Pengantar
Bayangkan bisnis Anda memiliki formulir kontak di situsnya. Setiap hari Anda mendapatkan banyak pesan dari formulir, banyak di antaranya dapat ditindaklanjuti dengan cara tertentu, tetapi semuanya menyatu dan mudah tertinggal dalam menanganinya karena karyawan yang berbeda menangani jenis pesan yang berbeda. Akan sangat baik jika sistem otomatis dapat mengategorikannya sehingga orang yang tepat melihat komentar yang tepat.
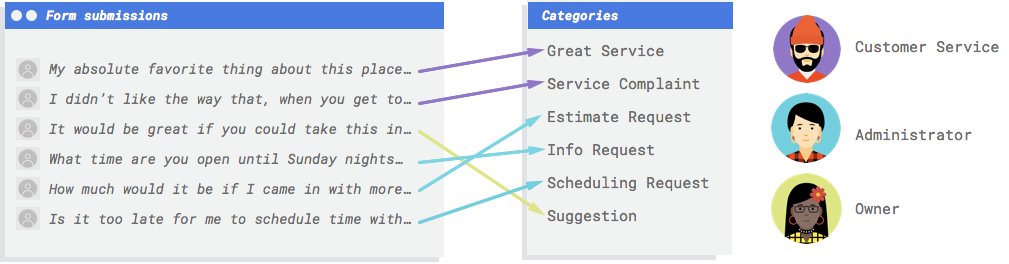
Anda memerlukan sistem untuk melihat komentar dan memutuskan apakah komentar tersebut mewakili keluhan, pujian untuk layanan sebelumnya, upaya untuk mempelajari bisnis Anda lebih lanjut, menjadwalkan janji temu, atau menjalin hubungan.
Mengapa Machine Learning (ML) merupakan alat yang tepat untuk masalah ini?
 Pemrograman klasik mengharuskan programmer menentukan petunjuk langkah demi langkah
yang harus diikuti oleh komputer. Namun, pendekatan ini tidak bisa dilakukan dengan cepat. Komentar pelanggan menggunakan kosakata dan struktur yang luas dan beragam — terlalu beragam untuk dipahami oleh sekumpulan aturan sederhana. Jika mencoba membuat filter manual, Anda akan
segera menemukan bahwa Anda tidak dapat mengategorikan sebagian besar
komentar pelanggan. Anda memerlukan sistem yang dapat
melakukan generalisasi terhadap berbagai jenis komentar.
Dalam skenario ketika urutan aturan tertentu terikat untuk diperluas secara eksponensial,
Anda memerlukan sistem yang dapat belajar dari contoh. Untungnya, sistem {i>machine learning<i} ditempatkan
dengan baik untuk memecahkan masalah ini.
Pemrograman klasik mengharuskan programmer menentukan petunjuk langkah demi langkah
yang harus diikuti oleh komputer. Namun, pendekatan ini tidak bisa dilakukan dengan cepat. Komentar pelanggan menggunakan kosakata dan struktur yang luas dan beragam — terlalu beragam untuk dipahami oleh sekumpulan aturan sederhana. Jika mencoba membuat filter manual, Anda akan
segera menemukan bahwa Anda tidak dapat mengategorikan sebagian besar
komentar pelanggan. Anda memerlukan sistem yang dapat
melakukan generalisasi terhadap berbagai jenis komentar.
Dalam skenario ketika urutan aturan tertentu terikat untuk diperluas secara eksponensial,
Anda memerlukan sistem yang dapat belajar dari contoh. Untungnya, sistem {i>machine learning<i} ditempatkan
dengan baik untuk memecahkan masalah ini.
Apakah Cloud Natural Language API atau AutoML Natural Language adalah alat yang tepat untuk saya?
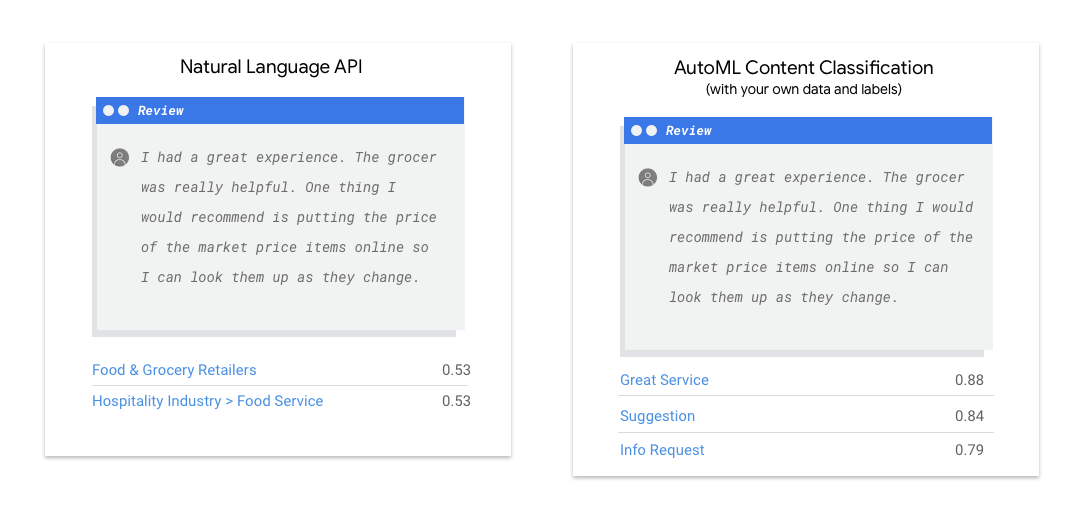
Natural Language API menemukan sintaksis, entity, dan sentimen dalam teks, serta mengklasifikasikan teks ke dalam kumpulan kategori yang telah ditentukan. Jika teks Anda berisi artikel berita atau konten lain yang ingin dikategorikan, atau jika Anda ingin menemukan sentimen contoh, Natural Language API patut dicoba. Namun, jika contoh teks Anda tidak cocok dengan skema klasifikasi berbasis sentimen atau berbasis topik vertikal yang tersedia di Natural Language API, dan Anda ingin menggunakan label sendiri, sebaiknya lakukan eksperimen dengan pengklasifikasi kustom untuk melihat apakah itu sesuai dengan kebutuhan Anda.
