O Google Distributed Cloud (apenas software) para bare metal suporta várias opções para o registo e a monitorização de clusters, incluindo serviços geridos baseados na nuvem, ferramentas de código aberto e compatibilidade validada com soluções comerciais de terceiros. Esta página explica estas opções e fornece orientações básicas sobre a seleção da solução certa para o seu ambiente.
Esta página destina-se a administradores, arquitetos e operadores que querem monitorizar o estado das aplicações ou dos serviços implementados, como a conformidade com o objetivo de nível de serviço (SLO). Para saber mais sobre as funções comuns e exemplos de tarefas referenciadas no conteúdo, consulte o artigo Funções e tarefas comuns do utilizador do GKE. Google Cloud
Opções para o Google Distributed Cloud
Tem várias opções de registo e monitorização para o seu cluster:
- Cloud Logging e Cloud Monitoring, ativados por predefinição nos componentes do sistema bare metal.
- O Prometheus e o Grafana estão disponíveis no Cloud Marketplace.
- Configurações validadas com soluções de terceiros.
Cloud Logging e Cloud Monitoring
O Google Cloud Observability é a solução de observabilidade integrada paraGoogle Cloud. Oferece uma solução de registo totalmente gerida, recolha de métricas, monitorização, painéis de controlo e alertas. O Cloud Monitoring monitoriza os clusters do Google Distributed Cloud de forma semelhante aos clusters do GKE baseados na nuvem.
O Cloud Logging e o Cloud Monitoring são ativados por predefinição quando cria clusters com as contas de serviço e as funções de gestão de identidade e de acesso (IAM) necessárias. Não pode desativar o Cloud Logging nem o Cloud Monitoring. Para mais informações sobre as contas de serviço e as funções necessárias, consulte o artigo Configure contas de serviço.
Os agentes podem ser configurados para alterar o seguinte:
- Âmbito do registo e da monitorização, desde apenas componentes do sistema (predefinição) até componentes do sistema e aplicações.
- Nível de métricas recolhidas, desde apenas um conjunto otimizado de métricas (a predefinição) a todas as métricas.
Consulte o artigo Configurar agentes do Stackdriver para o Google Distributed Cloud neste documento para mais informações.
O registo e a monitorização oferecem uma solução de observabilidade baseada na nuvem única, fácil de configurar e poderosa. Recomendamos vivamente a utilização do Logging e da monitorização quando executar cargas de trabalho no Google Distributed Cloud. Para aplicações com componentes em execução no Google Distributed Cloud e na infraestrutura no local padrão, pode considerar outras soluções para uma vista ponto a ponto dessas aplicações.
Para ver detalhes sobre a arquitetura, a configuração e os dados replicados para o seu Google Cloud projeto por predefinição, consulte o artigo Como funciona o registo e a monitorização do Google Distributed Cloud.
Para mais informações sobre o registo, consulte a documentação do Cloud Logging.
Para mais informações sobre a monitorização, consulte a documentação do Cloud Monitoring.
Para saber como ver e usar as métricas de utilização de recursos do Cloud Monitoring do Google Distributed Cloud ao nível da frota, consulte o artigo Use a vista geral do Google Kubernetes Engine.
Prometheus e Grafana
O Prometheus e o Grafana são dois produtos de monitorização de código aberto populares disponíveis no Cloud Marketplace:
O Prometheus recolhe métricas de aplicações e sistemas.
O Alertmanager processa o envio de alertas com vários mecanismos de alerta diferentes.
O Grafana é uma ferramenta de criação de painéis de controlo.
Recomendamos que use o serviço gerido do Google Cloud para o Prometheus, que se baseia no Cloud Monitoring, para todas as suas necessidades de monitorização. Com o Google Cloud Managed Service for Prometheus, pode monitorizar os componentes do sistema sem custo financeiro. O serviço gerido Google Cloud para Prometheus também é compatível com o Grafana. No entanto, se preferir um sistema de monitorização puramente local, pode optar por instalar o Prometheus e o Grafana nos seus clusters.
Se instalou o Prometheus localmente e quer recolher métricas de componentes do sistema, tem de conceder autorização à sua instância local do Prometheus para aceder aos pontos finais de métricas dos componentes do sistema:
Associe a conta de serviço da sua instância do Prometheus ao ClusterRole
gke-metrics-agentpredefinido e use o token da conta de serviço como credencial para extrair métricas dos seguintes componentes do sistema:kube-apiserverkube-schedulerkube-controller-managerkubeletnode-exporter
Use a chave e o certificado do cliente armazenados no segredo para autenticar a recolha de métricas do etcd.
kube-system/stackdriver-prometheus-etcd-scrapeCrie uma NetworkPolicy para permitir o acesso do seu espaço de nomes ao kube-state-metrics.
