予測を使用すれば、アナリストは新規または既存の Explore のクエリにデータ予測を迅速に追加して、ユーザーが特定のデータポイントを予測してモニタリングできるようにします。Explore の予測結果と可視化をダッシュボードに追加して、Looks として保存できます。予測結果と可視化は、埋め込み Looker コンテンツでも作成、表示できます。
予測を作成する権限があれば、データを予測できます。
予測結果の作成方法と表示方法
予測機能では、Explore のデータテーブルのデータ結果を使用して、将来のデータポイントを計算します。予測計算には、Explore クエリの結果として表示される結果のみが含まれます。行数の制限によって表示されない結果は含まれません。予測の計算に使用されるアルゴリズムの詳細については、このページの ARIMA アルゴリズムのセクションをご覧ください。
予測結果は既存の Explore の可視化の続きとして表示され、構成された可視化設定に従います。予測データポイントと非予測データポイントは、以下の点で区別されます。
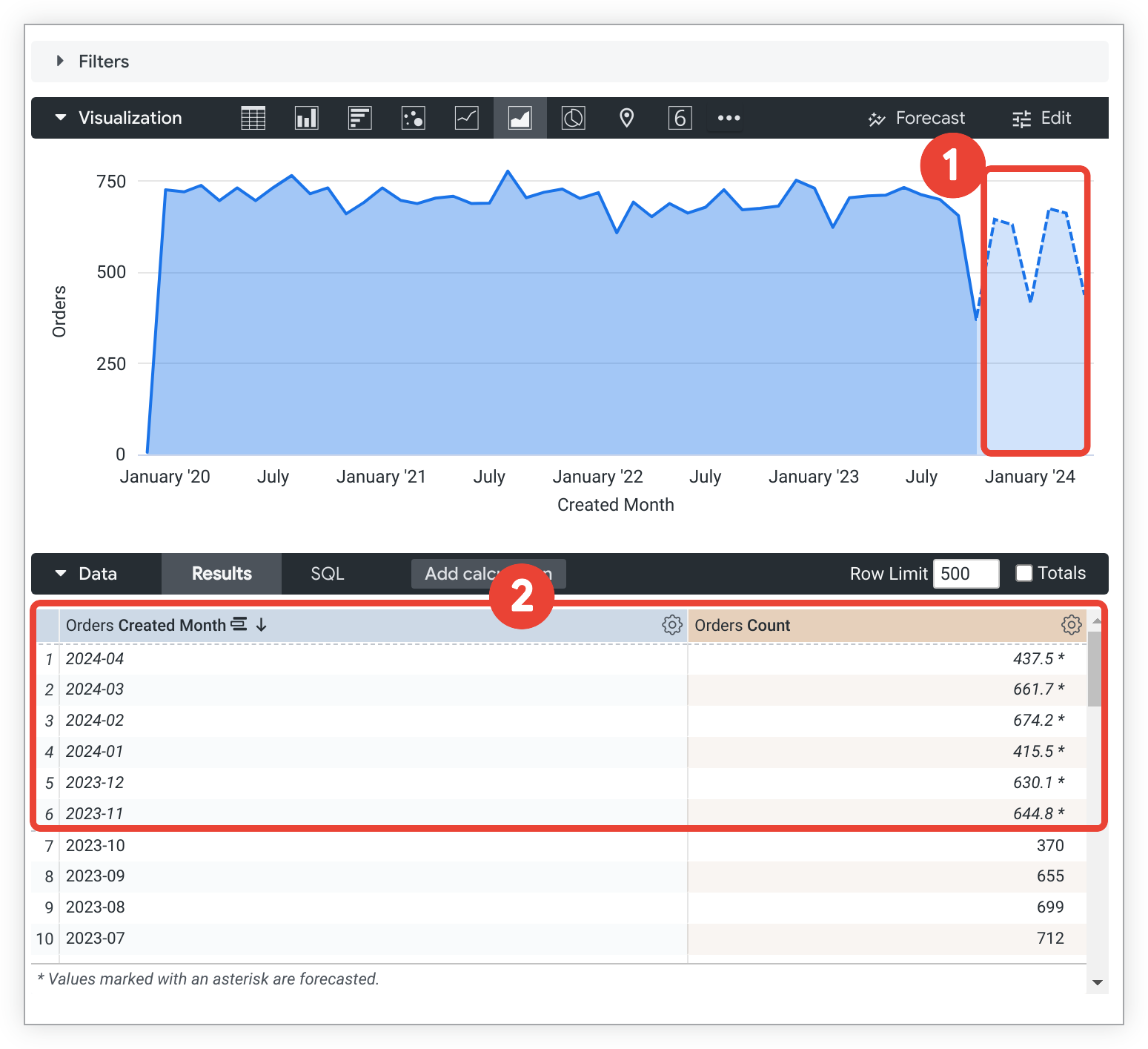
- サポート対象の直行座標のグラフでは、予測データポイントは、薄い影や破線でレンダリングされるため、非予測データポイントと区別されます。
- サポート対象のテキストと表グラフタイプでは、予測データポイントは斜体で表示され、アスタリスクが付いています。
予測データは、予測データポイントにカーソルを合わせたときに表示されるツールチップでも明示的に識別されます。

次のセクションで説明するように、予測データをサポートしているのは特定タイプの可視化だけです。
ARIMA アルゴリズム
予測では、自己回帰和分移動平均(ARIMA)アルゴリズムを利用して、予測に入力されたデータに最も適した方程式を作成します。Looker は、データに最適なものを見つけるために、一連の初期変数を使用して ARIMA を実行し、初期変数のバリエーションのリストを作成し、各バリエーションを使用して再度 ARIMA を実行します。いずれかのバリエーションで入力データにより適した方程式が作成されると、Looker はそのバリエーションを新しい初期変数として使用し、追加のバリエーションを作成して評価します。Looker は、最適な変数が特定されるまで、またはすべてのオプションまたは割り当てられたコンピューティング時間を使い切るまで、このプロセスを繰り返します。
