In Looker, le tabelle derivate persistenti (PDT) vengono scritte nello schema temporaneo del database. Looker persiste e ricrea una PDT in base alla sua strategia di persistenza. Quando si attiva la ricostruzione di una PDT, per impostazione predefinita Looker ricostruisce l'intera tabella.
Una PDT incrementale è una PDT creata da Looker aggiungendo dati aggiornati alla tabella anziché ricrearla integralmente:
Se il tuo dialetto supporta le PDT incrementali, puoi trasformare le seguenti PDT in PDT incrementali:
La prima volta che esegui una query su una PDT incrementale, Looker crea l'intera PDT per ottenere i dati iniziali. Se la tabella è grande, la creazione iniziale potrebbe richiedere molto tempo, così come la creazione di qualsiasi tabella di grandi dimensioni. Una volta creata la tabella iniziale, le build successive saranno incrementali e richiedono meno tempo se la PDT incrementale è configurata in modo strategico.
Tieni presente quanto segue per le PDT incrementali:
- Le PDT incrementali sono supportate solo per le PDT che utilizzano una strategia di persistenza basata su trigger (
datagroup_trigger,sql_trigger_valueointerval_trigger). Le PDT incrementali non sono supportate per le PDT che utilizzano la strategia di persistenzapersist_for. - Per le PDT basate su SQL, la query di tabella deve essere definita utilizzando il parametro
sqlper essere utilizzata come PDT incrementale. Le PDT basate su SQL definite con il parametrosql_createo il parametrocreate_processnon possono essere create in modo incrementale. Come vedi nell'Esempio 1 di questa pagina, Looker utilizza un comando INSERT o un comando HSM per creare gli incrementi di una PDT incrementale. La tabella derivata non può essere definita utilizzando istruzioni DDL (Data Definition Language) personalizzate, poiché Looker non sarebbe in grado di determinare quali istruzioni DDL sarebbero necessarie per creare un incremento accurato. - La tabella di origine delle PDT incrementali deve essere ottimizzata per le query basate sul tempo. In particolare, la colonna basata sul tempo utilizzata per la chiave di incremento deve avere una strategia di ottimizzazione, ad esempio partizionamento, ordinakey, indici o qualsiasi strategia di ottimizzazione supportata per il dialetto. L'ottimizzazione della tabella di origine è vivamente consigliata perché ogni volta che la tabella incrementale viene aggiornata, Looker esegue query sulla tabella di origine per determinare i valori più recenti della colonna basata sul tempo utilizzata per la chiave di incremento. Se la tabella di origine non è ottimizzata per queste query, la query di Looker per i valori più recenti potrebbe essere lenta e costosa.
Definizione di una PDT incrementale
Puoi utilizzare i seguenti parametri per trasformare una PDT in una PDT incrementale:
increment_key(obbligatorio per impostare la PDT come PDT incrementale): definisce il periodo di tempo durante il quale eseguire la query sui nuovi record.{% incrementcondition %}Filtro liquido (obbligatorio per applicare una PDT basata su SQL come PDT incrementale; non applicabile alle PDT basate su Look): connette la chiave di aumento alla colonna di tempo di database su cui si basa la chiave di incremento. Per ulteriori informazioni, consulta la pagina della documentazione diincrement_key.- (Facoltativo)
increment_offset: un numero intero che definisce il numero di periodi di tempo precedenti (alla granularità della chiave di incremento) ricreati per ciascuna build incrementale. Il parametroincrement_offsetè utile nel caso di dati in ritardo, in cui i periodi di tempo precedenti potrebbero avere nuovi dati che non sono stati inclusi quando l'incremento corrispondente è stato originariamente creato e aggiunto alla PDT.
Consulta la pagina della documentazione relativa al parametro increment_key per trovare esempi di come creare PDT incrementali da tabelle derivate native persistenti, tabelle derivate basate su SQL persistenti e tabelle aggregate.
Ecco un semplice esempio di file di vista che definisce una PDT incrementale basata su LookML:
view: flights_lookml_incremental_pdt {
derived_table: {
indexes: ["id"]
increment_key: "departure_date"
increment_offset: 3
datagroup_trigger: flights_default_datagroup
distribution_style: all
explore_source: flights {
column: id {}
column: carrier {}
column: departure_date {}
}
}
dimension: id {
type: number
}
dimension: carrier {
type: string
}
dimension: departure_date {
type: date
}
}
Questa tabella verrà creata interamente alla prima esecuzione di una query. In seguito, la PDT verrà ricreata con incrementi di un giorno (increment_key: departure_date), fino a tre giorni (increment_offset: 3).
