많은 Looker 고객은 사용자가 데이터 웨어하우스의 데이터를 보고하는 것뿐만 아니라 해당 데이터 웨어하우스에 실제로 다시 쓰고 업데이트할 수 있도록 지원하기를 원합니다.
Looker는 작업 API를 통해 모든 데이터 웨어하우스 또는 대상에 대해 이 사용 사례를 지원합니다. 이 문서 페이지에서는 Google Cloud 인프라를 사용하는 고객이 Cloud Run 함수에 솔루션을 배포하여 BigQuery에 다시 쓰는 방법을 안내합니다. 이 페이지에서는 다음 주제에 대해 설명합니다.
솔루션 고려사항
이 고려사항 목록을 사용하여 솔루션이 요구사항에 부합하는지 확인하세요.
- Cloud Run Functions
- Cloud Run Functions를 사용해야 하는 이유 Google의 '서버리스' 제품인 Cloud Run 함수는 운영 및 유지관리의 용이성을 위해 적합한 선택입니다. 고려해야 할 사항 중 하나는 지연 시간(특히 콜드 호출의 경우)이 전용 서버를 사용하는 솔루션보다 길 수 있다는 것입니다.
- 언어 및 런타임 Cloud Run Functions는 여러 언어와 런타임을 지원합니다. 이 문서 페이지에서는 JavaScript 및 Node.js의 예시에 중점을 둡니다. 하지만 개념은 지원되는 다른 언어와 런타임으로 직접 번역할 수 있습니다.
- BigQuery
- BigQuery를 사용해야 하는 이유 이 문서 페이지에서는 이미 BigQuery를 사용하고 있다고 가정하지만 BigQuery는 일반적으로 데이터 웨어하우스에 적합합니다. 다음 사항에 유의하세요.
- BigQuery Storage Write API: BigQuery는 SQL 기반 작업의 데이터 조작 언어 (DML) 문을 비롯하여 데이터 웨어하우스의 데이터를 업데이트하기 위한 여러 인터페이스를 제공합니다. 하지만 대량 쓰기에 가장 적합한 옵션은 BigQuery Storage Write API입니다.
- 업데이트가 아닌 추가: 이 솔루션은 행을 업데이트하지 않고 추가만 하지만, 쿼리 시점에 추가 전용 로그에서 '현재 상태' 테이블을 항상 파생하여 업데이트를 시뮬레이션할 수 있습니다.
- BigQuery를 사용해야 하는 이유 이 문서 페이지에서는 이미 BigQuery를 사용하고 있다고 가정하지만 BigQuery는 일반적으로 데이터 웨어하우스에 적합합니다. 다음 사항에 유의하세요.
- 지원 서비스
- Secret Manager: Secret Manager는 보안 비밀 값이 함수의 구성에 직접 저장되는 등 액세스하기 쉬운 위치에 저장되지 않도록 보안 비밀 값을 보유합니다.
- ID 및 액세스 관리 (IAM): IAM은 함수가 런타임에 필요한 보안 비밀에 액세스하고 의도한 BigQuery 테이블에 쓸 수 있도록 승인합니다.
- Cloud Build: 이 페이지에서는 Cloud Build에 대해 자세히 설명하지 않지만 Cloud Run Functions는 백그라운드에서 Cloud Build를 사용하며, Cloud Build를 사용하여 Git 저장소의 소스 코드 변경사항에서 함수로 지속적으로 배포되는 업데이트를 자동화할 수 있습니다.
- 작업 및 사용자 인증
- Cloud Run 서비스 계정 조직의 자체 퍼스트 파티 애셋 및 리소스와 통합하기 위해 Looker 작업을 사용하는 가장 쉽고 기본적인 방법은 Looker 작업 API의 토큰 기반 인증 메커니즘을 사용하여 Looker 인스턴스에서 전송되는 요청으로 인증한 다음 서비스 계정을 사용하여 BigQuery의 데이터를 업데이트하는 함수를 승인하는 것입니다.
- OAuth: 이 페이지에서 다루지 않는 또 다른 옵션은 Looker 작업 API의 OAuth 기능을 사용하는 것입니다. 이 방법은 더 복잡하며 일반적으로 필요하지 않지만, Looker의 액세스 권한이나 함수 코드 내의 임시 논리를 사용하는 대신 IAM을 사용하여 테이블에 쓰는 최종 사용자의 액세스 권한을 정의해야 하는 경우에 사용할 수 있습니다.