| Coba Natural Language API | Mulai menggunakan AutoML |
Apa yang tercakup dalam machine learning dalam AutoML Natural Language?
 Machine learning melibatkan penggunaan data untuk melatih algoritma guna mencapai hasil yang
diinginkan. Detail algoritma dan metode pelatihan berubah berdasarkan kasus penggunaan. Ada banyak subkategori machine learning yang berbeda, semuanya
memecahkan masalah yang berbeda dan bekerja dalam batasan yang berbeda. AutoML Natural Language memungkinkan Anda melakukan supervised learning, yang melibatkan pelatihan komputer untuk mengenali pola dari data berlabel. Dengan supervised learning, Anda dapat melatih model kustom
untuk mengenali konten yang penting bagi Anda dalam teks.
Machine learning melibatkan penggunaan data untuk melatih algoritma guna mencapai hasil yang
diinginkan. Detail algoritma dan metode pelatihan berubah berdasarkan kasus penggunaan. Ada banyak subkategori machine learning yang berbeda, semuanya
memecahkan masalah yang berbeda dan bekerja dalam batasan yang berbeda. AutoML Natural Language memungkinkan Anda melakukan supervised learning, yang melibatkan pelatihan komputer untuk mengenali pola dari data berlabel. Dengan supervised learning, Anda dapat melatih model kustom
untuk mengenali konten yang penting bagi Anda dalam teks.
Persiapan Data
Untuk melatih model kustom dengan AutoML Natural Language, Anda harus memberikan contoh berlabel untuk jenis item teks (input) yang ingin diklasifikasikan dan kategori atau label (jawaban) yang ingin diprediksi oleh sistem ML.
Menilai kasus penggunaan Anda

Saat menyusun set data, selalu mulailah dengan kasus penggunaan. Anda bisa mulai dengan pertanyaan-pertanyaan berikut:
- Hasil apa yang ingin Anda capai?
- Jenis kategori apa yang perlu Anda kenali untuk mencapai hasil ini?
- Mungkinkah manusia mengenali kategori-kategori tersebut? Meskipun AutoML Natural Language dapat menangani lebih banyak kategori daripada yang dapat diingat dan ditetapkan manusia pada satu waktu, jika manusia tidak dapat mengenali kategori tertentu, maka AutoML Natural Language juga akan mengalami kesulitan.
- Jenis contoh apa yang paling mencerminkan jenis dan rentang data yang akan diklasifikasikan sistem Anda?
Prinsip utama yang mendasari produk ML Google adalah machine learning yang berpusat pada manusia, sebuah pendekatan yang mengedepankan praktik responsible AI, termasuk keadilan. Tujuan keadilan dalam ML adalah untuk memahami dan mencegah perlakuan yang tidak adil atau merugikan terkait ras, pendapatan, orientasi seksual, agama, gender, dan karakteristik lain yang secara historis terkait dengan diskriminasi dan marginalisasi, ketika dan muncul dalam sistem algoritma atau pengambilan keputusan dengan bantuan algoritma. Anda dapat membaca selengkapnya di Panduan ML inklusif dan menemukan catatan "aware-aware" ✽ dalam panduan di bawah ini. Saat Anda mempelajari pedoman untuk mengumpulkan set data, sebaiknya pertimbangkan keadilan dalam machine learning jika relevan dengan kasus penggunaan Anda.
Mendapatkan data Anda
 Setelah menentukan data yang diperlukan, Anda harus menemukan cara untuk mendapatkannya. Anda dapat memulai dengan mempertimbangkan semua data yang dikumpulkan organisasi Anda.
Anda mungkin telah mengumpulkan data yang diperlukan untuk melatih model.
Jika tidak memiliki data yang diperlukan, Anda dapat memperolehnya secara manual atau melakukan outsourcing
ke penyedia pihak ketiga.