このプロセスは遺伝子アルゴリズムと考えることができます。何百世代にわたって個体がそれぞれ 1~10 個の子(親に基づく変数のバリエーション)を作り、最も優れた子が生き残って「より良い」世代を作る可能性があります。Looker が遺伝的アルゴリズムのアプローチで ARIMA を何度も呼び出して使用する方法は、AutoARIMA と呼ばれています。AutoARIMA
AutoARIMA の詳細については、pmdarima ユーザーガイドの auto_arima を使用する際のヒントのセクションをご覧ください。これは、Looker が AutoARIMA の実行に使用するライブラリではありませんが、pmdarima では使用されるプロセスとさまざまな変数について最も適切に説明されています。
クロスフィルタリング対応のビジュアリゼーションタイプ
次の直交座標系の可視化タイプは、予測データのレンダリングをサポートしています。
次のテキストおよび表グラフタイプは、予測データのレンダリングがサポートしています。
現在、カスタム可視化など、その他の可視化タイプは予測データをレンダリングできません。
予測に必要なクエリの要件を調べる
予測をcreateするには、Explore が以下の要件を満たしている必要があります。
- タイムフレーム ディメンションである必要があり、ディメンション フィルを有効にしてディメンションを 1 つだけ含める
- 少なくとも 1 つの measure またはカスタム measure を含める(予測には最大 5 つの measure またはカスタム measure を含めることができる)
- 結果を期間のディメンションの降順で並べ替える
注意点
予測のために新しい Explore クエリを作成したり、既存の Explore クエリに予測を追加したりする際に考慮すべき追加の基準は以下のとおりです。
- ピボット - 前述の要件が満たされている限り、ピボットされた Explore で予測を実行できます。
- 行の合計と小計 - 行の合計と小計には、予測値は含まれません。予期しない結果が生じるおそれがあるため、予測では小計や行の合計の使用はおすすめしません。
- 不完全な期間を含むフィルタ - Explore に不完全な期間のデータが含まれている場合、正確な予測のためには、予測は Explore フィルタの完全な期間ロジックのみと組み合わせて使用する必要があります。たとえば、ユーザーが 1 か月間の将来データを予測していて、Explore が過去 3 か月間のデータをフィルタリングして表示した場合、Explore には現在の不完全な月のデータが含まれます。