A transcodificação de dados localmente num mainframe é um processo que consome muita CPU e resulta num elevado consumo de milhões de instruções por segundo (MIPS). Para evitar esta situação, pode usar o Cloud Run para mover e transcodificar dados de mainframe remotamente no Google Cloud para o formato de colunas otimizado para linhas (ORC) e, em seguida, mover os dados para o Cloud Storage. Isto liberta o mainframe para tarefas críticas para a empresa e também reduz o consumo de MIPS.
A figura seguinte descreve como pode mover os dados do mainframe para o Google Cloud e transcodificá-los remotamente para o formato ORC através do Cloud Run e, em seguida, mover o conteúdo para o BigQuery.
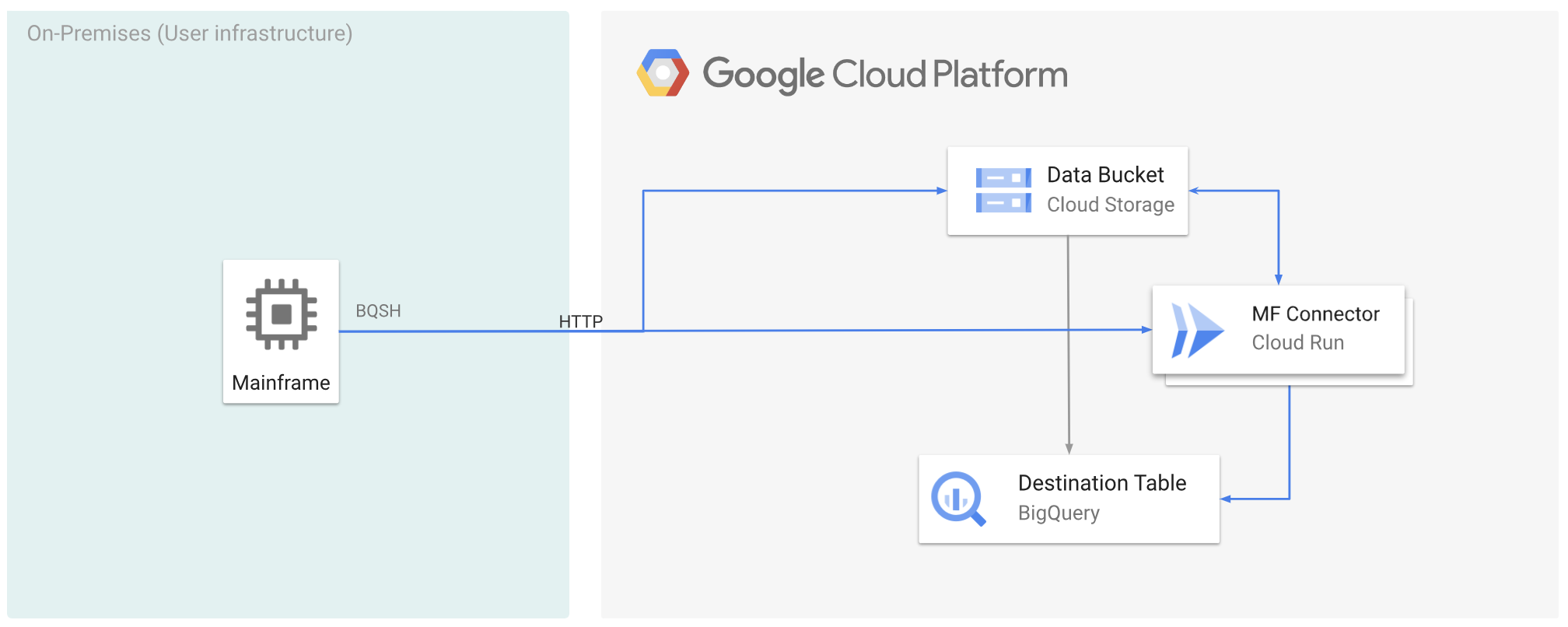
Antes de começar
- Implemente o Mainframe Connector no Cloud Run.
- Crie uma conta de serviço ou identifique uma conta de serviço existente para usar com o Mainframe Connector. Esta conta de serviço tem de ter autorizações para aceder a contentores do Cloud Storage, conjuntos de dados do BigQuery e qualquer outro Google Cloud recurso que queira usar.
- Confirme que à conta de serviço que criou está atribuída a função de invocador do Cloud Run.
Mova os dados do mainframe para o Google Cloud e transcodifique-os remotamente com o Cloud Run
Para mover os dados do mainframe para o Google Cloud e transcodificá-los remotamente através do Cloud Run, tem de realizar as seguintes tarefas:
- Ler e transcodificar um conjunto de dados num mainframe e carregá-lo para o Cloud Storage
no formato ORC. A transcodificação é feita durante a operação
gsutil cp, em que um conjunto de dados de código de intercâmbio decimal binário expandido (EBCDIC) de mainframe é convertido para o formato ORC em UTF-8 durante a cópia para um contentor do Cloud Storage. - Carregue o conjunto de dados para uma tabela do BigQuery.
- (Opcional) Execute uma consulta SQL na tabela do BigQuery.
- (Opcional) Exporte dados do BigQuery para um ficheiro binário no Cloud Storage.
Para realizar estas tarefas, siga estes passos:
No mainframe, crie uma tarefa para ler o conjunto de dados no mainframe e transcodificá-lo para o formato ORC, da seguinte forma. Ler os dados do conjunto de dados INFILE e o esquema de registo do COPYBOOK DD. O conjunto de dados de entrada tem de ser um ficheiro do método de acesso sequencial em fila (QSAM) com comprimento de registo fixo ou variável.
Para ver a lista completa de variáveis de ambiente suportadas pelo Mainframe Connector, consulte o artigo Variáveis de ambiente.
//STEP01 EXEC BQSH //INFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //STDIN DD * gsutil cp --replace gs://mybucket/tablename.orc --remote \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*Se quiser registar os comandos executados durante este processo, pode ativar as estatísticas de carregamento.
(Opcional) Crie e envie uma tarefa de consulta do BigQuery que execute uma leitura SQL a partir do ficheiro DD QUERY. Normalmente, a consulta é uma declaração
MERGEouSELECT INTO DMLque resulta na transformação de uma tabela do BigQuery. Tenha em atenção que o conetor do mainframe regista as métricas de tarefas, mas não escreve os resultados das consultas num ficheiro.Pode consultar o BigQuery de várias formas: inline, com um conjunto de dados separado através de DD ou com um conjunto de dados separado através de DSN.
Example JCL //STEP03 EXEC BQSH //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME LOCATION=LOCATION bq query --project_id=$PROJECT \ --location=$LOCATION \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443/* /*Além disso, tem de definir a variável de ambiente
BQ_QUERY_REMOTE_EXECUTION=true.Substitua o seguinte:
PROJECT_NAME: o nome do projeto no qual quer executar a consulta.LOCATION: a localização onde a consulta vai ser executada. Recomendamos que execute a consulta numa localização próxima dos dados.
(Opcional) Crie e envie uma tarefa de exportação que execute uma leitura SQL a partir do ficheiro DD QUERY e exporte o conjunto de dados resultante para o Cloud Storage como um ficheiro binário.
Example JCL //STEP04 EXEC BQSH //OUTFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME DATASET_ID=DATASET_ID DESTINATION_TABLE=DESTINATION_TABLE BUCKET=BUCKET bq export --project_id=$PROJECT \ --dataset_id=$DATASET_ID \ --destination_table=$DESTINATION_TABLE \ --location="US" \ --bucket=$BUCKET \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*Substitua o seguinte:
PROJECT_NAME: o nome do projeto no qual quer executar a consulta.DATASET_ID: O ID do conjunto de dados do BigQuery que contém a tabela que quer exportar.DESTINATION_TABLE: a tabela do BigQuery que quer exportar.BUCKET: O contentor do Cloud Storage que vai conter o ficheiro binário de saída.
O que se segue?
- Mova os dados do mainframe transcodificados localmente para Google Cloud
- Transcodifique dados de mainframe remotamente no Google Cloud
- Transcodifique dados de mainframe movidos para o Google Cloud usando uma biblioteca de fitas virtual