Una vez que hayas protegido y configurado tu base de datos, podrás conectarla a Looker.
Crea una conexión de base de datos en Looker en la página Conecta tu base de datos a Looker. Hay dos formas de abrir la página Conecta tu base de datos a Looker:
- En la sección Base de datos del panel Administración, selecciona Conexiones. En la página Conexiones, haz clic en el botón Añadir conexión.
- En el panel de navegación de la izquierda, haga clic en el botón Crear y, a continuación, seleccione el elemento de menú Conexión.
Para obtener más información sobre cómo aplicar atributos de usuario a los ajustes de conexión, consulta la sección Conexiones de la página de documentación Atributos de usuario.
En esta página se describen los campos habituales que Looker muestra en la página Conecta tu base de datos a Looker. Los campos exactos que se muestran en la página dependen del ajuste de dialecto.
Haz clic aquí para ver los enlaces a las instrucciones específicas de dialecto en la documentación de Looker.
- Actian Avalanche
- AlloyDB for PostgreSQL
- Amazon Aurora PostgreSQL
- Amazon Athena
- Amazon Aurora MySQL
- Amazon RDS para MySQL
- Amazon RDS para PostgreSQL
- Amazon Redshift
- Apache Druid
- Apache Hive 2.3 y 3.1.2 (o versiones posteriores)
- Apache Spark 3 o versiones posteriores
- ClickHouse
- Cloudera Impala 3.1 o versiones posteriores
- Databricks
- DataVirtuality
- Denodo
- Dremio
- Exasol
- SQL antiguo de Google BigQuery
- SQL estándar de Google BigQuery
- Google Cloud SQL para MySQL
- Google Cloud SQL para PostgreSQL
- Google Spanner
- Greenplum
- IBM DB2 en AS400
- IBM DB2 en LUW
- MariaDB
- Microsoft Azure Synapse Analytics
- Microsoft Azure SQL Database
- Microsoft Azure PostgreSQL
- Microsoft SQL Server (MSSQL)
- Conector de MongoDB para BI
- MySQL
- Oracle
- Oracle ADWC
- PostgreSQL
- PrestoDB
- SAP HANA
- SingleStore (antes MemSQL)
- Copo de nieve
- Teradata
- Trino
- Vector
- Vertica
Una vez que hayas introducido los ajustes de conexión de la base de datos, puedes seleccionar el botón Probar en la página Conectar tu base de datos a Looker para probar la conexión y asegurarte de que está configurada correctamente. Haz clic en Probar para verificar que la conexión se ha establecido correctamente. Consulta la página de documentación Probar la conectividad de la base de datos para obtener información sobre cómo solucionar problemas. Si Looker muestra Se puede conectar, pulsa Conectar para crear la conexión. La conexión de la base de datos se añade a la lista de la página de administración Conexiones de Looker.
Configuración general
Nombre
El nombre de la conexión tal como quieres que se muestre. Necesitas este nombre de conexión de base de datos para usarlo en el parámetro connection de tu modelo LookML. El nombre de la conexión de la base de datos también es la forma en que se identifica la conexión en la página Conexiones Administrar de Looker. No uses el nombre de ninguna carpeta en este ajuste. Este valor no tiene que coincidir con ningún elemento de tu base de datos. Name es una etiqueta que identifica esta conexión en la interfaz de usuario de Looker.
Ámbito de la conexión
Selecciona si la conexión se podrá usar con todos los proyectos o solo con uno:
- Todos los proyectos: todos los proyectos de LookML de la instancia pueden tener acceso a la conexión, por lo que el nombre de la conexión se puede especificar en el parámetro
connectionde los archivos de modelo de ese proyecto. - Proyecto seleccionado: solo un proyecto de LookML de la instancia puede tener acceso a la conexión. Si seleccionas esta opción, en la pantalla Conexión se mostrará un menú desplegable con los proyectos de la instancia. Selecciona el proyecto que puede tener acceso a esta conexión.
