En este documento se ofrece una descripción general de una suscripción de BigQuery, su flujo de trabajo y las propiedades asociadas.
Una suscripción de BigQuery es un tipo de suscripción de exportación que escribe mensajes en una tabla de BigQuery a medida que se reciben. No es necesario configurar un cliente de suscriptor independiente. Usa la Google Cloud consola, la CLI de Google Cloud, las bibliotecas de cliente o la API de Pub/Sub para crear, actualizar, enumerar, separar o eliminar una suscripción de BigQuery.
Sin el tipo de suscripción de BigQuery, necesitas una suscripción de extracción o de inserción y un suscriptor (como Dataflow) que lea los mensajes y los escriba en una tabla de BigQuery. No es necesario sobrecargar el sistema ejecutando una tarea de Dataflow cuando los mensajes no requieren un procesamiento adicional antes de almacenarlos en una tabla de BigQuery. En su lugar, puedes usar una suscripción de BigQuery.
Sin embargo, sigue siendo recomendable usar una canalización de Dataflow en sistemas de Pub/Sub en los que se requiera alguna transformación de datos antes de que estos se almacenen en una tabla de BigQuery. Para saber cómo transmitir datos de Pub/Sub a BigQuery con transformación mediante Dataflow, consulta el artículo sobre la transmisión de datos de Pub/Sub a BigQuery.
La plantilla de suscripción de Pub/Sub a BigQuery de Dataflow aplica la entrega exactamente una vez de forma predeterminada. Esto se suele conseguir mediante mecanismos de desduplicación en la canalización de Dataflow. Sin embargo, la suscripción de BigQuery solo admite la entrega al menos una vez. Si la desduplicación exacta es fundamental para tu caso práctico, considera la posibilidad de usar procesos posteriores en BigQuery para gestionar los posibles duplicados.
Antes de empezar
Antes de leer este documento, asegúrate de que conoces los siguientes conceptos:
Cómo funciona Pub/Sub y los diferentes términos de Pub/Sub.
Los diferentes tipos de suscripciones que admite Pub/Sub y por qué te puede interesar usar una suscripción de BigQuery.
Cómo funciona BigQuery y cómo configurar y gestionar tablas de BigQuery.
Flujo de trabajo de suscripción a BigQuery
En la siguiente imagen se muestra el flujo de trabajo entre una suscripción de BigQuery y BigQuery.
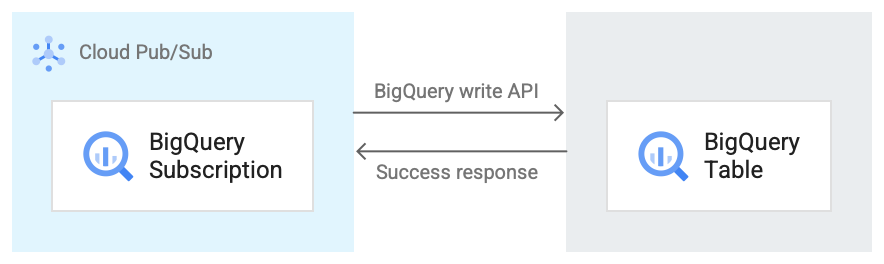
A continuación, se incluye una breve descripción del flujo de trabajo que se muestra en la imagen 1:
- Pub/Sub usa la API de escritura de almacenamiento de BigQuery para enviar datos a la tabla de BigQuery.
- Los mensajes se envían en lotes a la tabla de BigQuery.
- Cuando se completa correctamente una operación de escritura, la API devuelve una respuesta OK.
- Si se produce algún fallo en la operación de escritura, el mensaje de Pub/Sub se confirma de forma negativa. A continuación, se vuelve a enviar el mensaje. Si el mensaje falla suficientes veces y hay un tema de mensajes fallidos configurado en la suscripción, el mensaje se moverá al tema de mensajes fallidos.
Propiedades de una suscripción de BigQuery
Las propiedades que configures en una suscripción de BigQuery determinan la tabla de BigQuery en la que Pub/Sub escribe los mensajes y el tipo de esquema de esa tabla.
Para obtener más información, consulta las propiedades de BigQuery.
Compatibilidad de esquemas
Esta sección solo se aplica si selecciona la opción Usar esquema de tema al crear una suscripción a BigQuery.
Pub/Sub y BigQuery usan formas diferentes de definir sus esquemas. Los esquemas de Pub/Sub se definen en formato Apache Avro o Protocol Buffer, mientras que los esquemas de BigQuery se definen con varios formatos.
