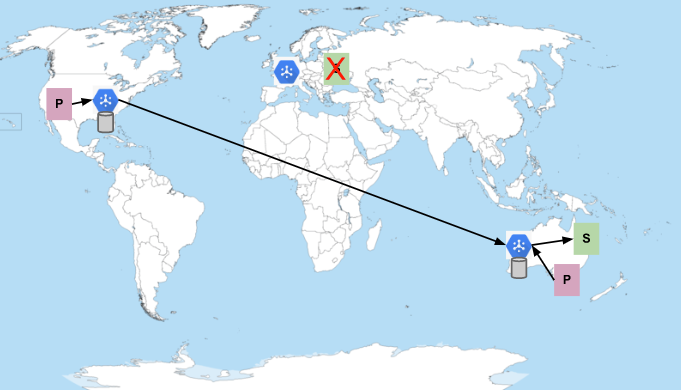
Abonnenten in Europa und Australien sind nicht verfügbar
Wenn alle Abonnenten nicht verfügbar sind, speichert Pub/Sub die Nachrichten bis zur konfigurierten Nachrichtenaufbewahrungsdauer.

Sobald die Abonnenten die Verbindung wiederherstellen, werden die Nachrichten zugestellt, sofern der Ausfall nicht länger als die konfigurierte Nachrichtenaufbewahrungsdauer dauert. Standardmäßig werden Abo-Nachrichten 7 Tage lang aufbewahrt. Sie können auch die Nachrichtenaufbewahrung für ein Thema für bis zu 31 Tage konfigurieren. Wählen Sie keine Nachrichtenaufbewahrungsdauer aus, die kürzer ist als der maximale Ausfall, den Sie erwarten oder tolerieren möchten.
Pub/Sub ist in Europa nicht verfügbar
Obwohl selten, sollten Sie auch Fälle berücksichtigen, in denen Pub/Sub selbst nicht verfügbar ist. Die Nichtverfügbarkeit von Pub/Sub macht sich durch längere Zeiträume mit unerwarteten Fehlern bei Veröffentlichungs- oder Abonnentenanfragen oder durch die Unfähigkeit, veröffentlichte Nachrichten an Abonnenten zu senden, bemerkbar. Wenn Pub/Sub beispielsweise in der Region in Europa ausfällt, sieht das Szenario ähnlich aus wie bei einem Ausfall von Abonnenten:

In diesem Fall werden Abonnenten in Europa nicht auf eine andere Region umgeleitet, auch wenn sie den globalen Endpunkt verwenden. Bei Pub/Sub wird absichtlich kein automatisches Failover durchgeführt. Stellen Sie sich vor, dass die Abonnenten selbst ein unerwartetes Problem in Pub/Sub verursachen, das zu einer Nichtverfügbarkeit führt. Ein solches Problem wird als schwerwiegender Ausfall behandelt. Die Auswirkungen des Ausfalls können jedoch auf die Region beschränkt werden, mit der sich die Abonnenten verbunden haben. Wenn der Dienst ein Failover in eine andere Region zulässt, können die Abonnenten auch dort zu einer Nichtverfügbarkeit führen, was zu einem kaskadierenden Ausfall des gesamten Dienstes führen kann.
Publisher in Australien sind nicht verfügbar
Wenn die Publisher in einer Region nicht mehr verfügbar sind, werden die bereits veröffentlichten Nachrichten weiterhin an die nächstgelegenen Abonnenten gesendet:

Schließlich werden alle Nachrichten von den Abonnenten empfangen und bestätigt. Beim Senden von Nachrichten versucht Pub/Sub, die Netzwerkentfernung zu minimieren. Daher können die Abonnenten in Australien keine Nachrichten mehr erhalten, wenn die Abonnenten in Europa genügend Kapazität haben, um alle in den USA veröffentlichten Nachrichten zu verarbeiten.