Usa esta opción junto con los siguientes permisos para delegar la gestión de conexiones y la configuración de modelos:
Dialecto
El dialecto SQL que coincida con tu conexión. Es importante elegir el valor correcto para que se le muestren las opciones de conexión adecuadas y para que Looker pueda traducir correctamente su LookML a SQL.
ID de proyecto de facturación
En el caso de las conexiones de Google BigQuery, el ID de proyecto de facturación es el Google Cloud ID de proyecto.
Host
El nombre de host de la base de datos que Looker debe usar para conectarse al host de la base de datos.
Si has trabajado con un analista de Looker para configurar un túnel SSH en tu base de datos, introduce "localhost" en el campo Host.
Puerto
El puerto de la base de datos que debe usar Looker para conectarse al host de la base de datos.
Si has trabajado con un analista de Looker para configurar un túnel SSH en tu base de datos, en el campo Puerto, introduce el número de puerto que redirige a tu base de datos. Tu analista de Looker debería haberte proporcionado este número.
Base de datos
El nombre de la base de datos de tu host. Por ejemplo, puede tener un nombre de host my-instance.us-east-1.redshift.amazonaws.com en el que haya una base de datos llamada sales_info. En este campo, introducirías sales_info. Si tienes varias bases de datos en el mismo host, es posible que tengas que crear varias conexiones para usarlas (excepto en MySQL, donde la palabra base de datos tiene un significado ligeramente diferente al de la mayoría de los dialectos de SQL).
Esquema
Es el esquema predeterminado que usa Looker cuando no se especifica ninguno. Esto se aplica cuando usas SQL Runner, durante la generación de proyectos de LookML y cuando consultas tablas.
Autenticación
En el caso de las conexiones de Google BigQuery, Snowflake, Trino y Databricks, seleccione el tipo de autenticación que quiera que use Looker para acceder a su base de datos:
- En el caso de las conexiones de Google BigQuery, puede configurar OAuth o una cuenta de servicio para que Looker la use para autenticarse en su base de datos.
- En el caso de las conexiones de Snowflake, Trino y Databricks, puedes configurar OAuth o una cuenta de base de datos para que Looker la use para autenticarse en tu base de datos.
Cuando usas OAuth, tus usuarios deben iniciar sesión en tu base de datos para enviar consultas desde Looker. Para obtener más información sobre cómo configurar OAuth en una conexión a Looker, consulta los procedimientos de conexión de Google BigQuery, Snowflake, Trino o Databricks.
Nombre de usuario
El nombre de usuario de una cuenta de usuario de tu base de datos que Looker puede usar para conectarse a ella.
Contraseña
La contraseña de una cuenta de usuario de tu base de datos que Looker puede usar para conectarse a ella.
Ajustes opcionales
Servidor SSH
La opción Servidor SSH solo está disponible si la instancia se ha implementado en la infraestructura de Kubernetes y si se ha habilitado la opción de añadir información de configuración del servidor SSH a tu instancia de Looker. Si esta opción no está habilitada en tu instancia de Looker y quieres habilitarla, ponte en contacto con un Google Cloud especialista de ventas o abre una solicitud de asistencia.
El servidor SSH elige automáticamente el puerto del host local y no se puede especificar. Si necesitas crear una conexión SSH que requiera que especifiques un puerto localhost, abre una solicitud de asistencia.
Para conectarte a tu base de datos mediante un túnel SSH, activa el interruptor y selecciona una configuración de servidor SSH en la lista desplegable.
Puerto local
De forma predeterminada, Looker selecciona automáticamente un puerto local disponible para el túnel SSH. Para elegir manualmente un puerto local, selecciona Entrada manual e introduce un número de puerto en el campo Puerto local personalizado. Asegúrate de que el puerto local esté disponible en tu instancia.
Tablas derivadas persistentes (PDTs)
Habilitar PDTs
Activa el interruptor Habilitar PDTs para habilitar las tablas derivadas persistentes. Cuando las PDTs están habilitadas, la ventana Conexión muestra campos de PDT adicionales y la sección Sustituciones de PDT. Looker muestra el interruptor Habilitar PDTs solo si el dialecto de la base de datos admite el uso de PDTs.
