データセットには分類するコンテンツ タイプの代表的なサンプルが含まれ、サンプルにはカスタムモデルで使用するカテゴリラベルが付けられています。このデータセットを入力値として利用し、モデルをトレーニングします。
データセットの主な作成手順は次のとおりです。
- データセット リソースを作成します。
- データセットにトレーニング データをインポートします。
- ドキュメントにラベルを付けるか、エンティティを識別します。
分類と感情分析では、多くの場合、ラベルがすでに割り当てられているデータ項目をインポートすることで、手順 2 と手順 3 が同時に行われます。
データセットの作成
カスタムモデルを作成するには、まず空のデータセットを作成します。作成したデータセットには、最終的にそのモデルのトレーニング データが格納されます。新しく作成したデータセットには、ドキュメントをインポートするまでデータは含まれません。
ウェブ UI
データセットを作成するには:
[AutoML Natural Language UI] を開き、トレーニングするモデルのタイプに対応するボックスの [開始] を選択します。
[データセット] ページに移り、現在のプロジェクトでこれまでに作成されたデータセットのステータスが表示されます。
別のプロジェクトのデータセットを追加するには、タイトルバーの右上にあるプルダウン リストからプロジェクトを選択します。
タイトルバーの [新しいデータセット] ボタンをクリックします。
データセットの名前を入力し、データセットを保存する地理的な [ロケーション] を指定します。
詳細については、ロケーションをご覧ください。
モデルの目標を選択します。ここでは、データセットを使用してトレーニングするモデルが行う分析のタイプを指定します。
- [単一ラベルの分類] では、分類されたドキュメントごとに 1 つのラベルを割り当てます。
- マルチラベル分類では、1 つのドキュメントに複数のラベルを割り当てることができます
- エンティティ抽出では、ドキュメント内のエンティティを識別します。
- 感情分析では、ドキュメント内の感情的な傾向を分析します。
[データセットを作成] をクリックします。
新しいデータセットの [インポート] ページが表示されます。 インポートの手順については、データセットへのデータのインポートをご覧ください。
コードサンプル
分類
REST
リクエストのデータを使用する前に、次のように置き換えます。
- project-id: プロジェクト ID
- location-id: リソースのロケーション。グローバル ロケーションの場合は
us-central1、EU の場合はeu。
HTTP メソッドと URL:
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets
JSON 本文のリクエスト:
{
"displayName": "test_dataset",
"textClassificationDatasetMetadata": {
"classificationType": "MULTICLASS"
}
}
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{
"name": "projects/434039606874/locations/us-central1/datasets/356587829854924648",
"displayName": "test_dataset",
"createTime": "2018-04-26T18:02:59.825060Z",
"textClassificationDatasetMetadata": {
"classificationType": "MULTICLASS"
}
}
Python
AutoML Natural Language のクライアント ライブラリをインストールして使用する方法については、AutoML Natural Language のクライアント ライブラリをご覧ください。 詳細については、AutoML Natural Language Python API のリファレンス ドキュメントをご覧ください。
AutoML Natural Language で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Java