Setelah menentukan data yang diperlukan, Anda harus menemukan cara untuk mendapatkannya. Anda dapat memulai dengan mempertimbangkan semua data yang dikumpulkan organisasi Anda.
Anda mungkin telah mengumpulkan data yang diperlukan untuk melatih model.
Jika tidak memiliki data yang diperlukan, Anda dapat memperolehnya secara manual atau melakukan outsourcing
ke penyedia pihak ketiga.
Sertakan contoh berlabel secukupnya untuk setiap kategori
 Persyaratan minimum yang diperlukan oleh AutoML Natural Language untuk pelatihan adalah 10 contoh teks per kategori/label.
Kemungkinan keberhasilan pengenalan label bertambah seiring bertambahnya jumlah contoh berkualitas tinggi untuk setiap label. Secara umum, semakin banyak data berlabel yang dapat Anda bawa ke proses pelatihan, semakin baik model Anda. Jumlah sampel yang dibutuhkan juga bervariasi berdasarkan tingkat konsistensi dalam data yang ingin Anda prediksi dan pada tingkat akurasi target Anda. Anda dapat menggunakan lebih sedikit contoh untuk set data yang konsisten atau untuk mencapai akurasi 80%, bukan akurasi 97%.
Latih model menggunakan 50 contoh per label, lalu evaluasi hasilnya. Tambahkan lebih banyak contoh dan latih ulang sampai Anda memenuhi target akurasi, yang dapat memerlukan ratusan atau bahkan ribuan contoh per label.
Persyaratan minimum yang diperlukan oleh AutoML Natural Language untuk pelatihan adalah 10 contoh teks per kategori/label.
Kemungkinan keberhasilan pengenalan label bertambah seiring bertambahnya jumlah contoh berkualitas tinggi untuk setiap label. Secara umum, semakin banyak data berlabel yang dapat Anda bawa ke proses pelatihan, semakin baik model Anda. Jumlah sampel yang dibutuhkan juga bervariasi berdasarkan tingkat konsistensi dalam data yang ingin Anda prediksi dan pada tingkat akurasi target Anda. Anda dapat menggunakan lebih sedikit contoh untuk set data yang konsisten atau untuk mencapai akurasi 80%, bukan akurasi 97%.
Latih model menggunakan 50 contoh per label, lalu evaluasi hasilnya. Tambahkan lebih banyak contoh dan latih ulang sampai Anda memenuhi target akurasi, yang dapat memerlukan ratusan atau bahkan ribuan contoh per label.
Distribusikan contoh secara merata di seluruh kategori
Penting untuk mencatat jumlah contoh pelatihan yang kurang lebih serupa untuk setiap kategori. Meskipun Anda memiliki banyak data untuk satu label, sebaiknya setiap label memiliki distribusi yang sama. Untuk mengetahui alasannya, bayangkan bahwa 80% komentar pelanggan yang Anda gunakan untuk membuat model merupakan estimasi permintaan. Dengan distribusi label yang tidak seimbang seperti itu, model Anda sangat mungkin untuk mempelajari bahwa aman untuk selalu memberi tahu Anda bahwa komentar pelanggan adalah permintaan estimasi, daripada mencoba memprediksi label yang jauh kurang umum. Ini seperti menulis ujian pilihan ganda yang hampir semua jawaban yang benar adalah "C" - tidak lama lagi peserta ujian yang cerdas akan dapat menjawab "C" setiap saat tanpa melihat pertanyaannya.

Tidak selalu bisa untuk mendapatkan sumber contoh dengan jumlah yang kurang lebih sama untuk setiap label. Contoh berkualitas tinggi dan tidak bias untuk beberapa kategori mungkin lebih sulit untuk diambil. Dalam situasi tersebut, label dengan jumlah contoh terendah harus memiliki setidaknya 10% contoh sebagai label dengan jumlah contoh tertinggi. Jadi, jika label terbesar memiliki 10.000 contoh, label terkecil harus memiliki minimal 1.000 contoh.
Tangkap variasi di ruang masalah Anda
Untuk alasan yang serupa, cobalah agar data Anda menangkap variasi dan keragaman ruang masalah Anda. Jika Anda memberikan kumpulan contoh yang lebih luas, model akan lebih mampu menggeneralisasi ke data baru. Katakanlah Anda mencoba mengklasifikasikan artikel tentang elektronik konsumen ke dalam topik. Semakin banyak nama merek dan spesifikasi teknis yang Anda berikan, semakin mudah bagi model untuk mengetahui topik artikel – meskipun artikel tersebut adalah tentang merek yang tidak disertakan dalam set pelatihan sama sekali. Anda juga dapat mempertimbangkan untuk menyertakan label "none_of_the_above" untuk dokumen yang tidak sesuai dengan label yang Anda tetapkan guna meningkatkan performa model lebih lanjut.