Pub/Sub ist in den USA nicht verfügbar
Pub/Sub schreibt Nachrichten synchron in mehrere Zonen innerhalb einer Region. Ein Zonenausfall reicht daher nicht aus, um die Zustellung von Nachrichten zu verhindern. Die gesamte Region muss nicht verfügbar sein. Wenn Pub/Sub in einer Region, in der Publisher Nachrichten senden, nicht mehr verfügbar ist, werden Nachrichten in dieser Region möglicherweise erst zugestellt, wenn der Dienst vollständig wiederhergestellt ist:

Die Nachricht wird letztendlich zugestellt (vorausgesetzt, die Aufbewahrungsdauer für Nachrichten ist noch nicht abgelaufen), jedoch mit einer Verzögerung, die der Dauer des Ausfalls entspricht. Ähnlich wie bei Abonnenten wird bei Publishern in den USA bei einem Dienstausfall kein Failover auf eine andere Region durchgeführt. So wird die Wahrscheinlichkeit von kaskadierenden Fehlern in verschiedenen Regionen aufgrund eines fehlerhaften Publishers oder Abonnenten verringert.
Vom Kunden gesteuertes Failover und Redundanz
Die standardmäßige Failover-Semantik von Pub/Sub garantiert möglicherweise nicht vollständig, dass Nachrichten immer von Publishern zu Abonnenten übertragen werden können, wenn es an einer Stelle dazwischen zu einem Ausfall kommt. Ausfälle können an verschiedenen Stellen auftreten, z. B. in Ihren Clients, im Dienst, auf dem Ihre Publisher oder Abonnenten ausgeführt werden, im Netzwerk oder selten auch in Pub/Sub selbst. Wenn Ihre Dienste gegen solche Ausfälle geschützt sein sollen, müssen Sie eigene Redundanzen implementieren. Diese Redundanzen umfassen in der Regel die Verwendung mehrerer Instanzen von Publisher- und Subscriber-Clients, die jeweils einen anderen Standortendpunkt verwenden.
Sie benötigen möglicherweise Ausfallsicherheit für zwei verschiedene Arten von Auswirkungen: zonal oder regional. Hier finden Sie die Einrichtungsoptionen für die einzelnen Produkte.
Zonale Ausfallsicherheit
Pub/Sub hat eine integrierte zonenübergreifende Replikation. Sie müssen keine besonderen Maßnahmen ergreifen, um mit Ausfällen in einer einzelnen Zone umzugehen, die den Dienst selbst betreffen. Um jedoch Ausfälle bei Ihren Clients oder in Ihrem Netzwerk zu vermeiden, sollten Sie Publisher und Abonnenten mit ausreichender Kapazität in mehreren Zonen innerhalb der Region ausführen. Wenn eine einzelne Zone ausfällt, können die Clients in der anderen Zone den Traffic übernehmen und die Nachrichten verarbeiten. Es wird empfohlen, Änderungen an diesen Clients nicht gleichzeitig zu veröffentlichen, damit die anderen, unveränderten Zonen weiterhin Nachrichten verarbeiten können, falls ein Fehler auftritt.
Regionale Ausfallsicherheit
Um vor regionalen Ausfällen geschützt zu sein, sollten Sie zusätzliche Redundanzen für Ihre Publisher und Abonnenten einrichten. Sie können Publisher und Abonnenten in mehreren Regionen ausführen, um die Möglichkeit von Ausfällen bei diesen Clients oder im Netzwerk zu berücksichtigen.
Wenn Sie vor potenziellen Pub/Sub-Ausfällen in einer Region geschützt sein möchten, müssen Sie einen Failover-Mechanismus bereithalten, um mit einem solchen Ausfall umzugehen. Die möglichen Ansätze sind ein Kompromiss zwischen der End-to-End-Latenz der Nachrichtenübermittlung und Ihren Kosten.
Wenn die Kosten keine Rolle spielen, ist es am besten, immer gleichzeitig in verschiedenen Regionen zu veröffentlichen und zu abonnieren, um die Latenz zu minimieren. Wählen Sie zuerst die Anzahl der Regionen aus, in denen Sie Redundanz wünschen. Als Nächstes können Sie, obwohl dies nicht unbedingt erforderlich ist, ein Thema und ein Abo für jede dieser Regionen einrichten.