Ten en cuenta lo siguiente sobre los PDTs:
- No se admiten PDTs en las conexiones de Snowflake que usan OAuth.
- Si inhabilitas las PDTs en una conexión, no se inhabilitarán los grupos de datos asociados a tus PDTs. Aunque inhabilite los PDTs, los grupos de datos seguirán ejecutando sus consultas
sql_triggeren la base de datos. Si quieres evitar que un grupo de datos ejecute su consultasql_triggeren tu base de datos, debes eliminar o comentar el parámetrodatagroupde tu proyecto de LookML. También puedes actualizar el ajuste Mantenimiento de grupos de datos y PDTs de la conexión para que Looker compruebe los PDTs y los grupos de datos con muy poca frecuencia o nunca. - En las conexiones de Snowflake, Looker asigna el valor
TRUE(el valor predeterminado de Snowflake) al parámetroAUTOCOMMIT.AUTOCOMMITes obligatorio para los comandos SQL que ejecuta Looker para mantener su sistema de registro de PDTs.
Base de datos temporal
Aunque se llama Base de datos temporal, debes introducir el nombre de la base de datos o el nombre del esquema (según corresponda a tu dialecto de SQL) que Looker debe usar para crear tablas derivadas persistentes. Debes configurar esta base de datos o esquema con antelación y con los permisos de escritura adecuados. En la página de documentación Instrucciones de configuración de la base de datos, seleccione el dialecto de su base de datos para ver las instrucciones correspondientes.
Cada conexión debe tener su propia base de datos temporal o esquema. No se pueden compartir entre conexiones.
Número máximo de conexiones de compilación de PDT
El ajuste Número máximo de conexiones del creador de PDTs le permite especificar cuántas compilaciones de tablas simultáneas puede iniciar el regenerador de Looker en su conexión de base de datos. El ajuste Número máximo de conexiones del creador de PDTs solo se aplica a los tipos de tablas para los que el regenerador de Looker inicia recompilaciones:
- Tablas con activador de persistencia (tablas derivadas persistentes y tablas agregadas que usan la estrategia de persistencia
datagroup_triggerosql_trigger_value). - Tablas persistentes que usan la estrategia
persist_for, pero solo cuando la tablapersist_forforma parte de una cascada de tablas derivadas en la que depende de una tabla que usa la estrategia de persistenciadatagroup_triggerosql_trigger_value. En este caso, el regenerador de Looker volverá a compilar una tablapersist_for, ya que se necesita para volver a compilar otra tabla en cascada. De lo contrario, el regenerador no iniciará compilaciones para las tablaspersist_for.
El valor predeterminado de Número máximo de conexiones del creador de PDT es 1, pero puede ser de hasta 10. Sin embargo, el valor no puede ser superior al valor definido en el campo Conexiones máximas por nodo ni al valor de per-user-query-limit definido en las opciones de inicio de Looker.
Asigne este valor con cuidado. Si el valor es demasiado alto, puede que sobrecargues tu base de datos. Si el valor es bajo, las PDTs de larga duración o las tablas agregadas pueden retrasar la creación de otras tablas persistentes o ralentizar otras consultas en la conexión. Las bases de datos que admiten multitenancy, como BigQuery, Snowflake y Redshift, pueden ofrecer un mejor rendimiento a la hora de gestionar compilaciones de consultas paralelas.
Si quieres aumentar el valor del ajuste Número máximo de conexiones del creador de PDTs, una buena práctica es aumentarlo en 1. Si se produce algún comportamiento inesperado, vuelve a definir el valor predeterminado 1. De lo contrario, si el rendimiento de las consultas no se ve afectado, puedes seguir aumentando el valor de forma incremental en 1 y verificar el rendimiento en cada incremento antes de aumentar aún más el valor.
