本教學課程說明如何使用 vLLM 服務架構,在 Google Kubernetes Engine (GKE) 上透過張量處理單元 (TPU) 供應大型語言模型 (LLM)。在本教學課程中,您將提供 Llama 3.1 70b,使用 TPU Trillium,並透過 vLLM 伺服器指標設定水平 Pod 自動調度。
如果您在部署及提供 AI/機器學習工作負載時,需要代管型 Kubernetes 的精細控制、擴充性、復原能力、可攜性和成本效益,這份文件就是不錯的入門資源。
背景
在 GKE 上使用 TPU Trillium,即可導入可用於正式環境的穩固服務解決方案,同時享有代管型 Kubernetes 的所有優點,包括高效率的擴充能力和更高的可用性。本節說明本指南中使用的重要技術。
TPU Trillium
TPU 是 Google 開發的客製化特殊應用積體電路 (ASIC)。TPU 可加速處理使用 TensorFlow、PyTorch 和 JAX 等架構建構的機器學習和 AI 模型。本教學課程使用 Google 第六代 TPU「Trillium」。
在 GKE 中使用 TPU 之前,建議您先完成下列學習路徑:
- 瞭解 TPU Trillium 系統架構。
- 瞭解 GKE 中的 TPU。
vLLM
vLLM 是經過高度最佳化的開放原始碼框架,可提供 LLM。vLLM 可透過下列功能提高 TPU 的服務輸送量:
- 使用 PagedAttention 實作最佳化轉換器。
- 持續批次處理,提升整體放送輸送量。
- 在多個 TPU 上進行張量平行處理和分散式服務。
詳情請參閱 vLLM 說明文件。
Cloud Storage FUSE
Cloud Storage FUSE 可讓 GKE 叢集存取物件儲存空間值區中的模型權重。在本教學課程中,建立的 Cloud Storage bucket 一開始會是空的。vLLM 啟動時,GKE 會從 Hugging Face 下載模型,並將權重快取到 Cloud Storage bucket。Pod 重新啟動或部署作業擴大時,後續的模型載入作業會從 Cloud Storage bucket 下載快取資料,並利用平行下載功能達到最佳效能。
建立 GKE 叢集
您可以在 GKE Autopilot 或 Standard 叢集上,透過 TPU 供應 LLM。建議您使用 Autopilot 叢集,享有全代管 Kubernetes 體驗。如要為工作負載選擇最合適的 GKE 作業模式,請參閱「選擇 GKE 作業模式」。
Autopilot
建立 GKE Autopilot 叢集:
gcloud container clusters create-auto ${CLUSTER_NAME} \ --cluster-version=${CLUSTER_VERSION} \ --location=${CONTROL_PLANE_LOCATION}
標準
建立 GKE Standard 叢集:
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --cluster-version=${CLUSTER_VERSION} \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons GcsFuseCsiDriver建立 TPU 節點集區:
gcloud container node-pools create tpunodepool \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --num-nodes=1 \ --machine-type=ct6e-standard-8t \ --cluster=${CLUSTER_NAME} \ --enable-autoscaling --total-min-nodes=1 --total-max-nodes=2GKE 會為 LLM 建立下列資源:
- 使用 Workload Identity Federation for GKE 的 GKE Standard 叢集,並啟用 Cloud Storage FUSE CSI 驅動程式。
- 機型為
ct6e-standard-8t的 TPU Trillium 節點集區。這個節點集區有一個節點、八個 TPU 晶片,並已啟用自動調度資源功能。
設定 kubectl 與叢集通訊
如要設定 kubectl 與叢集通訊,請執行下列指令:
gcloud container clusters get-credentials ${CLUSTER_NAME} --location=${CONTROL_PLANE_LOCATION}
為 Hugging Face 憑證建立 Kubernetes 密鑰
建立命名空間。如果使用
default命名空間,可以略過這個步驟:kubectl create namespace ${NAMESPACE}建立包含 Hugging Face 權杖的 Kubernetes Secret,然後執行下列指令:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=${HF_TOKEN} \ --namespace ${NAMESPACE}
建立 Cloud Storage 值區
在 Cloud Shell 中執行下列指令:
gcloud storage buckets create gs://${GSBUCKET} \
--uniform-bucket-level-access
這會建立 Cloud Storage bucket,用於儲存從 Hugging Face 下載的模型檔案。
設定 Kubernetes ServiceAccount 以存取 bucket
建立 Kubernetes ServiceAccount:
kubectl create serviceaccount ${KSA_NAME} --namespace ${NAMESPACE}授予 Kubernetes ServiceAccount 讀寫權限,以便存取 Cloud Storage bucket:
gcloud storage buckets add-iam-policy-binding gs://${GSBUCKET} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"或者,您也可以授予專案中所有 Cloud Storage 值區的讀寫權限:
gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"GKE 會為 LLM 建立下列資源:
- Cloud Storage bucket,用於儲存下載的模型和編譯快取。A Cloud Storage FUSE CSI 驅動程式 會讀取 bucket 的內容。
- 啟用檔案快取功能的磁碟區,以及 Cloud Storage FUSE 的平行下載功能。
最佳做法: 視模型內容 (例如權重檔案) 的預期大小而定,使用
tmpfs或Hyperdisk / Persistent Disk支援的檔案快取。在本教學課程中,您將使用以 RAM 為後端的 Cloud Storage FUSE 檔案快取。
部署 vLLM 模型伺服器
如要部署 vLLM 模型伺服器,本教學課程會使用 Kubernetes Deployment。Deployment 是 Kubernetes API 物件,可讓您執行多個 Pod 副本,並將這些副本分散到叢集中的節點。
檢查以下儲存為
vllm-llama3-70b.yaml的 Deployment 資訊清單,該資訊清單使用單一副本:如果將 Deployment 擴展至多個副本,並行寫入
VLLM_XLA_CACHE_PATH會導致RuntimeError: filesystem error: cannot create directories錯誤。如要避免發生這項錯誤,可以採取下列兩種做法:從 Deployment YAML 中移除下列區塊,即可移除 XLA 快取位置。這表示所有副本都會重新編譯快取。
- name: VLLM_XLA_CACHE_PATH value: "/data"將 Deployment 擴展至
1,並等待第一個副本準備就緒並寫入 XLA 快取。然後擴充至其他副本。這樣一來,其餘副本就能讀取快取,而不必嘗試寫入快取。
執行下列指令來套用資訊清單:
kubectl apply -f vllm-llama3-70b.yaml -n ${NAMESPACE}查看執行中模型伺服器的記錄:
kubectl logs -f -l app=vllm-tpu -n ${NAMESPACE}輸出內容應如下所示:
INFO: Started server process [1] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
提供模型
如要取得 VLLM 服務的外部 IP 位址,請執行下列指令:
export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE})使用
curl與模型互動:curl http://$vllm_service:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-3.1-70B", "prompt": "San Francisco is a", "max_tokens": 7, "temperature": 0 }'畫面會顯示如下的輸出內容:
{"id":"cmpl-6b4bb29482494ab88408d537da1e608f","object":"text_completion","created":1727822657,"model":"meta-llama/Llama-3-8B","choices":[{"index":0,"text":" top holiday destination featuring scenic beauty and","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":5,"total_tokens":12,"completion_tokens":7}}
設定自訂自動配置器
在本節中,您將使用自訂 Prometheus 指標設定水平 Pod 自動調度。您可以使用 vLLM 伺服器中的 Google Cloud Managed Service for Prometheus 指標。
詳情請參閱「Google Cloud Managed Service for Prometheus」。GKE 叢集應預設啟用這項功能。
在叢集上設定自訂指標 Stackdriver 轉接器:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yaml將「監控檢視者」角色新增至自訂指標 Stackdriver 轉接器使用的服務帳戶:
gcloud projects add-iam-policy-binding projects/${PROJECT_ID} \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapter將下列資訊清單儲存為
vllm_pod_monitor.yaml:將其套用至叢集:
kubectl apply -f vllm_pod_monitor.yaml -n ${NAMESPACE}
在 vLLM 端點上建立負載
在 vLLM 伺服器上建立負載,測試 GKE 如何使用自訂 vLLM 指標自動調度資源。
執行 bash 指令碼 (