Jeder Publisher erstellt so viele Publisher-Clients wie es Regionen gibt (einen für jede Region) und verwendet einen anderen Standortendpunkt, um sicherzustellen, dass Mitteilungen an unterschiedliche Regionen gesendet werden. Wenn Sie separate Themen verwenden, muss jeder Publisher-Client das entsprechende regionale Thema verwenden. Bei jeder Nachricht ruft der Publisher „publish“ für jeden Client auf. Bei redundanten Veröffentlichungen ist es nicht erforderlich, die Veröffentlichung noch einmal zu versuchen, wenn eine einzelne fehlschlägt.
Ebenso erstellt jeder Abonnent so viele Abonnentenclients wie Regionen und verwendet einen Standortendpunkt, um eine Verbindung zu einer anderen Region herzustellen. Wenn Sie für jede Region unterschiedliche Abos verwenden, muss jeder Abonnentenclient das entsprechende Abo verwenden. Die Regionen für Publisher und Abonnenten müssen nicht unbedingt identisch sein. Abonnenten empfangen Nachrichten über die drei Abos und verarbeiten sie.
Für diese Einrichtung gelten mehrere wichtige Funktionen und Anforderungen:
- Ein Ausfall in einer einzelnen Region hat keine Auswirkungen auf die Verarbeitung von Nachrichten, die bereits veröffentlicht wurden oder während des Ausfalls veröffentlicht werden. Da Nachrichten in mehreren Regionen veröffentlicht wurden, sind sie auch dann in anderen Regionen verfügbar, wenn eine Region ausfällt. Während des Ausfalls schlagen Publish-Aufrufe in der betroffenen Region fehl, in den anderen Regionen sind sie jedoch erfolgreich.
- Die Latenz bei der Nachrichtenverarbeitung ist nicht betroffen, solange eine der Regionen, durch die Nachrichten fließen, verfügbar ist.
- Die Nachrichtenverarbeitung muss idempotent sein. Da jede Nachricht mehrmals zugestellt wird, muss die Nachrichtenverarbeitung gegen Duplikate geschützt sein. Bei einem regionalen Ausfall können einige dieser Duplikate viel später als bei der ersten Zustellung der Nachricht eintreffen. Diese Duplikate stammen wahrscheinlich aus einer anderen Region, in der kein Ausfall aufgetreten ist.
Diese Art von Redundanz bietet die höchste Ausfallsicherheit. Für interne Google-Dienste, die auf Pub/Sub basieren und die höchste Verfügbarkeit erfordern, wird diese Einrichtung bevorzugt. Diese Einrichtung hat jedoch den Nachteil, dass sich die Kosten für die Nachrichtenübermittlung mit der Anzahl der verwendeten Regionen multiplizieren. Außerdem fallen zusätzliche Kosten für die interregionale Netzwerknutzung für Nachrichten an, die regionsübergreifend übertragen werden müssen.
Ein weiterer Ansatz für Redundanz besteht darin, nur dann ein Failover durchzuführen, wenn Anfragen fehlschlagen oder Nachrichten nicht wie erwartet von Publishern zu Abonnenten übertragen werden. In diesem Szenario haben Sie eine primäre Region, in die Sie Ihre Verlage und Abonnenten über standortbezogene Endpunkte leiten. Wie zuvor müssen diese nicht in derselben Region sein. Außerdem haben Sie dann eine Fallback-Region für Publisher und Abonnenten, die verwendet wird, wenn die primäre Region nicht verfügbar ist.
Publisher veröffentlichen nur in der primären Region (über den Standortendpunkt), wenn ihre Anfragen erfolgreich gesendet werden. Wenn die Region als nicht verfügbar eingestuft wird, veröffentlichen Publisher stattdessen in der Fallback-Region. Die Entscheidung, dass die Region nicht verfügbar ist und ein Failover durchgeführt werden muss, kann auf zwei Arten erfolgen. Das kann manuell erfolgen und die Konfiguration wird dynamisch bei den Verlagen und Webpublishern aktualisiert. Publisher können die Konfiguration auch selbst aktualisieren, wenn die Fehlerrate bei Veröffentlichungsanfragen hoch genug ist.