데모 코드 둘러보기
데모 작업의 전체 로직이 포함된 단일 파일이 GitHub에서 제공됩니다. 이 섹션에서는 코드의 주요 요소를 살펴봅니다.
설정 코드
첫 번째 섹션에는 작업이 쓸 테이블을 식별하는 몇 가지 데모 상수가 있습니다. 이 페이지의 뒷부분에 나오는 배포 가이드 섹션에서는 프로젝트 ID를 직접 입력한 ID로 바꾸라고 안내합니다. 이는 코드에 필요한 유일한 수정사항입니다.
/*** Demo constants */
const projectId = "your-project-id"
const datasetId = "demo_dataset"
const tableId = "demo_table"
다음 섹션에서는 작업에서 사용할 몇 가지 코드 종속 항목을 선언하고 초기화합니다. Secret Manager Node.js 모듈을 사용하여 '코드 내'에서 Secret Manager에 액세스하는 예시가 제공됩니다. 하지만 초기화 중에 보안 비밀을 가져오는 Cloud Run 함수의 기본 제공 기능을 사용하여 이 코드 종속성을 없앨 수도 있습니다.
/*** Code Dependencies ***/
const crypto = require("crypto")
const {SecretManagerServiceClient} = require('@google-cloud/secret-manager')
const secrets = new SecretManagerServiceClient()
const BigqueryStorage = require('@google-cloud/bigquery-storage')
const BQSManagedWriter = BigqueryStorage.managedwriter
참조된 @google-cloud 종속 항목은 종속 항목이 미리 로드되어 Node.js 런타임에서 사용할 수 있도록 package.json 파일에도 선언됩니다. crypto은 내장 Node.js 모듈이며 package.json에 선언되지 않습니다.
HTTP 요청 처리 및 라우팅
코드가 Cloud Run 함수 런타임에 노출하는 기본 인터페이스는 Node.js Express 웹 서버 규칙을 따르는 내보낸 JavaScript 함수입니다. 특히 함수는 두 개의 인수를 수신합니다. 첫 번째는 다양한 요청 매개변수와 값을 읽을 수 있는 HTTP 요청을 나타내고, 두 번째는 응답 데이터를 발행하는 응답 객체를 나타냅니다. 함수 이름은 원하는 대로 지정할 수 있지만 배포 가이드 섹션에 자세히 설명된 대로 나중에 Cloud Run Functions에 이름을 제공해야 합니다.
/*** Entry-point for requests ***/
exports.httpHandler = async function httpHandler(req,res) {
httpHandler 함수의 첫 번째 섹션에서는 작업에서 인식할 다양한 경로를 선언합니다. 이는 단일 작업에 필요한 작업 API 엔드포인트와 파일 후반부에 정의된 각 경로를 처리할 함수를 밀접하게 반영합니다.
일부 작업 + Cloud Run Functions 예시에서는 Cloud Run Functions의 기본 라우팅과 일대일로 일치하도록 각 경로에 별도의 함수를 배포하지만, 함수는 여기에 표시된 대로 코드 내에서 추가 '하위 라우팅'을 적용할 수 있습니다. 이는 궁극적으로 선호도의 문제이지만, 코드에서 이 추가 라우팅을 수행하면 배포해야 하는 함수 수가 최소화되고 모든 작업의 엔드포인트에서 일관된 단일 코드 상태를 유지하는 데 도움이 됩니다.
const routes = {
"/": [hubListing],
"/status": [hubStatus], // Debugging endpoint. Not required.
"/action-0/form": [
requireInstanceAuth,
action0Form
],
"/action-0/execute": [
requireInstanceAuth,
processRequestBody,
action0Execute
]
}
나머지 HTTP 핸들러 함수는 앞의 경로 선언에 대한 HTTP 요청 처리를 구현하고 이러한 핸들러의 반환 값을 응답 객체에 연결합니다.
try {
const routeHandlerSequence = routes[req.path] || [routeNotFound]
for(let handler of routeHandlerSequence) {
let handlerResponse = await handler(req)
if (!handlerResponse) continue
return res
.status(handlerResponse.status || 200)
.json(handlerResponse.body || handlerResponse)
}
}
catch(err) {
console.error(err)
res.status(500).json("Unhandled error. See logs for details.")
