Une table dérivée est une requête dont les résultats sont utilisés comme s'il s'agissait d'une table physique de la base de données. Une table dérivée native est basée sur une requête que vous définissez à l'aide de termes LookML. Cette méthode est différente d'une table dérivée basée sur SQL, qui est basée sur une requête que vous définissez avec des termes SQL. Comparées aux tables dérivées basées sur SQL, les tables dérivées natives sont beaucoup plus faciles à lire et à comprendre lors de la modélisation des données. Pour en savoir plus, consultez la section Tables dérivées natives et tables dérivées SQL de la page de documentation Tables dérivées dans Looker.
Les tables dérivées natives et basées sur SQL sont définies dans LookML à l'aide du paramètre derived_table au niveau de la vue. En revanche, avec les tables dérivées natives, il est inutile de créer une requête SQL. À la place, vous utilisez le paramètre explore_source afin d'indiquer l'exploration à utiliser pour baser la table dérivée, les colonnes souhaitées et d'autres caractéristiques souhaitées.
Vous pouvez également demander à Looker de créer le LookML de table dérivée à partir d'une requête de l'exécuteur SQL, comme décrit dans la page de documentation Utiliser l'exécuteur SQL pour créer des tables dérivées.
Définition de vos tables dérivées natives à partir d'une exploration
À partir d'une exploration, Looker peut générer un code LookML pour tout ou partie d'une table dérivée. Il suffit de créer une exploration et de sélectionner tous les champs souhaités dans la table. Ensuite, pour générer le code LookML de la table dérivée native :
Sélectionnez le menu en forme de roue dentée Explore Actions (Explorer les actions), puis cliquez sur Get LookML (Obtenir LookML).
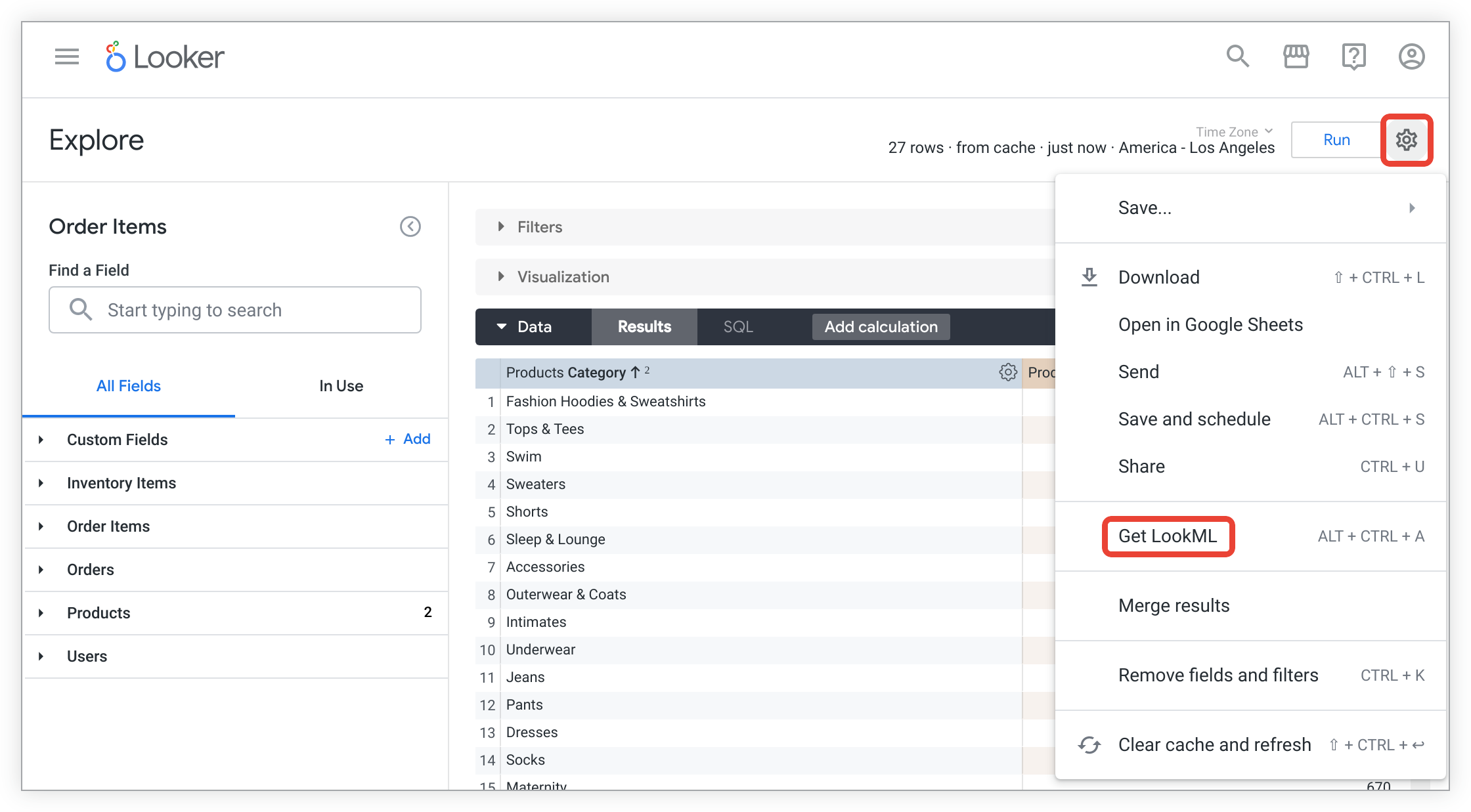
Cliquez sur l'onglet Tableau dérivé pour afficher le LookML permettant de créer une table dérivée native pour l'exploration.
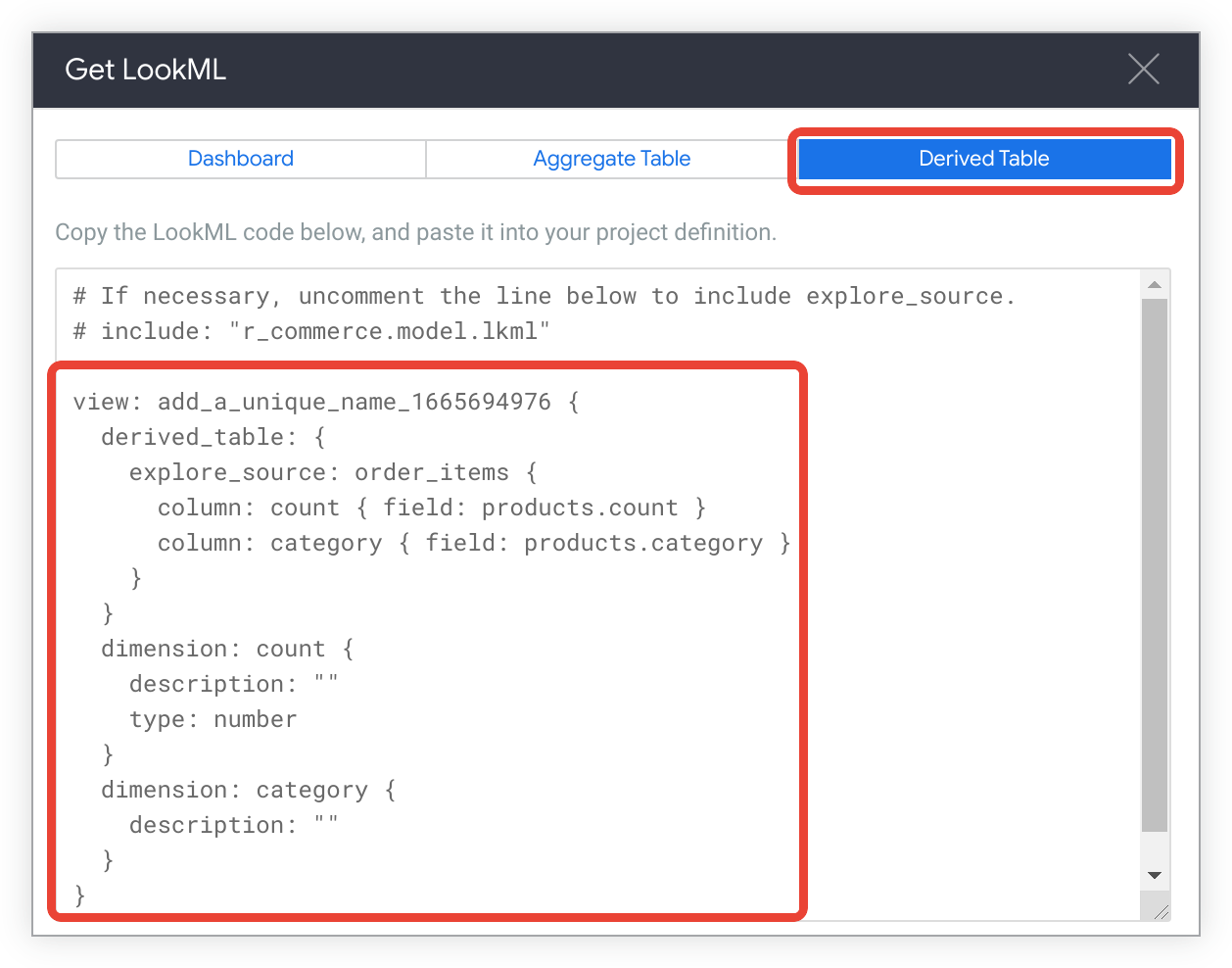
Copiez le code LookML.