Mencocokkan data dengan output yang diinginkan untuk model Anda

Temukan contoh teks yang mirip dengan teks yang ingin Anda buat prediksinya. Jika Anda mencoba mengklasifikasikan postingan media sosial tentang peniup kaca, Anda mungkin tidak akan mendapatkan performa bagus dari model yang dilatih di situs informasi peniup kaca, karena kosakata dan gayanya mungkin sangat berbeda. Idealnya, contoh pelatihan Anda adalah data dunia nyata yang diambil dari set data yang sama dengan yang Anda rencanakan sebagai model untuk diklasifikasikan.
Pertimbangkan bagaimana AutoML Natural Language menggunakan set data Anda dalam membuat model kustom
Set data Anda berisi set pelatihan, validasi, dan pengujian. Jika Anda tidak menentukan pemisahan seperti yang dijelaskan dalam bagian Menyiapkan Data), AutoML Natural Language akan otomatis menggunakan 80% dokumen konten Anda untuk pelatihan, 10% untuk memvalidasi, dan 10% untuk pengujian.
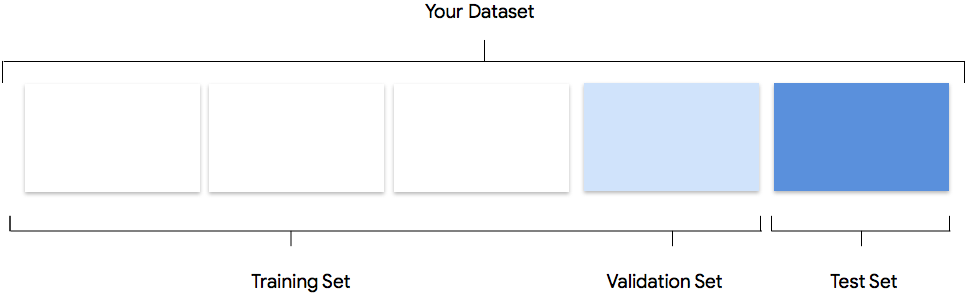
Set Pelatihan
 Sebagian besar data Anda harus berada dalam set pelatihan. Data ini adalah data yang "dilihat" oleh model Anda selama pelatihan: data ini digunakan untuk mempelajari parameter model, yaitu bobot koneksi antara node jaringan neural.
Sebagian besar data Anda harus berada dalam set pelatihan. Data ini adalah data yang "dilihat" oleh model Anda selama pelatihan: data ini digunakan untuk mempelajari parameter model, yaitu bobot koneksi antara node jaringan neural.
Set Validasi
 Set validasi, yang terkadang disebut juga dengan kumpulan "dev", juga digunakan selama
proses pelatihan. Setelah framework pembelajaran model menggabungkan data pelatihan selama setiap iterasi proses pelatihan, framework ini menggunakan performa model pada validasi yang ditetapkan untuk menyesuaikan hyperparameter model, yang merupakan variabel yang menentukan struktur model. Jika Anda mencoba menggunakan set pelatihan untuk menyesuaikan hyperparameter, kemungkinan model akan terlalu fokus pada data pelatihan Anda, dan mengalami kesulitan menggeneralisasi pada contoh yang tidak sama persis. Menggunakan set data yang agak baru untuk meningkatkan struktur model berarti model Anda akan digeneralisasi dengan lebih baik.
Set validasi, yang terkadang disebut juga dengan kumpulan "dev", juga digunakan selama
proses pelatihan. Setelah framework pembelajaran model menggabungkan data pelatihan selama setiap iterasi proses pelatihan, framework ini menggunakan performa model pada validasi yang ditetapkan untuk menyesuaikan hyperparameter model, yang merupakan variabel yang menentukan struktur model. Jika Anda mencoba menggunakan set pelatihan untuk menyesuaikan hyperparameter, kemungkinan model akan terlalu fokus pada data pelatihan Anda, dan mengalami kesulitan menggeneralisasi pada contoh yang tidak sama persis. Menggunakan set data yang agak baru untuk meningkatkan struktur model berarti model Anda akan digeneralisasi dengan lebih baik.
Set Pengujian
 Set pengujian tidak terlibat dalam proses pelatihan. Setelah model menyelesaikan pelatihannya, AutoML Natural Language menggunakan set pengujian sebagai tantangan untuk model Anda. Performa model Anda di set pengujian dimaksudkan untuk memberi Anda gambaran tentang performa model Anda pada data sebenarnya.
Set pengujian tidak terlibat dalam proses pelatihan. Setelah model menyelesaikan pelatihannya, AutoML Natural Language menggunakan set pengujian sebagai tantangan untuk model Anda. Performa model Anda di set pengujian dimaksudkan untuk memberi Anda gambaran tentang performa model Anda pada data sebenarnya.
Pembagian Manual
 Anda dapat membagi set data sendiri. Dengan membagi data secara manual, Anda dapat memiliki kontrol yang lebih besar atas proses tersebut atau jika ada contoh spesifik yang menurut Anda akan disertakan dalam bagian tertentu dari siklus proses pelatihan model.