}
}
HTTP 핸들러와 경로 선언이 완료되었으므로 구현해야 하는 세 가지 주요 작업 엔드포인트로 넘어가겠습니다.
작업 목록 엔드포인트
Looker 관리자가 Looker 인스턴스를 작업 서버에 처음 연결하면 Looker는 제공된 URL('작업 목록 엔드포인트'라고 함)을 호출하여 서버를 통해 사용할 수 있는 작업에 관한 정보를 가져옵니다.
앞서 보여드린 경로 선언에서 이 엔드포인트를 함수 URL 아래의 루트 경로 (/)에서 사용할 수 있도록 하고 hubListing 함수에서 처리하도록 표시했습니다.
다음 함수 정의에서 볼 수 있듯이 '코드'가 많지 않습니다. 매번 동일한 JSON 데이터를 반환할 뿐입니다. 한 가지 주의할 점은 Looker 인스턴스가 나중에 동일한 함수에 요청을 다시 보낼 수 있도록 일부 필드에 '자체' URL을 동적으로 포함한다는 것입니다.
async function hubListing(req){
return {
integrations: [
{
name: "demo-bq-insert",
label: "Demo BigQuery Insert",
supported_action_types: ["cell", "query", "dashboard"],
form_url:`${process.env.CALLBACK_URL_PREFIX}/action-0/form`,
url: `${process.env.CALLBACK_URL_PREFIX}/action-0/execute`,
icon_data_uri: "data:image/png;base64,...",
supported_formats:["inline_json"],
supported_formattings:["unformatted"],
required_fields:[
// You can use this to make your action available
// for specific queries/fields
// {tag:"user_id"}
],
params: [
// You can use this to require parameters, either
// from the Action's administrative configuration,
// or from the invoking user's user attributes.
// A common use case might be to have the Looker
// instance pass along the user's identification to
// allow you to conditionally authorize the action:
{name: "email", label: "Email", user_attribute_name: "email", required: true}
]
}
]
}
}
데모를 위해 코드는 이 등록정보를 가져오는 데 인증을 요구하지 않았습니다. 하지만 작업 메타데이터가 민감하다고 생각되면 다음 섹션에 표시된 대로 이 경로에 인증을 요구할 수도 있습니다.
또한 Cloud Run 함수는 여러 작업을 노출하고 처리할 수 있으므로 /action-X/... 경로 규칙이 적용됩니다. 하지만 데모 Cloud Run 함수는 하나의 작업만 구현합니다.
작업 양식 엔드포인트
모든 사용 사례에 양식이 필요한 것은 아니지만, 사용자가 Looker에서 데이터를 검사한 다음 데이터베이스에 삽입할 값을 제공할 수 있으므로 데이터베이스 쓰기 사용 사례에 적합합니다. 작업 목록에서 form_url 매개변수를 제공하므로 사용자가 작업과 상호작용하기 시작하면 Looker가 이 작업 양식 엔드포인트를 호출하여 사용자로부터 캡처할 추가 데이터를 결정합니다.
경로 선언에서 이 엔드포인트를 /action-0/form 경로에서 사용할 수 있도록 하고 requireInstanceAuth 및 action0Form의 두 핸들러를 연결했습니다.
일부 로직은 여러 엔드포인트에서 재사용할 수 있으므로 다음과 같이 여러 핸들러를 허용하도록 경로 선언을 설정합니다.
예를 들어 requireInstanceAuth이 여러 경로에 사용되는 것을 확인할 수 있습니다. 요청이 Looker 인스턴스에서 전송되어야 하는 경우 이 핸들러를 사용합니다. 핸들러는 Secret Manager에서 예상되는 보안 비밀 토큰 값을 가져오고 예상되는 토큰 값이 없는 요청을 거부합니다.
async function requireInstanceAuth(req) {
const lookerSecret = await getLookerSecret()
if(!lookerSecret){return}
const expectedAuthHeader = `Token token="${lookerSecret}"`
if(!timingSafeEqual(req.headers.authorization,expectedAuthHeader)){
return {
status:401,
body: {error: "Looker instance authentication is required"}
}
}
return
function timingSafeEqual(a, b) {
if(typeof a !== "string"){return}
if(typeof b !== "string"){return}
var aLen = Buffer.byteLength(a)
var bLen = Buffer.byteLength(b)
const bufA = Buffer.allocUnsafe(aLen)
bufA.write(a)
const bufB = Buffer.allocUnsafe(aLen) //Yes, aLen
bufB.write(b)
return crypto.timingSafeEqual(bufA, bufB) && aLen === bLen;
}
}
공격자가 비밀 값을 빠르게 파악할 수 있는 부채널 타이밍 정보가 유출되지 않도록 표준 동등성 검사 (==)가 아닌 timingSafeEqual 구현을 사용합니다.