AutoML Natural Language のクライアント ライブラリをインストールして使用する方法については、AutoML Natural Language のクライアント ライブラリをご覧ください。 詳細については、AutoML Natural Language Java API のリファレンス ドキュメントをご覧ください。
AutoML Natural Language で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Node.js
AutoML Natural Language のクライアント ライブラリをインストールして使用する方法については、AutoML Natural Language のクライアント ライブラリをご覧ください。 詳細については、AutoML Natural Language Node.js API のリファレンス ドキュメントをご覧ください。
AutoML Natural Language で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Go
AutoML Natural Language のクライアント ライブラリをインストールして使用する方法については、AutoML Natural Language のクライアント ライブラリをご覧ください。 詳細については、AutoML Natural Language Go API のリファレンス ドキュメントをご覧ください。
AutoML Natural Language で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
その他の言語
C#: クライアント ライブラリ ページの C# の設定手順を行ってから、.NET 用の AutoML Natural Language リファレンス ドキュメントをご覧ください。
PHP: クライアント ライブラリ ページの PHP の設定手順を行ってから、PHP 用の AutoML Natural Language リファレンス ドキュメントをご覧ください。
Ruby: クライアント ライブラリ ページの Ruby の設定手順を行ってから、Ruby 用の AutoML Natural Language のリファレンス ドキュメントをご覧ください。
エンティティの抽出
REST
リクエストのデータを使用する前に、次のように置き換えます。
- project-id: プロジェクト ID
- location-id: リソースのロケーション。グローバル ロケーションの場合は
us-central1、EU の場合はeu。
HTTP メソッドと URL:
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets
JSON 本文のリクエスト:
{
"displayName": "test_dataset",
"textExtractionDatasetMetadata": {
}
}
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{
name: "projects/000000000000/locations/us-central1/datasets/TEN5582774688079151104"
display_name: "test_dataset"
create_time {
seconds: 1539886451
nanos: 757650000
}
text_extraction_dataset_metadata {
}
}
Python
AutoML Natural Language のクライアント ライブラリをインストールして使用する方法については、AutoML Natural Language のクライアント ライブラリをご覧ください。 詳細については、AutoML Natural Language Python API のリファレンス ドキュメントをご覧ください。
AutoML Natural Language で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Java