Anda dapat membagi set data sendiri. Dengan membagi data secara manual, Anda dapat memiliki kontrol yang lebih besar atas proses tersebut atau jika ada contoh spesifik yang menurut Anda akan disertakan dalam bagian tertentu dari siklus proses pelatihan model.
Siapkan data Anda untuk diimpor

Setelah Anda memutuskan apakah pembagian data secara manual atau otomatis cocok untuk Anda, ada tiga cara untuk menambahkan data dalam AutoML Natural Language:
- Anda dapat mengimpor data dengan contoh teks yang diurutkan dan disimpan dalam folder yang sesuai dengan label Anda.
- Anda dapat mengimpor data dari komputer atau Cloud Storage dalam format CSV dengan label secara inline, seperti yang ditentukan dalam Menyiapkan data pelatihan Anda. Jika ingin membagi set data secara manual, Anda harus memilih opsi ini dan memformat CSV Anda.
- Jika data belum diberi label, Anda dapat mengupload contoh teks tidak berlabel dan menggunakan AutoML Natural Language UI untuk menerapkan label ke setiap contoh.
Evaluasi
Setelah model dilatih, Anda akan menerima ringkasan performa model tersebut. Untuk melihat analisis secara mendetail, klik evaluate atau evaluate.
Apa yang harus saya perhatikan sebelum mengevaluasi model saya?
 Proses debug model seharusnya lebih difokuskan pada proses debug data, dan bukan pada model itu sendiri. Jika model mulai bertindak secara tidak terduga saat Anda mengevaluasi performanya sebelum dan sesudah mengirim ke produksi, Anda harus kembali dan memeriksa data untuk melihat bagian mana yang dapat ditingkatkan.
Proses debug model seharusnya lebih difokuskan pada proses debug data, dan bukan pada model itu sendiri. Jika model mulai bertindak secara tidak terduga saat Anda mengevaluasi performanya sebelum dan sesudah mengirim ke produksi, Anda harus kembali dan memeriksa data untuk melihat bagian mana yang dapat ditingkatkan.
Jenis analisis apa yang dapat saya lakukan dalam AutoML Natural Language?
Di bagian evaluasi AutoML Natural Language, Anda dapat menilai performa model kustom menggunakan output model pada contoh pengujian dan metrik machine learning yang umum. Bagian ini membahas arti setiap konsep berikut:
- Output model
- Nilai minimum skor
- Positif benar, negatif benar, positif palsu, dan negatif palsu
- Presisi dan perolehan
- Kurva Presisi/Perolehan
- Presisi rata-rata
Bagaimana cara menafsirkan output model?
AutoML Natural Language mengambil contoh dari data pengujian Anda untuk memberikan tantangan baru bagi model Anda. Untuk setiap contoh, model menghasilkan serangkaian angka yang menyatakan seberapa kuat pengaitan setiap label dengan contoh tersebut. Jika angkanya tinggi, model memiliki keyakinan tinggi bahwa label harus diterapkan ke dokumen tersebut.

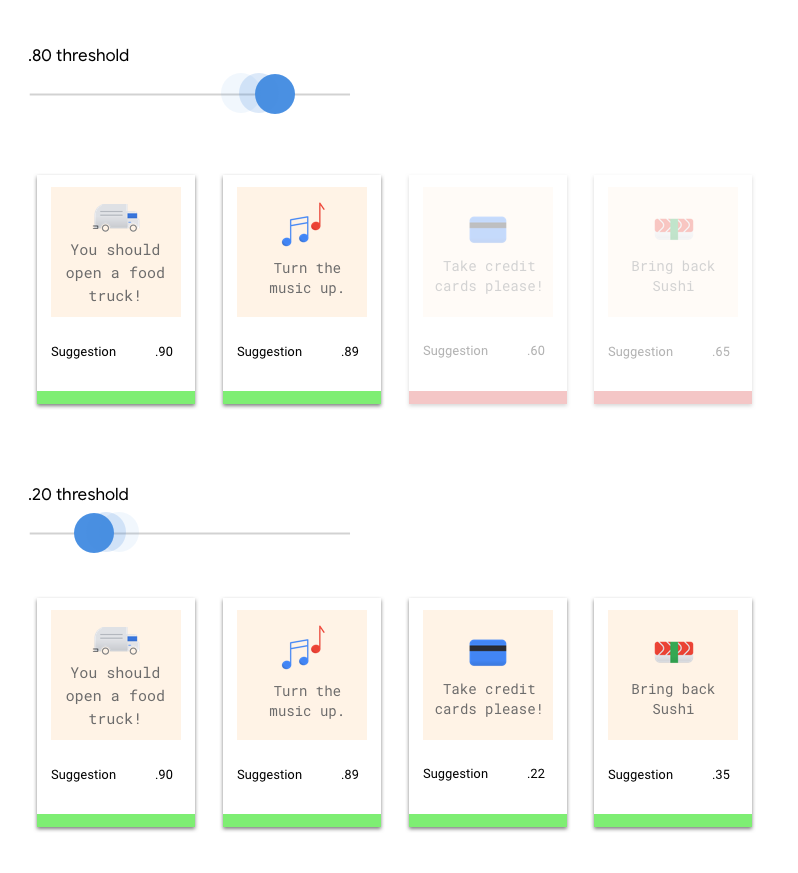
Berapa Nilai Minimum Skor?