요청이 인스턴스 인증 확인을 통과하면 action0Form 핸들러가 요청을 처리합니다.
async function action0Form(req){
return [
{name: "choice", label: "Choose", type:"select", options:[
{name:"Yes", label:"Yes"},
{name:"No", label:"No"},
{name:"Maybe", label:"Maybe"}
]},
{name: "note", label: "Note", type: "textarea"}
]
}
데모 예는 매우 정적이지만 특정 사용 사례의 경우 양식 코드가 더 대화형일 수 있습니다. 예를 들어 초기 드롭다운에서 사용자가 선택한 항목에 따라 다른 필드가 표시될 수 있습니다.
작업 실행 엔드포인트
작업 실행 엔드포인트는 작업 로직의 대부분이 있는 곳이며 BigQuery 삽입 사용 사례와 관련된 로직을 살펴볼 곳입니다.
경로 선언에서 /action-0/execute 경로 아래에서 이 엔드포인트를 사용할 수 있도록 하고 requireInstanceAuth, processRequestBody, action0Execute의 세 가지 핸들러를 연결했습니다.
requireInstanceAuth는 이미 다루었으며, processRequestBody 핸들러는 Looker 요청 본문의 불편한 필드를 더 편리한 형식으로 변환하기 위한 대부분 흥미롭지 않은 사전 처리를 제공하지만 전체 코드 파일에서 참조할 수 있습니다.
action0Execute 함수는 유용할 수 있는 작업 요청의 여러 부분에서 정보를 추출하는 예를 보여주는 것으로 시작합니다. 실제로 코드에서 formParams 및 actionParams로 참조하는 요청 요소에는 등록정보 및 양식 엔드포인트에서 선언한 내용에 따라 다른 필드가 포함될 수 있습니다.
async function action0Execute (req){
try{
// Prepare some data that we will insert
const scheduledPlanId = req.body.scheduled_plan && req.body.scheduled_plan.scheduled_plan_id
const formParams = req.body.form_params || {}
const actionParams = req.body.data || {}
const queryData = req.body.attachment.data //If using a standard "push" action
/*In case any fields require datatype-specific preparation, check this example:
https://github.com/googleapis/nodejs-bigquery-storage/blob/main/samples/append_rows_proto2.js
*/
const newRow = {
invoked_at: new Date(),
invoked_by: actionParams.email,
scheduled_plan_id: scheduledPlanId || null,
query_result_size: queryData.length,
choice: formParams.choice,
note: formParams.note,
}
그런 다음 코드는 실제로 데이터를 삽입하기 위해 일부 표준 BigQuery 코드로 전환됩니다. BigQuery Storage Write API는 지속적인 스트리밍 연결이나 많은 레코드의 대량 삽입에 더 적합한 다른 복잡한 변형을 제공하지만, Cloud Run 함수 컨텍스트에서 개별 사용자 상호작용에 응답하는 데는 이 변형이 가장 직접적입니다.
await bigqueryConnectAndAppend(newRow)
...
async function bigqueryConnectAndAppend(row){
let writerClient
try{
const destinationTablePath = `projects/${projectId}/datasets/${datasetId}/tables/${tableId}`
const streamId = `${destinationTablePath}/streams/_default`
writerClient = new BQSManagedWriter.WriterClient({projectId})
const writeMetadata = await writerClient.getWriteStream({
streamId,
view: 'FULL',
})
const protoDescriptor = BigqueryStorage.adapt.convertStorageSchemaToProto2Descriptor(
writeMetadata.tableSchema,
'root'
)
const connection = await writerClient.createStreamConnection({
streamId,
destinationTablePath,
})
const writer = new BQSManagedWriter.JSONWriter({
streamId,
connection,
protoDescriptor,
})
let result
if(row){
// The API expects an array of rows, so wrap the single row in an array
const rowsToAppend = [row]
result = await writer.appendRows(rowsToAppend).getResult()
}
return {
streamId: connection.getStreamId(),
protoDescriptor,
result
}
}
catch (e) {throw e}
finally{
if(writerClient){writerClient.close()}
}
}
데모 코드에는 문제 해결을 위한 'status' 엔드포인트도 포함되어 있지만 이 엔드포인트는 Action API 통합에 필요하지 않습니다.