Soluções de terceiros
A Google colaborou com vários fornecedores de soluções de registo e monitorização de terceiros para ajudar os respetivos produtos a funcionar bem com o Google Distributed Cloud. Estes incluem o Datadog, o Elastic e o Splunk. Vão ser adicionados mais terceiros validados no futuro.
Os seguintes guias de soluções estão disponíveis para usar soluções de terceiros com o Google Distributed Cloud:
- Monitorização do Google Distributed Cloud com o Elastic Stack
- Recolha registos no Google Distributed Cloud com o Splunk Connect
Como funciona o registo e a monitorização do Google Distributed Cloud
O Cloud Logging e o Cloud Monitoring são instalados e ativados em cada cluster quando cria um novo cluster de administrador ou de utilizador.
Os agentes do Stackdriver incluem vários componentes em cada cluster:
Operador do Stackdriver (
stackdriver-operator-*). Gere o ciclo de vida de todos os outros agentes do Stackdriver implementados no cluster.Recurso personalizado do Stackdriver. Um recurso criado automaticamente como parte do processo de instalação do Google Distributed Cloud.
Agente de métricas do GKE (
gke-metrics-agent-*). Um DaemonSet baseado no OpenTelemetry Collector que extrai métricas de cada nó para o Cloud Monitoring. Também são incluídos umnode-exporterDaemonSet e uma implementaçãokube-state-metricspara fornecer mais métricas sobre o cluster.Encaminhador de registos do Stackdriver (
stackdriver-log-forwarder-*). Um DaemonSet do Fluent Bit que encaminha registos de cada máquina para o Cloud Logging. O encaminhador de registos armazena em buffer as entradas de registo no nó localmente e reenvia-as durante um máximo de 4 horas. Se o buffer ficar cheio ou se o encaminhador de registos não conseguir aceder à API Cloud Logging durante mais de 4 horas, os registos são ignorados.Agente de metadados (
stackdriver-metadata-agent-). Uma implementação que envia metadados para recursos do Kubernetes, como pods, implementações ou nós, para a API Config Monitoring for Ops. Esta adição de metadados permite-lhe consultar os dados de métricas por nome de implementação, nome do nó ou até mesmo nome do serviço Kubernetes.
Pode ver os agentes instalados pelo Stackdriver executando o seguinte comando:
kubectl -n kube-system get pods -l "managed-by=stackdriver"
O resultado deste comando é semelhante ao seguinte:
kube-system gke-metrics-agent-4th8r 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-8lt4s 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-dhxld 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-lbkl2 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-pblfk 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-qfwft 1/1 Running 1 (40h ago) 40h
kube-system kube-state-metrics-9948b86dd-6chhh 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-5s4pg 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-d9gwv 1/1 Running 2 (40h ago) 40h
kube-system node-exporter-fhbql 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-gzf8t 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-tsrpp 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-xzww7 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-8lwxh 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-f7cgf 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-fl5gf 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-q5lq8 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-www4b 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-xqgjc 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-metadata-agent-cluster-level-5bb5b6d6bc-z9rx7 1/1 Running 1 (40h ago) 40h
Métricas do Cloud Monitoring
Para ver uma lista de métricas recolhidas pelo Cloud Monitoring, consulte o artigo Ver métricas do Google Distributed Cloud.
Configurar agentes do Stackdriver para o Google Distributed Cloud
Os agentes do Stackdriver instalados com o Google Distributed Cloud recolhem dados sobre os componentes do sistema para fins de manutenção e resolução de problemas com os seus clusters. As secções seguintes descrevem a configuração e os modos de funcionamento do Stackdriver.
Apenas componentes do sistema (modo predefinido)
Após a instalação, os agentes do Stackdriver são configurados por predefinição para recolher registos e métricas, incluindo detalhes de desempenho (por exemplo, utilização da CPU e da memória) e metadados semelhantes, para componentes do sistema fornecidos pela Google. Estes incluem todas as cargas de trabalho no cluster de administrador e, para clusters de utilizadores, cargas de trabalho nos espaços de nomes kube-system, gke-system, gke-connect, istio-system e config-management-system.
Componentes e aplicações do sistema
Para ativar o registo e a monitorização de aplicações além do modo predefinido, siga os passos em Ative o registo e a monitorização de aplicações.