La chiave di incremento si basa sulla dimensione departure_date, che in realtà è il periodo di tempo di date del gruppo di dimensioni departure. Per una panoramica del funzionamento dei gruppi di dimensioni, consulta la pagina della documentazione relativa al parametro dimension_group. Il gruppo di dimensioni e il periodo di tempo sono entrambi definiti nella vista flights, che è il explore_source per questa PDT. Ecco come viene definito il gruppo di dimensioni departure nel file vista flights:
...
dimension_group: departure {
type: time
timeframes: [
raw,
date,
week,
month,
year
]
sql: ${TABLE}.dep_time ;;
}
...
Interazione dei parametri di incremento e della strategia di persistenza
Le impostazioni increment_key e increment_offset di una PDT sono indipendenti dalla strategia di persistenza della PDT:
- La strategia di persistenza incrementale della PDT determina solo quando la PDT aumenta. Il generatore di PDT non modifica la PDT incrementale a meno che non venga attivata la strategia di persistenza della tabella o se quest'ultima viene attivata manualmente con l'opzione Rebuild Derived Tables & Run in un'esplorazione.
- Quando il valore PDT aumenta, il generatore di PDT determina il momento in cui i dati più recenti sono stati precedentemente aggiunti alla tabella, in termini di incremento di tempo più recente (il periodo di tempo definito dal parametro
increment_key). In base a ciò, il generatore di PDT troncherà i dati all'inizio dell'incremento di tempo più recente nella tabella, quindi creerà l'ultimo incremento da lì. - Se il PDT ha un parametro
increment_offset, lo strumento crea anche il numero di periodi di tempo precedenti specificati nel parametroincrement_offset. I periodi di tempo precedenti risalgono all'inizio dell'incremento di tempo più corrente (il periodo di tempo definito dal parametroincrement_key).
I seguenti scenari di esempio mostrano come vengono aggiornate le PDT incrementali mostrando l'interazione tra increment_key, increment_offset e la strategia di persistenza.
Esempio 1
In questo esempio viene utilizzata una PDT con queste proprietà:
- Chiave di incremento: data
- Incremento incrementale: 3
- Strategia di persistenza: attivata una volta al mese il primo giorno del mese.
Ecco come verrà aggiornata questa tabella:
- Una strategia di persistenza mensile significa che la tabella viene creata automaticamente una volta al mese. Ciò significa che il 1° giugno, ad esempio, l'ultima riga della tabella verrà aggiunta il 1° maggio.
- Poiché questa PDT ha una chiave di incremento basata sulla data, il generatore di PDT verrà troncato dal 1° maggio all'inizio della giornata e ricostruisce i dati dal 1° al 1° giugno fino al giorno corrente.
- Inoltre, questa PDT ha un offset incrementale di
3. Pertanto, il generatore di PDT ricostruisce anche i dati dei tre periodi di tempo precedenti al giorno 1° maggio. Il risultato è che i dati vengono ricostruiti per il 28, 29, 30 aprile e fino al giorno corrente del 1 giugno.
In termini SQL, ecco il comando che il builder PDT verrà eseguito il 1° giugno per determinare le righe della PDT esistente che devono essere ricostruite:
## Example SQL for BigQuery:
SELECT FORMAT_TIMESTAMP('%F %T',TIMESTAMP_ADD(MAX(pdt_name),INTERVAL -3 DAY))
## Example SQL for other dialects:
SELECT CAST(DATE_ADD(MAX(pdt_name),INTERVAL -3 DAY) AS CHAR)
Ecco il comando SQL che il generatore di PDT eseguirà il 1° giugno per creare l'incremento più recente:
## Example SQL for BigQuery:
MERGE INTO [pdt_name] USING (SELECT [columns]
WHERE created_at >= TIMESTAMP('4/28/21 12:00:00 AM'))
AS tmp_name ON FALSE
WHEN NOT MATCHED BY SOURCE AND created_date >= TIMESTAMP('4/28/21 12:00:00 AM')
THEN DELETE
WHEN NOT MATCHED THEN INSERT [columns]
## Example SQL for other dialects:
START TRANSACTION;
DELETE FROM [pdt_name]
WHERE created_date >= TIMESTAMP('4/28/21 12:00:00 AM');
INSERT INTO [pdt_name]
SELECT [columns]
FROM [source_table]
WHERE created_at >= TIMESTAMP('4/28/21 12:00:00 AM');
COMMIT;
Esempio 2
In questo esempio viene utilizzata una PDT con queste proprietà:
- Strategia di persistenza: attivata una volta al giorno
- Chiave di incremento: mese
- Incremento incrementale: 0
Ecco come verrà aggiornata questa tabella il 1° giugno:
- La strategia di persistenza giornaliera significa che la tabella viene creata automaticamente una volta al giorno. Il 1° giugno l'ultima riga della tabella sarà aggiunta il 31 maggio.