Abonnenten müssen sich immer über den Standortendpunkt mit der primären Region verbinden. Sie können festlegen, dass der Abonnent die Fallback-Region mit einem oder mehreren der folgenden Trigger verwenden kann:
- Immer die Fallback-Region abonnieren. In diesem Fall behält der Abonnent jederzeit eine Verbindung sowohl zur primären Region als auch zur Fallback-Region bei. Für primäre und Fallback-Streams können sowohl Publisher als auch Abonnenten dieselben Regionen verwenden. In diesem Fall darf der Abonnent Nachrichten nur über die Sicherungsregion empfangen, wenn der Publisher ein Failover durchgeführt hat.
- Abonnenten über eine Konfiguration manuell erkennen und zur Fallback-Region wechseln. Wenn Sie einen Ausfall erkennen, können Sie ein Failover zur Fallback-Region durchführen und dann zur primären Region zurückkehren, wenn der Ausfall behoben ist.
- Failover bei Abonnentenfehlern. Wenn bei den Abonnentenanfragen Fehler zurückgegeben werden, kann dies ein Hinweis darauf sein, dass Sie ein Failover zur Fallback-Region durchführen müssen. Die Pub/Sub-Clientbibliotheken wiederholen Streaming-Pull-Anfragen intern bei vorübergehenden Fehlern. Daher können Sie möglicherweise nicht erkennen, ob es lange Phasen unerwarteter Fehler gibt. Außerdem wird erwartet, dass die Fehlerrate für StreamingPull 100 % beträgt, auch während des normalen Betriebs.
- Failover, wenn der Abonnent unerwartet lange keine Nachrichten empfängt. Bei einer konsistenten Veröffentlichung von Nachrichten können die Abonnenten immer Nachrichten empfangen. Wenn sie über einen längeren Zeitraum keine Nachrichten empfangen, liegt möglicherweise ein Problem auf der Abonnentenseite in Pub/Sub in der primären Region vor. Dies wird durch das Failover zur Fallback-Region behoben.
Von allen vier Optionen ist die erste ideal. Eine Abonnentenverbindung kostet nichts, wenn keine Nachrichten darüber übertragen werden. Die einzigen Kosten entstehen durch die zusätzliche Instanz der Abonnentenclientbibliothek, die jedoch vernachlässigbar sein können. Sie müssen auch das Kontingent für die Anzahl der offenen StreamingPull-Verbindungen pro Region im Blick behalten.
Der Vorteil dieses zweiten Modells besteht darin, dass es keinen Multiplikator für die Pub/Sub-Kosten gibt, da Nachrichten nur einmal veröffentlicht werden. Der Nachteil ist jedoch, dass Nachrichten, die vor Beginn bestimmter Arten von Ausfällen veröffentlicht wurden, möglicherweise erst nach Behebung des Ausfalls verfügbar sind. Nachrichten, die in der nicht verfügbaren Region gespeichert sind, können möglicherweise nicht an Abonnenten gesendet werden, unabhängig davon, wo sie verbunden sind. Nachrichten, die während des Ausfalls in der Fallback-Region veröffentlicht wurden, sind möglicherweise verfügbar. Außerdem kann es zu einer vorübergehenden Nichtverfügbarkeit mit erhöhten Fehlerraten für die Publisher oder die Abonnenten kommen. Das hängt von der Methode ab, mit der ein Ausfall erkannt wird, und von der Zeit, die für das Failover zur Fallback-Region benötigt wird.
Unabhängig davon, welche Option Sie auswählen, sollten Sie sich darüber im Klaren sein, wie sich dies auf die Funktionen von Pub/Sub auswirken kann. Sowohl die geordnete Zustellung als auch die genau einmalige Zustellung bieten ihre Garantien innerhalb einer Region. Wenn Sie beispielsweise die Failover-Redundanz verwenden, wird die Nachrichtenübermittlung nur für Nachrichten garantiert, die in derselben Region veröffentlicht werden. Der Abonnent kann Nachrichten, die in der Fallback-Region veröffentlicht wurden, vor Nachrichten empfangen, die in der primären Region veröffentlicht wurden, auch wenn die Nachrichten zuerst in der primären Region veröffentlicht wurden.