Métricas otimizadas (métricas predefinidas)
Por predefinição, as implementações kube-state-metrics em execução no cluster recolhem e comunicam um conjunto otimizado de métricas do kube ao Google Cloud Observability (anteriormente, Stackdriver).
São necessários menos recursos para recolher este conjunto de métricas otimizado, o que melhora o desempenho geral e a escalabilidade.
Para desativar as métricas otimizadas (não recomendado), substitua a predefinição no recurso personalizado do Stackdriver.
Use o serviço gerido do Google Cloud para o Prometheus para componentes do sistema selecionados
O serviço gerido do Google Cloud para Prometheus faz parte do Cloud Monitoring e está disponível como opção para componentes do sistema. As vantagens do Google Cloud Managed Service for Prometheus incluem o seguinte:
Pode continuar a usar a sua monitorização baseada no Prometheus sem alterar os seus alertas e painéis de controlo do Grafana.
Se usar o GKE e o Google Distributed Cloud, pode usar a mesma linguagem de consulta Prometheus (PromQL) para métricas em todos os seus clusters. Também pode usar o separador PromQL no Explorador de métricas na Google Cloud consola.
Ative e desative o Google Cloud Managed Service for Prometheus
A partir da versão 1.30.0-gke.1930 do Google Distributed Cloud,
o Google Cloud Managed Service for Prometheus está sempre ativado. Nas versões anteriores, pode editar o recurso do Stackdriver, stackdriver, para ativar ou desativar o
Google Cloud Managed Service for Prometheus. Para desativar o serviço gerido do Google Cloud para Prometheus para versões de clusters anteriores a 1.30.0-gke.1930, defina spec.featureGates.enableGMPForSystemMetrics no recurso stackdriver como false.
Veja dados de métricas
Quando enableGMPForSystemMetrics está definido como true, as métricas dos seguintes componentes têm um formato diferente para a forma como são armazenadas e consultadas no Cloud Monitoring:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- kubelet e cadvisor
- kube-state-metrics
- node-exporter
No novo formato, pode consultar as métricas anteriores através da linguagem de consulta Prometheus (PromQL).
Exemplo de consulta PromQL:
histogram_quantile(0.95, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le))
Configurar painéis de controlo do Grafana com o serviço gerido do Google Cloud para Prometheus
Para usar o Grafana com dados de métricas do Google Cloud Managed Service for Prometheus, tem de configurar e autenticar primeiro a origem de dados do Grafana. Para configurar e autenticar a origem de dados, usa o sincronizador de origens de dados (datasource-syncer) para gerar credenciais OAuth2 e sincronizá-las com o Grafana através da API de origens de dados do Grafana. O sincronizador de origens de dados define a API Cloud Monitoring como o URL do servidor Prometheus (o valor do URL começa com https://monitoring.googleapis.com) na origem de dados no Grafana.
Siga os passos em Consultar com o Grafana para autenticar e configurar uma origem de dados do Grafana para consultar dados do Google Cloud Managed Service for Prometheus.
É disponibilizado um conjunto de painéis de controlo do Grafana de exemplo no repositório anthos-samples no GitHub. Para instalar os painéis de controlo de exemplo, faça o seguinte:
Transfira os ficheiros JSON de exemplo:
git clone https://github.com/GoogleCloudPlatform/anthos-samples.git cd anthos-samples/gmp-grafana-dashboards
Se a sua origem de dados do Grafana foi criada com um nome diferente de
Managed Service for Prometheus, altere o campodatasourceem todos os ficheiros JSON:sed -i "s/Managed Service for Prometheus/[DATASOURCE_NAME]/g" ./*.json
Substitua [DATASOURCE_NAME] pelo nome da origem de dados no seu Grafana que foi direcionada para o serviço
frontenddo Prometheus.Aceda à IU do Grafana a partir do navegador e selecione + Importar no menu Painéis de controlo.
Carregue o ficheiro JSON ou copie e cole o conteúdo do ficheiro e selecione Carregar. Quando o conteúdo do ficheiro for carregado com êxito, selecione Importar. Opcionalmente, também pode alterar o nome e o UID do painel de controlo antes da importação.
