AutoML Natural Language を使用して ML モデルを作成する
このクイックスタートでは、AutoML Natural Language を使用してカスタムの機械学習モデルを作成する方法を説明します。モデルを作成して、ドキュメントの分類、ドキュメント内のエンティティの識別、ドキュメント内の感情的な傾向の分析ができます。
始める前に
プロジェクトを設定する
AutoML Natural Language を使用する前に、Google Cloud プロジェクトを作成し、そのプロジェクトで AutoML Natural Language を有効にする必要があります。
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
-
Cloud AutoML and Storage API を有効にします。
-
Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
-
Cloud AutoML and Storage API を有効にします。
モデルの目標
AutoML Natural Language では、「モデルの目標」と呼ばれる 4 つの別々のタスク向けに、カスタムモデルをトレーニングできます。
- シングルラベル分類では、ドキュメントに 1 つのラベルを割り当てて分類します。
- マルチラベル分類では、1 つのドキュメントに複数のラベルを割り当てることができます
- エンティティ抽出では、ドキュメント内のエンティティを識別します。
- 感情分析では、ドキュメント内の感情的な傾向を分析します。
このクイックスタートでは、一般公開の Cloud Storage バケットでホストされている 3 つのサンプル データセットのいずれかから選択することで、作成するモデルのタイプを選択できます。
シングルラベル分類モデルを作成するには、Kaggle オープンソース データセット HappyDB から派生した「happy moments」データセットを使用します。結果として得られるモデルにより、さまざまな幸せな瞬間が、幸せの原因に対応するカテゴリに分類されます。
このデータは、クリエイティブ・コモンズの CCO: Public Domain ライセンスで入手できます。
エンティティ抽出モデルを作成するには、数百の疾患とコンセプトを言及する生物医学研究の要約のコーパスを使用します。結果として得られるモデルにより、他のドキュメントの医療エンティティが識別されます。
このデータセットは、米国著作権法の条項に基づく「米国政府業務」としてパブリック ドメインに存在します。
感情分析モデルを作成するには、アレルギー薬クラリチンに関する Twitter のツイートを分析している FigureEight のオープン データセットを使用します。
データセットを作成する
AutoML Natural Language UI を開き、トレーニングするモデルのタイプに対応するボックスの [開始] を選択します。
タイトルバーの [新しいデータセット] ボタンをクリックします。
データセットの名前を入力し、選択したサンプル データセットに一致するモデル目標を選択します。
[ロケーション] を [グローバル] に設定します。
[テキスト アイテムをインポート] セクションで、[Cloud Storage で CSV ファイルを選択] を選択し、テキスト ボックスに使用するデータセットのパスを入力します。
