Create an ML model by using AutoML Natural Language
This quickstart shows you how to use AutoML Natural Language to create a custom machine learning model. You can create a model to classify documents, identify entities in documents, or analyze the prevailing emotional attitude in a document.
Before you begin
Set up your project
Before you can use AutoML Natural Language, you must create a Google Cloud project and enable AutoML Natural Language for that project.
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud AutoML and Storage APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud AutoML and Storage APIs.
Model objectives
AutoML Natural Language can train custom models for four distinct tasks, known as model objectives:
- Single label classification classifies documents by assigning a label to them
- Multi-label classification allows a document to be assigned multiple labels
- Entity extraction identifies entities in documents
- Sentiment analysis analyzes attitudes within documents
For this quickstart, you can choose which type of model to create by selecting one of three sample datasets hosted in a public Cloud Storage bucket:
To create a single-label classification model, use the "happy moments" dataset derived from the Kaggle open-source dataset HappyDB. The resulting model classifies happy moments into categories reflecting the causes of happiness.
The data is made available through a Creative Commons CCO: Public Domain license.
To create an entity extraction model, use a corpus of biomedical research abstracts that mention hundreds of diseases and concepts. The resulting model identifies these medical entities in other documents.
This dataset is in the public domain as a "United States Government Work" under the terms of the United States Copyright Act.
To create a sentiment analysis model, use the open dataset from FigureEight that analyzes Twitter mentions of the allergy medicine Claritin.
Create a dataset
Open the AutoML Natural Language UI and select Get started in the box corresponding to the type of model you plan to train.
Click the New Dataset button in the title bar.
Enter a name for the dataset and select the model objective that matches the sample dataset you chose.
Leave the Location set to Global.
In the Import text items section, choose Select a CSV file on Cloud Storage, and enter the path to the dataset you want to use into the text box.
- For the "happy moments" dataset:
cloud-ml-data/NL-classification/happiness.csv - For the biomedical research dataset:
cloud-ml-data/NL-entity/dataset.csv - For the Claritin sentiment dataset:
cloud-ml-data/NL-sentiment/crowdflower-twitter-claritin-80-10-10.csv
(The
gs://prefix is added automatically.) Alternatively, you can click Browse and navigate to the CSV file.If you choose the sentiment dataset, AutoML Natural Language asks for the maximum sentiment value. The maximum value for this dataset is 4.
- For the "happy moments" dataset:
Click Create dataset.
You're returned to the Datasets page; your dataset will show an in progress animation while your documents are being imported. This process should take approximately 10 minutes per 1000 documents, but may take more or less time.
After the dataset is successfully created, you will receive a message at the email address associated with your project.
Train your model
After your training data has been successfully imported, select the dataset from the dataset listing page to see the details about the dataset. The name of the selected dataset appears in the title bar, and the page lists the individual documents in the dataset along with their labels. The navigation bar along the left summarizes the number of labeled and unlabeled documents and enables you to filter the document list by label.
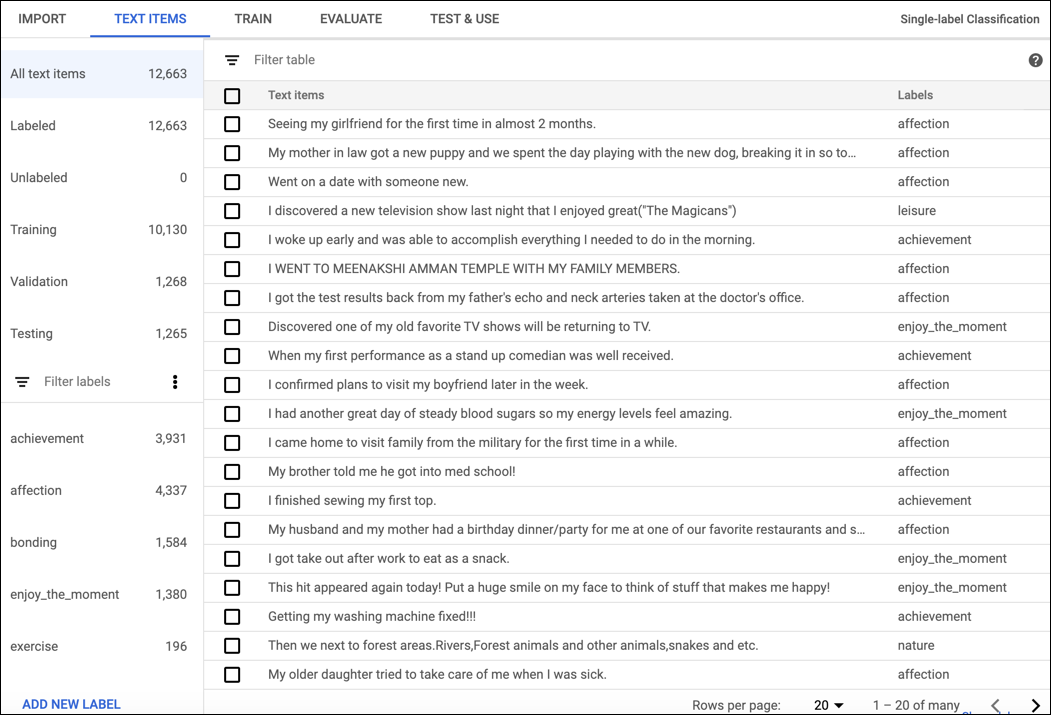
When you are done reviewing the dataset, click the Train tab just below the title bar.
Click Start Training.
Enter a name for the new model and check the Deploy model after training finishes check box.
Click Start Training.
Training a model can take several hours to complete. After the model is successfully trained, you will receive a message at the email address associated with your project.
After training, the bottom of the Train page shows high-level metrics for the model, such as precision and recall. To see more details, click the Evaluate tab.
Use the custom model
After your model has been successfully trained, you can use it to analyze other documents. Click the Test & Use tab just below the title bar. Enter text in the Input text box or the URL of a PDF or TIFF file in a Cloud Storage bucket, then click Predict. AutoML Natural Language analyzes the text using your model and displays the annotations.
Clean up
To avoid incurring charges to your Google Cloud account for the resources used on this page, follow these steps.
To avoid unnecessary Google Cloud Platform charges, use the Google Cloud console to delete your project if you do not need it.