Prueba Gemini 2.5 Flash Image, nuestro modelo de imagen de vanguardia, ahora disponible en Vertex AI
Vertex AI Platform
Innova más rápido con la IA preparada para empresas y mejorada por los modelos de Gemini
Vertex AI es una plataforma de desarrollo de IA unificada y completamente administrada para crear y usar IA generativa. Accede a Vertex AI Studio, Agent Builder y más de 200 modelos de base, y utilízalos.
Los clientes nuevos obtienen hasta $300 en créditos gratuitos para probar Vertex AI y otros productos de Google Cloud.
Funciones
Gemini, Los modelos multimodales más capaces de Google
Vertex AI ofrece acceso a los modelos de Gemini más recientes que ofrece Google. Gemini es capaz de comprender de forma virtual prácticamente cualquier entrada, combinar diferentes tipos de información y generar casi cualquier resultado. Envíale instrucciones a Gemini y pruébalo en Vertex AI Studio con texto, imágenes, video o código. Con el razonamiento avanzado y las capacidades de generación de vanguardia de Gemini, los desarrolladores pueden probar instrucciones de muestra para extraer texto de imágenes, convertir texto de imágenes a JSON y hasta generar respuestas sobre las imágenes subidas para compilar aplicaciones de IA de nueva generación.

Más de 200 modelos y herramientas de IA generativa
Elige entre la variedad más amplia de modelos, con opciones propias (Gemini, Imagen, Chirp, Veo), de terceros (la familia de modelos Claude de Anthropic) y abiertas (Gemma, Llama 3.2) en Model Garden. Usa extensiones para habilitar los modelos a fin de recuperar información en tiempo real y activar acciones. Personaliza los modelos según tu caso de uso con una variedad de opciones de ajuste para los modelos de texto, imagen o código de Google.
Los modelos de IA generativa y las herramientas completamente administradas facilitan la creación de prototipos, la personalización, la integración y la implementación en aplicaciones.
Plataforma de IA integrada y abierta
Los científicos de datos pueden avanzar más rápido con las herramientas de Vertex AI Platform para entrenar, ajustar e implementar modelos de AA.
Los notebooks de Vertex AI, incluida tu elección de Colab Enterprise o Workbench, se integran de forma nativa en BigQuery, lo que proporciona una sola plataforma en todas las cargas de trabajo de IA y datos.
Vertex AI Training y Prediction te ayudan a reducir el tiempo de entrenamiento y a implementar modelos en producción con facilidad mediante los frameworks de código abierto que elijas y la infraestructura de IA optimizada.
MLOps para IA predictiva y generativa
Vertex AI Platform proporciona herramientas de MLOps específicas para que los científicos de datos y los ingenieros de AA automaticen, estandaricen y administren proyectos de AA.
Las herramientas modulares te ayudan a colaborar con los equipos y a mejorar los modelos durante todo el ciclo de vida del desarrollo. Identifica el mejor modelo para un caso de uso con Vertex AI Evaluation, organiza flujos de trabajo con Vertex AI Pipelines, administra cualquier modelo con Model Registry, entregar, comparte y reutiliza atributos de AA con Feature Store, y supervisa los modelos para el sesgo de entrada y el desvío.
Agent Builder
Vertex AI Agent Builder permite a los desarrolladores compilar e implementar fácilmente experiencias de IA generativa listas para empresas. Proporciona la conveniencia de una consola para crear agentes sin código y capacidades potentes de base, organización y personalización. Con Vertex AI Agent Builder, los desarrolladores pueden crear rápidamente una variedad de agentes y aplicaciones de IA generativa que se basan en los datos de su organización.
Cómo funciona
Vertex AI proporciona varias opciones para el entrenamiento y la implementación de modelos:
- La IA generativa te brinda acceso a grandes modelos, incluido Gemini 2.5, para que puedas evaluarlos, ajustarlos e implementarlos, y usarlos en tus aplicaciones potenciadas por IA.