- 「happy moments」データセットの場合:
cloud-ml-data/NL-classification/happiness.csv - 生物医学研究データセットの場合:
cloud-ml-data/NL-entity/dataset.csv - クラリチン感情データセットの場合:
cloud-ml-data/NL-sentiment/crowdflower-twitter-claritin-80-10-10.csv
(
gs://接頭辞が自動的に追加されます)あるいは、[参照] をクリックして、CSV ファイルに移動することもできます。感情データセットを選択した場合、AutoML Natural Language は最大感情値を訊いてきます。このデータセットの最大値は 4 です。
- 「happy moments」データセットの場合:
[データセットを作成] をクリックします。
[データセット] ページに戻ります。ドキュメントのインポート中は、データセットに進行中アニメーションが表示されます。このプロセスにかかる時間はドキュメント 1,000 個あたり約 10 分ですが、それより長い場合も短い場合もあります。
データセットが正常に作成されると、プロジェクトに関連付けられたメールアドレスにメッセージが届きます。
モデルのトレーニング
トレーニング データが正常にインポートされたら、作成したデータセットをデータセットの一覧ページから選択して、データセットの詳細を確認します。選択したデータセットの名前がタイトルバーに表示され、データセット内の個々のドキュメントがラベルと一緒にページに一覧表示されます。左側にあるナビゲーション バーには、ラベル付きドキュメントとラベルなしドキュメントの数が要約され、項目の一覧をラベル別にフィルタリングできます。
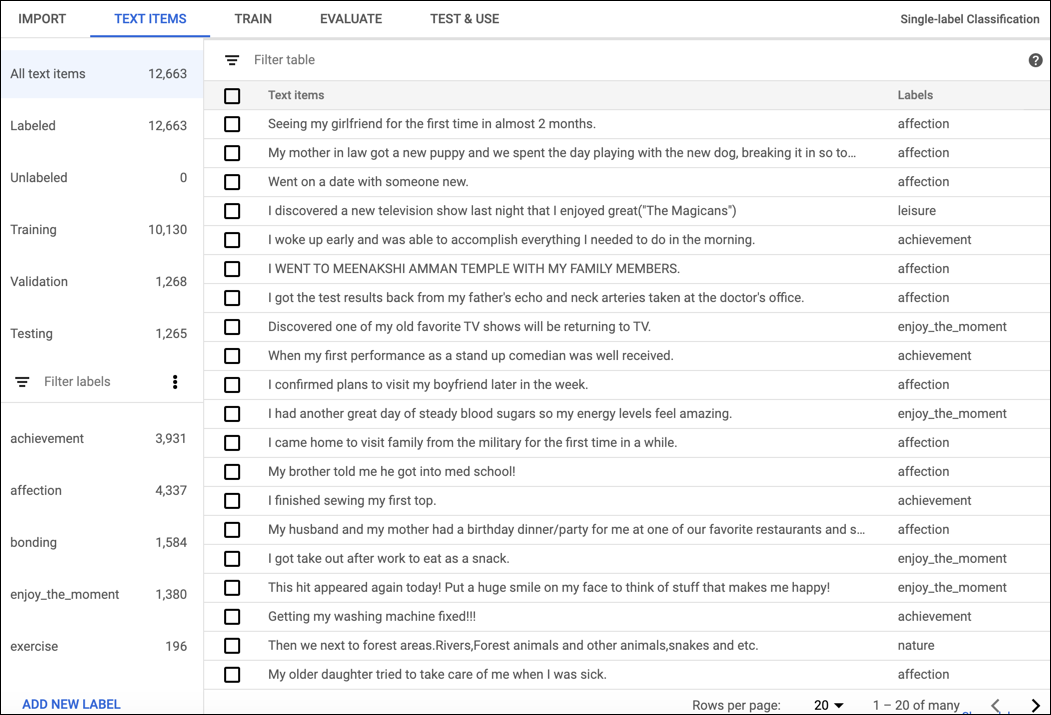
データセットの確認を終えたら、タイトルバーのすぐ下にある [トレーニング] タブをクリックします。
[トレーニングを開始] をクリックします。
新しいモデルの名前を入力し、[トレーニング終了後にモデルをデプロイ] チェックボックスをオンにします。
[トレーニングを開始] をクリックします。
モデルのトレーニングが完了するまで数時間かかることがあります。モデルのトレーニングが正常に終了したら、プロジェクトに関連付けられたメールアドレスにメッセージが届きます。
トレーニング後、[トレーニング] ページの下部にモデルの大まかな指標(適合率や再現率など)が表示されます。詳細を表示するには、[評価] タブをクリックします。
カスタムモデルの使用
モデルのトレーニングが正常に終了したら、そのモデルをもとに、他のドキュメントを分析できます。タイトルバーのすぐ下にある [テストと使用] タブをクリックします。入力テキスト ボックスにテキストを入力するか、Cloud Storage バケット内の PDF または TIFF ファイルの URL を入力して、[予測] をクリックします。AutoML Natural Language がモデルを使用してテキストを分析し、アノテーションを表示します。
クリーンアップ
このページで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、次の操作を行います。
Google Cloud Platform で不必要な課金を避けるため、Google Cloud コンソールを使用して、不要なプロジェクトを削除します。