Vous pouvez utiliser la console Google Cloud ou l'API Cloud Monitoring pour surveiller Pub/Sub.
Ce document explique comment surveiller votre utilisation de Pub/Sub dans la console Google Cloud à l'aide de Monitoring.
Si vous souhaitez afficher les métriques d'autres ressources Google Cloud en plus des métriques Pub/Sub, utilisez Monitoring.
Sinon, vous pouvez utiliser les tableaux de bord de surveillance fournis dans Pub/Sub. Consultez Surveiller les thèmes et Surveiller les abonnements.
Pour connaître les bonnes pratiques concernant l'utilisation des métriques dans votre autoscaling, consultez Bonnes pratiques pour utiliser les métriques Pub/Sub comme signal de scaling.
Avant de commencer
Avant d'utiliser Monitoring, assurez-vous d'avoir préparé les éléments suivants :
Un compte de facturation Cloud
Un projet Pub/Sub avec la facturation activée
Pour vérifier que vous avez bien obtenu les deux, suivez le guide de démarrage rapide sur l'utilisation de la console Cloud.
Afficher un tableau de bord existant
Un tableau de bord vous permet d'afficher et d'analyser des données provenant de différentes sources dans le même contexte. Google Cloud fournit des tableaux de bord prédéfinis et personnalisés. Par exemple, vous pouvez afficher un tableau de bord Pub/Sub prédéfini ou créer un tableau de bord personnalisé qui affiche les données de métriques, les règles d'alerte et les entrées de journal liées à Pub/Sub.
Pour surveiller votre projet Pub/Sub à l'aide de Cloud Monitoring, procédez comme suit :
Dans la console Google Cloud , accédez à la page Monitoring.
En haut de la page, sélectionnez le nom de votre projet s'il n'est pas déjà sélectionné.
Dans le menu de navigation, cliquez sur Tableaux de bord.
Sur la page Aperçu des tableaux de bord, créez un tableau de bord ou sélectionnez le tableau de bord Pub/Sub existant.
Pour rechercher le tableau de bord Pub/Sub existant, dans le filtre Tous les tableaux de bord, sélectionnez la propriété Nom et saisissez
Pub/Sub.
Pour savoir comment créer, modifier et gérer un tableau de bord personnalisé, consultez Gérer les tableaux de bord personnalisés.
Afficher une seule métrique Pub/Sub
Pour afficher une seule métrique Pub/Sub à l'aide de la console Google Cloud , procédez comme suit :
Dans la console Google Cloud , accédez à la page Monitoring.
Dans le volet de navigation, sélectionnez Explorateur de métriques.
Dans la section Configuration, cliquez sur Sélectionner une métrique.
Dans le filtre, saisissez
Pub/Sub.Dans Ressources actives, sélectionnez Abonnement Pub/Sub ou Sujet Pub/Sub.
Accédez à une métrique spécifique, puis cliquez sur Appliquer.
La page d'une métrique spécifique s'ouvre.
Pour en savoir plus sur le tableau de bord de surveillance, consultez la documentation Cloud Monitoring.
Afficher les métriques et les types de ressources Pub/Sub
Pour afficher les métriques que Pub/Sub rapporte à Cloud Monitoring, consultez la liste des métriques Pub/Sub dans la documentation Cloud Monitoring.
Pour afficher les détails des types de ressources surveillées
pubsub_topic,pubsub_subscriptionoupubsub_snapshot, consultez la section Types de ressources surveillées dans la documentation Cloud Monitoring.
Accéder à l'éditeur PromQL
L'explorateur de métriques est une interface de Cloud Monitoring conçue pour explorer et visualiser vos données de métriques. Dans l'explorateur de métriques, vous pouvez utiliser le langage de requête Prometheus (PromQL) pour interroger et analyser vos métriques Pub/Sub.
Pour accéder à l'éditeur de code et interroger les métriques Cloud Monitoring avec PromQL dans l'explorateur de métriques, consultez Utiliser l'éditeur de code pour PromQL.