Nilai minimum skor memungkinkan AutoML Natural Language mengonversi probabilitas menjadi nilai biner 'on'/'off'. Nilai minimum skor mengacu pada tingkat keyakinan yang harus dimiliki model untuk menetapkan kategori ke item pengujian. Penggeser nilai minimum skor di UI adalah alat visual untuk menguji dampak berbagai nilai minimum dalam set data Anda. Pada contoh di atas, jika nilai minimum skor ditetapkan ke 0,8 untuk semua kategori, "Layanan Hebat" dan "Saran" akan ditetapkan, tetapi tidak dengan "Permintaan Info". Jika nilai minimum skor rendah, model akan mengklasifikasikan lebih banyak item teks, tetapi berisiko salah mengklasifikasikan lebih banyak item teks dalam prosesnya. Jika nilai minimum skor tinggi, model akan mengklasifikasikan lebih sedikit item teks, tetapi risiko kesalahan klasifikasi item teks akan lebih rendah. Anda dapat menyesuaikan nilai minimum per kategori di UI untuk bereksperimen. Namun, saat menggunakan model dalam produksi, Anda harus menerapkan batas yang optimal bagi Anda.
Apa itu Positif Benar, Negatif Benar, Positif Palsu, Negatif Palsu?
Setelah menerapkan nilai minimum skor, prediksi yang dibuat oleh model Anda akan masuk ke dalam salah satu dari empat kategori berikut.
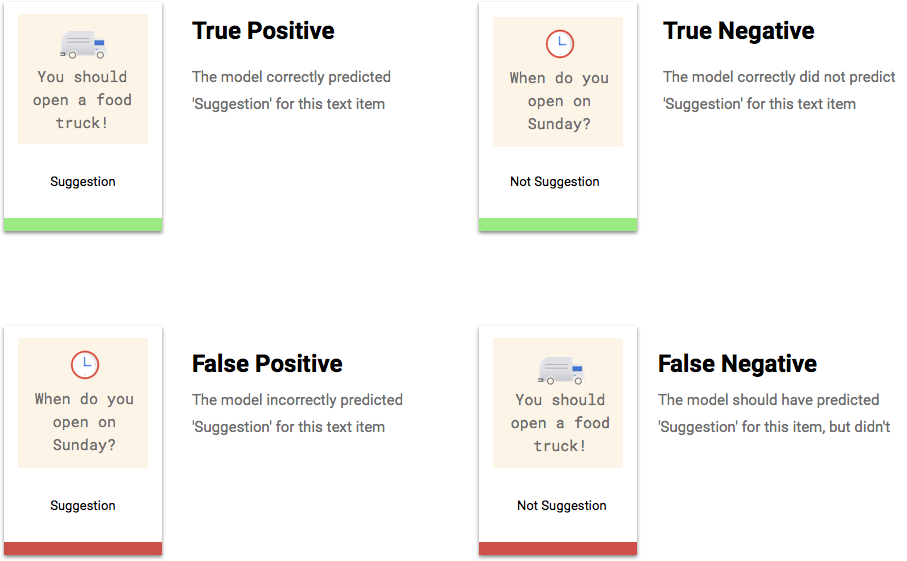
Anda dapat menggunakan kategori ini untuk menghitung presisi dan perolehan — metrik yang membantu mengukur efektivitas model Anda.
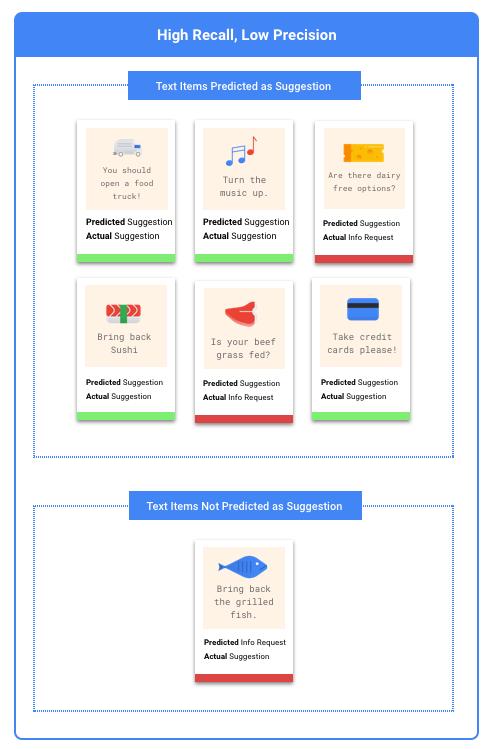
Apa yang dimaksud dengan presisi dan perolehan?