배포 가이드
마지막으로 사전 요구사항, Cloud Run 함수 배포, BigQuery 구성, Looker 구성을 다루는 데모 배포를 위한 단계별 가이드를 제공합니다.
프로젝트 및 서비스 기본 요건
구체적인 사항을 구성하기 전에 이 목록을 검토하여 솔루션에 필요한 서비스와 정책을 파악하세요.
- 새 프로젝트: 예시의 리소스를 저장할 새 프로젝트가 필요합니다.
- 서비스: Cloud 콘솔 UI에서 BigQuery 및 Cloud Run 함수를 처음 사용하는 경우 BigQuery, Artifact Registry, Cloud Build, Cloud Functions, Cloud Logging, Pub/Sub, Cloud Run Admin, Secret Manager를 비롯한 필수 서비스에 필요한 API를 사용 설정하라는 메시지가 표시됩니다.
- 인증되지 않은 호출 정책: 이 사용 사례에서는 IAM을 사용하는 대신 Action API에 따라 코드에서 수신 요청의 인증을 처리하므로 '공개 액세스 허용' Cloud Run 함수를 배포해야 합니다. 기본적으로 허용되지만 조직 정책에서 이 사용을 제한하는 경우가 많습니다. 구체적으로
constraints/iam.allowedPolicyMemberDomains정책은 IAM 권한을 부여받을 수 있는 사용자를 제한하며, 인증되지 않은 액세스를 위해allUsers주 구성원을 허용하도록 조정해야 할 수 있습니다. 공개 액세스를 허용할 수 없는 경우 이 가이드(도메인 제한 공유가 적용될 때 공개 Cloud Run 서비스를 만드는 방법)를 참고하세요. - 기타 정책: 다른 Google Cloud 조직 정책 제약 조건으로 인해 기본적으로 허용되는 서비스의 배포가 방지될 수도 있습니다.
Cloud Run 함수 배포
새 프로젝트를 만든 후 다음 단계에 따라 Cloud Run 함수를 배포합니다.
- Cloud Run Functions에서 함수 만들기를 클릭합니다.
- 함수 이름을 선택합니다 (예: 'demo-bq-insert-action').
- 트리거 설정에서 다음을 수행합니다.
- 트리거 유형은 이미 'HTTPS'여야 합니다.
- 인증을 인증되지 않은 호출 허용으로 설정합니다.
- URL 값을 클립보드에 복사합니다.
- 런타임 > 런타임 환경 변수 설정에서 다음을 수행합니다.
- 변수 추가를 클릭합니다.
- 변수 이름을
CALLBACK_URL_PREFIX로 설정합니다. - 이전 단계의 URL을 값으로 붙여넣습니다.
- 다음을 클릭합니다.
package.json파일을 클릭하고 contents를 붙여넣습니다.index.js파일을 클릭하고 contents를 붙여넣습니다.- 파일 상단에서
projectId변수를 자체 프로젝트 ID에 할당합니다. - 진입점을
httpHandler로 설정합니다. - 배포를 클릭합니다.
- 빌드 서비스 계정에 요청된 권한을 부여합니다 (있는 경우).
- 배포가 완료될 때까지 기다립니다.
- 향후 단계에서 Google Cloud 로그를 검토하라는 오류가 표시되면 이 페이지의 로그 탭에서 이 함수의 로그에 액세스할 수 있습니다.
- Cloud Run 함수의 페이지에서 나가기 전에 세부정보 탭에서 함수에 있는 서비스 계정을 찾아 기록해 둡니다. 이 값은 나중에 함수에 필요한 권한이 있는지 확인하는 데 사용됩니다.
- URL을 방문하여 브라우저에서 직접 함수 배포를 테스트합니다. 통합 등록정보가 포함된 JSON 응답이 표시됩니다.
- 403 오류가 표시되면 조직 정책으로 인해 인증되지 않은 호출 허용 설정 시도가 자동으로 실패했을 수 있습니다. 함수에서 인증되지 않은 호출을 허용하는지 확인하고 조직 정책 설정을 검토한 후 설정을 업데이트해 보세요.