AutoML Natural Language のクライアント ライブラリをインストールして使用する方法については、AutoML Natural Language のクライアント ライブラリをご覧ください。 詳細については、AutoML Natural Language Java API のリファレンス ドキュメントをご覧ください。
AutoML Natural Language で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Node.js
AutoML Natural Language のクライアント ライブラリをインストールして使用する方法については、AutoML Natural Language のクライアント ライブラリをご覧ください。 詳細については、AutoML Natural Language Node.js API のリファレンス ドキュメントをご覧ください。
AutoML Natural Language で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Go
AutoML Natural Language のクライアント ライブラリをインストールして使用する方法については、AutoML Natural Language のクライアント ライブラリをご覧ください。 詳細については、AutoML Natural Language Go API のリファレンス ドキュメントをご覧ください。
AutoML Natural Language で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
その他の言語
C#: クライアント ライブラリ ページの C# の設定手順を行ってから、.NET 用の AutoML Natural Language リファレンス ドキュメントをご覧ください。
PHP: クライアント ライブラリ ページの PHP の設定手順を行ってから、PHP 用の AutoML Natural Language リファレンス ドキュメントをご覧ください。
Ruby: クライアント ライブラリ ページの Ruby の設定手順を行ってから、Ruby 用の AutoML Natural Language のリファレンス ドキュメントをご覧ください。
感情分析
REST
リクエストのデータを使用する前に、次のように置き換えます。
- project-id: プロジェクト ID
- location-id: リソースのロケーション。グローバル ロケーションの場合は
us-central1、EU の場合はeu。
HTTP メソッドと URL:
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets
JSON 本文のリクエスト:
{
"displayName": "test_dataset",
"textSentimentDatasetMetadata": {
"sentimentMax": 4
}
}
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{
name: "projects/000000000000/locations/us-central1/datasets/TST8962998974766436002"
display_name: "test_dataset_name"
create_time {
seconds: 1538855662
nanos: 51542000
}
text_sentiment_dataset_metadata {
sentiment_max: 7
}
}
Python
AutoML Natural Language のクライアント ライブラリをインストールして使用する方法については、AutoML Natural Language のクライアント ライブラリをご覧ください。 詳細については、AutoML Natural Language Python API のリファレンス ドキュメントをご覧ください。
AutoML Natural Language で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Java
AutoML Natural Language のクライアント ライブラリをインストールして使用する方法については、AutoML Natural Language のクライアント ライブラリをご覧ください。 詳細については、AutoML Natural Language Java API のリファレンス ドキュメントをご覧ください。