- Model Garden te permite descubrir, probar, personalizar e implementar Vertex AI, y seleccionar modelos y elementos de código abierto (OSS).
- El entrenamiento personalizado te brinda control total sobre el proceso de entrenamiento, incluido el uso de tu marco de trabajo de AA preferido, la escritura de tu propio código de entrenamiento y la elección de las opciones de ajuste de hiperparámetros.
Vertex AI proporciona varias opciones para el entrenamiento y la implementación de modelos:
- La IA generativa te brinda acceso a grandes modelos, incluido Gemini 2.5, para que puedas evaluarlos, ajustarlos e implementarlos, y usarlos en tus aplicaciones potenciadas por IA.
- Model Garden te permite descubrir, probar, personalizar e implementar Vertex AI, y seleccionar modelos y elementos de código abierto (OSS).
- El entrenamiento personalizado te brinda control total sobre el proceso de entrenamiento, incluido el uso de tu marco de trabajo de AA preferido, la escritura de tu propio código de entrenamiento y la elección de las opciones de ajuste de hiperparámetros.
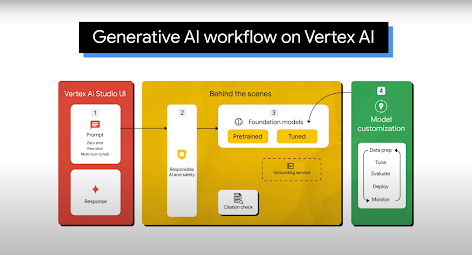
Usos comunes
Compila con Gemini
Accede a modelos de Gemini a través de la API de Gemini en Vertex AI de Google Cloud
- Python
- JavaScript
- Java
- Go
- Curl
Muestra de código
Accede a modelos de Gemini a través de la API de Gemini en Vertex AI de Google Cloud
- Python
- JavaScript
- Java
- Go
- Curl
IA generativa en aplicaciones
Obtén una introducción a la IA generativa en Vertex AI
Vertex AI Studio ofrece una herramienta de la consola de Google Cloud para crear prototipos de modelos de IA generativa y probarlos con rapidez. Aprende a usar Generative AI Studio para probar modelos mediante muestras de mensajes, diseñar y guardar mensajes, ajustar un modelo de base y realizar conversiones entre voz y texto.
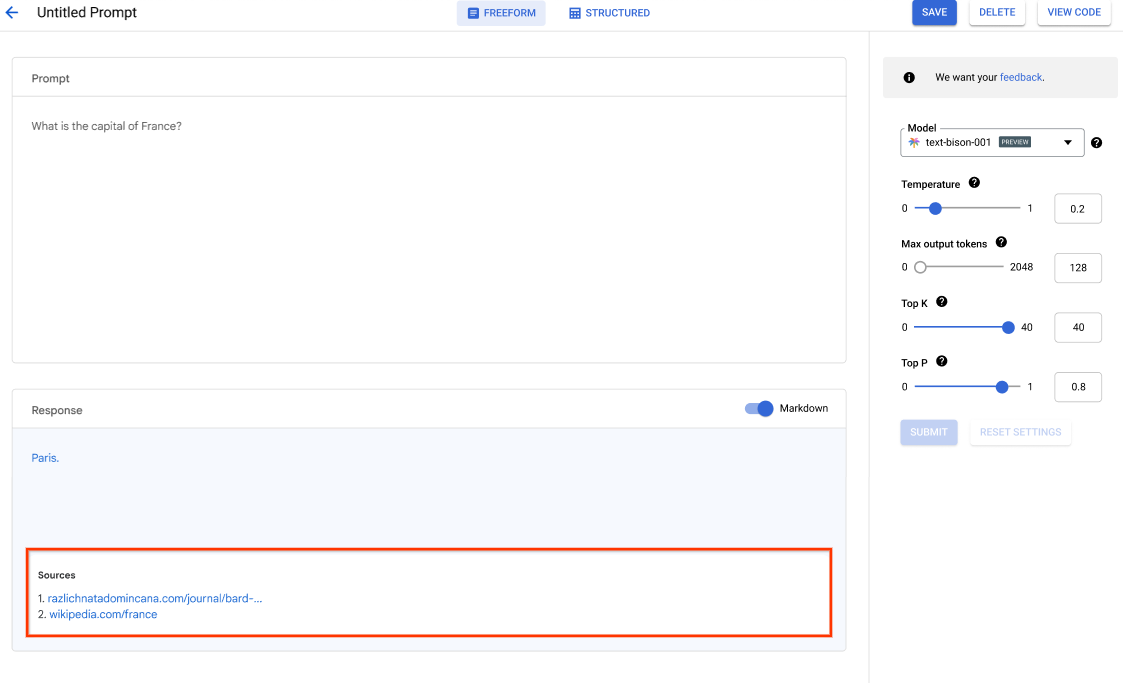
Consulta cómo ajustar LLM en Vertex AI Studio
Instructivos, guías de inicio rápido y labs
Obtén una introducción a la IA generativa en Vertex AI
Vertex AI Studio ofrece una herramienta de la consola de Google Cloud para crear prototipos de modelos de IA generativa y probarlos con rapidez. Aprende a usar Generative AI Studio para probar modelos mediante muestras de mensajes, diseñar y guardar mensajes, ajustar un modelo de base y realizar conversiones entre voz y texto.
Consulta cómo ajustar LLM en Vertex AI Studio
Extrae, resume y clasifica datos
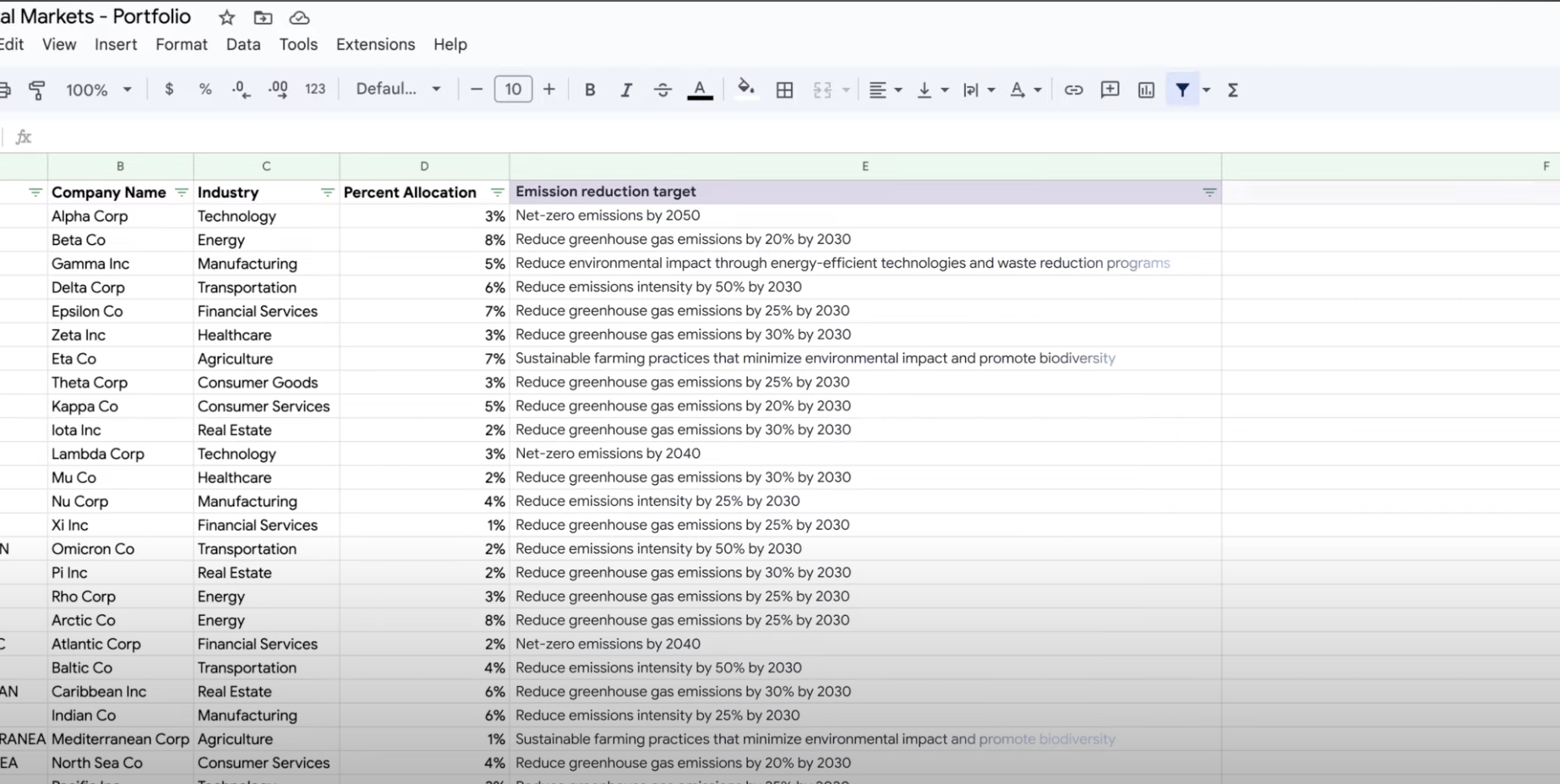
Usa IA generativa para resumir, clasificar y extraer