BigQuery 대상 테이블에 대한 액세스
실제로 삽입할 대상 테이블은 다른 Google Cloud 프로젝트에 있을 수 있지만, 데모를 위해 동일한 프로젝트에 새 대상 테이블을 만듭니다. 어떤 경우든 Cloud Run 함수의 서비스 계정에 테이블에 쓸 수 있는 권한이 있는지 확인해야 합니다.
- BigQuery 콘솔로 이동합니다.
데모 테이블을 만듭니다.
- 탐색기 바에서 프로젝트 옆에 있는 줄임표 메뉴를 사용하여 데이터 세트 만들기를 선택합니다.
- 데이터 세트에 ID
demo_dataset를 지정하고 데이터 세트 만들기를 클릭합니다. - 새로 만든 데이터 세트에서 줄임표 메뉴를 사용하고 테이블 만들기를 선택합니다.
- 표 이름을
demo_table로 지정합니다. 스키마에서 텍스트로 편집을 선택하고 다음 스키마를 사용한 후 표 만들기를 클릭합니다.
[ {"name":"invoked_at","type":"TIMESTAMP"}, {"name":"invoked_by","type":"STRING"}, {"name":"scheduled_plan_id","type":"STRING"}, {"name":"query_result_size","type":"INTEGER"}, {"name":"choice","type":"STRING"}, {"name":"note","type":"STRING"} ]
권한 할당:
- 탐색기 표시줄에서 데이터 세트를 클릭합니다.
- 데이터 세트 페이지에서 공유 > 권한을 클릭합니다.
- 주 구성원 추가를 클릭합니다.
- 새 주 구성원을 이 페이지 앞부분에서 확인한 함수의 서비스 계정으로 설정합니다.
- BigQuery 데이터 편집자 역할을 할당합니다.
- 저장을 클릭합니다.
Looker에 연결
이제 함수가 배포되었으므로 Looker를 함수에 연결하겠습니다.
- 요청이 Looker 인스턴스에서 전송되었음을 인증하려면 작업의 공유 비밀번호가 필요합니다. 긴 임의 문자열을 생성하고 안전하게 보관합니다. 이 값은 후속 단계에서 Looker 비밀번호 값으로 사용됩니다.
- Cloud 콘솔에서 Secret Manager로 이동합니다.
- 보안 비밀 만들기를 클릭합니다.
- 이름을
LOOKER_SECRET로 설정합니다. (이 데모의 코드에서는 하드 코딩되어 있지만 자체 코드를 사용할 때는 어떤 이름이든 선택할 수 있습니다.) - Secret Value를 생성한 비밀 값으로 설정합니다.
- 보안 비밀 만들기를 클릭합니다.
- 보안 비밀 페이지에서 권한 탭을 클릭합니다.
- 액세스 권한 부여를 클릭합니다.
- 새 주 구성원을 앞에서 확인한 함수의 서비스 계정으로 설정합니다.
- Secret Manager 보안 비밀 접근자 역할을 할당합니다.
- 저장을 클릭합니다.
- 함수 URL에 추가된
/status경로를 방문하여 함수가 보안 비밀에 성공적으로 액세스하는지 확인할 수 있습니다.
- Looker 인스턴스에서 다음 단계를 따르세요.
- 관리 > 플랫폼 > 작업으로 이동합니다.
- 페이지 하단으로 이동하여 작업 허브 추가를 클릭합니다.
- 함수의 URL (예: https://your-region-your-project.cloudfunctions.net/demo-bq-insert-action)을 입력하고 작업 허브 추가를 클릭하여 확인합니다.
- 이제 Demo BigQuery Insert라는 작업이 하나 있는 새 작업 허브 항목이 표시됩니다.
- 작업 허브 항목에서 승인 구성을 클릭합니다.
- 생성된 Looker Secret을 Authorization Token 필드에 입력하고 Update Token을 클릭합니다.
- 데모 BigQuery 삽입 작업에서 사용 설정을 클릭합니다.
- 사용 설정됨 스위치를 사용 설정으로 전환합니다.
- 작업 테스트가 자동으로 실행되어 함수가 Looker의 요청을 수락하고 양식 엔드포인트에 올바르게 응답하는지 확인해야 합니다.
- 저장을 클릭합니다.