O painel de controlo importado deve ser carregado com êxito se o Google Distributed Cloud e a origem de dados estiverem configurados corretamente. Por exemplo, a captura de ecrã seguinte mostra o painel de controlo configurado por
cluster-capacity.json.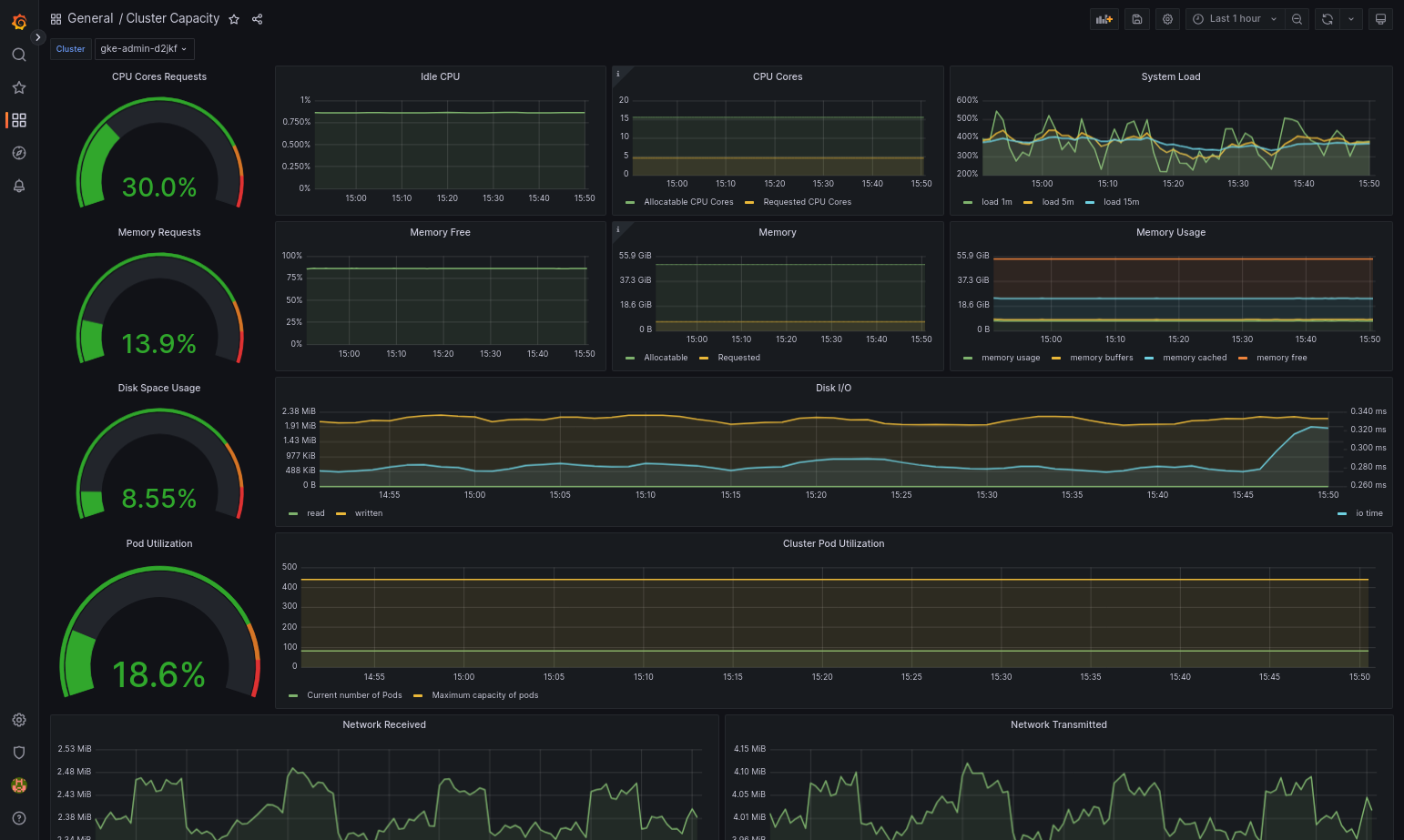
Recursos adicionais
Para mais informações sobre o serviço gerido do Google Cloud para Prometheus, consulte o seguinte:
Configurar recursos de componentes do Stackdriver
Quando cria um cluster, o Google Distributed Cloud cria automaticamente um recurso personalizado do Stackdriver. Pode editar a especificação no recurso personalizado para substituir os valores predefinidos dos pedidos e limites de CPU e memória de um componente do Stackdriver, e pode substituir separadamente a predefinição de métricas otimizadas.