A continuación, se muestra una lista de información importante sobre la compatibilidad de esquemas entre un tema de Pub/Sub y una tabla de BigQuery.
Los mensajes que contengan un campo con un formato incorrecto no se escribirán en BigQuery.
En el esquema de BigQuery,
INT,SMALLINT,INTEGER,BIGINT,TINYINTyBYTEINTson alias deINTEGER;DECIMALes un alias deNUMERIC, yBIGDECIMALes un alias deBIGNUMERIC.Si el tipo del esquema del tema es
stringy el tipo de la tabla de BigQuery esJSON,TIMESTAMP,DATETIME,DATE,TIME,NUMERICoBIGNUMERIC, cualquier valor de este campo en un mensaje de Pub/Sub debe cumplir el formato especificado para el tipo de datos de BigQuery.Se admiten algunos tipos lógicos de Avro, tal como se especifica en la siguiente tabla. Los tipos lógicos que no se incluyan en la lista solo coincidirán con el tipo Avro equivalente al que anotan, tal como se detalla en la especificación de Avro.
A continuación, se muestra una colección de asignaciones de diferentes formatos de esquema a tipos de datos de BigQuery.
Tipos de Avro
| Tipo de Avro | Tipo de datos de BigQuery |
null |
Any NULLABLE |
boolean |
BOOLEAN |
int |
INTEGER, NUMERIC o
BIGNUMERIC |
long |
INTEGER, NUMERIC o
BIGNUMERIC |
float |
FLOAT64, NUMERIC o
BIGNUMERIC |
double |
FLOAT64, NUMERIC o
BIGNUMERIC |
bytes |
BYTES, NUMERIC o
BIGNUMERIC |
string |
STRING, JSON,
TIMESTAMP, DATETIME,
DATE, TIME,
NUMERIC o BIGNUMERIC |
record |
RECORD/STRUCT |
array de Type |
REPEATED Type |
map con el tipo de valor ValueType
|
REPEATED STRUCT <key STRING, value
ValueType> |
union con dos tipos: uno null y otro Type |
NULLABLE Type |
otros unions |
No se puede asignar |
fixed |
BYTES, NUMERIC o
BIGNUMERIC |
enum |
INTEGER |
Tipos lógicos de Avro
| Tipo lógico de Avro | Tipo de datos de BigQuery |
timestamp-micros |
TIMESTAMP |
date |
DATE |
time-micros |
TIME |
duration |
INTERVAL |
decimal |
NUMERIC o BIGNUMERIC |
Tipos de búfer de protocolo
| Tipo de búfer de protocolo | Tipo de datos de BigQuery |
double |
FLOAT64, NUMERIC o
BIGNUMERIC |
float |
FLOAT64, NUMERIC o
BIGNUMERIC |
int32 |
INTEGER, NUMERIC,
BIGNUMERIC o DATE |
int64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME o TIMESTAMP |
uint32 |
INTEGER, NUMERIC,
BIGNUMERIC o DATE |
uint64 |
NUMERIC o BIGNUMERIC |
sint32 |
INTEGER, NUMERIC o
BIGNUMERIC |
sint64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME o TIMESTAMP |
fixed32 |
INTEGER, NUMERIC,
BIGNUMERIC o DATE |
fixed64 |
NUMERIC o BIGNUMERIC |
sfixed32 |
INTEGER, NUMERIC,
BIGNUMERIC o DATE |
sfixed64 |
INTEGER, NUMERIC,
BIGNUMERIC, DATE,
DATETIME o TIMESTAMP |
bool |
BOOLEAN |
string |
STRING, JSON,
TIMESTAMP, DATETIME,
DATE, TIME,
NUMERIC o BIGNUMERIC |
bytes |
BYTES, NUMERIC o
BIGNUMERIC |
enum |
INTEGER |
message |
RECORD/STRUCT |
oneof |
No se puede asignar |
map<KeyType, ValueType> |
REPEATED RECORD<key KeyType, value
ValueType> |
enum |
INTEGER |
repeated/array of Type |
REPEATED Type |
Representación entera de fecha y hora
Cuando se asigna un número entero a uno de los tipos de fecha u hora, el número debe representar el valor correcto. A continuación, se muestra la asignación de los tipos de datos de BigQuery al número entero que los representa.