엔드 투 엔드 테스트
이제 새 작업을 실제로 사용할 수 있습니다. 이 작업은 모든 쿼리와 함께 작동하도록 구성되어 있으므로 Explore (예: 내장 시스템 활동 Explore)를 선택하고 새 쿼리에 필드를 추가한 후 실행한 다음 톱니바퀴 메뉴에서 보내기를 선택합니다. 작업이 사용 가능한 대상 중 하나로 표시되고 일부 필드 입력을 묻는 메시지가 표시됩니다.
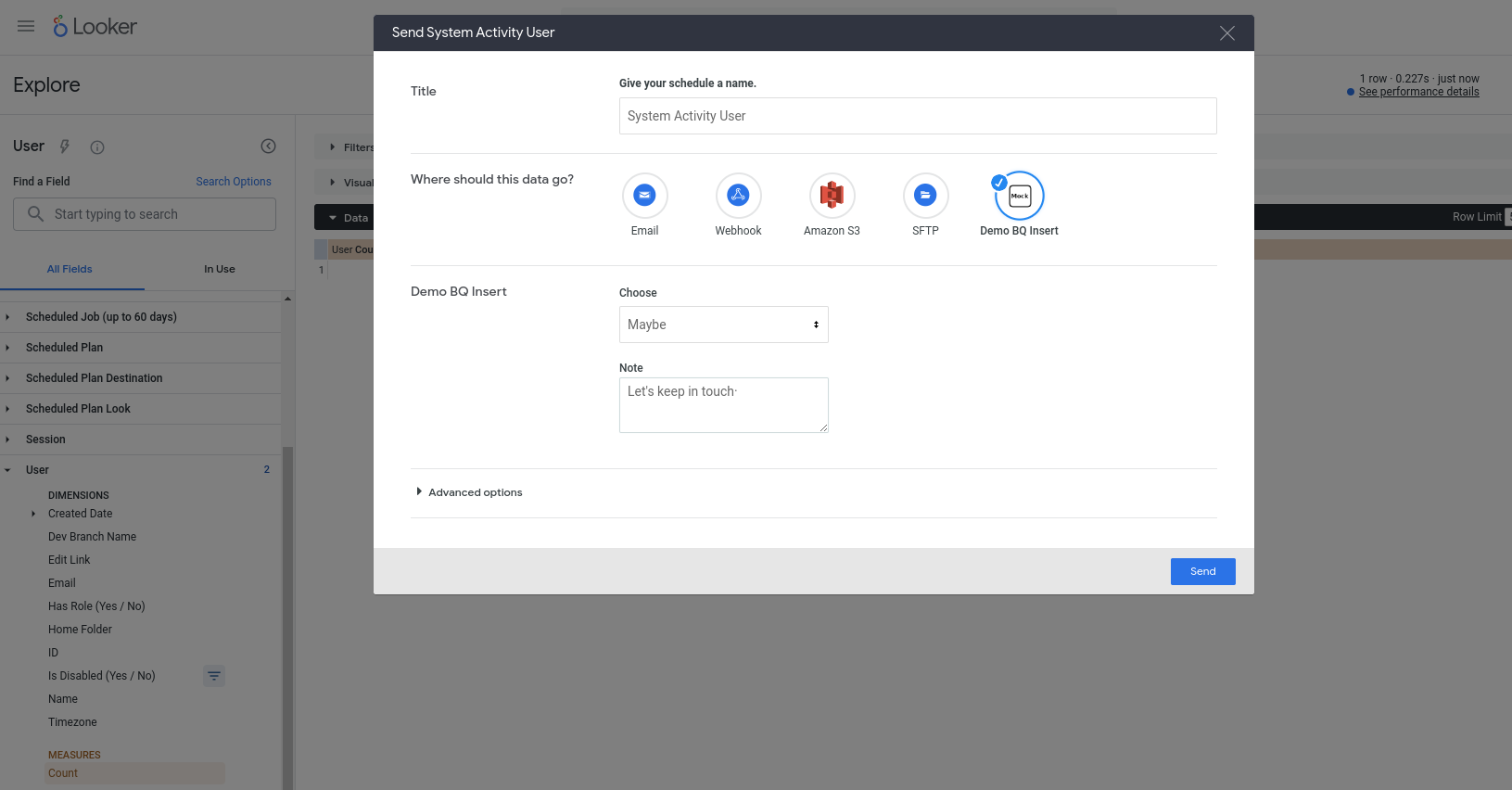
보내기를 누르면 BigQuery 테이블에 새 행이 삽입되고 Looker 사용자 계정의 이메일이 invoked_by 열에 표시됩니다.