予測は不完全なデータを計算に組み込んで、信頼性の低い結果を表示します。代わりに、Explore に不完全な期間が含まれている場合(たとえば、Explore に当月の不完全な月次データが含まれている場合)、過去 3 か月間ではなく過去完全 3 か月間などのフィルタ ロジックを使用して、より正確な予測を確保します。
- テーブル計算 - 1 つ以上の予測 measure に基づくテーブル計算が自動的に予測に含まれます。
- 行数上限 - 予測行を含むデータテーブル全体に行数上限がどのように適用されるかを確認します。
その他のヒントやトラブルシューティングのリソースについては、このページの一般的な問題と注意事項のセクションをご覧ください。
一般的に、データセットの行数が多く、予測期間が短い組み合わせほど、予測の精度が向上します。
[予測] メニュー オプション
[Visualization] タブの [Forecast] メニューにあるオプションを使用して、予測データをカスタマイズできます。[Forecast] メニューには、次のオプションがあります。
フィールドを選択
[フィールドを選択] プルダウン メニューには、予測で使用できる Explore クエリの measure またはカスタム measure が表示されます。最大 5 つの measure またはカスタム measure を選択できます。
長さ
[Length] オプションは、データ値を予測する行数または時間の長さを示します。予測期間の間隔は、Explore クエリのタイムフレーム ディメンションに基づいて自動的に入力されます。
一般的に、データセットの行数が多く、予測期間が短い組み合わせほど、予測の精度が向上します。
予測間隔
[Prediction Interval] オプションを使用すると、アナリストは予測精度を高めるために、不確実性をある程度表現できます。有効にした場合、[Prediction Interval] オプションを使用して予測データ値の境界を選択できます。たとえば、予測間隔が 95% の場合、予測 measure 値が予測の上限と下限の間にある可能性が 95% であることを示します。
選択した予測間隔が大きくなるほど、上限と下限の幅は広くなります。
季節性
[Seasonality] オプションを使用すると、アナリストは予測において既知のサイクルや反復的なデータトレンドを考慮できます。これは、サイクルにおけるデータの行数を表します。たとえば、Explore データテーブルが 1 時間あたり 1 行で、データが毎日周期である場合、時期による変動は 24 です。
