本教程介绍如何通过 vLLM 部署框架,使用 Google Kubernetes Engine (GKE) 上的张量处理单元 (TPU) 来部署大语言模型 (LLM)。在本教程中,您将部署 Llama 3.1 70b、使用 TPU Trillium,并利用 vLLM 服务器指标设置 Pod 横向自动扩缩。
如果您在部署和应用 AI/机器学习工作负载时需要利用托管式 Kubernetes 的精细控制、可伸缩性、弹性、可移植性和成本效益,那么本文档是一个很好的起点。
背景
通过在 GKE 上使用 TPU Trillium,您可以实现一个能直接用于生产环境的强大服务解决方案,享受托管式 Kubernetes 的所有优势,包括高效的可伸缩性和更高的可用性。本部分介绍本指南中使用的关键技术。
TPU Trillium
TPU 是 Google 定制开发的应用专用集成电路 (ASIC)。TPU 用于加速使用 TensorFlow、PyTorch 和 JAX 等框架构建的机器学习和 AI 模型。本教程使用 TPU Trillium,这是 Google 的第六代 TPU。
使用 GKE 中的 TPU 之前,我们建议您完成以下学习路线:
- 了解 TPU Trillium 系统架构。
- 了解 GKE 中的 TPU。
vLLM
vLLM 是一个经过高度优化的开源 LLM 部署框架。vLLM 可提高 TPU 上的服务吞吐量,具有以下功能:
- 具有 PagedAttention 且经过优化的 Transformer 实现
- 连续批处理,可提高整体服务吞吐量。
- 多个 TPU 上的张量并行处理和分布式服务。
如需了解详情,请参阅 vLLM 文档。
Cloud Storage FUSE
Cloud Storage FUSE 提供从您的 GKE 集群到 Cloud Storage 的访问权限,以获取驻留在对象存储桶中的模型权重。在本教程中,创建的 Cloud Storage 存储桶最初将为空。 当 vLLM 启动时,GKE 会从 Hugging Face 下载模型并将权重缓存到 Cloud Storage 存储桶。在 Pod 重启或部署纵向扩容时,后续模型加载将从 Cloud Storage 存储桶下载缓存的数据,并利用并行下载来获得最佳性能。
如需了解详情,请参阅 Cloud Storage FUSE CSI 驱动程序文档。
创建 GKE 集群
您可以在 GKE Autopilot 或 Standard 集群中的 TPU 上部署 LLM。我们建议您使用 Autopilot 集群获得全托管式 Kubernetes 体验。如需选择最适合您的工作负载的 GKE 操作模式,请参阅选择 GKE 操作模式。
Autopilot
创建 GKE Autopilot 集群:
gcloud container clusters create-auto ${CLUSTER_NAME} \ --cluster-version=${CLUSTER_VERSION} \ --location=${CONTROL_PLANE_LOCATION}
Standard
创建 GKE Standard 集群:
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --cluster-version=${CLUSTER_VERSION} \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons GcsFuseCsiDriver创建 TPU 切片节点池:
gcloud container node-pools create tpunodepool \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --num-nodes=1 \ --machine-type=ct6e-standard-8t \ --cluster=${CLUSTER_NAME} \ --enable-autoscaling --total-min-nodes=1 --total-max-nodes=2GKE 会为 LLM 创建以下资源:
- 使用 Workload Identity Federation for GKE 并已启用 Cloud Storage FUSE CSI 驱动程序的 GKE Standard 集群。
- 具有
ct6e-standard-8t机器类型的 TPU Trillium 节点池。此节点池有一个节点、八个 TPU 芯片,并启用了自动扩缩。
配置 kubectl 以与您的集群通信
如需配置 kubectl 以与您的集群通信,请运行以下命令:
gcloud container clusters get-credentials ${CLUSTER_NAME} --location=${CONTROL_PLANE_LOCATION}
为 Hugging Face 凭据创建 Kubernetes Secret
创建命名空间。如果您使用的是
default命名空间,则可以跳过此步骤:kubectl create namespace ${NAMESPACE}创建包含 Hugging Face 令牌的 Kubernetes Secret,请运行以下命令:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=${HF_TOKEN} \ --namespace ${NAMESPACE}
创建 Cloud Storage 存储桶
在 Cloud Shell 中,运行以下命令:
gcloud storage buckets create gs://${GSBUCKET} \
--uniform-bucket-level-access
这会创建一个 Cloud Storage 存储桶,用于存储您从 Hugging Face 下载的模型文件。