- Poiché la chiave di incremento si basa sul mese, il generatore di PDT verrà troncato dal 31 maggio all'inizio del mese e ricostruisce i dati relativi a tutto il giorno di maggio e fino al giorno corrente, incluso il 1° giugno.
- Poiché questa PDT non ha un offset incrementale, non vengono ricreati periodi di tempo precedenti.
Ecco come verrà aggiornata questa tabella il 2 giugno:
- Il 2 giugno l'ultima riga della tabella verrà aggiunta il 1° giugno.
- Poiché il generatore di PDT verrà troncato all'inizio del mese di giugno per poi ricostruire i dati a partire dal 1° giugno e fino al giorno corrente, questi vengono ricostruiti solo per i giorni 1 e 2 giugno.
- Poiché questa PDT non ha un offset incrementale, non vengono ricreati periodi di tempo precedenti.
Esempio 3
In questo esempio viene utilizzata una PDT con queste proprietà:
- Chiave di incremento: mese
- Incremento incrementale: 3
- Strategia di persistenza: attivata una volta al giorno
Questo scenario illustra una cattiva configurazione per una PDT incrementale, poiché si tratta di una PDT giornaliera che si attiva con un offset di tre mesi. Ciò significa che vengono ricreati almeno tre mesi di dati ogni giorno, il che sarebbe un uso molto inefficiente di una PDT incrementale. Tuttavia, è uno scenario interessante da analizzare per capire come funzionano le PDT incrementali.
Ecco come verrà aggiornata questa tabella il 1° giugno:
- La strategia di persistenza giornaliera significa che la tabella viene creata automaticamente una volta al giorno. Il 1° giugno, ad esempio, l'ultima riga della tabella sarà aggiunta il 31 maggio.
- Poiché la chiave di incremento si basa sul mese, il generatore di PDT verrà troncato dal 31 maggio all'inizio del mese e ricostruisce i dati relativi a tutto il giorno di maggio e fino al giorno corrente, incluso il 1° giugno.
- Inoltre, questa PDT ha un offset incrementale di
3. Ciò significa che il generatore di PDT ricostruisce anche i dati dei tre periodi di tempo precedenti (mesi) precedenti a maggio. In questo modo, i dati vengono ricostruiti da febbraio, marzo, aprile e fino al giorno corrente, il 1° giugno.
Ecco come verrà aggiornata questa tabella il 2 giugno:
- Il 2 giugno l'ultima riga della tabella verrà aggiunta il 1° giugno.
- Il generatore di PDT tronca il mese al 1° giugno e ricostruisce i dati relativi al mese di giugno, incluso il 2 giugno.
- Inoltre, a causa dell'incremento di offset, il generatore di PDT ricostruisce i dati dei tre mesi precedenti a giugno. Di conseguenza, i dati vengono ricreati da marzo, aprile, maggio e il giorno corrente, 2 giugno.
Test di una PDT incrementale in modalità sviluppatore
Prima di eseguire il deployment di una nuova PDT incrementale nell'ambiente di produzione, puoi testarla per assicurarti che generi e aumenti. Per testare una PDT incrementale in modalità sviluppatore:
Crea un'esplorazione per le PDT:
- In un file del modello associato, utilizza il parametro
includeper includere il file di vista PDT nel file del modello. - Nello stesso file modello, utilizza il parametro
exploreper creare un'esplorazione per la visualizzazione PDT incrementale.
include: "/views/e_faa_pdt.view" explore: e_faa_pdt {}- In un file del modello associato, utilizza il parametro
Apri Esplora per le PDT. Per farlo, seleziona il pulsante Visualizza le azioni sui file, quindi seleziona un nome Esplora.