デフォルトの予測設定では、Looker は Explore の日付ディメンションを参照し、可能性のある時期による変動のサイクルをいくつかスキャンして、最終予測に最適なものを見つけます。たとえば、毎時データを使用する際、Looker は毎日、毎週、4 週間の時期による変動サイクルを試す可能性があります。Looker では、ディメンションの頻度も考慮されています。ディメンションが 6 時間の期間を表している場合、Looker は 1 日に 4 行しか存在しないことを認識し、それに応じて時期による変動を調整します。
一般的なユースケースでは、[Automatic] オプションを使用して、特定のデータセットに最適な時期による変動を検出します。データセット内の特定のサイクルがわかっている場合は、[カスタム] オプションを使用して、予測の個々のメジャーのサイクルを構成する行数を指定できます。
複数のメジャーのデータ値を予測する場合は、個別のメジャーごとに異なる時期による変動オプション(なしを含む)を選択できます。[Seasonality] プルダウン メニューには次の複数のオプションがあります。
[Seasonality] オプションが有効になっていない場合でも、予測では [Automatic] 時期による変動オプションがデフォルトで予測に適用されます。
自動
[Automatic] 時期による変動オプションを使用すると、Looker は日単位、時間単位、月単位など、複数の一般的な時期による変動の期間からデータに最適なオプションを選択します。
カスタム
データセット内のそれぞれのシーズンまたはサイクルを構成する特定の行数がわかっている場合は、[Period] フィールドにその数を指定できます。データが特定の行数で循環することがわかっている場合は、[カスタム] を選択すると便利な場合があります。
月単位で循環するデータを扱っていて、より細かい粒度で表現する場合(たとえば、Explore で日付や週の粒度を使用)、一般的に 4 週または 30 日の期間が月単位のサイクルに適合します。
なし
時期による変動は予測の重要な要素です。ただし、入力データによっては、必ずしも推奨されるわけではありません。データに予測可能なサイクルがない場合、時期による変動を有効にすると、アルゴリズムがパターンを見つけようとして誤ったパターンを予測に適合しようとし、不正確な予測につながることがあります。そのため、不明瞭な予測が発生する可能性があります。