Tenga en cuenta lo siguiente sobre el ajuste Número máximo de conexiones de compilación de PDT:
- El ajuste Número máximo de conexiones del creador de PDTs solo se aplica a las conexiones necesarias para reconstruir tablas, no a las conexiones necesarias para las comprobaciones de activadores. Una comprobación de activador es una consulta que comprueba si se activa la estrategia de persistencia de la tabla. Como estas consultas de comprobación de activador siempre se ejecutan de forma secuencial, no se aplica el ajuste Número máximo de conexiones de compilación de PDT.
- En una instancia de Looker en clúster, el regenerador solo se ejecuta en el nodo principal. El ajuste Número máximo de conexiones del creador de PDT solo se aplica al nodo principal y, por lo tanto, establece el límite para todo el clúster.
- El ajuste Número máximo de conexiones del creador de PDT no se aplica a los siguientes tipos de tablas. Estos tipos de tablas se crean de forma consecutiva:
- Tablas conservadas mediante el parámetro
persist_for(a menos que otras tablas dependan de ellas y utilicen las estrategiasdatagroup_triggerosql_trigger_value). - Tablas en modo Desarrollo.
- Tablas creadas de nuevo con la opción Reconstruir tablas derivadas y ejecutar.
- Tablas en las que una depende de otra en una cascada de dependencias. Una tabla no se puede compilar al mismo tiempo que otra de la que depende. Por ejemplo, si
table_Bdepende detable_A,table_Adebe terminar de recompilarse antes de quetable_Bpueda empezar a recompilarse.
- Tablas conservadas mediante el parámetro
Calendario de mantenimiento de Datagroup y PDT
El regenerador de Looker comprueba los grupos de datos y las tablas persistentes (tanto las tablas agregadas como las tablas derivadas persistentes) que se basan en sql_trigger_value. En función de estas comprobaciones, el regenerador de Looker vuelve a compilar o elimina las tablas persistentes del esquema de borrador de tu base de datos.
El valor Programación de mantenimiento de grupo de datos y PDT define el intervalo cron del regenerador de Looker. El regenerador de Looker inicia un ciclo de regeneración para comprobar los grupos de datos y las tablas persistentes en el intervalo cron. Si un ciclo de regeneración de Looker sigue en curso en el siguiente intervalo cron, el regenerador de Looker completará el ciclo de regeneración que esté en curso y, a continuación, esperará hasta el siguiente intervalo cron para iniciar el siguiente ciclo de regeneración.
El ajuste Horario de mantenimiento de grupos de datos y PDT acepta una expresión cron. El valor predeterminado es */5 * * * *, lo que significa que el ciclo del regenerador de Looker iniciará un ciclo en el intervalo de cinco minutos si el ciclo anterior del regenerador se ha completado. Si el ciclo de regeneración anterior no se ha completado, el regenerador de Looker se iniciará en el siguiente intervalo de cinco minutos después de que se complete el ciclo.
El valor predeterminado de cinco minutos también es el intervalo más frecuente admitido para Mantenimiento de grupos de datos y PDT. Looker no aplica un intervalo máximo para Mantenimiento de Datagroup y PDT, lo que significa que puedes ampliar el intervalo entre los ciclos del regenerador de Looker durante el tiempo que se pueda especificar con una expresión cron. Ten en cuenta que los ciclos de regeneración de Looker más largos pueden afectar negativamente a la actualización de los datos de tu caché y de tus tablas persistentes.
Una vez que el regenerador de Looker haya completado todas las comprobaciones y las compilaciones de PDT en un ciclo, esperará al siguiente intervalo cron para iniciar el siguiente ciclo. Si tienes compilaciones de PDT de larga duración, puede que haya largos periodos entre los ciclos del regenerador de Looker. Otros factores pueden afectar al tiempo necesario para volver a generar las tablas, tal como se describe en la sección Consideraciones importantes para implementar tablas persistentes de la página Tablas derivadas en Looker.
