Buat model ML menggunakan AutoML Natural Language
Panduan memulai ini menunjukkan cara menggunakan AutoML Natural Language untuk membuat model machine learning kustom. Anda dapat membuat model untuk mengklasifikasikan dokumen, mengidentifikasi entitas dalam dokumen, atau menganalisis sikap emosional yang berlaku dalam dokumen.
Sebelum memulai
Menyiapkan project
Sebelum dapat menggunakan AutoML Natural Language, Anda harus membuat project Google Cloud dan mengaktifkan AutoML Natural Language untuk project tersebut.
- Login ke akun Google Cloud Anda. Jika Anda baru menggunakan Google Cloud, buat akun untuk mengevaluasi performa produk kami dalam skenario dunia nyata. Pelanggan baru juga mendapatkan kredit gratis senilai $300 untuk menjalankan, menguji, dan men-deploy workload.
-
Di konsol Google Cloud, pada halaman pemilih project, pilih atau buat project Google Cloud.
-
Pastikan penagihan telah diaktifkan untuk project Google Cloud Anda.
-
Enable the Cloud AutoML and Storage APIs.
-
Di konsol Google Cloud, pada halaman pemilih project, pilih atau buat project Google Cloud.
-
Pastikan penagihan telah diaktifkan untuk project Google Cloud Anda.
-
Enable the Cloud AutoML and Storage APIs.
Tujuan model
AutoML Natural Language dapat melatih model kustom untuk empat tugas berbeda, yang dikenal sebagai tujuan model:
- Klasifikasi label tunggal mengklasifikasikan dokumen dengan menetapkan label ke dokumen tersebut
- Klasifikasi multi-label memungkinkan dokumen diberi beberapa label
- Ekstraksi entity mengidentifikasi entity dalam dokumen
- Analisis sentimen menganalisis sikap dalam dokumen
Untuk panduan memulai ini, Anda dapat memilih jenis model yang akan dibuat dengan memilih salah satu dari tiga set data sampel yang dihosting di bucket Cloud Storage publik:
Untuk membuat model klasifikasi label tunggal, gunakan set data "momen bahagia" yang diperoleh dari set data open source Kaggle, HappyDB. Model yang dihasilkan mengklasifikasikan momen bahagia ke dalam kategori yang mencerminkan penyebab kebahagiaan.
Data tersedia melalui lisensi Creative Commons CCO: Domain Publik.
Untuk membuat model ekstraksi entity, gunakan korpus abstrak riset biomedis yang menyebutkan ratusan penyakit dan konsep. Model yang dihasilkan mengidentifikasi entitas medis ini dalam dokumen lain.
Set data ini berada dalam domain publik sebagai "United States Government Work" berdasarkan persyaratan Copyright Act Amerika Serikat.
Untuk membuat model analisis sentimen, gunakan set data terbuka dari FigureEight yang menganalisis penyebutan obat alergi Claritin di Twitter.
Membuat set data
Buka AutoML Natural Language UI dan pilih Get started di kotak yang sesuai dengan jenis model yang ingin Anda latih.
Klik tombol Set Data Baru pada kolom judul.
Masukkan nama untuk set data dan pilih tujuan model yang cocok dengan contoh set data yang Anda pilih.
Biarkan Location disetel ke Global.
Di bagian Import text items, pilih Select a CSV file on Cloud Storage, lalu masukkan jalur ke set data yang ingin Anda gunakan ke dalam kotak teks.
- Untuk set data "momen bahagia":
cloud-ml-data/NL-classification/happiness.csv - Untuk set data riset biomedis:
cloud-ml-data/NL-entity/dataset.csv - Untuk set data sentimen Claritin:
cloud-ml-data/NL-sentiment/crowdflower-twitter-claritin-80-10-10.csv
(Awalan
gs://ditambahkan secara otomatis.) Atau, Anda dapat mengklik Cari dan membuka file CSV.Jika Anda memilih set data sentimen, AutoML Natural Language akan meminta nilai sentimen maksimum. Nilai maksimum untuk set data ini adalah 4.
- Untuk set data "momen bahagia":
Klik Create dataset.
Anda akan kembali ke halaman Set data; set data Anda akan menampilkan animasi yang menunjukkan bahwa proses impor dokumen sedang berlangsung. Proses ini akan memerlukan waktu sekitar 10 menit per 1.000 dokumen, tetapi mungkin memerlukan waktu lebih atau kurang.