Presisi dan perolehan membantu kita memahami seberapa baik model kita dalam menangkap informasi, dan seberapa banyak informasi yang terlewatkan. Presisi menunjukkan, dari semua contoh pengujian yang diberi label, berapa banyak sebenarnya yang seharusnya dikategorikan dengan label tersebut. Recall memberi tahu kita, dari semua contoh pengujian yang seharusnya memiliki label, berapa banyak yang sebenarnya diberi label.

Apakah saya harus mengoptimalkan presisi atau perolehan?
Bergantung pada kasus penggunaan, sebaiknya optimalkan presisi atau perolehan. Mari kita pelajari cara mengambil keputusan ini dengan dua kasus penggunaan berikut.
Kasus penggunaan: Dokumen penting
Katakanlah Anda ingin membuat sistem yang dapat memprioritaskan dokumen yang mendesak dari yang tidak penting.

Positif palsu dalam kasus ini adalah dokumen yang tidak mendesak, tetapi ditandai sebagaimana mestinya. Pengguna dapat menolaknya sebagai tidak mendesak dan melanjutkan.

Negatif palsu dalam kasus ini adalah dokumen yang mendesak, tetapi sistem gagal menandainya seperti itu. Hal ini dapat menimbulkan masalah.
Dalam hal ini, sebaiknya optimalkan perolehan. Metrik ini mengukur berapa banyak prediksi yang dibuat, untuk semua prediksi yang dibuat. Model dengan daya tarik tinggi cenderung memberi label pada contoh yang sedikit relevan, yang berguna untuk kasus ketika kategori Anda memiliki sedikit data pelatihan.
Kasus penggunaan: Pemfilteran spam
Katakanlah Anda ingin membuat sistem yang otomatis memfilter pesan email yang merupakan spam dari pesan yang tidak.

Negatif palsu dalam kasus ini adalah email spam yang tidak tertangkap dan yang Anda lihat di kotak masuk Anda. Biasanya, hal ini hanya sedikit menjengkelkan.

Positif palsu dalam kasus ini adalah email yang salah ditandai sebagai spam dan dihapus dari kotak masuk Anda. Jika email itu penting, pengguna mungkin akan terdampak secara negatif.
Dalam hal ini, Anda perlu mengoptimalkan presisi. Metrik ini mengukur seberapa benar prediksi tersebut, untuk semua prediksi yang dibuat. Model presisi tinggi cenderung hanya melabeli contoh yang paling relevan, yang berguna untuk kasus ketika kategori Anda sama dalam data pelatihan.
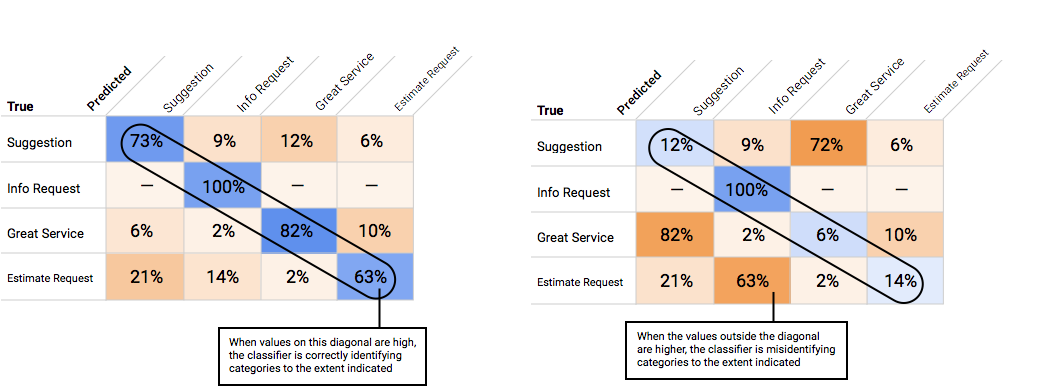
Bagaimana cara menggunakan Matriks Konfusi?
Kita dapat membandingkan performa model di setiap label menggunakan matriks konfusi. Dalam model ideal, semua nilai pada diagonal akan tinggi, dan semua nilai lainnya akan rendah. Hal ini menunjukkan bahwa kategori yang diinginkan telah diidentifikasi dengan benar. Jika ada nilai lain yang tinggi, kita akan tahu bagaimana model salah mengklasifikasikan item pengujian.
Bagaimana cara menafsirkan kurva Presisi-Perolehan?