设置 Kubernetes ServiceAccount 以访问存储桶
创建 Kubernetes ServiceAccount:
kubectl create serviceaccount ${KSA_NAME} --namespace ${NAMESPACE}向 Kubernetes ServiceAccount 授予读写权限,以便访问 Cloud Storage 存储桶:
gcloud storage buckets add-iam-policy-binding gs://${GSBUCKET} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"或者,您可以授予对项目中所有 Cloud Storage 存储桶的读写权限:
gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"GKE 会为 LLM 创建以下资源:
- 存储下载的模型和编译缓存的 Cloud Storage 存储桶。Cloud Storage FUSE CSI 驱动程序会读取存储桶的内容。
- 启用文件缓存的卷和 Cloud Storage FUSE 的并行下载功能。
最佳实践: 根据模型内容(例如权重文件)的预期大小,使用由
tmpfs或Hyperdisk / Persistent Disk提供支持的文件缓存。在本教程中,您将使用由 RAM 提供支持的 Cloud Storage FUSE 文件缓存。
部署 vLLM 模型服务器
本教程将使用 Kubernetes Deployment 来部署 vLLM 模型服务器。Deployment 是一个 Kubernetes API 对象,可让您运行在集群节点中分布的多个 Pod 副本。
检查以下保存为
vllm-llama3-70b.yaml的 Deployment 清单,该清单使用单个副本:如果您将 Deployment 扩缩到多个副本,则对
VLLM_XLA_CACHE_PATH的并发写入会导致错误:RuntimeError: filesystem error: cannot create directories。如需防止此错误,您有以下两种选择:通过从 Deployment YAML 中移除以下块来移除 XLA 缓存位置。这意味着所有副本都会重新编译缓存。
- name: VLLM_XLA_CACHE_PATH value: "/data"将 Deployment 扩缩到
1,并等待第一个副本准备就绪并写入 XLA 缓存。然后扩缩到其他副本。这样,其余副本就可以读取缓存,而无需尝试写入缓存。
通过运行以下命令来应用清单:
kubectl apply -f vllm-llama3-70b.yaml -n ${NAMESPACE}查看正在运行的模型服务器的日志:
kubectl logs -f -l app=vllm-tpu -n ${NAMESPACE}输出应类似如下所示:
INFO: Started server process [1] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
应用模型
如需获取 VLLM 服务的外部 IP 地址,请运行以下命令:
export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE})使用
curl与模型互动:curl http://$vllm_service:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-3.1-70B", "prompt": "San Francisco is a", "max_tokens": 7, "temperature": 0 }'输出应类似如下所示:
{"id":"cmpl-6b4bb29482494ab88408d537da1e608f","object":"text_completion","created":1727822657,"model":"meta-llama/Llama-3-8B","choices":[{"index":0,"text":" top holiday destination featuring scenic beauty and","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":5,"total_tokens":12,"completion_tokens":7}}
设置自定义自动扩缩器
在本部分中,您将使用自定义 Prometheus 指标设置 Pod 横向自动扩缩。您可以使用来自 vLLM 服务器的 Google Cloud Managed Service for Prometheus 指标。
如需了解详情,请参阅 Google Cloud Managed Service for Prometheus。这应在 GKE 集群上默认启用。
对集群设置自定义指标 Stackdriver 适配器:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yaml将 Monitoring Viewer 角色添加到自定义指标 Stackdriver 适配器使用的服务账号:
gcloud projects add-iam-policy-binding projects/${PROJECT_ID} \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapter将以下清单保存为
vllm_pod_monitor.yaml:将其应用于集群:
kubectl apply -f vllm_pod_monitor.yaml -n ${NAMESPACE}
在 vLLM 端点上创建负载
创建 vLLM 服务器的负载,以测试 GKE 如何使用自定义 vLLM 指标进行自动扩缩。