Aprende a crear mensajes de texto para controlar cualquier cantidad de tareas con la asistencia de la IA generativa de Vertex AI. Algunas de las tareas más comunes son la clasificación, el resumen y la extracción. Gemini en Vertex AI te permite diseñar instrucciones con flexibilidad en términos de su estructura y formato.
Instructivos, guías de inicio rápido y labs
Usa IA generativa para resumir, clasificar y extraer
Aprende a crear mensajes de texto para controlar cualquier cantidad de tareas con la asistencia de la IA generativa de Vertex AI. Algunas de las tareas más comunes son la clasificación, el resumen y la extracción. Gemini en Vertex AI te permite diseñar instrucciones con flexibilidad en términos de su estructura y formato.
Entrena modelos de AA personalizados
Descripción general y documentación del entrenamiento del AA personalizado
Mira un video explicativo de los pasos necesarios para entrenar modelos personalizados en Vertex AI.
Instructivos, guías de inicio rápido y labs
Descripción general y documentación del entrenamiento del AA personalizado
Mira un video explicativo de los pasos necesarios para entrenar modelos personalizados en Vertex AI.
Implementa un modelo para usar en la producción
Implementa modelos para predicciones en línea o por lotes
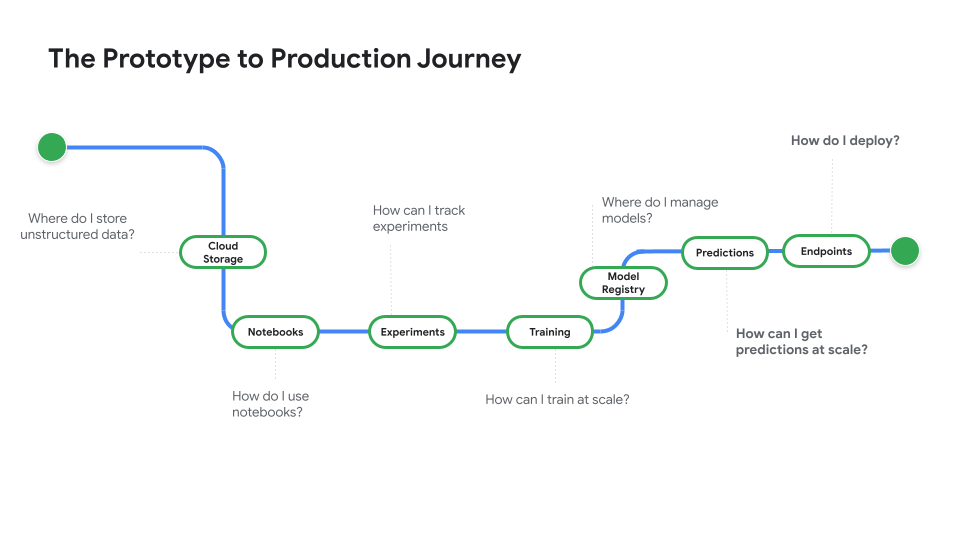
Mira Del prototipo a la producción, una serie de videos que te llevará del código de notebook a un modelo implementado.
Instructivos, guías de inicio rápido y labs
Implementa modelos para predicciones en línea o por lotes
Mira Del prototipo a la producción, una serie de videos que te llevará del código de notebook a un modelo implementado.
Precios
| Cómo funcionan los precios de Vertex AI | Paga por las herramientas de Vertex AI, el almacenamiento, el procesamiento y los recursos de Cloud que uses. Los clientes nuevos obtienen $300 en créditos gratuitos para probar Vertex AI y otros productos de Google Cloud. | |
|---|---|---|
| Herramientas y uso | Descripción | Precio |
IA generativa | Modelo de imagen para la generación de imágenes Según los precios de la entrada de imágenes, la entrada de caracteres o del entrenamiento personalizado. | A partir de $0.0001 |
Generación de mensajes, chat y código Según cada 1,000 caracteres de entrada (mensaje) y cada 1,000 caracteres de salida (respuesta). | A partir de $0.0001 por cada 1,000 caracteres | |
Modelos de AutoML | Entrenamiento, implementación y predicción de datos de imágenes Según el tiempo de entrenamiento por hora de procesamiento de nodo, lo que refleja el uso de recursos, y si se trata de clasificación o detección de objetos. | A partir de $1.375 por hora de procesamiento de nodo |
Entrenamiento y predicción de datos de video Se basa en el precio por hora de procesamiento de nodo y si se utiliza clasificación, seguimiento de objetos o reconocimiento de acciones. | A partir de $0.462 por hora de procesamiento de nodo | |
Entrenamiento y predicción de datos tabulares Se basa en el precio por hora de procesamiento de nodo y si se utiliza clasificación, regresión o previsión. Comunícate con Ventas para obtener información sobre precios y posibles descuentos. | Comunicarse con Ventas | |
Carga, entrenamiento, implementación y predicción de datos de texto Según las tarifas por hora para el entrenamiento y la predicción, las páginas para la carga de datos heredados (solo PDF), y los registros de texto y las páginas para la predicción. | A partir de $0.05 por hora | |
Modelos entrenados de forma personalizada | Entrenamiento personalizado de modelos Según el tipo de máquina que se usa por hora, la región y los aceleradores utilizados. Obtén una estimación mediante el equipo de ventas o nuestra calculadora de precios. | Comunicarse con Ventas |
Notebooks de Vertex AI | Recursos de procesamiento y almacenamiento Según las mismas tarifas que Compute Engine y Cloud Storage. | Consulta los productos |
Tarifas de administración Además del uso de recursos mencionado anteriormente, se aplican tarifas de administración según la región, las instancias, los notebooks y los notebooks administrados que se usen. Ver detalles. | Consulta los detalles | |
Vertex AI Pipelines | Tarifas de ejecución y adicionales Según el cargo de ejecución, los recursos usados y cualquier cargo de servicio adicional. | A partir de $0.03 por ejecución de canalización |
Vector Search de Vertex AI | Costos de entrega y compilación Según el tamaño de tus datos, la cantidad de consultas por segundo (QPS) que deseas ejecutar y la cantidad de nodos que usas. Ver ejemplo. | Consulta el ejemplo |
Consulta los detalles de precios de todas las funciones y servicios de Vertex AI.
Cómo funcionan los precios de Vertex AI
Paga por las herramientas de Vertex AI, el almacenamiento, el procesamiento y los recursos de Cloud que uses. Los clientes nuevos obtienen $300 en créditos gratuitos para probar Vertex AI y otros productos de Google Cloud.
Modelo de imagen para la generación de imágenes
Según los precios de la entrada de imágenes, la entrada de caracteres o del entrenamiento personalizado.
Starting at
$0.0001
Generación de mensajes, chat y código
Según cada 1,000 caracteres de entrada (mensaje) y cada 1,000 caracteres de salida (respuesta).
Starting at
$0.0001
por cada 1,000 caracteres
Entrenamiento, implementación y predicción de datos de imágenes
Según el tiempo de entrenamiento por hora de procesamiento de nodo, lo que refleja el uso de recursos, y si se trata de clasificación o detección de objetos.
Starting at
$1.375
por hora de procesamiento de nodo
Entrenamiento y predicción de datos de video
Se basa en el precio por hora de procesamiento de nodo y si se utiliza clasificación, seguimiento de objetos o reconocimiento de acciones.
Starting at
$0.462
por hora de procesamiento de nodo
Entrenamiento y predicción de datos tabulares
Se basa en el precio por hora de procesamiento de nodo y si se utiliza clasificación, regresión o previsión. Comunícate con Ventas para obtener información sobre precios y posibles descuentos.
Comunicarse con Ventas
Carga, entrenamiento, implementación y predicción de datos de texto
Según las tarifas por hora para el entrenamiento y la predicción, las páginas para la carga de datos heredados (solo PDF), y los registros de texto y las páginas para la predicción.
Starting at
$0.05
por hora
Entrenamiento personalizado de modelos
Según el tipo de máquina que se usa por hora, la región y los aceleradores utilizados. Obtén una estimación mediante el equipo de ventas o nuestra calculadora de precios.
Comunicarse con Ventas
Recursos de procesamiento y almacenamiento
Según las mismas tarifas que Compute Engine y Cloud Storage.
Consulta los productos
Tarifas de administración
Además del uso de recursos mencionado anteriormente, se aplican tarifas de administración según la región, las instancias, los notebooks y los notebooks administrados que se usen. Ver detalles.
Consulta los detalles
Tarifas de ejecución y adicionales
Según el cargo de ejecución, los recursos usados y cualquier cargo de servicio adicional.
Starting at
$0.03
por ejecución de canalización
Vector Search de Vertex AI
Costos de entrega y compilación
Según el tamaño de tus datos, la cantidad de consultas por segundo (QPS) que deseas ejecutar y la cantidad de nodos que usas. Ver ejemplo.
Consulta el ejemplo
Consulta los detalles de precios de todas las funciones y servicios de Vertex AI.
Comienza tu prueba de concepto
Caso empresarial
Aprovecha todo el potencial de la IA generativa

“La precisión de la solución de IA generativa de Google Cloud y la practicidad de Vertex AI Platform nos dan la confianza que necesitábamos para implementar esta tecnología de vanguardia en el centro de nuestra empresa y lograr nuestro objetivo a largo plazo de obtener un tiempo de respuesta de cero minutos”.
Abdol Moabery, director general de GA Telesis
Informes de analistas
TKTKT
Se nombró líder a Google en el informe The Forrester Wave™: AI Infrastructure Solutions del 1ᵉʳ trim. de 2024, en el que recibió las puntuaciones más altas entre los proveedores evaluados en las categorías Oferta actual y Estrategia.
Google es líder en el informe The Forrester Wave™: AI Foundation Models for Language, T2 de 2024 Lee el informe.
Google es líder en el informe The Forrester Wave: AI/ML Platforms, Q3 2024. Obtener más información.