| Tipo de datos de BigQuery | Representación de números enteros |
DATE |
Número de días transcurridos desde la época de Unix, el 1 de enero de 1970. |
DATETIME |
Fecha y hora en microsegundos expresadas como hora civil mediante CivilTimeEncoder. |
TIME |
La hora en microsegundos expresada como hora civil mediante CivilTimeEncoder. |
TIMESTAMP |
Número de microsegundos transcurridos desde el registro de tiempo de Unix, el 1 de enero de 1970 a las 00:00:00 UTC. |
Captura de datos modificados de BigQuery
Las suscripciones de BigQuery admiten actualizaciones de captura de datos de cambios (CDC) cuando use_topic_schema o use_table_schema se definen como true en las propiedades de la suscripción. Para usar la función con use_topic_schema, define el esquema del tema con los siguientes campos:
_CHANGE_TYPE(obligatorio): campostringcon el valorUPSERToDELETE.Si un mensaje de Pub/Sub escrito en la tabla de BigQuery tiene el valor
_CHANGE_TYPEdefinido comoUPSERT, BigQuery actualiza la fila con la misma clave si existe o inserta una nueva fila si no existe.Si un mensaje de Pub/Sub escrito en la tabla de BigQuery tiene el valor
_CHANGE_TYPEdefinido comoDELETE, BigQuery elimina la fila de la tabla con la misma clave, si existe.
_CHANGE_SEQUENCE_NUMBER(opcional): un campostringconfigurado para asegurarse de que las actualizaciones y las eliminaciones realizadas en la tabla de BigQuery se procesen en orden. Los mensajes de la misma clave de fila deben contener un valor que aumente de forma monótona en_CHANGE_SEQUENCE_NUMBER. Los mensajes con números de secuencia inferiores al número de secuencia más alto procesado de una fila no tienen ningún efecto en la fila de la tabla de BigQuery. El número de secuencia debe seguir el formato_CHANGE_SEQUENCE_NUMBER.
Para usar la función con use_table_schema, incluye los campos anteriores en el mensaje JSON.
Para obtener información sobre los precios de CDC, consulta la página de precios de CDC.
Tablas de BigLake para Apache Iceberg en BigQuery
Las suscripciones de BigQuery se pueden usar con tablas de BigLake para Apache Iceberg en BigQuery sin necesidad de hacer cambios adicionales.
Las tablas de BigLake para Apache Iceberg en BigQuery proporcionan la base para crear lakehouses de formato abierto en Google Cloud. Estas tablas ofrecen la misma experiencia totalmente gestionada que las tablas de BigQuery estándar (integradas), pero almacenan los datos en los contenedores de almacenamiento propiedad del cliente mediante Parquet para que sean interoperables con los formatos de tabla abiertos de Iceberg.
Para obtener información sobre cómo crear tablas de BigLake para Apache Iceberg en BigQuery , consulta el artículo Crear una tabla de Iceberg.
Gestionar fallos de mensajes
Cuando no se puede escribir un mensaje de Pub/Sub en BigQuery, no se puede confirmar la recepción del mensaje. Para reenviar estos mensajes no entregados, configura un tema de mensajes fallidos en la suscripción de BigQuery. El mensaje de Pub/Sub
reenviado al tema de mensajes fallidos contiene un atributo
CloudPubSubDeadLetterSourceDeliveryErrorMessage que indica el motivo por el que el mensaje de Pub/Sub no se ha podido escribir en BigQuery.
Si Pub/Sub no puede escribir mensajes en BigQuery, Pub/Sub retrocede en el envío de mensajes de forma similar al comportamiento de retroceso de push. Sin embargo, si la suscripción tiene un tema de mensajes fallidos adjunto, Pub/Sub no retrocede en el envío cuando los errores de los mensajes se deben a errores de compatibilidad de esquemas.
Cuotas y límites
Hay limitaciones de cuota en el rendimiento de los suscriptores de BigQuery por región. Para obtener más información, consulta las cuotas y los límites de Pub/Sub.
Las suscripciones de BigQuery escriben datos mediante la API Storage Write de BigQuery. Para obtener información sobre las cuotas y los límites de la API Storage Write, consulta las solicitudes de la API Storage Write de BigQuery. Las suscripciones a BigQuery solo consumen la cuota de rendimiento de la API Storage Write. En este caso, puedes ignorar las demás consideraciones sobre la cuota de la API Storage Write.
Precios
Para consultar los precios de las suscripciones de BigQuery, visita la página de precios de Pub/Sub.
Siguientes pasos
Crea una suscripción, como una suscripción de BigQuery.
Solucionar problemas de una suscripción a BigQuery.
Consulta información sobre BigQuery.
Consulta los precios de Pub/Sub, incluidas las suscripciones de BigQuery.
Crea o modifica una suscripción con
gcloudcomandos de la CLI.Crea o modifica una suscripción con las APIs REST.