Os mainframes da IBM são usados por organizações para realizar tarefas de computação essenciais. Nos últimos anos, muitas empresas que dependem de mainframes têm trabalhado para migrar para a nuvem. Com o Mainframe Connector, você pode mover seus dados de mainframe para o Google Cloud para descarregar cargas de trabalho de relatórios com uso intensivo da CPU para o Google Cloud.
Principais benefícios do Mainframe Connector
Confira os principais benefícios de usar o Mainframe Connector para mover dados do mainframe para o Google Cloud:
- Transferência de dados simplificada:simplifica a movimentação de dados do mainframe para Google Cloud serviços de armazenamento como o Cloud Storage e o BigQuery.
- Integração de jobs em lote:permite enviar jobs do BigQuery usando jobs em lote de mainframe definidos na linguagem de controle de jobs (JCL). À medida que as consultas são lidas de conjuntos de dados ou arquivos, os analistas podem usar jobs programados com conhecimento e compreensão mínimos dos ambientes de mainframe.
- Monitoramento fácil:o pessoal de operações do mainframe não precisa monitorar um ambiente diferente à medida que os jobs são enviados com programações conhecidas usando JCL.
- Redução de MIPS:o Mainframe Connector usa uma máquina virtual Java (JVM) para a maioria dos processamentos, minimizando a carga de trabalho do processador do mainframe durante a transferência de dados. Isso reduz milhões de instruções por segundo (MIPS), diminuindo os custos. O Mainframe Connector descarrega a maior parte do trabalho que exige muito do processador para processadores auxiliares. Se os processadores auxiliares estiverem sobrecarregados, você também poderá configurar o Mainframe Connector para realizar transcodificação e conversão usando o Compute Engine. Para mais informações sobre as configurações do Mainframe Connector, consulte Configurações do Mainframe Connector.
Transformação de streaming:transcodifica arquivos para os formatos ORC, JSON ou CSV, que são compatíveis com serviços do Google Cloud , como o BigQuery. O Mainframe Connector é compatível com transcodificação para os seguintes tipos de arquivo:
- Conjuntos de dados de mainframe do método de acesso sequencial enfileirado (QSAM) ou do método de acesso ao armazenamento virtual (VSAM) associados a copybooks COBOL no código de troca decimal codificado em binário estendido (EBCDIC)
- Arquivos em ASCII UTF-8
Por padrão, o Mainframe Connector transcodifica conjuntos de dados do conjunto de caracteres US EBCDIC: Cp037 para os formatos ORC, JSON e CSV. No entanto, o Mainframe Connector também é compatível com a transcodificação de conjuntos de dados dos seguintes conjuntos de caracteres EBCDIC regionais:
- Francês: Cp297
- Alemão: Cp1141
- Espanhol: Cp1145
Um conjunto de caracteres personalizado pode ser implementado se um adequado não estiver incluído na JVM da IBM.
Como o Mainframe Connector funciona
Com o conector de mainframe, é possível mover dados localizados no mainframe para dentro e para fora do Cloud Storage e enviar jobs do BigQuery de jobs em lote baseados em mainframe definidos em JCL. Com o Mainframe Connector, é possível transcodificar conjuntos de dados de mainframe diretamente para o formato Optimized Row Columnar (ORC).
A transcodificação é o processo de conversão de informações de uma forma de representação codificada para outra, neste caso, para ORC. O ORC é um formato de dados de código aberto orientado por colunas muito usado no ecossistema do Apache Hadoop e compatível com o BigQuery.
O Mainframe Connector oferece um subconjunto dos utilitários de linha de comando do SDK Google Cloud para que você possa transferir dados e interagir com serviços do Google Cloud . O interpretador de shell e as implementações baseadas em JVM de gsutil e utilitários de linha de comando bq permitem gerenciar um pipeline completo de extração, carregamento e transformação (ELT) inteiramente do IBM z/OS, mantendo o programador de jobs atual.
Um dos principais desafios na transferência de dados do mainframe para a nuvem e vice-versa é que esse é um processo de várias etapas que normalmente inclui a execução das seguintes etapas:
- Copie os dados para um servidor de arquivos.