Après avoir copié le code LookML généré, collez-le dans un fichier de vue :
En mode Développement, accédez aux fichiers de votre projet.
Dans l'IDE Looker, cliquez sur + en haut de la liste des fichiers du projet, puis sélectionnez Créer une vue. Vous pouvez également cliquer sur le menu d'un dossier et sélectionner Créer une vue dans le menu pour créer le fichier à l'intérieur du dossier.
Donnez un nom représentatif à la vue.
Au besoin, changez le nom des colonnes, désignez des colonnes dérivées et ajoutez des filtres.
Lorsque vous utilisez une mesure de
type: countdans une exploration, la visualisation associe les valeurs obtenues au nom de la vue plutôt qu'au mot Count. Pour éviter toute confusion, nous vous recommandons de donner au nom de votre vue au pluriel, de sélectionner Afficher le nom complet du champ sous Série dans les paramètres de visualisation ou d'utiliser uneview_labelavec une version plurielle du nom de votre vue.
Définition d'une table dérivée native dans LookML
Que vous utilisiez des tables dérivées déclarées en SQL ou un langage LookML natif, la sortie d'une requête derived_table est une table comportant un ensemble de colonnes. Si la table dérivée est exprimée en SQL, les noms de ces colonnes de sortie sont implicitement fournis par la requête SQL. Par exemple, la requête SQL ci-dessous comportera les colonnes de sortie user_id, lifetime_number_of_orders et lifetime_customer_value:
SELECT
user_id
, COUNT(DISTINCT order_id) as lifetime_number_of_orders
, SUM(sale_price) as lifetime_customer_value
FROM order_items
GROUP BY 1
Dans Looker, les requêtes sont basées sur une exploration, incluent des champs de mesure et de dimension, ajoutent si nécessaire des filtres, et peuvent même indiquer un ordre de tri. Une table dérivée native contient tous ces éléments, ainsi que les noms de sortie des colonnes.
L'exemple simple ci-dessous génère un tableau dérivé de trois colonnes: user_id, lifetime_customer_value et lifetime_number_of_orders. Vous n'avez pas besoin d'écrire manuellement la requête en SQL. Looker crée la requête à votre place en utilisant la fonctionnalité Explorer order_items spécifiée, ainsi que certains des champs de cette exploration (order_items.user_id, order_items.total_revenue et order_items.order_count).