Par exemple, vous pouvez saisir une requête PromQL pour surveiller le nombre de messages envoyés à un abonnement spécifique sur une période glissante d'une heure :
sum(
increase({
"__name__"="pubsub.googleapis.com/subscription/sent_message_count",
"monitored_resource"="pubsub_subscription",
"project_id"="your-project-id",
"subscription_id"="your-subscription-id"
}[1h])
)
Surveiller l'utilisation du quota
Pour un projet donné, vous pouvez consulter les quotas actuels et leur utilisation dans le tableau de bord des quotas IAM et d'administration.
Vous pouvez afficher l'historique de votre utilisation des quotas à l'aide des métriques suivantes :
Ces métriques utilisent le type de ressource surveillée consumer_quota. Pour plus de métriques liées aux quotas, consultez la liste des métriques.
Par exemple, la requête PromQL suivante crée un graphique avec la fraction de quota d'éditeur utilisée dans chaque région :
sum by (quota_metric, location) (
rate({
"__name__"="serviceruntime.googleapis.com/quota/rate/net_usage",
"monitored_resource"="consumer_quota",
"service"="pubsub.googleapis.com",
"quota_metric"="pubsub.googleapis.com/regionalpublisher"
}[${__interval}])
)
/
(max by (quota_metric, location) (
max_over_time({
"__name__"="serviceruntime.googleapis.com/quota/limit",
"monitored_resource"="consumer_quota",
"service"="pubsub.googleapis.com",
"quota_metric"="pubsub.googleapis.com/regionalpublisher"
}[${__interval}])
) / 60 )
Si vous prévoyez que votre utilisation dépasse les limites de quota par défaut, créez des règles d'alerte pour tous les quotas correspondants. Ces alertes se déclenchent lorsque votre utilisation atteint une fraction de la limite. Par exemple, la requête PromQL suivante déclenche une règle d'alerte lorsqu'un quota Pub/Sub dépasse 80 % :
sum by (quota_metric, location) (
increase({
"__name__"="serviceruntime.googleapis.com/quota/rate/net_usage",
"monitored_resource"="consumer_quota",
"service"="pubsub.googleapis.com"
}[1m])
)
/
max by (quota_metric, location) (
max_over_time({
"__name__"="serviceruntime.googleapis.com/quota/limit",
"monitored_resource"="consumer_quota",
"service"="pubsub.googleapis.com"
}[1m])
)
> 0.8
Pour une surveillance plus personnalisée et des alertes sur les métriques de quota, consultez la page Utiliser des métriques de quota.
Pour en savoir plus, consultez la page Quotas et limites.
Maintenir un abonnement sain
Pour maintenir un abonnement en bon état, vous pouvez surveiller plusieurs de ses propriétés à l'aide des métriques fournies par Pub/Sub. Par exemple, vous pouvez surveiller le volume de messages non confirmés, l'expiration des délais de confirmation des messages, etc. Vous pouvez également vérifier si votre abonnement est suffisamment sain pour obtenir une faible latence de distribution des messages.
Pour en savoir plus sur les métriques spécifiques, consultez les sections suivantes.
Surveiller les messages en attente
Pour vous assurer que vos abonnés gèrent le flux des messages, créez un tableau de bord. Le tableau de bord peut afficher les métriques de messages en attente suivantes, regroupées par ressource, pour tous vos abonnements :
Messages non confirmés (
subscription/num_unacked_messages_by_region) pour afficher le nombre de messages non confirmés.Âge du plus ancien message non confirmé (
subscription/oldest_unacked_message_age_by_region) : affiche l'âge du plus ancien message non confirmé dans les messages en attente de l'abonnement.L'évaluation de la latence de diffusion (
subscription/delivery_latency_health_score) permet de vérifier l'état général de l'abonnement en termes de latence de diffusion. Pour en savoir plus sur cette métrique, consultez la section correspondante de ce document.
Créez des règles d'alerte qui se déclenchent lorsque ces valeurs sont en dehors de la plage acceptable dans le contexte de votre système. Par exemple, le nombre absolu de messages non confirmés n'est pas forcément significatif. Une valeur d'un million de messages en attente peut être acceptable pour un abonnement à un million de messages par seconde, et inacceptable pour un abonnement à un message par seconde.