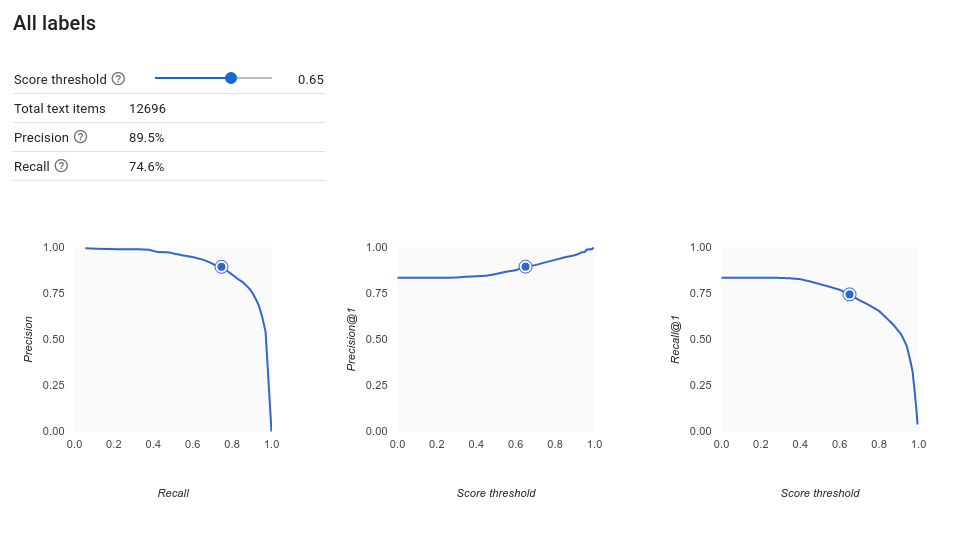
Alat nilai minimum skor memungkinkan Anda mempelajari bagaimana nilai minimum skor yang dipilih memengaruhi presisi dan perolehan. Saat menarik penggeser pada batang ambang batas skor, Anda dapat melihat di mana nilai minimum tersebut menempatkan Anda pada kurva keseimbangan presisi-recall, serta bagaimana nilai minimum tersebut memengaruhi presisi dan perolehan satu per satu (untuk model multiclass, pada grafik ini, presisi dan perolehan berarti satu-satunya label yang digunakan untuk menghitung presisi dan metrik perolehan adalah label dengan skor tertinggi dalam kumpulan label yang kita tampilkan). Hal ini dapat membantu Anda menemukan keseimbangan yang baik antara positif palsu dan negatif palsu.
Setelah memilih nilai minimum yang tampaknya dapat diterima untuk keseluruhan model, Anda dapat mengklik label individual dan melihat posisi nilai minimum tersebut pada kurva perolehan presisi per label. Dalam kasus tertentu, hal ini mungkin berarti Anda mendapatkan banyak prediksi yang salah untuk beberapa label, yang dapat membantu Anda memutuskan untuk memilih nilai minimum per class yang disesuaikan untuk label tersebut. Misalnya, katakanlah Anda melihat set data komentar pelanggan dan memperhatikan bahwa nilai minimum sebesar 0,5 memiliki presisi dan perolehan yang wajar untuk setiap jenis komentar kecuali "Saran", mungkin karena itu adalah kategori yang sangat umum. Untuk kategori itu, Anda melihat banyak positif palsu. Dalam hal ini, Anda mungkin memutuskan untuk menggunakan nilai minimum 0,8 hanya untuk "Saran" saat memanggil pengklasifikasi untuk prediksi.
Apa yang dimaksud dengan Presisi Rata-Rata?
Metrik yang berguna untuk akurasi model adalah area di bawah kurva presisi-perolehan. Kurva ini mengukur seberapa baik performa model Anda di semua nilai minimum skor. Dalam AutoML Natural Language, metrik ini disebut Average Precision. Semakin mendekati 1,0 skor ini, semakin baik performa model Anda pada set pengujian. Model yang menebak secara acak untuk setiap label akan mendapatkan presisi rata-rata sekitar 0,5.
Menguji model Anda
 AutoML Natural Language menggunakan 10% data Anda secara otomatis (atau, jika Anda memilih membagi data sendiri, berapa pun persentase yang Anda pilih untuk digunakan) untuk menguji model, dan halaman "Evaluate" akan memberi tahu Anda bagaimana performa model pada data pengujian tersebut. Namun, untuk berjaga-jaga jika Anda ingin memeriksa model, ada beberapa cara. Cara termudah adalah memasukkan contoh teks ke dalam kotak teks di halaman "Predict", dan melihat label yang dipilih model untuk contoh Anda. Semoga, ini sesuai dengan
ekspektasi Anda. Coba beberapa contoh dari setiap jenis komentar yang ingin Anda terima.
AutoML Natural Language menggunakan 10% data Anda secara otomatis (atau, jika Anda memilih membagi data sendiri, berapa pun persentase yang Anda pilih untuk digunakan) untuk menguji model, dan halaman "Evaluate" akan memberi tahu Anda bagaimana performa model pada data pengujian tersebut. Namun, untuk berjaga-jaga jika Anda ingin memeriksa model, ada beberapa cara. Cara termudah adalah memasukkan contoh teks ke dalam kotak teks di halaman "Predict", dan melihat label yang dipilih model untuk contoh Anda. Semoga, ini sesuai dengan
ekspektasi Anda. Coba beberapa contoh dari setiap jenis komentar yang ingin Anda terima.
Jika Anda ingin menggunakan model dalam pengujian otomatis Anda sendiri, halaman "Predict" akan memberi tahu Anda cara melakukan panggilan ke model secara terprogram.