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: lifetime_number_of_orders {
field: order_items.order_count
}
column: lifetime_customer_value {
field: order_items.total_revenue
}
}
}
# Define the view's fields as desired
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
}
Utiliser des instructions include pour activer le référencement des champs
Dans le fichier de vue de la table dérivée native, vous utilisez le paramètre explore_source pour pointer vers une exploration, ainsi que pour définir les colonnes souhaitées et d'autres caractéristiques souhaitées pour la table dérivée native. Étant donné que vous placez le curseur sur une exploration à partir du fichier de vue de la table dérivée native, vous devez également inclure le fichier contenant la définition de l'exploration. Les explorations sont généralement définies dans un fichier de modèle, mais dans le cas des tables dérivées natives, il est plus propre de créer un fichier distinct pour l'exploration à l'aide de l'extension de fichier .explore.lkml, comme décrit dans la documentation Créer des fichiers d'exploration. De cette façon, vous pouvez inclure un unique fichier d'exploration dans le fichier de vue de votre table dérivée native, plutôt que l'intégralité du fichier de modèle. Dans ce cas :
- Le fichier de vue de la table dérivée native doit inclure le fichier Explorer. Exemple:
include: "/explores/order_items.explore.lkml" - Le fichier de l'exploration doit inclure les fichiers d'affichage dont il a besoin. Exemple:
include: "/views/order_items.view.lkml"
include: "/views/users.view.lkml" - Le modèle doit inclure le fichier Explorer. Exemple:
include: "/explores/order_items.explore.lkml"
Les fichiers Explorer détecteront la connexion du modèle dans lequel ils sont inclus. Tenez-en compte lorsque vous incluez des fichiers Explorer dans des modèles configurés avec une connexion différente du modèle parent du fichier Explorer. Si le schéma de connexion du modèle inclus est différent de celui de la connexion du modèle parent, des erreurs de requête peuvent se produire.
Définition de colonnes d'une table dérivée native
Comme indiqué dans l'exemple ci-dessus, vous devez spécifier les colonnes de sortie de la table dérivée à l'aide de column.
Spécification des noms de colonnes
Pour la colonne user_id, le nom de la colonne correspond au nom du champ spécifié dans l'exploration d'origine.
En général, vous souhaitez que les colonnes de la table de sortie portent un nom différent de celui des champs de l'exploration d'origine. Dans l'exemple ci-dessus, nous effectuons un calcul de la valeur vie par utilisateur à l'aide de la fonction order_items Explorer. Dans la table de sortie, total_revenue est vraiment la lifetime_customer_value du client.
La déclaration column permet de déclarer un nom de sortie différent du champ de saisie. Par exemple, le code ci-dessous indique "Créer une colonne de sortie nommée lifetime_value à partir du champ order_items.total_revenue":
column: lifetime_value {
field: order_items.total_revenue
}
Noms de colonnes implicites
Si le paramètre field est omis d'une déclaration de colonne, il est défini sur <explore_name>.<field_name>. Par exemple, si vous avez spécifié explore_source: order_items,
column: user_id {
field: order_items.user_id
}
équivaut à
column: user_id {}
Création de colonnes dérivées pour des valeurs calculées
Vous pouvez ajouter des paramètres derived_column afin de spécifier des colonnes qui n'existent pas dans la colonne Explorer du paramètre explore_source. Chaque paramètre derived_column comporte un paramètre sql qui indique comment construire la valeur.
Votre calcul sql peut utiliser n'importe quelle colonne que vous avez spécifiée à l'aide des paramètres column. Les colonnes dérivées ne peuvent pas inclure de fonctions d'agrégation, mais peuvent en revanche contenir des calculs réalisables sur une seule ligne de la table.
L'exemple ci-dessous génère la même table dérivée que la précédente, sauf qu'elle ajoute une colonne average_customer_order calculée, qui est calculée à partir des colonnes lifetime_customer_value et lifetime_number_of_orders de la table dérivée native.
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: lifetime_number_of_orders {
field: order_items.order_count
}
column: lifetime_customer_value {
field: order_items.total_revenue
}
derived_column: average_customer_order {
sql: lifetime_customer_value / lifetime_number_of_orders ;;
}
}
}
# Define the view's fields as desired
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
dimension: average_customer_order {
type: number
}
}
Utilisation des fonctions de fenêtrage SQL
Certains dialectes de base de données prennent en charge les fenêtrages, en particulier pour créer des numéros de séquence, des clés primaires, des totaux cumulés et cumulés, ainsi que d'autres calculs multilignes utiles. Après l'exécution de la requête principale, toutes les déclarations derived_column sont exécutées dans un cycle distinct.
Si votre dialecte de base de données prend en charge les fonctions de fenêtrage, vous pouvez les utiliser dans votre table dérivée native. Créez un paramètre derived_column avec un paramètre sql contenant le fenêtrage souhaité. Pour référencer ces valeurs, vous devez utiliser le nom de colonne défini dans la table dérivée native.
