A transcodificação de dados localmente num mainframe é um processo que consome muita CPU e resulta num elevado consumo de milhões de instruções por segundo (MIPS). Para evitar esta situação, pode usar o Cloud Run para mover e transcodificar dados de mainframe remotamente noGoogle Cloud. Isto liberta o mainframe para tarefas críticas para a empresa e também reduz o consumo de MIPS.
Se quiser mover volumes de dados muito grandes (cerca de 500 GB por dia ou mais) do seu mainframe para o Google Cloude não quiser usar o mainframe para este esforço, pode usar uma solução de biblioteca de fitas virtuais (VTL) ativada na nuvem para transferir os dados para um contentor do Cloud Storage. Em seguida, pode usar o Cloud Run para transcodificar os dados presentes no contentor e movê-los para o BigQuery.
Esta página aborda a forma de ler dados de mainframe copiados para um contentor do Cloud Storage, transcodificá-los do conjunto de dados do código de intercâmbio decimal codificado em binário alargado (EBCDIC) para o formato ORC em UTF-8 e carregar o conjunto de dados para uma tabela do BigQuery.
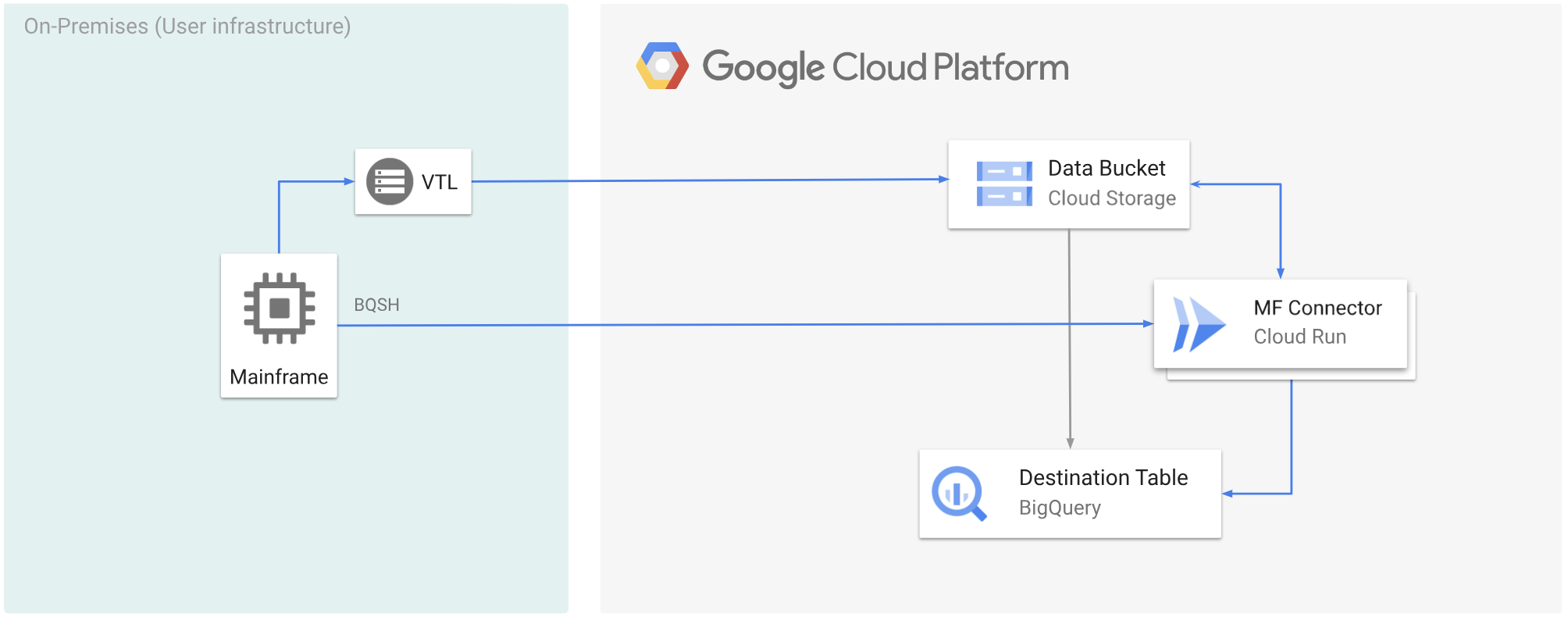
O diagrama seguinte mostra como pode mover os dados do mainframe para um contentor do Cloud Storage através de uma solução VTL, transcodificar os dados para o formato ORC com o Cloud Run e, em seguida, mover o conteúdo para o BigQuery.