- Copie os dados do servidor de arquivos para outro local para processamento.
- Use uma pilha de processamento de dados para converter os dados em um formato moderno.
- Grave os dados processados em outro local.
- Carregue os dados processados em um banco de dados ou um data warehouse em que eles possam ser consultados ou usados.
A figura a seguir mostra o processo de várias etapas normalmente usado para transferir dados de um mainframe para o Google Cloud.
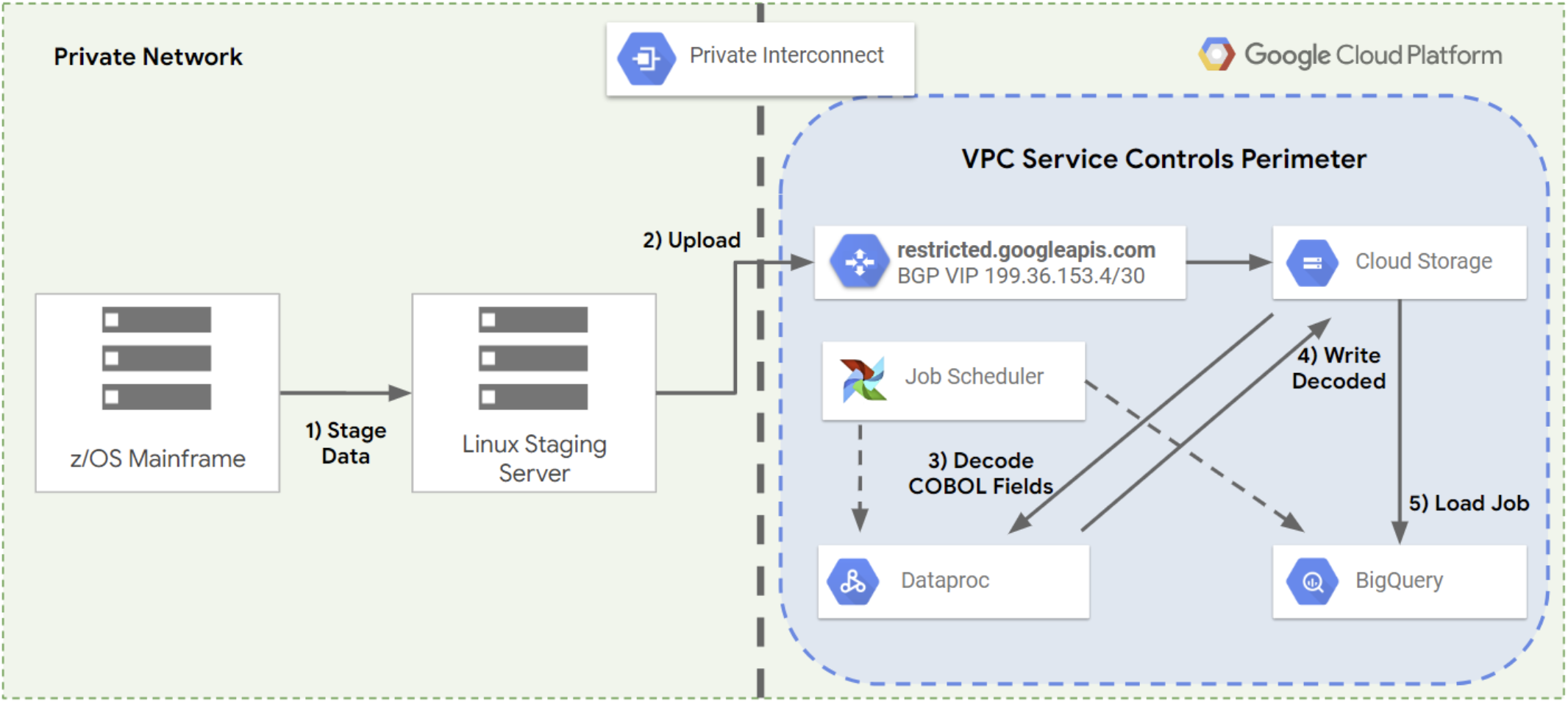