运行 bash 脚本 (
load.sh) 以向 vLLM 端点发送N个并发请求:#!/bin/bash N=PARALLEL_PROCESSES export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE}) for i in $(seq 1 $N); do while true; do curl http://$vllm_service:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "meta-llama/Llama-3.1-70B", "prompt": "Write a story about san francisco", "max_tokens": 1000, "temperature": 0}' done & # Run in the background done wait将 PARALLEL_PROCESSES 替换为您要运行的并行进程数。
运行 bash 脚本:
chmod +x load.sh nohup ./load.sh &
验证 Google Cloud Managed Service for Prometheus 是否注入指标
在 Google Cloud Managed Service for Prometheus 爬取指标并且您向 vLLM 端点添加负载后,您可以在 Cloud Monitoring 上查看指标。
在 Google Cloud 控制台中,前往 Metrics Explorer 页面。
点击 < > PromQL。
输入以下查询,以观察流量指标:
vllm:num_requests_waiting{cluster='CLUSTER_NAME'}
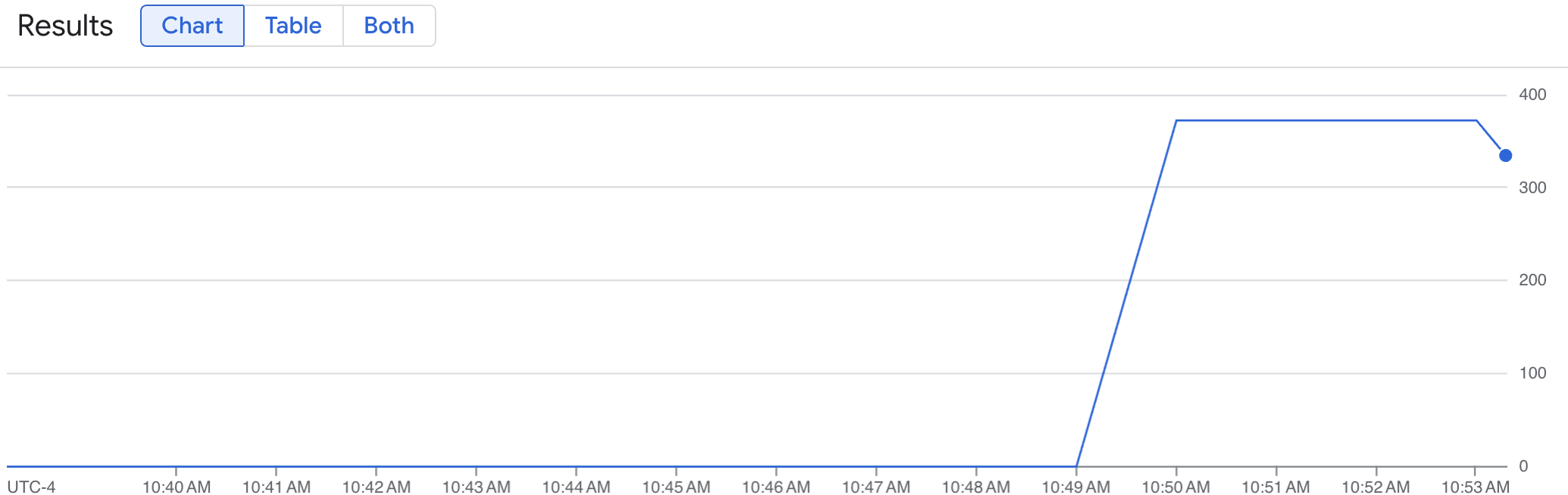
折线图显示了随时间变化的 vLLM 指标 (num_requests_waiting)。vLLM 指标从 0(预加载)纵向扩容到某个值(加载后)。此图表确认 vLLM 指标正在注入到 Google Cloud Managed Service for Prometheus 中。以下示例图表显示了初始预加载值为 0,在一分钟内达到接近 400 的最大后加载值。
部署 Pod 横向自动扩缩器配置
在决定根据哪个指标进行自动扩缩时,我们建议您为 vLLM TPU 使用以下指标:
num_requests_waiting:此指标与模型服务器队列中等待的请求数相关。当 kv 缓存已满时,此数量会开始显著增长。gpu_cache_usage_perc:此指标与 kv 缓存利用率相关,这与模型服务器上给定推理周期内处理的请求数直接相关。请注意,此指标在 GPU 和 TPU 上的工作方式相同,但与 GPU 命名架构相关联。
在优化吞吐量和费用时,以及在使用模型服务器的最大吞吐量可以实现延迟时间目标时,我们建议您使用 num_requests_waiting。
如果您的工作负载对延迟时间敏感,并且基于队列的扩缩不够快,无法满足您的要求,我们建议您使用 gpu_cache_usage_perc。
如需了解详情,请参阅自动扩缩使用 TPU 的大语言模型 (LLM) 推理工作负载的最佳实践。
为 HPA 配置选择 averageValue 目标时,您需要通过实验确定此值。如需了解有关如何优化这部分的更多思路,请参阅节省 GPU 费用:为 GKE 推理工作负载提供更智能的自动扩缩博文。这篇博文中使用的 profile-generator 也适用于 vLLM TPU。
在以下说明中,您将使用 num_requests_waiting 指标部署 HPA 配置。出于演示目的,您将指标设置为较低的值,以便 HPA 配置将 vLLM 副本扩缩为两个。如需使用 num_requests_waiting 部署 Pod 横向自动扩缩器配置,请按照以下步骤操作:
将以下清单保存为
vllm-hpa.yaml:Google Cloud Managed Service for Prometheus 中的 vLLM 指标遵循
vllm:metric_name格式。最佳实践: 使用
num_requests_waiting来扩缩吞吐量。对于对延迟时间敏感的 TPU 应用场景,请使用gpu_cache_usage_perc。部署 Pod 横向自动扩缩器配置:
kubectl apply -f vllm-hpa.yaml -n ${NAMESPACE}GKE 会调度另一个 Pod 进行部署,这会触发节点池自动扩缩器在部署第二个 vLLM 副本之前添加第二个节点。
观察 Pod 自动扩缩的进度:
kubectl get hpa --watch -n ${NAMESPACE}输出类似于以下内容:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE vllm-hpa Deployment/vllm-tpu <unknown>/10 1 2 0 6s vllm-hpa Deployment/vllm-tpu 34972m/10 1 2 1 16s vllm-hpa Deployment/vllm-tpu 25112m/10 1 2 2 31s vllm-hpa Deployment/vllm-tpu 35301m/10 1 2 2 46s vllm-hpa Deployment/vllm-tpu 25098m/10 1 2 2 62s vllm-hpa Deployment/vllm-tpu 35348m/10 1 2 2 77s等待 10 分钟,然后重复验证 Google Cloud Managed Service for Prometheus 是否注入指标部分中的步骤。Google Cloud Managed Service for Prometheus 现在会从两个 vLLM 端点注入指标。