Setelah set data berhasil dibuat, Anda akan menerima pesan di alamat email yang terkait dengan project Anda.
Latih model Anda
Setelah data pelatihan Anda berhasil diimpor, pilih set data dari halaman listingan set data untuk melihat detail tentang set data. Nama set data yang dipilih akan muncul di kolom judul, dan halaman tersebut mencantumkan setiap dokumen dalam set data bersama dengan labelnya. Menu navigasi di sebelah kiri meringkas jumlah dokumen berlabel dan tidak berlabel dan memungkinkan Anda memfilter daftar dokumen berdasarkan label.
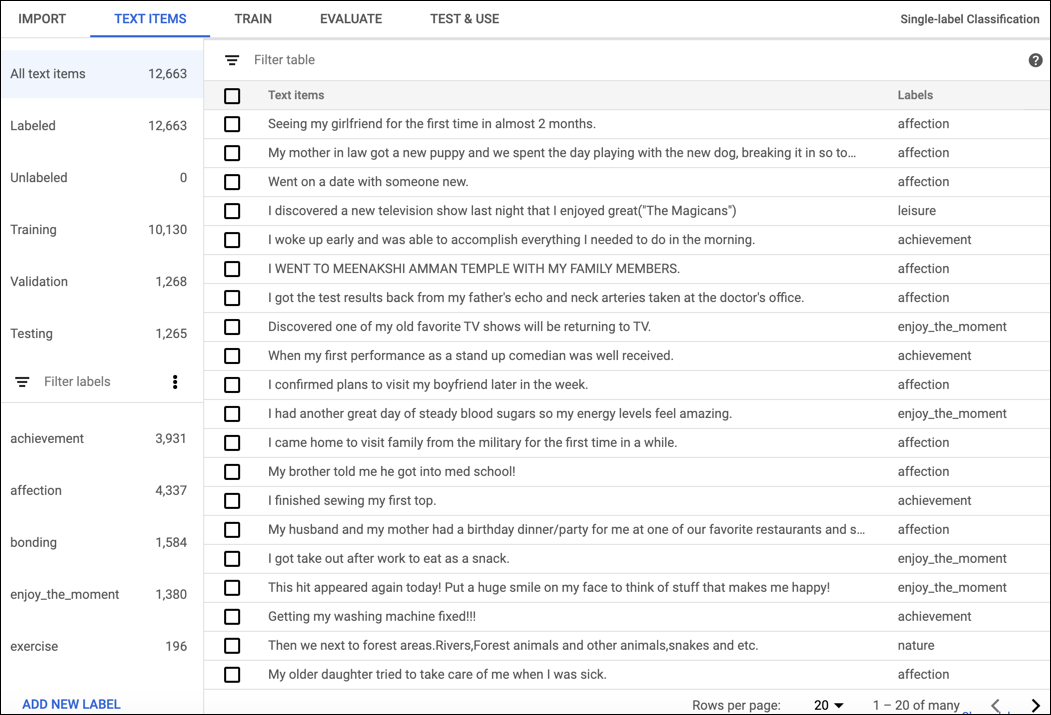
Setelah selesai meninjau set data, klik tab Latih tepat di bawah batang judul.
Klik Start Training.
Masukkan nama untuk model baru dan centang kotak Deploy model after training completed.
Klik Start Training.
Proses pelatihan model dapat memakan waktu beberapa jam untuk diselesaikan. Setelah model berhasil dilatih, Anda akan menerima pesan di alamat email yang terkait dengan project Anda.
Setelah pelatihan, bagian bawah halaman Train akan menampilkan metrik tingkat tinggi untuk model, seperti presisi dan perolehan. Untuk melihat detail selengkapnya, klik tab Evaluate.
Gunakan model kustom
Setelah model berhasil dilatih, Anda dapat menggunakannya untuk menganalisis dokumen lain. Klik tab Pengujian & Penggunaan tepat di bawah batang judul. Masukkan teks di kotak Input text atau URL file PDF atau TIFF di bucket Cloud Storage, lalu klik Predict. AutoML Natural Language menganalisis teks menggunakan model Anda dan menampilkan anotasi tersebut.
Pembersihan
Agar akun Google Cloud Anda tidak dikenakan biaya untuk resource yang digunakan pada halaman ini, ikuti langkah-langkah berikut.
Untuk menghindari tagihan Google Cloud Platform yang tidak diperlukan, gunakan konsol Google Cloud untuk menghapus project jika Anda tidak membutuhkannya.