複数の measure のデータ値を予測していて、1 つまたはいくつかの measure に対してのみ時期による変動を有効にしたい場合、時期による変動を有効にしたくないすべての measure に対してなしを選択できます。
予測の作成
権限を持つユーザーだけが予測を作成できます。
予測を作成する手順は次のとおりです。
Explore が予測の要件を満たしていることを確認します。たとえば、ユーザーが、[Users Created Month] ごとに降順で並べ替えられた [Users Created Month]、[Users Count]、[Orders Count] を使用して、Explore クエリの予測を作成するとします。結果には 2019 年 12 月までのデータが表示されます。
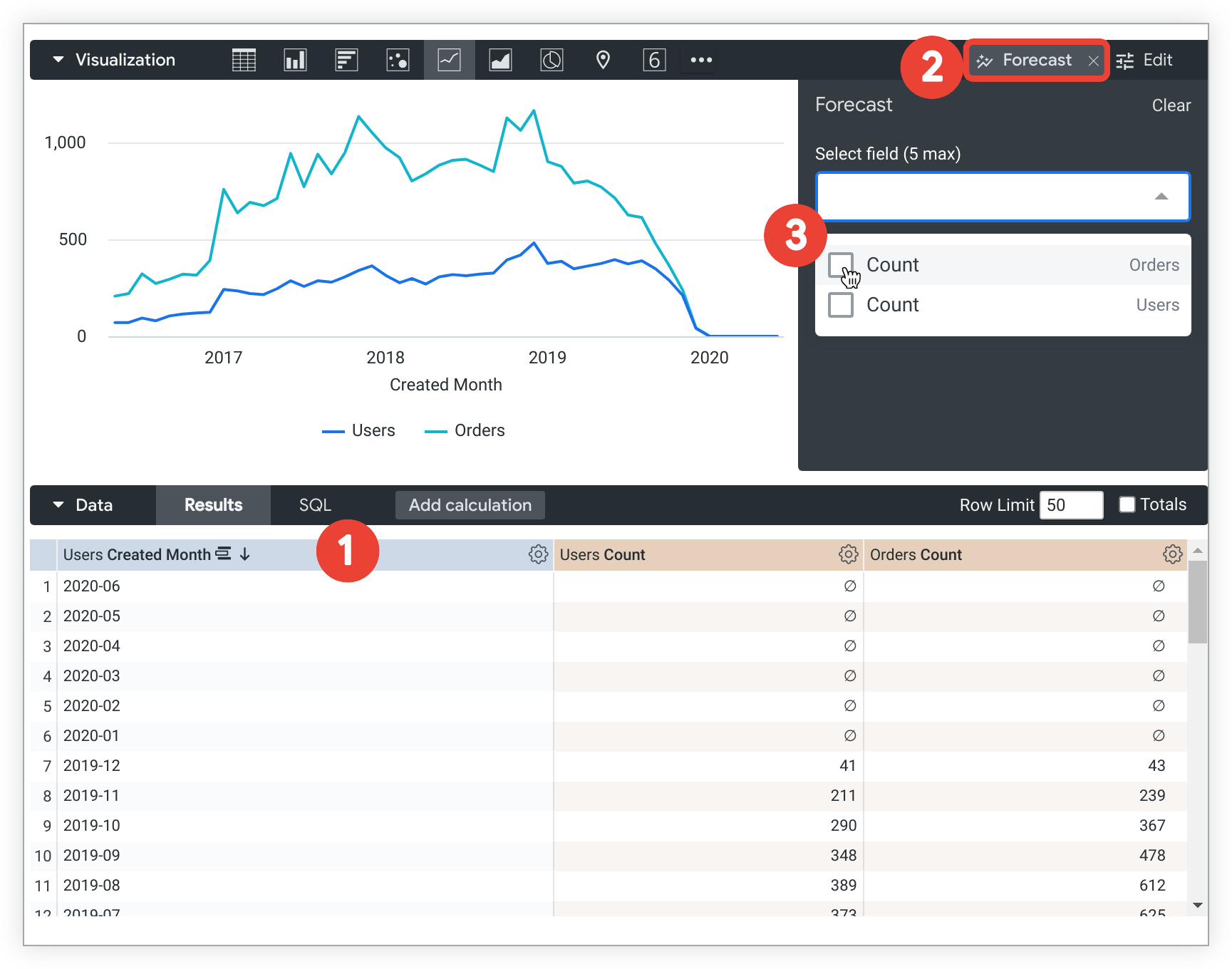
Explore の [Visualization] タブで [Forecast] をクリックして、[Forecast] メニューを開きます。
[フィールドを選択] プルダウン メニューをクリックして、予測する measure またはカスタム measure を 5 つまで選択します。この例のユーザーは、[Users Count] と [Orders Count] を選択します。
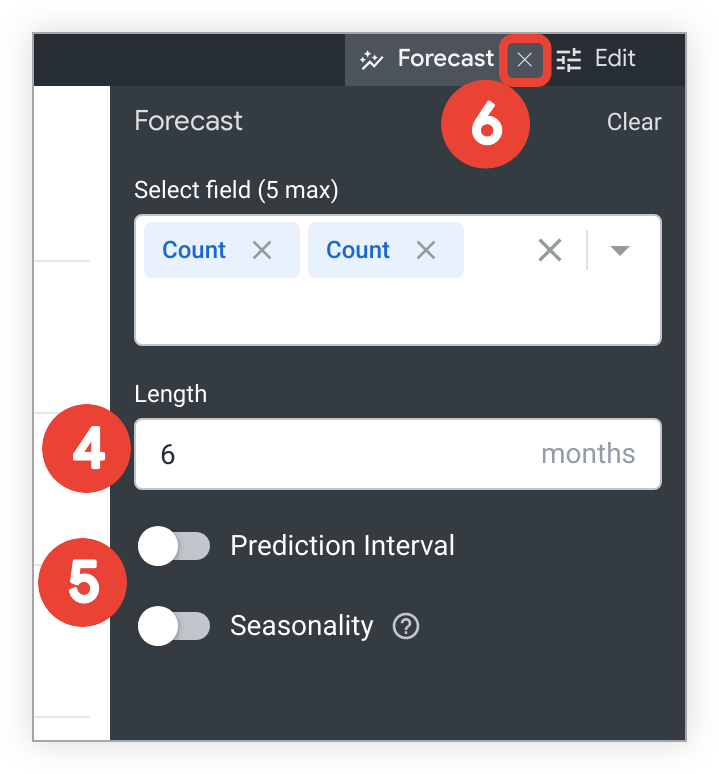
[Length] フィールドに、今後予測する時間の長さを入力します。この例のユーザーは「6」月と入力します。
必要に応じて、[Prediction Interval] または [Seasonality] スイッチをクリックして、どちらかの機能を有効にし、関連するオプションをカスタマイズします。この例のユーザーは、どちらのオプションも有効にしていません。
[x] の横にあるメニュータブで x をクリックして、設定を保存し、メニューを終了します。
[Run] をクリックして Explore クエリを再実行します(予測に変更を加えた場合は、Explore を再実行する必要があります)。
Explore の結果と可視化に、指定された期間の予測値が表示されるようになりました。指定したオプションで、サンプルの Explore に [Users Count] と [Orders Count] の 2020-01 から 2020-06 までの 6 か月間の予測データが表示されます。
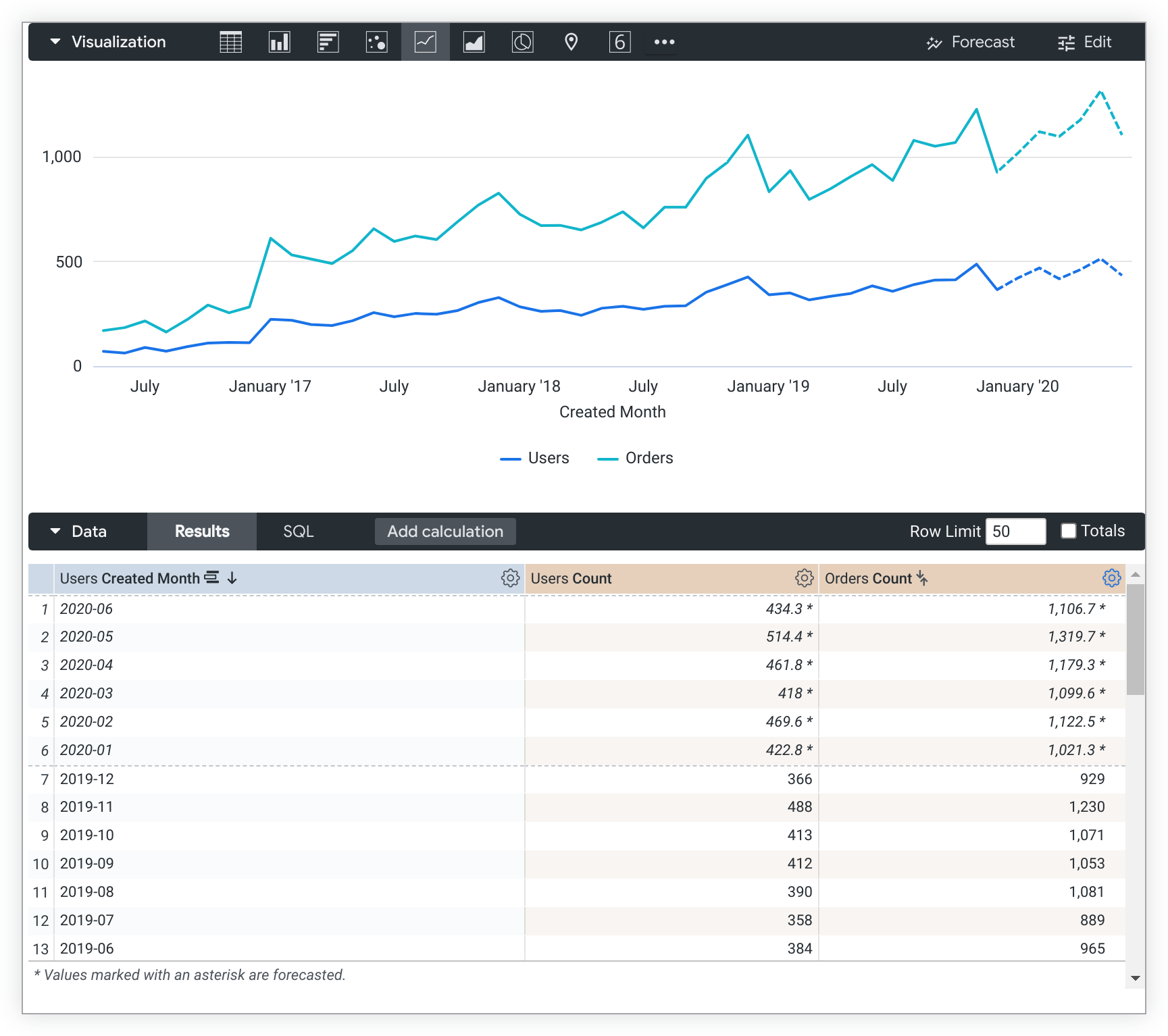