Publisher optimieren
Unabhängig davon, welche Failover-Option Sie auswählen, sind einige zusätzliche Optimierungsschritte erforderlich, die Sie bei den Publishern selbst vornehmen müssen. Durch die Optimierung des Publisher-Verhaltens wird eine optimale Leistung bei hoher Last gewährleistet. Nachrichten in Batches zusammenfassen ist eine Möglichkeit, die Latenz zu verringern und gleichzeitig die Kosten zu senken. Dies ist jedoch weniger ein Problem der Zuverlässigkeit und wird daher hier nicht behandelt. Konzentrieren Sie sich stattdessen auf einige der anderen Parameter, die für die Zuverlässigkeit nützlich sind, einschließlich der Einstellungen für Wiederholungsversuche und der Einstellungen für die Flusssteuerung.
Die Veröffentlichung kann aus verschiedenen Gründen fehlschlagen, z. B. aufgrund vorübergehender Probleme wie einer nicht verfügbaren Netzwerkverbindung oder aufgrund von Problemen, die eine Nutzeraktion erfordern, z. B. Berechtigungsänderungen. Die Pub/Sub-Clientbibliothek wiederholt vorübergehende Fehler mithilfe der in den Wiederholungseinstellungen angegebenen Parameter. Diese Einstellungen steuern das Verhalten des exponentiellen Backoff bei Wiederholungsversuchen von Publish-RPCs, die aus vorübergehenden Gründen fehlschlagen. Die Standardeinstellungen funktionieren in den meisten Fällen gut. Es gibt jedoch Situationen, in denen Sie diese Werte anpassen sollten.
Die beiden Eigenschaften, die Sie am wahrscheinlichsten optimieren möchten, sind das anfängliche RPC-Zeitlimit und das Gesamtzeitlimit. Das anfängliche RPC-Zeitlimit gibt an, wie lange der erste Publish-RPC Zeit hat, bis er abgeschlossen sein muss. Wenn ein RPC fehlschlägt oder das Zeitlimit überschritten wird, wird ein weiterer RPC mit einem längeren Zeitlimit versucht, bis die Gesamtzahl der Anfragen oder das Gesamttimeout überschritten wird.
Das anfängliche Zeitlimit kann angepasst werden, wenn der Publisher durch das Netzwerk eingeschränkt ist oder sich weit entfernt vom nächsten Google Cloud -Rechenzentrum befindet, in dem Pub/Sub ausgeführt wird. Netzwerkbeschränkungen können durch die Bandbreite des Computers, auf dem der Publisher ausgeführt wird, oder durch andere Dienste, die auf demselben Computer ausgeführt werden und viel Netzwerkbandbreite benötigen, verursacht werden. Wenn die Zeitüberschreitung zu kurz eingestellt ist, können anfängliche RPCs wiederholt fehlschlagen. Das führt dazu, dass mehr Versuche (mit längeren Zeitüberschreitungen) erforderlich sind, um die Veröffentlichung erfolgreich abzuschließen. Die wiederholte Notwendigkeit von Wiederholungsversuchen erhöht die Veröffentlichungsverzögerung. In diesem Fall kann eine Erhöhung des anfänglichen Zeitlimits zu schnelleren Veröffentlichungen führen.
Wenn die Netzwerkverbindung nicht zuverlässig ist, kann es helfen, das gesamte und das anfängliche Zeitlimit zu erhöhen. Durch ein erhöhtes Gesamttimeout hat die Publish-RPC mehr Zeit, um erfolgreich abgeschlossen zu werden. Wenn Veröffentlichungs-RPCs immer wieder mit Fehlern aufgrund überschrittener Fristen fehlschlagen, sollten Sie diese Werte anpassen.
Wenn beim Veröffentlichen wiederholt Fehler aufgrund überschrittener Fristen auftreten, müssen Sie möglicherweise die Ablaufsteuerung für Publisher anpassen. Mit diesen Einstellungen können Sie dafür sorgen, dass Ihre Publisher auch bei Spitzen des eingehenden Traffics, die zu mehr Nachrichten führen, die an Pub/Sub gesendet werden müssen, stabil bleiben. Ein starker Anstieg der ausgehenden Anfragen kann die CPU, den Arbeitsspeicher oder die Netzwerkkapazität des Publishers überlasten. Wenn der Publish-Vorgang überlastet ist, können Publish-Anfragen oder -Antworten nicht vor den Zeitüberschreitungen verarbeitet werden. Das führt zu noch mehr Veröffentlichungsanfragen und schließlich zum Erreichen des gesamten Zeitlimits. Die Ablaufsteuerung für Publisher begrenzt die Anzahl der Nachrichten oder Bytes, die ohne Antwort auf die Publish-Anfrage ausstehen können. Durch die Begrenzung der Anzahl der Anfragen wird die Ressourcennutzung auf einem überschaubaren Niveau gehalten, auch bei Spitzen. Je nachdem, wie Ihr Publisher arbeitet, können Sie zulassen, dass nachfolgende Publish-RPCs auf Kapazität warten, indem Sie zulassen, dass Publish weitere Anfragen blockiert. Alternativ können Sie die Anrufer Ihres Dienstes zurückweisen, indem Sie bei Erreichen der Kapazität einen Fehler zurückgeben. Sie konfigurieren, wie die Publisher-Clientbibliothek auf das Überschreiten des Limits reagiert.
Abonnenten optimieren
Möglicherweise ist auch eine Anpassung durch den Abonnenten erforderlich, damit sie zuverlässig funktionieren. Ähnlich wie bei Publishern können Sie die Einstellungen für die Ablaufsteuerung von Abonnenten anpassen, um sicherzustellen, dass sie nicht überfordert werden. Die Abonnenten-Clientbibliothek verwendet Streaming-Pull, bei dem der Client einen persistenten Stream zum Server öffnet und der Server Nachrichten sendet, sobald sie verfügbar sind. Bei einer starken Zunahme der veröffentlichten Nachrichten kann der Abonnent mehr Nachrichten erhalten, als er verarbeiten kann. Durch die Ablaufsteuerung wird die Anzahl der unbestätigten Nachrichten, die für den Client zu einem bestimmten Zeitpunkt ausstehen, begrenzt. Dadurch wird die Anzahl der gleichzeitig verarbeiteten Nachrichten reduziert und die Verarbeitung über einen längeren Zeitraum verteilt. Durch die Verteilung der Last können Abonnenten unter allen Ressourcenbeschränkungen bleiben, die sich auf die Nachrichtenverarbeitung auswirken. Dies kann zu einem Kaskadeneffekt führen, der dazu führt, dass keine Nachrichten mehr verarbeitet werden können.
Die Ablaufsteuerung allein reicht aus, wenn Sie nur mit vorübergehenden Spitzen bei der zu verarbeitenden Datenmenge rechnen. Wenn der Traffic im Laufe der Zeit aufgrund einer höheren Nutzung zunimmt, schützt die Ablaufsteuerung die Abonnenten. Dies kann jedoch zu einem Rückstand führen, der immer größer wird und dazu, dass Nachrichten nicht zugestellt werden können, bevor die Aufbewahrungsdauer für Nachrichten abläuft. In solchen Fällen kann es auch sinnvoll sein, das Autoscaling so einzustellen, dass mehr Abonnenten aktiviert werden, wenn die Anzahl der nicht bestätigten Nachrichten steigt. Wie du das einrichtest, hängt von der Compute-Plattform ab, die du für deine Abonnenten verwendest. Mit dem Autoscaler von Compute Engine können Sie beispielsweise anhand von Messwerten wie der Anzahl nicht zugestellter Nachrichten skalieren. Durch die Verwendung von Autoscaling und Ablaufsteuerung können Sie dafür sorgen, dass Ihre Abonnenten auch bei kurzfristigen Spitzen im Nachrichtendurchsatz und langfristigem Wachstum, das mehr Rechenleistung erfordert, stabil bleiben. Halten Sie sich an die Best Practices für die Verwendung von Pub/Sub-Messwerten als Skalierungssignal.
Snapshot und Seek für sichere Deployments verwenden
Der Verlust von Nachrichten ist in der Regel ein katastrophales Ereignis. Pub/Sub bietet eine mindestens einmalige Zustellung für alle veröffentlichten Nachrichten. Die korrekte Verarbeitung dieser Nachrichten hängt jedoch vom Verhalten der Abonnenten ab. Wenn Nachrichten erfolgreich bestätigt werden, werden sie von Pub/Sub nicht noch einmal zugestellt. Ein Fehler im neuen Abonnentencode, den Sie bereitstellen, der Nachrichten bestätigt, ohne sie richtig verarbeitet zu haben, kann daher zu einem durch den Abonnenten verursachten Nachrichtenverlust führen. Pub/Sub bietet die Funktion Snapshot und Seek, mit der Sie dafür sorgen können, dass jede Nachricht korrekt verarbeitet wird, auch wenn Fehler beim Abonnenten auftreten.
Das Muster für jede Abonnentenbereitstellung muss so aussehen:
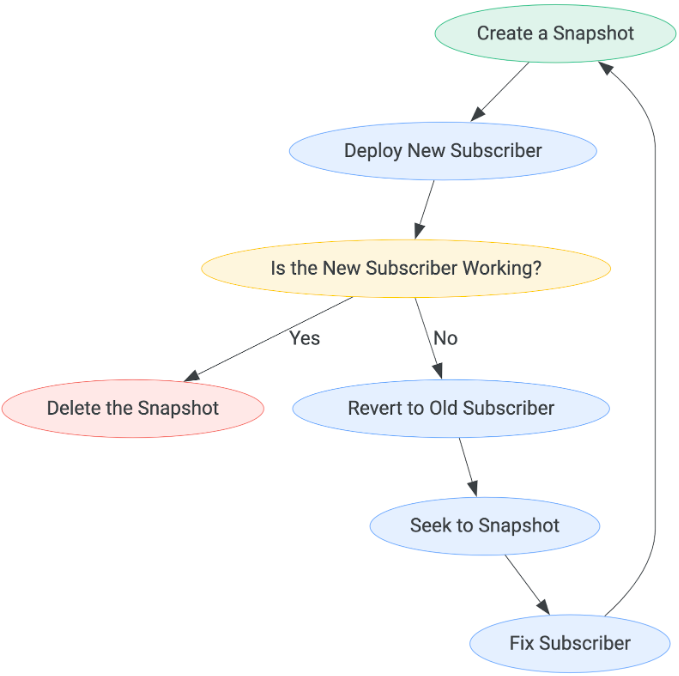
Die Wartezeit, bevor Sie feststellen können, ob das neue Abo funktioniert, kann je nach Anwendungsfall variieren. Der einzige Weg, den Ablauf der Schritte zu beenden, ist, wenn ein Abonnent als aktiv eingestuft wird. Dann kann der Snapshot gelöscht werden.
Die Verwendung von Snapshot und Seek soll nicht die Best Practices ersetzen, Software zuerst in einer Nicht-Produktionsumgebung auszuführen und sie schrittweise in der Produktion bereitzustellen. Sie bieten eine zusätzliche Schutzebene, um die zuverlässige Verarbeitung von Daten zu gewährleisten. Der Nachteil ist, dass das Suchen nach dem Snapshot dazu führen kann, dass Nachrichten, die dein Abonnent erfolgreich verarbeitet hat, doppelt zugestellt werden. Da Pub/Sub jedoch standardmäßig eine mindestens einmalige Zustellung bietet, sind Ihre Abonnenten bereits gegen die erneute Zustellung von Nachrichten geschützt.