Si tu base de datos no está disponible las 24 horas, puedes limitar las comprobaciones a los momentos en los que esté activa. Aquí tienes algunas expresiones cron adicionales:
cron expresión |
Definición |
|---|---|
*/5 8-17 * * MON-FRI |
Comprobar los grupos de datos y los PDTs cada 5 minutos durante el horario de oficina, de lunes a viernes |
*/5 8-17 * * * |
Comprobar los grupos de datos y los PDTs cada 5 minutos durante el horario de apertura, todos los días |
0 8-17 * * MON-FRI |
Comprobar los grupos de datos y los PDTs cada hora durante el horario de oficina, de lunes a viernes |
1 3 * * * |
Comprobar los grupos de datos y los PDTs todos los días a las 3:01 |
Algunos aspectos que debes tener en cuenta al crear una expresión cron:
- Looker usa parse-cron v0.1.3, que no admite
?en expresionescron. - La expresión
cronusa la zona horaria de la aplicación de Looker para determinar cuándo se realizan las comprobaciones. - Si no se están compilando PDTs, vuelve a establecer el valor predeterminado de la cadena cron, que es
*/5 * * * *.
A continuación, se indican algunos recursos que pueden ayudarte a crear cadenas cron:
- https://crontab.guru: ayuda para editar y probar cadenas
cron. - http://www.crontab-generator.org: selecciona la configuración de hora y el generador creará la cadena
croncorrespondiente.
Reintentar compilaciones de PDT fallidas
El interruptor Reintentar compilaciones de PDT fallidas configura cómo intenta el regenerador de Looker volver a compilar las tablas persistentes activadas que han fallado en el ciclo anterior del regenerador. El regenerador de Looker es el proceso que vuelve a compilar las tablas persistentes activadas (PDTs y tablas conjuntas) según el intervalo configurado en el ajuste de conexión Datagroup and PDT Maintenance Schedule (Grupo de datos y programación de mantenimiento de PDT). Cuando el interruptor Reintentar compilaciones de PDT fallidas está habilitado, el regenerador de Looker intentará volver a compilar un PDT que haya fallado en el ciclo anterior del regenerador, aunque no se cumpla la condición de activación del PDT. Si este ajuste está inhabilitado, el regenerador de Looker intentará volver a compilar un PDT que no se haya podido compilar anteriormente solo cuando se cumpla la condición de activación del PDT. La opción Reintentar compilaciones de PDT fallidas está inhabilitada de forma predeterminada.
Consulta la página de documentación Tablas derivadas en Looker para obtener más información sobre el regenerador de Looker.
API Control de PDT
El interruptor Control de API de PDT determina si se pueden usar las llamadas a las APIs start_pdt_build, check_pdt_build y stop_pdt_build para esta conexión. Cuando el interruptor Control de API de PDT esté inhabilitado, se producirá un error en estas llamadas a la API cuando hagan referencia a PDTs en esta conexión. El interruptor Control de API de PDT está inhabilitado de forma predeterminada.