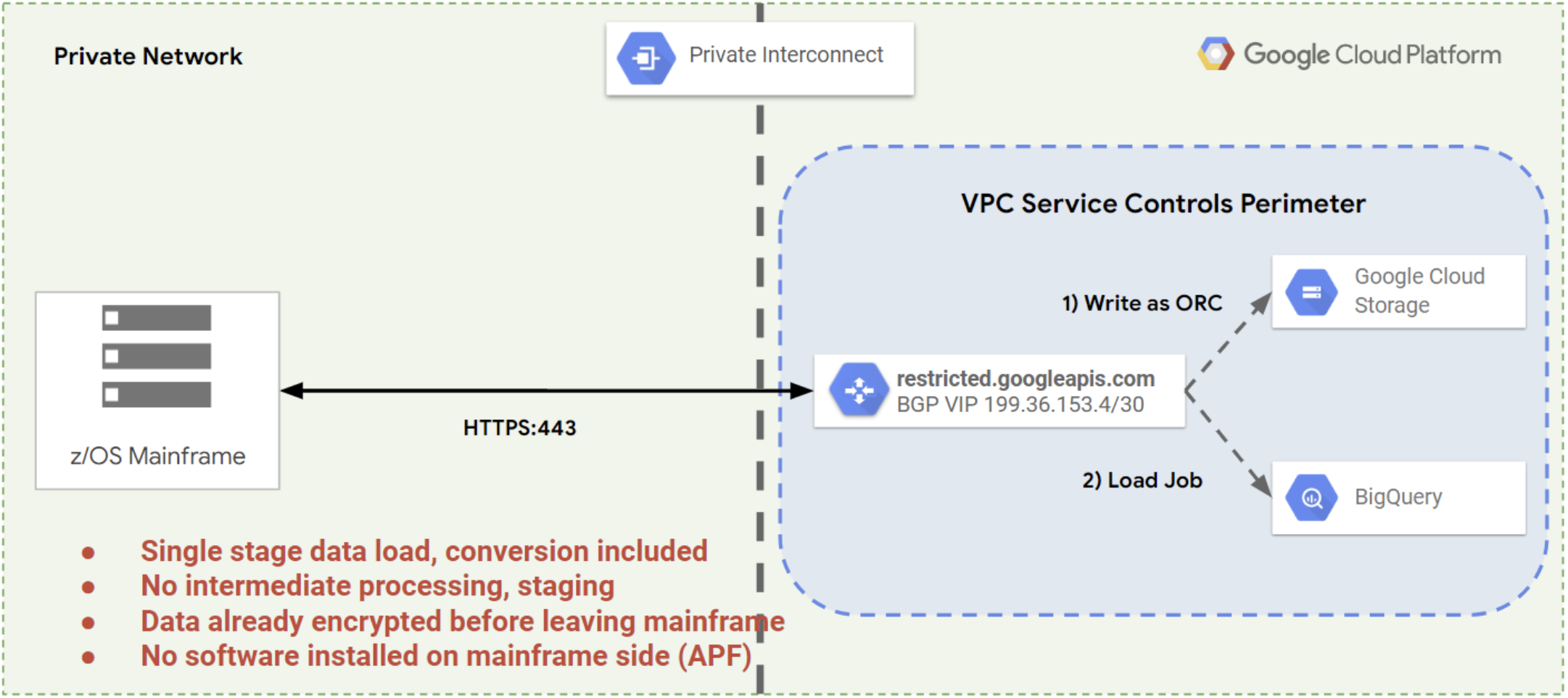
Com o Mainframe Connector, é possível realizar todas essas etapas com um único comando usando o Cloud Storage como um local de armazenamento intermediário. Isso reduz o tempo necessário para que os dados do mainframe sejam processados e disponibilizados em um banco de dados ou data warehouse, conforme mostrado na figura a seguir.
A seguir
- Arquitetura do Mainframe Connector
- Configurações do Mainframe Connector
- Instalar o Mainframe Connector