load.sh),將N個並行要求傳送至 vLLM 端點:#!/bin/bash N=PARALLEL_PROCESSES export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE}) for i in $(seq 1 $N); do while true; do curl http://$vllm_service:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "meta-llama/Llama-3.1-70B", "prompt": "Write a story about san francisco", "max_tokens": 1000, "temperature": 0}' done & # Run in the background done wait將 PARALLEL_PROCESSES 替換為要執行的平行程序數量。
執行 bash 指令碼:
chmod +x load.sh nohup ./load.sh &
確認 Google Cloud Managed Service for Prometheus 是否會擷取指標
Google Cloud Managed Service for Prometheus 擷取指標後,您就可以在 Cloud Monitoring 中查看指標,並將負載新增至 vLLM 端點。
前往 Google Cloud 控制台的「指標探索器」頁面。
按一下「< > PromQL」。
輸入下列查詢,觀察流量指標:
vllm:num_requests_waiting{cluster='CLUSTER_NAME'}
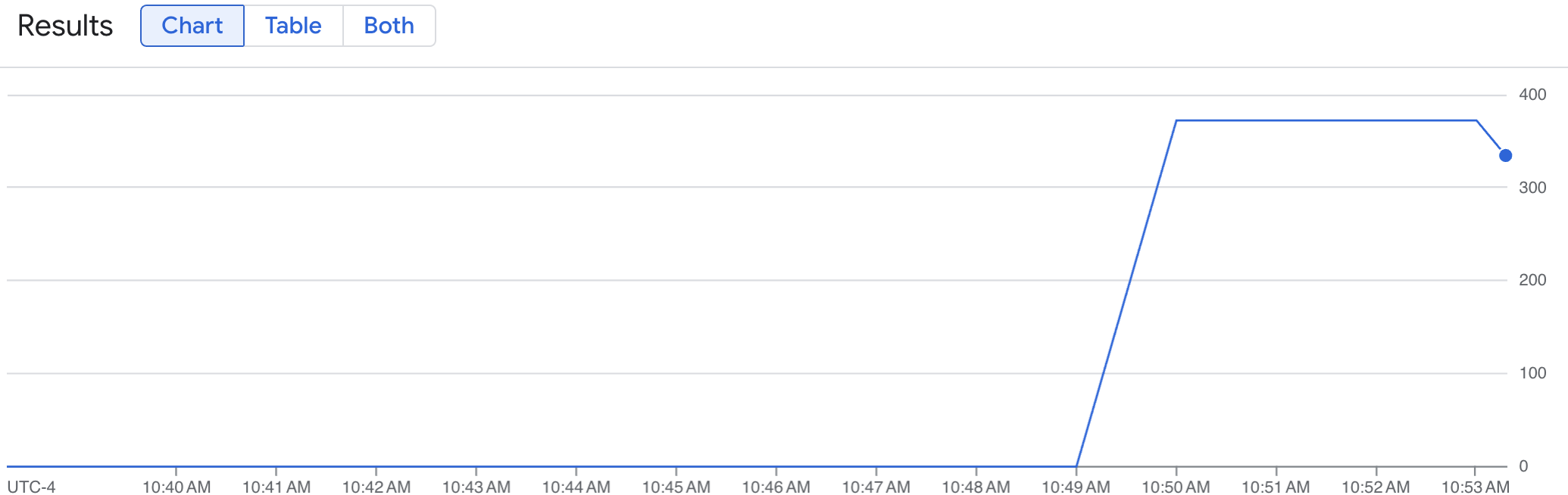
折線圖會顯示一段時間內測得的 vLLM 指標 (num_requests_waiting)。vLLM 指標會從 0 (預先載入) 向上調整至某個值 (載入後)。這張圖表會確認 vLLM 指標是否已擷取至 Google Cloud Managed Service for Prometheus。下圖顯示預先載入值從 0 開始,在一分鐘內達到接近 400 的最大載入後值。
部署水平 Pod 自動調度資源設定
決定要根據哪項指標自動調度資源時,建議您使用下列 vLLM TPU 指標:
num_requests_waiting:這項指標與模型伺服器佇列中等待的要求數量有關。當 kv 快取已滿時,這個數字就會開始明顯增加。gpu_cache_usage_perc:這項指標與 kv 快取使用率有關,直接影響模型伺服器在特定推論週期內處理的要求數量。請注意,這項指標在 GPU 和 TPU 上的運作方式相同,但與 GPU 命名架構有關。
如果想盡量提高總處理量並降低成本,且模型伺服器的最大總處理量可達到延遲目標,建議使用 num_requests_waiting。
如果工作負載對延遲時間很敏感,且以佇列為基礎的擴縮速度不夠快,無法滿足您的需求,建議使用 gpu_cache_usage_perc。
如需進一步說明,請參閱「使用 TPU 自動調度大型語言模型 (LLM) 推論工作負載的最佳做法」。
選取 HPA 設定的averageValue目標時,您必須透過實驗判斷此目標。如需更多最佳化這部分的構想,請參閱「節省 GPU 費用:為 GKE 推論工作負載提供更智慧的自動調度功能」網誌文章。這篇網誌文章中使用的 profile-generator 也適用於 vLLM TPU。
在下列操作說明中,您會使用 num_requests_waiting 指標部署 HPA 設定。為方便示範,您將指標設為低值,讓 HPA 設定將 vLLM 副本擴充至兩個。如要使用 num_requests_waiting 部署水平 Pod 自動調度器設定,請按照下列步驟操作:
將下列資訊清單儲存為
vllm-hpa.yaml:Google Cloud Managed Service for Prometheus 中的 vLLM 指標採用
vllm:metric_name格式。最佳做法: 使用
num_requests_waiting調整輸送量。對於延遲時間敏感的 TPU 用途,請使用gpu_cache_usage_perc。部署水平 Pod 自動調度資源設定:
kubectl apply -f vllm-hpa.yaml -n ${NAMESPACE}GKE 會排定部署另一個 Pod,這會觸發節點集區自動調度器新增第二個節點,然後再部署第二個 vLLM 副本。
查看 Pod 自動調度資源的進度:
kubectl get hpa --watch -n ${NAMESPACE}輸出結果會與下列內容相似:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE vllm-hpa Deployment/vllm-tpu <unknown>/10 1 2 0 6s vllm-hpa Deployment/vllm-tpu 34972m/10 1 2 1 16s vllm-hpa Deployment/vllm-tpu 25112m/10 1 2 2 31s vllm-hpa Deployment/vllm-tpu 35301m/10 1 2 2 46s vllm-hpa Deployment/vllm-tpu 25098m/10 1 2 2 62s vllm-hpa Deployment/vllm-tpu 35348m/10 1 2 2 77s等待 10 分鐘,然後重複「確認 Google Cloud Managed Service for Prometheus 擷取指標」一節中的步驟。Google Cloud Managed Service for Prometheus 現在會從 vLLM 端點擷取指標。