予測の計算はデータの並べ替え順序に依存するため、予測クエリを実行すると、並べ替えは無効になります。
予測の編集
権限を持つユーザーのみが予測を編集できます。
予測を編集するには:
- 必要に応じて Explore クエリを編集し、さまざまな measure や期間フィールドを追加または削除します。Explore が予測の要件を満たしていることを確認します。
- Explore の [Visualization] タブで [Forecast] をクリックして、[Forecast] メニューを開きます。
- [フィールドを選択] プルダウン メニューをクリックして、予測フィールドを変更します。予測フィールドを削除するには:
- 展開した [フィールドを選択] プルダウン メニューで、予測フィールドの横にあるチェックボックスをオンにして、予測からフィールドを削除します。
- または、折りたたまれている [x] メニューのフィールド名の横にある x をクリックします。
- 必要に応じて、[Length] フィールドで、指定した将来の時間の長さを編集して予測を行います。
- 必要に応じて、[Prediction Interval] または [Seasonality] スイッチをクリックして、どちらかの機能を有効にし、関連するオプションをカスタマイズします。
- [Prediction Interval] または [Seasonality] のいずれかがすでに有効になっている場合は、カスタムが表示されます。必要に応じてカスタム設定を編集するか、スイッチを選択して予測から関数を削除します。
- [x] の横にあるメニュータブで x をクリックして、設定を保存し、メニューを終了します。
- [Run] をクリックして Explore クエリを再実行します(予測に変更を加えた場合は、Explore を再実行する必要があります)。
Explore の結果と可視化に、修正された予測が表示されるようになりました。予測の計算はデータの並べ替え順序に依存するため、予測クエリを実行すると、並べ替えは無効になります。
予測の削除
予測を削除できるのは、権限を持つユーザーのみです。
Explore からフィールドを削除するには:
- Explore の [Visualization] タブで [Forecast] をクリックして、[Forecast] メニューを開きます。
- [Forecast] メニューの上部にある [Clear] をクリックします。