Problèmes courants liés au backlog
| Symptômes | Problème | Solutions |
|---|---|---|
Les valeurs oldest_unacked_message_age_by_region et num_unacked_messages_by_region augmentent conjointement. |
Les abonnés n'arrivent pas à gérer le volume de messages |
|
Si le volume des tâches en attente est faible et stable, et que la valeur oldest_unacked_message_age_by_region augmente progressivement, il peut y avoir quelques messages impossibles à traiter. |
Messages bloqués |
|
La valeur oldest_unacked_message_age_by_region dépasse la
durée de conservation des messages définie dans l'abonnement. |
Perte définitive de données |
|
Surveiller l'état de la latence de diffusion
Dans Pub/Sub, la latence de distribution correspond au temps nécessaire pour qu'un message publié soit distribué à un abonné.
Si votre backlog de messages augmente, vous pouvez utiliser le score d'intégrité de la latence de distribution (subscription/delivery_latency_health_score) pour vérifier quels facteurs contribuent à l'augmentation de la latence.
Cette métrique mesure l'état d'un seul abonnement sur une période glissante de 10 minutes. Cette métrique fournit des informations sur les critères suivants, qui sont nécessaires pour qu'un abonnement atteigne une latence faible et constante :
Les demandes de recherche sont négligeables.
Messages négatifs confirmés (NACK) négligeables.
Délais de confirmation des messages expirés négligeables.
Latence d'accusé de réception constante inférieure à 30 secondes.
Une utilisation faible et constante, ce qui signifie que l'abonnement dispose toujours d'une capacité suffisante pour traiter les nouveaux messages.
La métrique Évaluation de la latence de diffusion indique un score de 0 ou 1 pour chacun des critères spécifiés. Un score de 1 indique un état opérationnel et un score de 0 indique un état non opérationnel.
Demandes de recherche : si l'abonnement a fait l'objet de demandes de recherche au cours des 10 dernières minutes, le score est défini sur 0. Une recherche d'abonnement peut entraîner la relecture d'anciens messages longtemps après leur première publication, ce qui augmente leur latence de distribution.
Messages ayant fait l'objet d'un accusé de réception négatif : si l'abonnement a fait l'objet de demandes d'accusé de réception négatif au cours des 10 dernières minutes, le score est défini sur 0. Un accusé de réception négatif entraîne la rediffusion d'un message avec une latence de diffusion accrue.
Délais de confirmation expirés : si l'abonnement a expiré au cours des 10 dernières minutes, le score est défini sur 0. Les messages dont le délai de confirmation a expiré sont à nouveau distribués avec une latence de distribution plus élevée.
Latences d'accusé de réception : si le 99,9e centile de toutes les latences d'accusé de réception au cours des 10 dernières minutes a déjà été supérieur à 30 secondes, le score est défini sur 0. Une latence de confirmation élevée indique qu'un client abonné met un temps anormalement long à traiter un message. Ce score peut impliquer un bug ou des contraintes de ressources côté client abonné.
Utilisation faible : l'utilisation est calculée différemment pour chaque type d'abonnement.
StreamingPull : si vous n'avez pas assez de flux ouverts, le score est défini sur 0. Ouvrez d'autres flux pour vous assurer d'avoir une capacité suffisante pour les nouveaux messages.
Push : si vous avez trop de messages en attente à votre point de terminaison push, le score est défini sur 0. Augmentez la capacité de votre point de terminaison push pour pouvoir recevoir de nouveaux messages.
Pull : si vous n'avez pas assez de demandes d'extraction en attente, le score est défini sur 0. Ouvrez plus de demandes d'extraction simultanées pour vous assurer d'être prêt à recevoir de nouveaux messages.
Pour afficher la métrique, dans l'explorateur de métriques, sélectionnez la métrique Score d'état de la latence de remise pour le type de ressource d'abonnement Pub/Sub. Ajoutez un filtre pour ne sélectionner qu'un seul abonnement à la fois. Sélectionnez le graphique en aires empilées et pointez sur un moment précis pour vérifier les scores des critères de l'abonnement à ce moment-là.
Voici une capture d'écran de la métrique représentée sur une période d'une heure à l'aide d'un graphique en aires empilées. Le score de santé combiné atteint 5 à 4h15, avec un score de 1 pour chaque critère. Plus tard, le score combiné diminue à 4 à 4h20, lorsque le score d'utilisation tombe à 0.
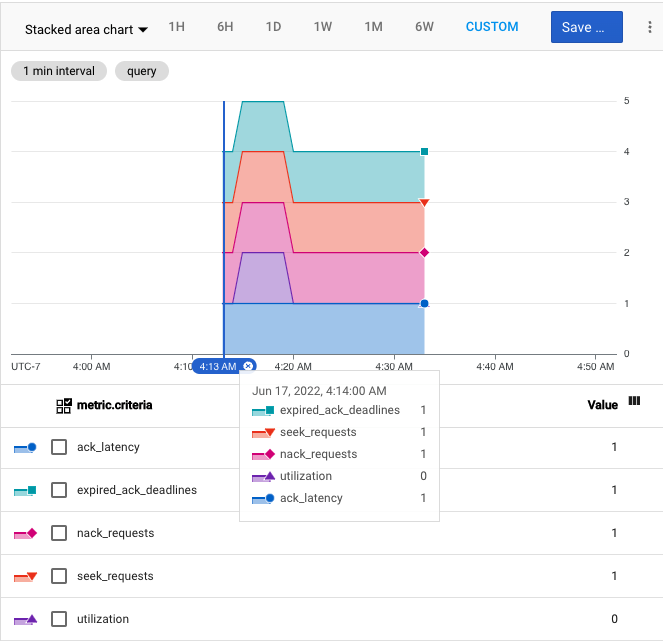
PromQL fournit une interface textuelle expressive aux données de séries temporelles de Cloud Monitoring. La requête PromQL suivante crée un graphique pour mesurer le score d'état de latence de distribution d'un abonnement.
sum_over_time(
{
"__name__"="pubsub.googleapis.com/subscription/delivery_latency_health_score",
"monitored_resource"="pubsub_subscription",
"subscription_id"="$SUBSCRIPTION"
}[${__interval}]
)
Surveiller l'arrivée à expiration du délai de confirmation
Afin de réduire la latence de distribution des messages, Pub/Sub accorde aux clients abonnés une période limitée pour accuser réception d'un message donné. Cette période est appelée "délai d'accusé de réception". Si vos abonnés mettent trop de temps à accuser réception des messages, ceux-ci sont redistribués, ce qui entraîne la réception de messages en double. Cette nouvelle tentative de distribution peut avoir lieu pour différentes raisons :
Vos abonnés sont sous-provisionnés (vous avez besoin de davantage de threads ou de machines).
Le traitement de chaque message dépasse le délai de confirmation des messages. En règle générale, les bibliothèques clientes Cloud augmentent le délai de chaque message jusqu'à la valeur maximale. Toutefois, la prolongation du délai maximale s'applique également aux bibliothèques.
Certains messages entraînent systématiquement le plantage du client.
Vous pouvez mesurer le rythme auquel les abonnés dépassent le délai de confirmation. La métrique spécifique dépend du type d'abonnement :
Pull et StreamingPull :
subscription/expired_ack_deadlines_countPush :
subscription/push_request_countfiltré parresponse_code != "success"
Des taux d'expiration du délai de confirmation excessifs peuvent entraîner des sources d'inefficacité coûteuses dans votre système. Chaque redistribution et chaque tentative de traitement d'un message entraîne des coûts. À l'inverse, un taux d'expiration faible (par exemple, entre 0,1 et 1 %) peut s'avérer plus sain.
Surveiller le débit des messages
Les abonnés Pull et StreamingPull peuvent recevoir des lots de messages dans chaque réponse pull. Les abonnements push reçoivent un seul message dans chaque requête push. Vous pouvez surveiller le débit de messages par lot traités par vos abonnés à l'aide des métriques suivantes :
Pull :
subscription/pull_request_count(notez que cette métrique peut également inclure les demandes d'extraction qui n'ont renvoyé aucun message)StreamingPull :
subscription/streaming_pull_response_count
Vous pouvez surveiller le débit de messages individuels ou non regroupés traités par vos abonnés à l'aide de la métrique subscription/sent_message_count filtrée par le libellé delivery_type.
La requête PromQL suivante vous fournit un graphique de série temporelle indiquant le nombre total de messages envoyés à un abonnement Pub/Sub spécifique sur une période glissante de 10 minutes. Remplacez les valeurs d'espace réservé pour $PROJECT_NAME et $SUBSCRIPTION_NAME par les identifiants réels de votre projet et de votre thème.
sum(
increase({
"__name__"="pubsub.googleapis.com/subscription/sent_message_count",
"monitored_resource"="pubsub_subscription",
"project_id"="$PROJECT_NAME",
"subscription_id"="$SUBSCRIPTION_NAME"
}[10m])
)
Surveiller les abonnements push
Pour les abonnements push, surveillez ces métriques :
subscription/push_request_countRegroupez la métrique par
response_codeetsubscription_id. Étant donné que les abonnements push Pub/Sub utilisent des codes de réponse comme accusés de réception de messages implicites, il est important de surveiller les codes de réponse des requêtes push. Étant donné que les abonnements push cessent de fonctionner de manière exponentielle en cas de délais avant expiration ou d'erreurs, le nombre de vos tâches en attente peut augmenter rapidement en fonction de la réponse de votre point de terminaison.Envisagez de définir une alerte pour les taux d'erreur élevés, car ils entraînent un ralentissement de la distribution et une augmentation du nombre de tâches en attente. Vous pouvez créer une métrique filtrée par classe de réponse. Toutefois, le nombre de requêtes push peut s'avérer plus utile en tant qu'outil permettant d'étudier la croissance de la taille et de l'âge des tâches en attente.
subscription/num_outstanding_messagesEn règle générale, Pub/Sub limite le nombre de messages en attente. Dans la plupart des cas,essayez de ne pas dépasser 1 000 messages en attente. Une fois que le débit atteint une valeur de l'ordre de 10 000 messages par seconde, le service ajuste la limite du nombre de messages en attente. Cette limitation est effectuée par incréments de 1 000. Comme aucune garantie spécifique n'est apportée au-delà de la valeur maximale, il est recommandé de s'en tenir à 1 000 messages en attente.
subscription/push_request_latenciesCette métrique vous aide à comprendre la répartition de la latence des réponses du point de terminaison push. En raison de la limite appliquée au nombre de messages en attente, la latence du point de terminaison a une incidence sur le débit de l'abonnement. Si le traitement de chaque message nécessite 100 millisecondes, il est probable que votre limite de débit soit de 10 messages par seconde.
Pour accéder à des limites de messages en attente plus élevées, les abonnés push doivent accuser réception de plus de 99 % des messages qu'ils reçoivent.
Vous pouvez calculer la fraction de messages confirmés par les abonnés à l'aide de PromQL. La requête PromQL suivante permet de créer un graphique avec la fraction de messages confirmés par les abonnés sur un abonnement :
rate({
"__name__"="pubsub.googleapis.com/subscription/push_request_count",
"monitored_resource"="pubsub_subscription",
"subscription_id"="$SUBSCRIPTION",
"response_class"="ack"
}[${__interval}])
/
rate({
"__name__"="pubsub.googleapis.com/subscription/push_request_count",
"monitored_resource"="pubsub_subscription",
"subscription_id"="$SUBSCRIPTION"
}[${__interval}])
Surveiller les abonnements avec des filtres
Si vous configurez un filtre sur un abonnement, Pub/Sub reconnaît automatiquement les messages qui ne correspondent pas au filtre. Vous pouvez surveiller cet accusé de réception automatique.
Les métriques de messages en attente n'incluent que les messages correspondant au filtre.
Pour surveiller le taux de messages confirmés automatiquement qui ne correspondent pas au filtre, utilisez la métrique subscription/ack_message_count avec le libellé delivery_type défini sur filter.
Pour surveiller le débit et le coût des messages avec accusé de réception automatique qui ne correspondent pas au filtre, utilisez la métrique subscription/byte_cost avec le libellé operation_type défini sur filter_drop. Pour en savoir plus sur les frais liés à ces messages, consultez la page des tarifs de Pub/Sub.
Surveiller les abonnements avec les outils de surveillance et de test
Si votre abonnement contient un SMT qui filtre les messages, les métriques de backlog incluent les messages filtrés jusqu'à ce que le SMT s'exécute réellement sur eux. Cela signifie que le backlog peut sembler plus important et que l'âge du plus ancien message non confirmé peut sembler plus élevé que ce qui sera envoyé à votre abonné. Il est particulièrement important de garder cela à l'esprit si vous utilisez ces métriques pour effectuer un scaling automatique des abonnés.
Surveiller les messages non distribuables transférés
Pour surveiller les messages non distribuables que Pub/Sub transfère vers un sujet de lettres mortes, utilisez la métrique subscription/dead_letter_message_count. Cette métrique indique le nombre de messages non distribuables que Pub/Sub transfère à partir d'un abonnement.
Pour vérifier que Pub/Sub transfère les messages non distribuables, vous pouvez comparer la métrique subscription/dead_letter_message_count avec la métrique topic/send_request_count. Comparez-les pour le file d'attente de lettres mortes vers lequel Pub/Sub transfère ces messages.
Vous pouvez également associer un abonnement au file d'attente de lettres mortes, puis surveiller les messages non distribuables transférés sur cet abonnement à l'aide des métriques suivantes :
subscription/num_unacked_messages_by_region- le nombre de messages transférés accumulés dans l'abonnement
subscription/oldest_unacked_message_age_by_region- âge du plus ancien message transféré dans l'abonnement
Maintenir un éditeur sain
Le principal objectif d'un éditeur est de conserver rapidement les données des messages. Surveillez ces performances à l'aide de topic/send_request_count, regroupées par response_code. Cette métrique vous indique si Pub/Sub est opérationnel et accepte les requêtes.
Le taux d'erreurs renouvelables en arrière-plan (inférieur à 1 %) ne devrait pas être une source d'inquiétude, car la plupart des bibliothèques clientes Cloud effectuent de nouvelles tentatives après échec. Examinez les taux d'erreur supérieurs à 1 %.
Étant donné que les codes non renouvelables sont traités par votre application (et non par la bibliothèque cliente), vous devez examiner les codes de réponse. Si votre application d'éditeur ne permet pas de signaler un état défaillant correctement, envisagez de définir une alerte sur la métrique topic/send_request_count.
Il est tout aussi important de suivre les requêtes de publication ayant échoué dans votre client de publication. Bien que les bibliothèques clientes relancent généralement les requêtes ayant échoué, elles ne garantissent pas la publication. Pour savoir comment détecter les échecs de publication permanents lors de l'utilisation des bibliothèques clientes Cloud, reportez-vous à la section Publier des messages. Au minimum, votre application d'éditeur doit consigner les erreurs de publication permanentes. Si vous enregistrez ces erreurs dans Cloud Logging, vous pouvez configurer une métrique basée sur les journaux avec une règle d'alerte.
Surveiller le débit des messages
Les éditeurs peuvent envoyer des messages par lots. Vous pouvez surveiller le débit de messages envoyés par vos éditeurs à l'aide des métriques suivantes :
topic/send_request_count: volume de messages par lot envoyés par les éditeurs.count de
topic/message_sizes: volume de messages individuels (non regroupés) envoyés par les éditeurs.
Pour obtenir un nombre précis de messages publiés, utilisez la requête PromQL suivante. Cette requête PromQL récupère efficacement le nombre de messages individuels publiés dans un sujet Pub/Sub spécifique au cours d'intervalles de temps définis. Remplacez les valeurs d'espace réservé pour $PROJECT_NAME et $TOPIC_ID par les identifiants réels de votre projet et de votre thème.
sum by (topic_id) (
increase({
"__name__"="pubsub.googleapis.com/topic/message_sizes_count",
"monitored_resource"="pubsub_topic",
"project_id"="$PROJECT_NAME",
"topic_id"="$TOPIC_ID"
}[${__interval}])
)
Pour une meilleure visualisation, en particulier pour les métriques quotidiennes, tenez compte des points suivants :
Affichez vos données sur une période plus longue pour obtenir plus de contexte sur les tendances quotidiennes.
Utilisez des graphiques à barres pour représenter le nombre de messages quotidiens.
Étapes suivantes
Pour créer une alerte pour une métrique spécifique, consultez Gérer les règles d'alerte basées sur les métriques.
Pour en savoir plus sur l'utilisation de PromQL pour créer des graphiques de surveillance, consultez Utiliser l'éditeur de code pour PromQL.
Pour en savoir plus sur les ressources d'API pour l'API Monitoring, telles que les métriques, les ressources surveillées, les groupes de ressources surveillées et les règles d'alerte, consultez Ressources d'API.