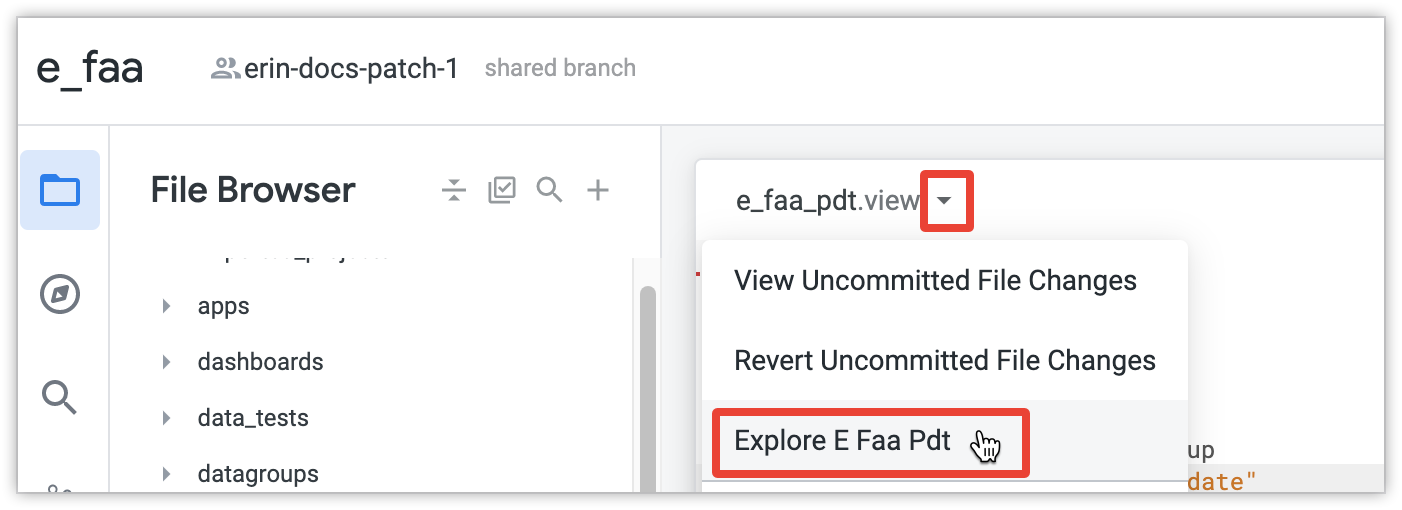
In Esplora, seleziona alcune dimensioni o misure e fai clic su Esegui. Looker creerà quindi l'intera PDT. Se questa è la prima query che hai eseguito sulla PDT incrementale, quest'ultimo creerà l'intera PDT per ottenere i dati iniziali. Se la tabella è grande, la creazione iniziale potrebbe richiedere molto tempo, così come la creazione di qualsiasi tabella di grandi dimensioni.
Puoi verificare che la PDT iniziale sia stata creata nei seguenti modi:
- Se hai l'autorizzazione
see_logs, puoi verificare che la tabella sia stata creata esaminando il log eventi PDT. Se non visualizzi gli eventi di creazione di PDT nel log eventi PDT, controlla le informazioni sullo stato nella parte superiore di Esplora log eventi PDT. Se è indicato "da cache", puoi selezionare Svuota cache e aggiorna per ottenere informazioni più recenti. - In alternativa, puoi visualizzare i commenti nella scheda SQL della barra Dati di Esplora. Nella scheda SQL vengono visualizzate la query e le azioni che vengono eseguite quando esegui la query in Esplora. Ad esempio, se i commenti nella scheda SQL indicano
-- generate derived table e_incremental_pdt,
- Se hai l'autorizzazione
Dopo aver creato la build PDT iniziale, richiedine una incrementale utilizzando l'opzione Riesegui tabelle derivate ed esecuzione da Esplora.
Puoi utilizzare gli stessi metodi di prima per verificare che la PDT venga sviluppata in modo incrementale:
- Se disponi dell'autorizzazione
see_logs, puoi utilizzare il log eventi PDT per visualizzare gli eventicreate increment completerelativi alla PDT incrementale. Se non vedi questo evento nel log eventi PDT e lo stato della query è "da cache", seleziona Svuota cache e aggiorna per ottenere informazioni più recenti. - Esamina i commenti nella scheda SQL della barra Dati di Esplora. In questo caso, i commenti indicheranno che la PDT è stata incrementata. Ad esempio:
-- increment persistent derived table e_incremental_pdt to generation 2
- Se disponi dell'autorizzazione
Dopo aver verificato che la PDT è stata creata e incrementata correttamente, se non vuoi conservare la esplorazione dedicata per la PDT, puoi rimuovere i parametri
exploreeincludedella PDT dal file del modello.
Dopo che la PDT è stata creata in modalità di sviluppo, la stessa tabella verrà utilizzata per la produzione dopo che avrai eseguito il deployment delle modifiche, a meno che non apporti ulteriori modifiche alla definizione della tabella. Per ulteriori informazioni, consulta la sezione Tabelle persistenti in modalità Sviluppo della pagina della documentazione Tabelle derivate in Looker.
Dialetti supportati dal database per le PDT incrementali
Affinché Looker supporti le PDT incrementali nel tuo progetto Looker, il dialetto del tuo database deve supportare i comandi DDL (Data Definition Language) che consentono l'eliminazione e l'inserimento delle righe.
La seguente tabella mostra quali dialetti supportano le PDT incrementali nell'ultima release di Looker: