커스텀 모델을 학습하려면 AutoML Natural Language를 통해 유사한 문서에 라벨을 지정하는 방식으로 라벨을 지정해 분석할 문서 유형의 대표 샘플을 제공합니다. 학습 데이터의 품질은 생성하는 모델의 효율성에 상당한 영향을 주며, 나아가 모델에서 반환한 예측의 품질에도 영향을 줍니다.
학습 문서 수집 및 라벨링
첫 단계는 커스텀 모델에서 처리할 문서 범위가 반영된 다양한 학습 문서 세트를 수집하는 것입니다. 학습 문서의 준비 단계는 분류, 항목 추출 또는 감정 분석 중 어떤 모델을 학습할지에 따라 다릅니다.
항목 추출
항목 추출 모델을 학습하려면 AutoML Natural Language를 통해 식별할 항목 유형을 식별하는 라벨로 주석을 추가해 분석하려는 콘텐츠 유형의 대표 샘플을 제공합니다.
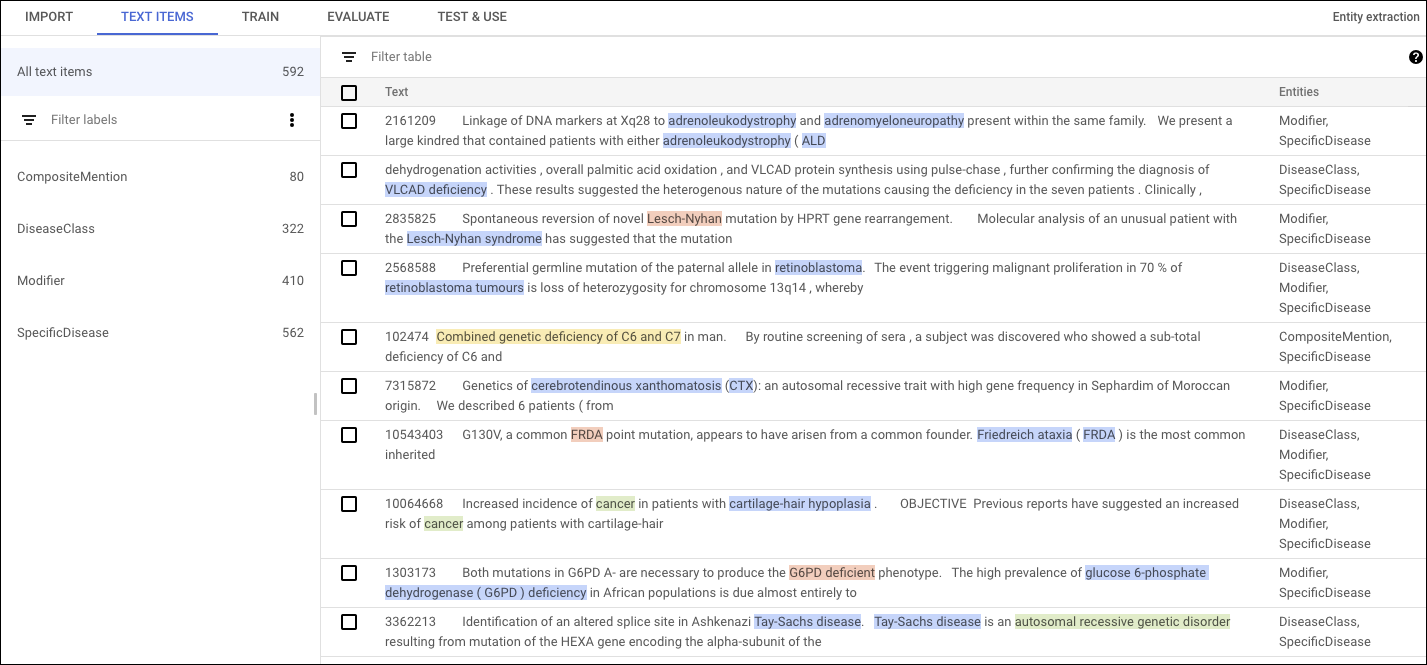
커스텀 모델 학습에 사용할 문서를 50개에서 100,000개까지 제공합니다. 1개에서 100개 사이의 고유 라벨을 사용하여 모델을 통해 추출할 항목에 주석을 추가할 수 있습니다. 각 주석에는 텍스트와 관련 라벨이 포함됩니다. 라벨 이름 길이는 2~30자이고, 주석에는 1~10개의 단어를 사용할 수 있습니다. 학습 데이터세트에서 각 라벨은 200회 이상 사용하는 것이 좋습니다.