Antes de começar
- Escolha uma solução VTL adequada aos seus requisitos e mova os dados do mainframe para um contentor do Cloud Storage e guarde-os como um ficheiro
.dat. Certifique-se de que adiciona uma chave de metadados denominadax-goog-meta-lreclao ficheiro.datcarregado e que o comprimento da chave de metadados é igual ao comprimento do registo do ficheiro original, por exemplo, 80. - Implemente o Mainframe Connector no Cloud Run.
- No mainframe, defina a variável de ambiente
GCSDSNURIpara o prefixo que usou para os dados do mainframe no contentor do Cloud Storage.export GCSDSNURI="gs://BUCKET/PREFIX"
- BUCKET: o nome do contentor do Cloud Storage.
- PREFIX: o prefixo que quer usar no contentor.
- Crie uma conta de serviço ou identifique uma conta de serviço existente para usar com o Mainframe Connector. Esta conta de serviço tem de ter autorizações para aceder a contentores do Cloud Storage, conjuntos de dados do BigQuery e qualquer outro Google Cloud recurso que queira usar.
- Certifique-se de que à conta de serviço que criou está atribuída a função de invocador do Cloud Run.
Transcodifique dados de mainframe carregados para um contentor do Cloud Storage
Para mover dados de mainframe para o Google Cloud usando VTL e transcodificar remotamente, tem de realizar as seguintes tarefas:
- Ler e transcodificar os dados presentes num contentor do Cloud Storage para o formato ORC. A operação de transcodificação converte um conjunto de dados EBCDIC de mainframe para o formato ORC em UTF-8.
- Carregue o conjunto de dados para uma tabela do BigQuery.
- (Opcional) Execute uma consulta SQL na tabela do BigQuery.
- (Opcional) Exporte dados do BigQuery para um ficheiro binário no Cloud Storage.
Para realizar estas tarefas, siga estes passos:
No mainframe, crie uma tarefa para ler os dados de um
.datficheiro num contentor do Cloud Storage e transcodificá-los para o formato ORC, da seguinte forma.Para ver a lista completa de variáveis de ambiente suportadas pelo Mainframe Connector, consulte o artigo Variáveis de ambiente.
//STEP01 EXEC BQSH //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //STDIN DD * gsutil cp --replace gs://mybucket/tablename.orc \ --inDsn INPUT_FILENAME \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 \ --project_id PROJECT_NAME /*Substitua o seguinte:
PROJECT_NAME: o nome do projeto no qual quer executar a consulta.INPUT_FILENAME: o nome do.datficheiro que carregou para um contentor do Cloud Storage.
Se quiser registar os comandos executados durante este processo, pode ativar as estatísticas de carregamento.
(Opcional) Crie e envie uma tarefa de consulta do BigQuery que execute uma leitura SQL a partir do ficheiro DD QUERY. Normalmente, a consulta é uma declaração
MERGEouSELECT INTO DMLque resulta na transformação de uma tabela do BigQuery. Tenha em atenção que o conetor do mainframe regista as métricas de tarefas, mas não escreve os resultados das consultas num ficheiro.Pode consultar o BigQuery de várias formas: inline, com um conjunto de dados separado através de DD ou com um conjunto de dados separado através de DSN.
Example JCL //STEP03 EXEC BQSH //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME LOCATION=LOCATION bq query --project_id=$PROJECT \ --location=$LOCATION/* /*Substitua o seguinte:
PROJECT_NAME: o nome do projeto no qual quer executar a consulta.LOCATION: a localização onde a consulta vai ser executada. Recomendamos que execute a consulta numa localização próxima dos dados.
(Opcional) Crie e envie uma tarefa de exportação que execute uma leitura SQL a partir do ficheiro DD QUERY e exporte o conjunto de dados resultante para o Cloud Storage como um ficheiro binário.
Example JCL //STEP04 EXEC BQSH //OUTFILE DD DSN=<HLQ>.DATA.FILENAME,DISP=SHR //COPYBOOK DD DISP=SHR,DSN=<HLQ>.COPYBOOK.FILENAME //QUERY DD DSN=<HLQ>.QUERY.FILENAME,DISP=SHR //STDIN DD * PROJECT=PROJECT_NAME DATASET_ID=DATASET_ID DESTINATION_TABLE=DESTINATION_TABLE BUCKET=BUCKET bq export --project_id=$PROJECT \ --dataset_id=$DATASET_ID \ --destination_table=$DESTINATION_TABLE \ --location="US" \ --bucket=$BUCKET \ --remoteHost <mainframe-connector-url>.a.run.app \ --remotePort 443 /*Substitua o seguinte:
PROJECT_NAME: o nome do projeto no qual quer executar a consulta.DATASET_ID: O ID do conjunto de dados do BigQuery que contém a tabela que quer exportar.DESTINATION_TABLE: a tabela do BigQuery que quer exportar.BUCKET: O contentor do Cloud Storage que vai conter o ficheiro binário de saída.