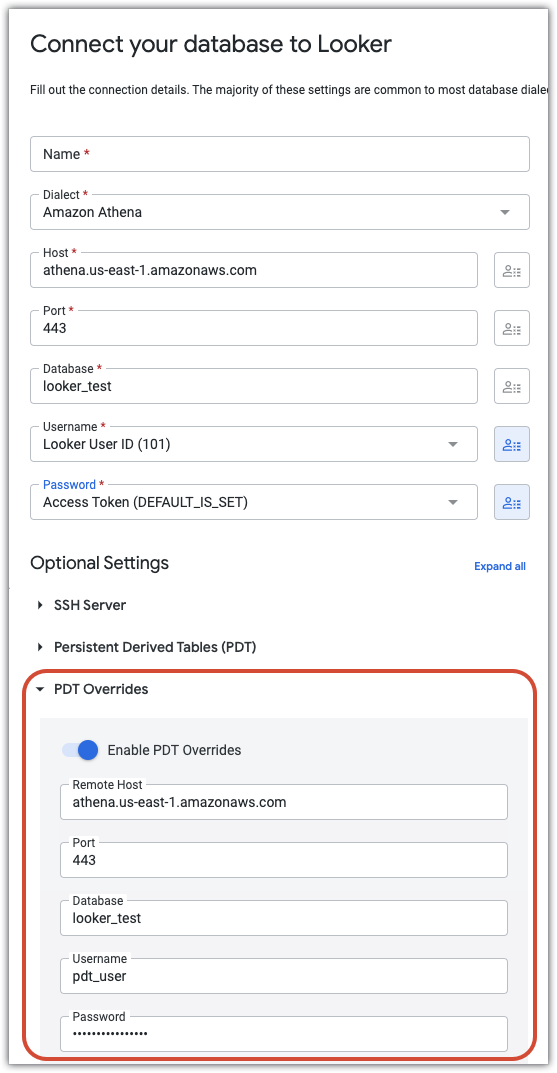
Anulaciones de PDT
Si tu base de datos admite tablas derivadas persistentes y has activado el interruptor Habilitar PDTs en los ajustes de conexión, Looker mostrará la sección Sustituciones de PDTs. En la sección Sustituciones de PDT, puede introducir parámetros JDBC independientes (host, puerto, base de datos, nombre de usuario, contraseña, esquema, parámetros adicionales e instrucciones posteriores a la conexión) que sean específicos de los procesos de PDT. Esto puede ser valioso por varios motivos:
- Si creas un usuario de base de datos independiente para los procesos de PDT, podrás usar PDTs en tu proyecto de Looker aunque asignes atributos de usuario a tus credenciales de inicio de sesión de la base de datos o uses OAuth para la conexión de la base de datos.
- Los procesos de PDT pueden autenticarse a través de un usuario de base de datos independiente que tenga una prioridad más alta. De esta forma, la base de datos puede priorizar los trabajos de PDT sobre las consultas de los usuarios menos importantes.
- Se puede revocar el acceso de escritura a la conexión de base de datos estándar de Looker y concederlo solo a un usuario especial que los procesos de PDT utilizarán para la autenticación. Esta es una estrategia de seguridad más adecuada para la mayoría de las organizaciones.
- En bases de datos como Snowflake, los procesos de PDT se pueden dirigir a hardware más potente que no se comparte con el resto de los usuarios de Looker. De esta forma, las PDTs se pueden compilar rápidamente sin incurrir en el coste de ejecutar hardware caro a tiempo completo.
Por ejemplo, en la siguiente configuración se muestra una conexión en la que los campos de nombre de usuario y contraseña se han definido como atributos de usuario. De esta forma, cada usuario puede acceder a la base de datos con sus credenciales individuales. En la sección Sustituciones de PDT se crea un usuario independiente (pdt_user) con su propia contraseña. La cuenta de pdt_user se usará en todos los procesos de PDT, con niveles de acceso adecuados para la creación y actualización de PDTs.
Zona horaria
Zona horaria de la base de datos
La zona horaria en la que su base de datos almacena la información basada en la hora. Looker necesita saberlo para poder convertir los valores de tiempo de los usuarios, lo que facilita la comprensión y el uso de los datos basados en el tiempo. Para obtener más información, consulta la página de documentación Usar la configuración de zona horaria.
zona horaria de consulta
La opción Zona horaria de la consulta solo está visible si has inhabilitado Zonas horarias específicas del usuario.
Cuando la opción Zonas horarias específicas de los usuarios está inhabilitada, la Zona horaria de la consulta es la zona horaria que se muestra a los usuarios cuando consultan datos basados en la hora, así como la zona horaria a la que Looker convertirá los datos basados en la hora de la Zona horaria de la base de datos.
Para obtener más información, consulta la página de documentación Usar la configuración de zona horaria.
Configuración adicional
Parámetros JDBC adicionales
Si es necesario, puede incluir parámetros adicionales de conectividad de bases de datos Java (JDBC) para sus consultas.
Para hacer referencia a un atributo de usuario en un parámetro JDBC, usa la sintaxis de plantillas Liquid: _user_attributes['name_of_attribute']. Por ejemplo:
my_jdbc_param={{ _user_attributes['name_of_attribute'] }}
Número máximo de conexiones por nodo
Aquí puedes definir el número máximo de conexiones que Looker puede establecer con tu base de datos. En la mayoría de los casos, se establece el número de consultas simultáneas que Looker puede ejecutar en tu base de datos. Looker también reserva hasta tres conexiones para finalizar consultas. Si el grupo de conexiones es muy pequeño, Looker reservará menos conexiones.
Asigne este valor con cuidado. Si el valor es demasiado alto, puede que sobrecargues tu base de datos. Si el valor es demasiado bajo, las consultas tendrán que compartir un número reducido de conexiones. Por lo tanto, es posible que los usuarios perciban que muchas consultas son lentas, ya que tienen que esperar a que se devuelvan otras consultas anteriores.
El valor predeterminado (que varía en función del dialecto de SQL) suele ser un buen punto de partida. La mayoría de las bases de datos también tienen sus propios ajustes para el número máximo de conexiones que aceptarán. Si la configuración de su base de datos limita las conexiones, asegúrese de que el valor de Conexiones máximas por nodo sea igual o inferior al límite de su base de datos.
Tiempo de espera de grupo de conexiones
Si tus usuarios solicitan más conexiones que el valor de Conexiones máximas por nodo, las solicitudes esperarán a que se completen otras antes de ejecutarse. Aquí se configura el tiempo máximo que esperará una solicitud. El valor predeterminado es 120 segundos.
Debes definir este valor con cuidado. Si es demasiado bajo, es posible que los usuarios vean cómo se cancelan sus consultas porque no hay tiempo suficiente para que finalicen las consultas de otros usuarios. Si es demasiado alto, se pueden acumular grandes cantidades de consultas, lo que provoca que los usuarios tengan que esperar mucho tiempo. El valor predeterminado suele ser un buen punto de partida.
Número máximo de consultas simultáneas para esta conexión
Este valor opcional limita el número de consultas simultáneas que Looker enviará a esta conexión de base de datos a la vez. Si llegan más solicitudes simultáneas que requieren la misma conexión, Looker las pondrá en cola internamente y las procesará por orden. Si se define este valor, se sobrescribirá el valor de Conexiones máximas por nodo.
Número máximo de consultas simultáneas por usuario para esta conexión
Este valor opcional limita el número de consultas simultáneas de un usuario que Looker enviará a esta conexión de base de datos a la vez. Si llegan más solicitudes simultáneas que requieren la misma conexión, Looker las pondrá en cola internamente y las procesará por orden.
SSL
Elige si quieres usar el cifrado SSL para proteger los datos mientras se transfieren entre Looker y tu base de datos. SSL es solo una de las opciones que se pueden usar para proteger tus datos. En la página de documentación Habilitar el acceso seguro a la base de datos se describen otras opciones seguras.
Verificar SSL
Elige si quieres requerir la verificación del certificado SSL que usa la conexión. Si se requiere verificación, la autoridad de certificación (CA) SSL que firmó el certificado SSL debe proceder de la lista de fuentes de confianza del cliente. Si la CA no es una fuente de confianza, no se establecerá la conexión con la base de datos.
Si esta casilla no está marcada, se sigue usando el cifrado SSL en la conexión, pero no es necesario verificar la conexión SSL, por lo que se puede establecer una conexión cuando la CA no está en la lista de fuentes de confianza del cliente.
Precaché de SQL Runner
En SQL Runner, toda la información de las tablas se carga previamente en cuanto seleccionas una conexión y un esquema. De esta forma, SQL Runner puede mostrar rápidamente las columnas de una tabla en cuanto haces clic en el nombre de la tabla. Sin embargo, en el caso de las conexiones y los esquemas con muchas tablas o con tablas muy grandes, puede que no quieras que SQL Runner precargue toda la información.
Si prefieres que SQL Runner cargue la información de las tablas solo cuando se selecciona una tabla, puedes desmarcar la opción Precaché de SQL Runner para inhabilitar la precarga de SQL Runner en la conexión.
Obtener el esquema de información para la escritura de SQL
En algunas funciones de escritura de SQL, como Conocimiento de agregaciones, Looker usa el esquema de información de tu base de datos para optimizar la escritura de SQL. Si el esquema de información no está almacenado en caché, es posible que Looker tenga que bloquear ocasionalmente la escritura de SQL en la base de datos para poder obtener el esquema de información. En el caso de los dialectos que usan Hadoop Distributed File System (HDFS), la obtención del esquema de información puede tardar lo suficiente como para afectar significativamente al rendimiento de las consultas de Looker. Si sabes que tu esquema de información es lento, puedes inhabilitar la opción Obtener esquema de información para escritura de SQL de tu conexión. Si inhabilita esta función, se impedirá que Looker optimice el código SQL de algunas funciones, por lo que debería habilitar la opción Obtener Information Schema para escribir código SQL, a menos que sepa que el Information Schema de su conexión es especialmente lento.
Estimación de costes
El interruptor Estimación de costes solo se aplica a las siguientes conexiones de bases de datos:
- Copo de nieve
- Amazon Redshift
- Amazon Aurora
- PostgreSQL, Google Cloud SQL para PostgreSQL y Microsoft Azure PostgreSQL
El interruptor Estimación de costes habilita las siguientes funciones en la conexión:
- Estimaciones de costes de las consultas de Exploración
- Estimaciones de costes de las consultas de SQL Runner
- Estimaciones del ahorro de computación en consultas de notoriedad total
Consulta la página de documentación Examinar los datos en Looker para obtener más información.
Grupo de conexiones de bases de datos
En el caso de los dialectos que admiten la agrupación de conexiones de bases de datos, esta función permite que Looker use grupos de conexiones a través del controlador JDBC. La agrupación de conexiones de bases de datos permite que las consultas se ejecuten más rápido, ya que no es necesario crear una conexión de base de datos nueva para cada consulta, sino que se puede usar una conexión del grupo de conexiones. La función de agrupación de conexiones asegura que una conexión se limpia después de la ejecución de una consulta y está disponible para volver a usarse cuando finaliza la ejecución de la consulta. Consulta la página de documentación Agrupación de conexiones de bases de datos para obtener más información.
Probar los ajustes de conexión
Puedes probar la configuración de la conexión desde dos lugares de la interfaz de Looker:
- Selecciona el botón Probar situado en la parte inferior de la página Configuración de conexiones.
- Seleccione el botón Probar situado junto a la conexión en la página de administración Conexiones, tal como se describe en la página de documentación Conexiones.
Una vez que hayas introducido los ajustes de conexión, haz clic en Probar para verificar que la información sea correcta y que la base de datos pueda conectarse.
Si tu conexión no supera una o varias pruebas, aquí tienes algunas opciones para solucionar el problema:
- Prueba algunos de los pasos para solucionar problemas que se indican en la página de documentación Probar la conectividad de la base de datos.
- Si usas la versión 3.6 o una anterior de Mongo en Atlas y se produce un error de enlace de comunicaciones, consulta la página de documentación sobre Mongo Connector.
- Para recibir mensajes de conexión correctos sobre el esquema temporal y los PDTs, debes permitir esa función al configurar tu base de datos de Looker. Puedes consultar las instrucciones para hacerlo en la página de documentación Instrucciones de configuración de la base de datos.
Si sigues teniendo problemas, abre una solicitud de asistencia.
Probar como usuario
Si ha asignado uno o varios valores de parámetros de conexión a un atributo de usuario, aparecerá la opción Hacer prueba como usuario. Selecciona un usuario y haz clic en Probar para verificar que la base de datos puede conectarse y ejecutar consultas como este usuario.
Pasos siguientes
Una vez que hayas conectado tu base de datos a Looker, podrás configurar las opciones de inicio de sesión de tus usuarios.