인보이스나 계약서 같이 구조화된 문서 유형 또는 반구조화된 문서 유형에 주석을 추가하는 경우 AutoML Natural Language는 페이지 내 주석의 위치를 라벨의 적절성을 판단하는 요소로 고려할 수 있습니다. 예를 들어 계약 인수일과 계약 성사일이 있는 부동산 계약서의 경우 AutoML Natural Language는 주석의 공간 위치를 계산하여 두 날짜를 구분할 수 있습니다.
학습 문서 형식 지정
학습 데이터는 AutoML Natural Language에 샘플 문서가 포함된 JSONL 파일로 업로드합니다. 파일의 각 줄은 다음 2가지 양식 중 하나로 지정된 단일 학습 문서입니다.
- UTF-8로 인코딩된 10~10,000 바이트 길이의 전체 문서 콘텐츠
- 프로젝트와 관련된 Cloud Storage 버킷의 PDF 또는 TIFF 파일 URI
공간 위치에 대한 고려사항은 PDF 형식의 학습 문서에만 사용할 수 있습니다.
다음 세 가지 방법으로 텍스트 문서에 주석을 추가할 수 있습니다.
- 업로드 전 JSONL 파일에 바로 주석 추가
- 주석이 없는 문서 업로드 후 AutoML Natural Language UI에 주석 추가
- AI Platform Data Labeling Service를 사용하는 수동 라벨러를 통해 라벨링 요청
처음 2가지 옵션은 라벨이 지정된 JSONL 파일을 업로드하고 UI에서 수정하는 방식으로 결합할 수 있습니다.
AutoML Natural Language UI를 사용하면 PDF 파일에만 주석을 추가할 수 있습니다.
JSONL 문서
AutoML Natural Language는 JSONL 학습 파일을 만드는 데 유용하도록 일반 텍스트 파일을 올바르게 형식이 지정된 JSONL 파일로 변환하는 Python 스크립트를 제공합니다. 자세한 내용은 스크립트 내 댓글을 참조하세요.
JSONL 파일의 각 문서는 다음 형식 중 하나여야 합니다.
각 문서는 JSONL 파일의 한 줄을 나타냅니다. 아래의 예시에는 가독성을 위해 줄바꿈이 포함되어 있습니다. JSONL 파일에서는 이 줄바꿈을 삭제하세요. 자세한 내용은 http://jsonlines.org/를 참조하세요.
주석이 없는 문서의 경우:
{
"text_snippet":
{"content": string}
}
주석이 추가된 문서의 경우:
{
"annotations": [
{
"text_extraction": {
"text_segment": {
"end_offset": number, "start_offset": number
}
},
"display_name": string
},
{
"text_extraction": {
"text_segment": {
"end_offset": number, "start_offset": number
}
},
"display_name": string
},
...
],
"text_snippet":
{"content": string}
}
각 text_extraction 요소는 text_snippet.content 내의 주석을 식별하며, text_snippet.content의 시작과 텍스트의 시작(start_offset) 및 끝(end_offset) 사이의 문자 수를 지정하여 주석 처리된 텍스트의 위치를 나타냅니다. display_name은 항목의 라벨입니다.
start_offset과 end_offset` 모두 바이트 오프셋이 아닌 문자 오프셋입니다. end_offset의 문자는 텍스트 세그먼트에 포함되지 않습니다. 자세한 내용은 TextSegment를 참조하세요. text_extraction 요소는 선택사항이며, AutoML Natural Language UI를 사용하여 문서에 주석을 추가할 경우에는 생략해도 됩니다. 각 주석에는 최대 10개의 토큰(단어)이 포함될 수 있습니다. 이러한 토큰은 겹칠 수 없고, 주석의 start_offset은 동일 문서 내 주석의 start_offset 및 end_offset과 겹치면 안 됩니다
예를 들어 이 학습 문서 예시는 NCBI 자료의 초록에 언급된 특정 질병을 식별합니다.
{
"annotations": [
{
"text_extraction": {
"text_segment": {
"end_offset": 67,
"start_offset": 62
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 158,
"start_offset": 141
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 330,
"start_offset": 290
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 337,
"start_offset": 332
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 627,
"start_offset": 610
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 754,
"start_offset": 749
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 875,
"start_offset": 865
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 968,
"start_offset": 951
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1553,
"start_offset": 1548
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1652,
"start_offset": 1606
}
},
"display_name": "CompositeMention"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1833,
"start_offset": 1826
}
},
"display_name": "DiseaseClass"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1860,
"start_offset": 1843
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 1930,
"start_offset": 1913
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2129,
"start_offset": 2111
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2188,
"start_offset": 2160
}
},
"display_name": "SpecificDisease"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2260,
"start_offset": 2243
}
},
"display_name": "Modifier"
},
{
"text_extraction": {
"text_segment": {
"end_offset": 2356,
"start_offset": 2339
}
},
"display_name": "Modifier"
}
],
"text_snippet": {
"content": "10051005\tA common MSH2 mutation in English and North American HNPCC families:
origin, phenotypic expression, and sex specific differences in colorectal cancer .\tThe
frequency , origin , and phenotypic expression of a germline MSH2 gene mutation previously
identified in seven kindreds with hereditary non-polyposis cancer syndrome (HNPCC) was
investigated . The mutation ( A-- > T at nt943 + 3 ) disrupts the 3 splice site of exon 5
leading to the deletion of this exon from MSH2 mRNA and represents the only frequent MSH2
mutation so far reported . Although this mutation was initially detected in four of 33
colorectal cancer families analysed from eastern England , more extensive analysis has
reduced the frequency to four of 52 ( 8 % ) English HNPCC kindreds analysed . In contrast ,
the MSH2 mutation was identified in 10 of 20 ( 50 % ) separately identified colorectal
families from Newfoundland . To investigate the origin of this mutation in colorectal cancer
families from England ( n = 4 ) , Newfoundland ( n = 10 ) , and the United States ( n = 3 ) ,
haplotype analysis using microsatellite markers linked to MSH2 was performed . Within the
English and US families there was little evidence for a recent common origin of the MSH2
splice site mutation in most families . In contrast , a common haplotype was identified
at the two flanking markers ( CA5 and D2S288 ) in eight of the Newfoundland families .
These findings suggested a founder effect within Newfoundland similar to that reported by
others for two MLH1 mutations in Finnish HNPCC families . We calculated age related risks
of all , colorectal , endometrial , and ovarian cancers in nt943 + 3 A-- > T MSH2 mutation
carriers ( n = 76 ) for all patients and for men and women separately . For both sexes combined ,
the penetrances at age 60 years for all cancers and for colorectal cancer were 0 . 86 and 0 . 57 ,
respectively . The risk of colorectal cancer was significantly higher ( p < 0.01 ) in males
than females ( 0 . 63 v 0 . 30 and 0 . 84 v 0 . 44 at ages 50 and 60 years , respectively ) .
For females there was a high risk of endometrial cancer ( 0 . 5 at age 60 years ) and premenopausal
ovarian cancer ( 0 . 2 at 50 years ) . These intersex differences in colorectal cancer risks
have implications for screening programmes and for attempts to identify colorectal cancer
susceptibility modifiers .\n "
}
}
JSONL 파일에는 이 구조로 된 여러 학습 문서가 파일의 각 줄에 하나씩 포함될 수 있습니다.
PDF 또는 TIFF 문서
PDF 또는 TIFF 파일을 문서로 업로드하려면 JSONL document 요소 내에 파일 경로를 래핑하십시오.
각 문서는 JSONL 파일의 한 줄을 나타냅니다. 아래의 예시에는 가독성을 위해 줄바꿈이 포함되어 있습니다. JSONL 파일에서는 이 줄바꿈을 삭제하세요. 자세한 내용은 http://jsonlines.org/를 참조하세요.
{
"document": {
"input_config": {
"gcs_source": {
"input_uris": [ "gs://cloud-ml-data/NL-entity/sample.pdf" ]
}
}
}
}
input_uris 요소 값은 프로젝트와 연결된 Cloud Storage 버킷의 PDF 또는 TIFF 파일에 대한 경로입니다. PDF 또는 TIFF 파일의 최대 크기는 2MB입니다.
학습 문서 가져오기
문서를 나열하고 카테고리 라벨 또는 감정 값을 선택적으로 포함하는 CSV 파일을 사용하여 학습 데이터를 AutoML Natural Language로 가져올 수 있습니다. AutoML Natural Language는 나열된 문서에서 데이터세트를 만듭니다.
학습 데이터와 평가 데이터
AutoML Natural Language는 학습 문서를 학습 세트, 검증 세트, 테스트 세트라는 3가지 학습 모델 세트로 나눕니다.
AutoML Natural Language는 학습 세트를 사용하여 모델을 빌드합니다. 모델은 여러 알고리즘과 매개변수를 시도하면서 학습 데이터의 패턴을 찾습니다. 패턴이 발견되면 모델은 검증 세트를 사용하여 알고리즘과 패턴을 테스트합니다. AutoML Natural Language는 학습 단계에서 식별된 것 중에서 성능이 가장 우수한 알고리즘과 패턴을 선택합니다.
성능이 가장 우수한 알고리즘과 패턴이 식별되면 AutoML Natural Language는 이 요소를 테스트 세트에 적용하여 오류율, 품질, 정확성을 테스트합니다.
기본적으로 AutoML Natural Language은 학습 데이터를 무작위로 3가지 세트로 분할합니다.
- 문서 중 80%는 학습에 사용됩니다.
- 문서 중 10%는 검증에 사용됩니다(초매개변수 미세 조정 또는 학습 중지 시점 결정).
- 문서 중 10%는 학습에 사용하는 대신 테스트용으로 예약됩니다.
학습 데이터의 각 문서가 속하게 될 세트를 지정하려는 경우 다음 섹션의 설명대로 문서를 CSV 파일로 된 세트에 명시적으로 할당할 수 있습니다.
가져오기 CSV 파일 만들기
모든 학습 문서를 수집했으면 이 문서가 모두 나열된 CSV 파일을 만듭니다. CSV 파일의 이름에는 제한이 없지만 UTF-8로 인코딩되고 .csv 확장자로 끝나야 합니다. 프로젝트와 연결된 Cloud Storage 버킷에 저장해야합니다.
CSV 파일에는 학습 문서마다 행이 하나씩 있으며, 각 행에는 다음과 같은 열이 있습니다.
행에 지정된 콘텐츠의 집합. 이 열은 선택사항이며 다음 값 중 하나일 수 있습니다.
TRAIN- document을 사용하여 모델을 학습시킵니다.VALIDATION- document을 사용하여 학습 중에 모델이 반환하는 결과를 검증합니다.TEST- document을 사용하여 모델이 학습된 후 모델의 결과를 확인합니다.
이 열에 값을 포함하여 세트를 지정하려면 카테고리별로 데이터의 5% 이상을 식별하는 것이 좋습니다. 학습, 검증 또는 테스트에 사용되는 데이터가 5%에 미달하면 예기치 않은 결과가 나타나고 모델의 효율성이 떨어질 수 있습니다.
이 열에 값을 포함하지 않은 경우에는 각 행을 쉼표로 시작하여 비어 있는 첫 번째 열을 나타냅니다. AutoML Natural Language는 문서를 자동으로 3가지 세트로 구분하며, 데이터 중 약 80%를 학습에, 10%를 검증에, 10%를 테스트 용도로 사용합니다. 검증 및 테스트에는 최대 10,000개 쌍을 사용할 수 있습니다.
분류 대상 콘텐츠 이 열에는 문서의 Cloud Storage URI가 포함됩니다. Cloud Storage URI는 대소문자를 구분합니다.
분류 및 감정 분석의 경우 문서는 텍스트 파일, PDF 파일, TIFF 파일 또는 ZIP 파일일 수 있고, 엔티티 추출의 경우 JSONL 파일입니다.
분류 및 감정 분석의 경우 이 열의 값은 Cloud Storage URI가 아닌 인라인 텍스트로 인용될 수 있습니다.
분류 데이터세트의 경우 선택적으로 문서 분류 방법을 식별하는 라벨 목록을 쉼표로 구분하여 포함할 수 있습니다. 라벨은 문자로 시작해야 하며 문자, 숫자, 밑줄만 포함할 수 있습니다. 각 문서에 최대 20개의 라벨을 포함할 수 있습니다.
감정 분석 데이터세트의 경우 선택적으로 콘텐츠에 대한 감정 값을 나타내는 정수를 포함할 수 있습니다. 감정 값의 범위는 0(매우 부정적 감정)에서 최대 10(매우 긍정적 감정)까지입니다.
예를 들어 다중 라벨 분류 데이터세트의 CSV 파일에는 다음이 포함될 수 있습니다.
TRAIN, gs://my-project-lcm/training-data/file1.txt,Sports,Basketball VALIDATION, gs://my-project-lcm/training-data/ubuntu.zip,Computers,Software,Operating_Systems,Linux,Ubuntu TRAIN, gs://news/documents/file2.txt,Sports,Baseball TEST, "Miles Davis was an American jazz trumpeter, bandleader, and composer.",Arts_Entertainment,Music,Jazz TRAIN,gs://my-project-lcm/training-data/astros.txt,Sports,Baseball VALIDATION,gs://my-project-lcm/training-data/mariners.txt,Sports,Baseball TEST,gs://my-project-lcm/training-data/cubs.txt,Sports,Baseball
일반적인 .csv 오류
- 라벨에 유니코드 문자 사용. 예를 들어 일본어 문자는 지원되지 않습니다.
- 라벨에 공백 및 영숫자가 아닌 문자 사용
- 빈 줄
- 빈 열(줄에 쉼표가 연속으로 두 개 나오는 경우)
- 쉼표를 포함해 삽입된 텍스트에 따옴표 누락
- Cloud Storage 경로의 대소문자가 잘못되었습니다.
- 문서에 대한 액세스 제어 구성 오류. 서비스 계정에 읽기 이상의 액세스 권한이 있거나 파일이 공개 읽기가 가능한 상태여야 합니다.
- 문서가 아닌 파일 참조(PDF, PSD 파일 등). 마찬가지로 문서 파일이 아니지만 문서 파일처럼 확장자를 붙인 파일도 오류의 원인이 됩니다.
- 현재 프로젝트와 다른 버킷을 가리키는 문서의 URI. 프로젝트 버킷에 있는 파일만 액세스할 수 있습니다.
- CSV 형식이 아닌 파일
가져오기 ZIP 파일 만들기
분류 데이터세트의 경우 ZIP 파일을 사용하여 학습 문서를 가져올 수 있습니다. ZIP 파일에서 라벨 또는 감정 값마다 하나의 폴더를 만들고 각 문서를 해당 문서에 적용할 라벨 또는 값에 해당하는 폴더에 저장합니다. 예를 들어 비즈니스 서신을 분류하는 모델용 ZIP 파일의 구조는 다음과 같습니다.
correspondence.zip
transactional
letter1.pdf
letter2.pdf
letter5.pdf
persuasive
letter3.pdf
letter7.pdf
letter8.pdf
informational
letter6.pdf
instructional
letter4.pdf
letter9.pdf
AutoML Natural Language는 폴더 이름을 폴더의 문서에 라벨로 적용합니다. 감정 분석 데이터세트의 폴더 이름은 다음과 같이 감정 값입니다.
sentiment.zip
0
document4.txt
1
document3.txt
document1.txt
document5.txt
2
document2.txt
document6.txt
document8.txt
document9.txt
3
document7.txt
다음 단계
- 데이터를 가져와 데이터세트 만들기