クエリが自動的に再実行され、予測が適用されずに結果が生成されます。
一般的な問題と注意事項
予測の正確さ
予測の精度は入力データによって異なります。Looker の AutoARIMA を実装すると、非常に正確な予測が可能になり、入力データのさまざまなニュアンスを適切に組み合わせることができます。アルゴリズムが入力データの奇妙なパターンにとらわれて、それを過度に強調して予測するケースもあります。予測から最大限の効果を得るために、十分なデータが提供され、データが可能な限り正確であることを確認します。
予測を生成できなかった
予測を生成できなくても仕方がない場合があります。これは通常、入力データの量が少なすぎるか、リクエストした予測の期間が長すぎる場合に発生します。どちらの要因にも特に目安があるわけではありません。また、特定の予測期間に対して必要な入力データについての正確な比率はありません。入力データが散在化し、予測不能になればなるほど、AutoARIMA アルゴリズムで一致を検出するのが難しくなります。予測を生成する最も効果的な方法は、クリーンな入力データの量を増やして時期による変動の設定が正しいことを確認し、予測の期間を必要な範囲にのみ短縮することです。[Prediction Interval] オプションを使用する場合は、より短い間隔を選択することをおすすめします。
入力データのクリーニングには、以下のようなものがあります。
- データが含まれていない期間を対象に、先頭部分または末尾部分の行をカットする
- より大きな日付ディメンションを選択してデータセット内のノイズを減らす
- 予測にメリットがないフィルタの外れ値を変更する
予測なしでクエリ結果が返され、不明瞭なエラーが発生した
これは本来発生しないはずです。発生する場合は、予測の構成からその measure を削除してから、再度追加してみてください。
予測が表示されるものの、明らかに間違っている、または有用性がない
この場合、より多くの入力データを追加し、可能な限りクリーンアップし、将来的な可能性も含めてカスタムの時期による変動を設定するか(データの特定のサイクルがわかっている場合)、[なし] を選択することで、[Seasonality] オプションを完全に無効にすることが最適です。
入力データのクリーニングには、次のようなタスクが含まれます。
- データが含まれていない期間を対象に、先頭部分または末尾部分の行をカットする
- より大きな日付ディメンションを選択してデータセット内のノイズを減らす
- 予測にメリットがないフィルタの外れ値を変更する