L'exemple ci-dessous crée une table dérivée native qui inclut les colonnes user_id, order_id et created_time. Ensuite, à l'aide d'une colonne dérivée avec un fenêtrage SQL ROW_NUMBER(), il calcule une colonne contenant le numéro de séquence d'une commande d'un client.
view: user_order_sequences {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: order_id {
field: order_items.order_id
}
column: created_time {
field: order_items.created_time
}
derived_column: user_sequence {
sql: ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_time) ;;
}
}
}
dimension: order_id {
hidden: yes
}
dimension: user_sequence {
type: number
}
}
Ajout de filtres à une table dérivée native
Supposons que nous voulions créer une table dérivée de la valeur d'un client au cours des 90 derniers jours. Nous souhaitons effectuer les mêmes calculs que ci-dessus, mais en ne tenant compte que des achats effectués au cours des 90 derniers jours.
Nous ajoutons simplement un filtre à derived_table qui filtre les transactions des 90 derniers jours. Le paramètre filters d'une table dérivée utilise la même syntaxe que celle que vous utilisez pour créer une mesure filtrée.
view: user_90_day_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: number_of_orders_90_day {
field: order_items.order_count
}
column: customer_value_90_day {
field: order_items.total_revenue
}
filters: [order_items.created_date: "90 days"]
}
}
# Add define view's fields as desired
dimension: user_id {
hidden: yes
}
dimension: number_of_orders_90_day {
type: number
}
dimension: customer_value_90_day {
type: number
}
}
Les filtres sont ajoutés à la clause WHERE lorsque Looker écrit le code SQL pour la table dérivée.
De plus, vous pouvez utiliser le sous-paramètre dev_filters de explore_source avec une table dérivée native. Le paramètre dev_filters vous permet de spécifier des filtres que Looker applique uniquement aux versions de développement de la table dérivée. Vous pouvez ainsi créer des versions filtrées plus petites de la table à itérer et tester sans attendre que la table complète soit créée après chaque modification.
Le paramètre dev_filters fonctionne conjointement avec le paramètre filters. Ainsi, tous les filtres sont appliqués à la version de développement de la table. Si dev_filters et filters spécifient des filtres pour la même colonne, dev_filters prévaut pour la version de développement de la table.
Pour en savoir plus, consultez Travailler plus rapidement en mode développement.
Utilisation de filtres basés sur un modèle
Vous pouvez utiliser bind_filters pour inclure des filtres modélisés:
bind_filters: {
to_field: users.created_date
from_field: filtered_lookml_dt.filter_date
}
Cela revient à utiliser le code suivant dans un bloc sql:
{% condition filtered_lookml_dt.filter_date %} users.created_date {% endcondition %}
to_field est le champ auquel le filtre est appliqué. to_field doit être un champ de explore_source.
from_field spécifie le champ à partir duquel obtenir le filtre, s'il existe un filtre au moment de l'exécution.
Dans l'exemple bind_filters ci-dessus, Looker utilise tous les filtres appliqués au champ filtered_lookml_dt.filter_date et les applique au champ users.created_date.
Vous pouvez également utiliser le sous-paramètre bind_all_filters de explore_source pour transmettre tous les filtres d'exécution d'une exploration à une sous-requête de table dérivée native. Pour en savoir plus, consultez la page de documentation sur le paramètre explore_source.
Tri et limitation des tables dérivées natives
Vous pouvez également trier et limiter les tables dérivées si vous le souhaitez:
sorts: [order_items.count: desc]
limit: 10
N'oubliez pas qu'une exploration peut présenter les lignes dans un ordre différent de l'ordre de tri sous-jacent.
Conversion de tables NDT dans différents fuseaux horaires
Vous pouvez spécifier le fuseau horaire de votre table dérivée native à l'aide du sous-paramètre timezone:
timezone: "America/Los_Angeles"
Lorsque vous utilisez le sous-paramètre timezone, toutes les données temporelles de la table dérivée native sont converties au fuseau horaire spécifié. Consultez la page de documentation sur les valeurs timezone pour obtenir la liste des fuseaux horaires acceptés.
Si vous ne spécifiez pas de fuseau horaire dans la définition de table dérivée native, la table dérivée native n'effectue aucune conversion de fuseau horaire sur les données basées sur l'heure et celles-ci sont définies par défaut sur le fuseau horaire de votre base de données.
Si la table dérivée native n'est pas persistante, vous pouvez définir la valeur de fuseau horaire sur "query_timezone" pour utiliser automatiquement le fuseau horaire de la requête en cours d'exécution.