AutoML Natural Language で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Node.js
AutoML Natural Language のクライアント ライブラリをインストールして使用する方法については、AutoML Natural Language のクライアント ライブラリをご覧ください。 詳細については、AutoML Natural Language Node.js API のリファレンス ドキュメントをご覧ください。
AutoML Natural Language で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Go
AutoML Natural Language のクライアント ライブラリをインストールして使用する方法については、AutoML Natural Language のクライアント ライブラリをご覧ください。 詳細については、AutoML Natural Language Go API のリファレンス ドキュメントをご覧ください。
AutoML Natural Language で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
その他の言語
C#: クライアント ライブラリ ページの C# の設定手順を行ってから、.NET 用の AutoML Natural Language リファレンス ドキュメントをご覧ください。
PHP: クライアント ライブラリ ページの PHP の設定手順を行ってから、PHP 用の AutoML Natural Language リファレンス ドキュメントをご覧ください。
Ruby: クライアント ライブラリ ページの Ruby の設定手順を行ってから、Ruby 用の AutoML Natural Language のリファレンス ドキュメントをご覧ください。
データセットへのトレーニング データのインポート
データセットを作成すると、Cloud Storage バケットに保存されている CSV ファイルからドキュメントの URI とドキュメントのラベルをインポートできるようになります。データの準備とインポート用の CSV ファイルの作成の詳細については、トレーニング データの準備をご覧ください。
ドキュメントを空のデータセットにインポート、または既存のデータセットに追加でインポートできます。
ウェブ UI
ドキュメントをデータセットにインポートするには、次のようにします。
[データセット] ページでドキュメントをインポートするデータセットを選択します。
[インポート] タブで、トレーニング ドキュメントの場所を指定します。
次のことが可能です。
トレーニング ドキュメントと関連するカテゴリラベルを含む .csv ファイルをローカル PC または Cloud Storage からアップロードします。
ローカル PC からトレーニング ドキュメントを含む .txt、.pdf、.zip ファイルをアップロードする。
インポートするファイルとインポートしたドキュメント用の Cloud Storage のパスを選択します。
[インポート] をクリックします。
コードサンプル
REST
リクエストのデータを使用する前に、次のように置き換えます。
- project-id: プロジェクト ID
- location-id: リソースのロケーション。グローバル ロケーションの場合は
us-central1、EU の場合はeu。 - dataset-id: データセット ID
- bucket-name: Cloud Storage バケット
- csv-file-name: CSV トレーニング データファイル
HTTP メソッドと URL:
POST https://automl.googleapis.com/v1/projects/project-id/locations/location-id/datasets/dataset-id:importData
JSON 本文のリクエスト:
{
"inputConfig": {
"gcsSource": {
"inputUris": ["gs://bucket-name/csv-file-name.csv"]
}
}
}
リクエストを送信するには、次のいずれかのオプションを展開します。
出力は次のようになります。オペレーション ID を使用して、タスクのステータスを取得できます。例については、オペレーションのステータスの取得をご覧ください。
{
"name": "projects/434039606874/locations/us-central1/operations/1979469554520650937",
"metadata": {
"@type": "type.googleapis.com/google.cloud.automl.v1beta1.OperationMetadata",
"createTime": "2018-04-27T01:28:36.128120Z",
"updateTime": "2018-04-27T01:28:36.128150Z",
"cancellable": true
}
}
Python
AutoML Natural Language のクライアント ライブラリをインストールして使用する方法については、AutoML Natural Language のクライアント ライブラリをご覧ください。 詳細については、AutoML Natural Language Python API のリファレンス ドキュメントをご覧ください。
AutoML Natural Language で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Java
AutoML Natural Language のクライアント ライブラリをインストールして使用する方法については、AutoML Natural Language のクライアント ライブラリをご覧ください。 詳細については、AutoML Natural Language Java API のリファレンス ドキュメントをご覧ください。
AutoML Natural Language で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Node.js
AutoML Natural Language のクライアント ライブラリをインストールして使用する方法については、AutoML Natural Language のクライアント ライブラリをご覧ください。 詳細については、AutoML Natural Language Node.js API のリファレンス ドキュメントをご覧ください。
AutoML Natural Language で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
Go
AutoML Natural Language のクライアント ライブラリをインストールして使用する方法については、AutoML Natural Language のクライアント ライブラリをご覧ください。 詳細については、AutoML Natural Language Go API のリファレンス ドキュメントをご覧ください。
AutoML Natural Language で認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
その他の言語
C#: クライアント ライブラリ ページの C# の設定手順を行ってから、.NET 用の AutoML Natural Language リファレンス ドキュメントをご覧ください。
PHP: クライアント ライブラリ ページの PHP の設定手順を行ってから、PHP 用の AutoML Natural Language リファレンス ドキュメントをご覧ください。
Ruby: クライアント ライブラリ ページの Ruby の設定手順を行ってから、Ruby 用の AutoML Natural Language のリファレンス ドキュメントをご覧ください。
トレーニング ドキュメントのラベル付け
モデルのトレーニングで役立つように、AutoML Natural Language が類似のドキュメントにラベル付けを行うように、データセット内の各ドキュメントにラベルを付ける必要があります。トレーニング データの品質は作成するモデルの有効性を大きく左右し、ひいてはそのモデルから返される予測の品質にも大きく影響します。トレーニング中、AutoML Natural Language はラベルのないドキュメントを無視します。
トレーニング ドキュメントには、次の 3 つの方法でラベルを付けることができます。
- ラベルを .csv ファイルに含める(分類と感情分析のみ)
- AutoML Natural Language UI でドキュメントにラベルを付ける
- AI Platform Data Labeling Service を使用して人間のラベル付け担当者に依頼する
AutoML API にはラベル付けのためのメソッドは含まれていません。
.csv ファイルでドキュメントにラベルを付ける方法の詳細については、トレーニング データの準備をご覧ください。
分類と感情分析用のラベル付け
AutoML Natural Language UI でドキュメントにラベルを付けるには、データセットの一覧ページからデータセットを選択してデータセットの詳細を表示します。選択したデータセットの表示名がタイトルバーに表示され、データセット内の個々のドキュメントがラベルと一緒にページに一覧表示されます。左側にあるナビゲーション バーには、ラベル付きドキュメントとラベルなしドキュメントの数が表示され、項目の一覧をラベルや感情値でフィルタリングできます。

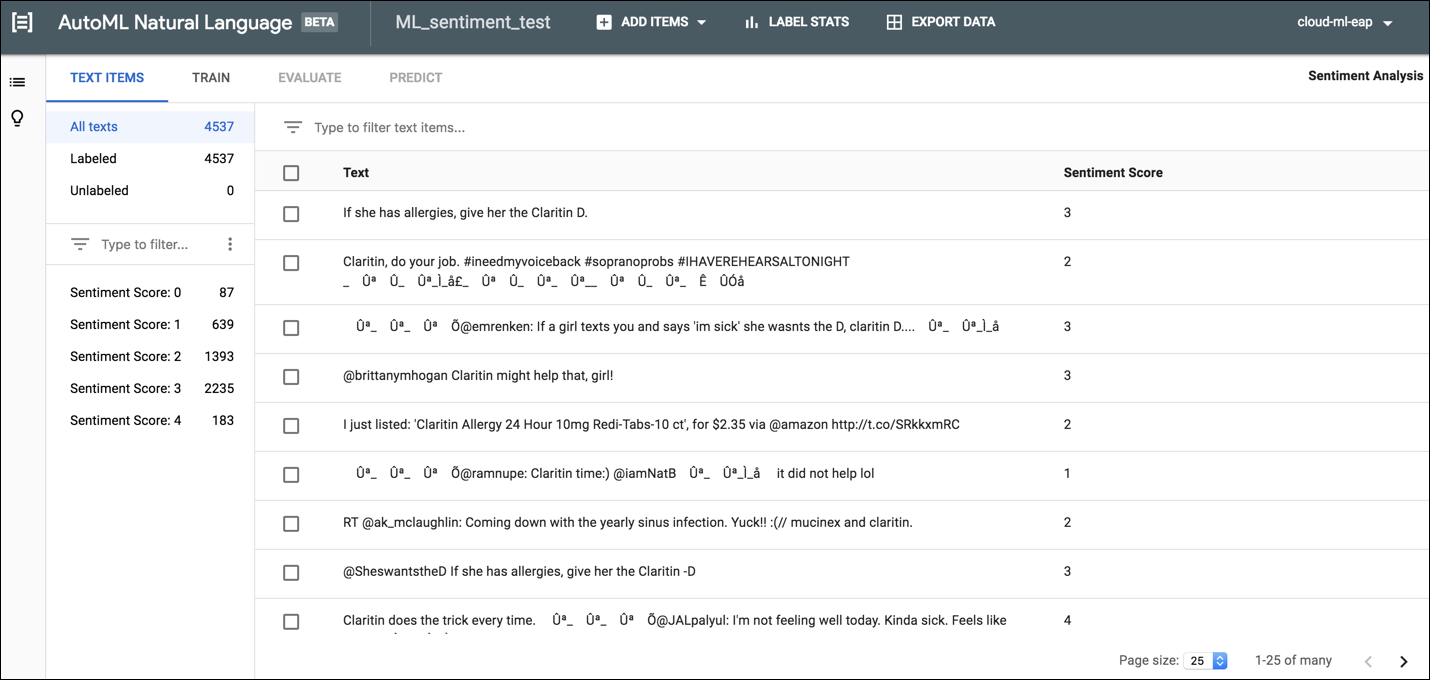
ラベルのないドキュメントへのラベルや感情値の割り当てや、ラベルの変更を行うには、更新するドキュメントおよび割り当てるラベルや感情値を選択します。ドキュメントのラベルを更新するには、次の 2 つの方法があります。
更新するドキュメントの横にあるチェックボックスをオンにし、ドキュメント一覧の上部に表示される [ラベル] プルダウン リストから適用するラベルを選択する。
更新する項目の行をクリックし、[Text detail] ページに表示されるリストから適用するラベルを選択する。
エンティティ抽出用のエンティティの識別
カスタムモデルをトレーニングする前に、データセット内のトレーニング ドキュメントにアノテーションを付ける必要があります。 インポート前にトレーニング ドキュメントにアノテーションを追加するか、AutoML Natural Language UI でアノテーションを追加できます。
AutoML Natural Language UI でアノテーションを追加するには、データセットの一覧ページからデータセットを選択してデータセットの詳細を表示します。選択したデータセットの表示名がタイトルバーに表示され、データセット内の個々のドキュメントが付けられているアノテーションと一緒にページに一覧表示されます。左側のナビゲーション バーには、ラベルと各ラベルの表示回数が表示されます。ドキュメントの一覧はラベルでフィルタリングすることもできます。
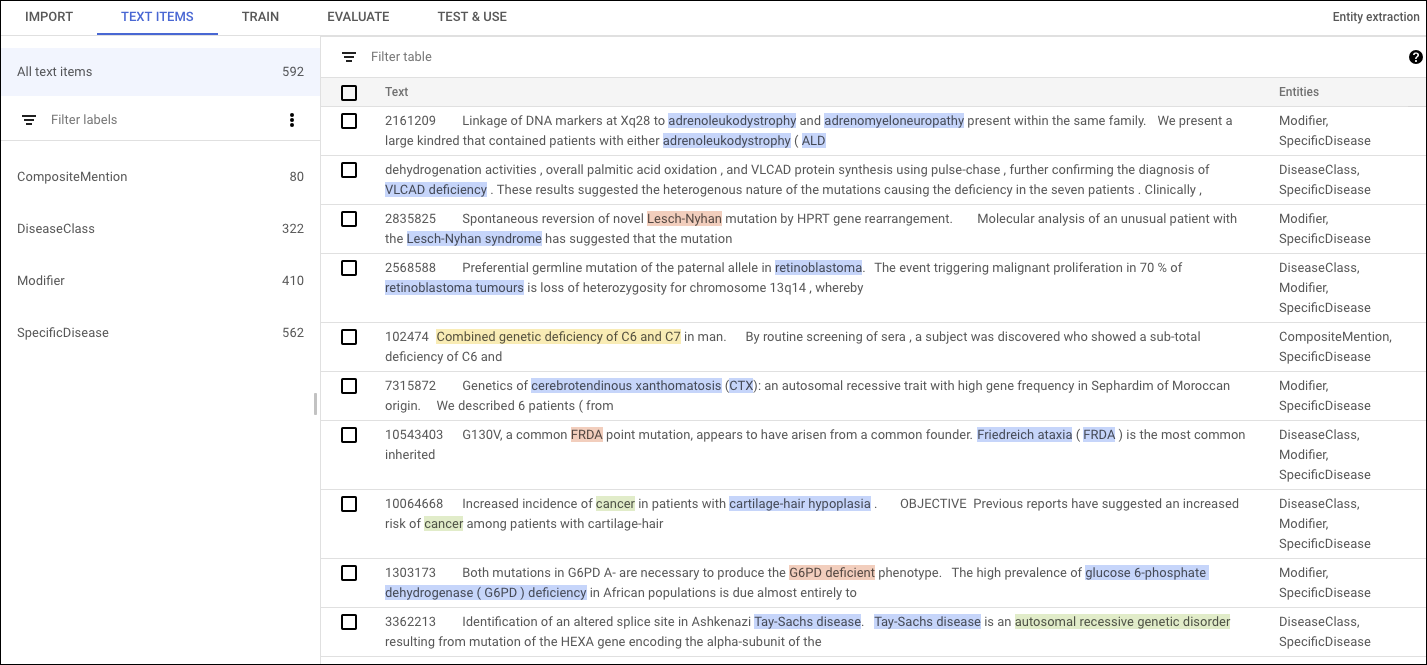
ドキュメント内のアノテーションを追加または削除するには、更新するドキュメントをダブルクリックします。[編集] ページに、選択したドキュメントの全テキストが表示され、以前の注釈すべてがハイライトされます。

PDF のトレーニング ドキュメントやレイアウト情報をインポートしたドキュメントの場合、[編集] ページは 2 つのタブ [Plain text] と [Structured text] で構成されます。[Plain text] タブには、トレーニング ドキュメントの内容が書式なしで表示されます。[Structured text] タブには、トレーニング ドキュメントの基本レイアウトが再作成されます。 ([Plain text] タブにも、元の PDF ファイルへのリンクがあります。)

新しいアノテーションを追加するには、エンティティを表すテキストをハイライト表示し、[Annotate] ダイアログ ボックスでラベルを選択して [保存] をクリックします。[Structured text] タブにアノテーションを追加すると、AutoML Natural Language はトレーニング中に考慮される要素としてページ上のアノテーションの位置を取得します。
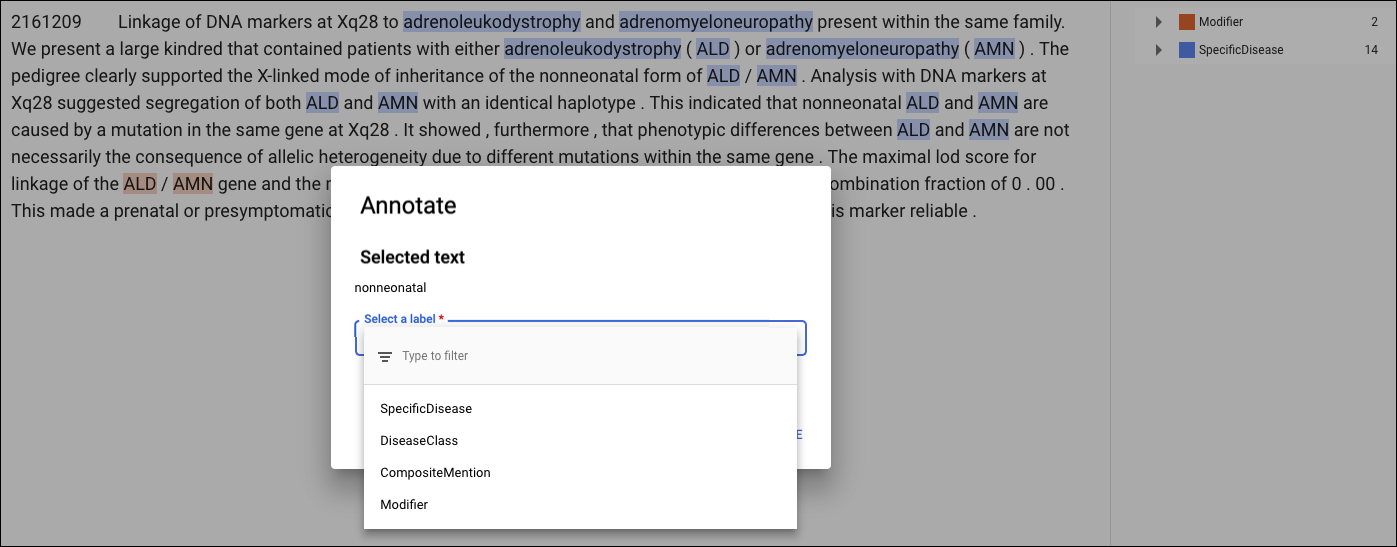
アノテーションを削除するには、右側のラベル一覧内でテキストを見つけ、横のゴミ箱アイコンをクリックします。