Substituir os pedidos e os limites predefinidos de CPU e memória para um componente do Stackdriver
Os clusters com uma densidade de pods elevada introduzem uma sobrecarga de registo e monitorização mais elevada. Em casos extremos, os componentes do Stackdriver podem comunicar que estão perto do limite de utilização da CPU e da memória ou até podem estar sujeitos a reinícios constantes devido a limites de recursos. Neste caso, para substituir os valores predefinidos dos pedidos e limites de CPU e memória de um componente do Stackdriver, siga estes passos:
Execute o seguinte comando para abrir o recurso personalizado do Stackdriver num editor de linha de comandos:
kubectl -n kube-system edit stackdriver stackdriver
No recurso personalizado do Stackdriver, adicione a secção
resourceAttrOverrideno campospec:resourceAttrOverride: DAEMONSET_OR_DEPLOYMENT_NAME/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITYTenha em atenção que a secção
resourceAttrOverridesubstitui todos os limites e pedidos predefinidos existentes para o componente especificado. Os seguintes componentes são suportados peloresourceAttrOverride:gke-metrics-agent/gke-metrics-agentstackdriver-log-forwarder/stackdriver-log-forwarderstackdriver-metadata-agent-cluster-level/metadata-agentnode-exporter/node-exporterkube-state-metrics/kube-state-metrics
Um ficheiro de exemplo tem o seguinte aspeto:
apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a resourceAttrOverride: gke-metrics-agent/gke-metrics-agent: requests: cpu: 110m memory: 240Mi limits: cpu: 200m memory: 4.5GiPara guardar as alterações ao recurso personalizado do Stackdriver, guarde e saia do editor de linha de comandos.
Verifique o estado do seu Pod:
kubectl -n kube-system get pods -l "managed-by=stackdriver"
Uma resposta para um Pod saudável tem o seguinte aspeto:
gke-metrics-agent-4th8r 1/1 Running 1 40h
Verifique a especificação do pod do componente para se certificar de que os recursos estão definidos corretamente.
kubectl -n kube-system describe pod POD_NAME
Substitua
POD_NAMEpelo nome do podcast que acabou de alterar. Por exemplo,gke-metrics-agent-4th8r.A resposta tem o seguinte aspeto:
Name: gke-metrics-agent-4th8r Namespace: kube-system ... Containers: gke-metrics-agent: Limits: cpu: 200m memory: 4.5Gi Requests: cpu: 110m memory: 240Mi ...
Desative as métricas otimizadas
Por predefinição, as implementações kube-state-metricsem execução no cluster recolhem e comunicam um conjunto otimizado de métricas do kube ao Stackdriver. Se precisar de métricas adicionais,
recomendamos que encontre uma substituição na lista de métricas do Google Distributed Cloud.
Seguem-se alguns exemplos de substituições que pode usar:
| Métrica desativada | Substituições |
|---|---|
kube_pod_start_time |
container/uptime |
kube_pod_container_resource_requests |
container/cpu/request_cores container/memory/request_bytes |
kube_pod_container_resource_limits |
container/cpu/limit_cores container/memory/limit_bytes |
Para desativar a predefinição de métricas otimizadas (não recomendado), faça o seguinte:
Abra o recurso personalizado do Stackdriver num editor de linha de comandos:
kubectl -n kube-system edit stackdriver stackdriver
Defina o campo
optimizedMetricscomofalse:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a optimizedMetrics: false
Guarde as alterações e saia do editor de linha de comandos.
Servidor de métricas
O servidor de métricas é a origem das métricas de recursos do contentor para vários pipelines de escalabilidade automática. O Metrics Server obtém métricas dos kubelets e expõe-nas através da API Kubernetes Metrics. Em seguida, o HPA e o VPA usam estas métricas para determinar quando acionar o ajuste de escala automático. O servidor de métricas é dimensionado através do redimensionador de suplementos.
Em casos extremos em que a elevada densidade de pods cria uma sobrecarga excessiva de registo e monitorização, o servidor de métricas pode ser parado e reiniciado devido a limitações de recursos. Neste caso, pode atribuir mais recursos ao servidor de métricas editando o configmap metrics-server-config no espaço de nomes gke-managed-metrics-server e alterando o valor de cpuPerNode e memoryPerNode.
kubectl edit cm metrics-server-config -n gke-managed-metrics-server
O conteúdo de exemplo do ConfigMap é:
apiVersion: v1
data:
NannyConfiguration: |-
apiVersion: nannyconfig/v1alpha1
kind: NannyConfiguration
cpuPerNode: 3m
memoryPerNode: 20Mi
kind: ConfigMap
Após atualizar o ConfigMap, recrie os pods do servidor de métricas com o seguinte comando:
kubectl delete pod -l k8s-app=metrics-server -n gke-managed-metrics-server
Encaminhamento de registos e métricas
O encaminhador de registos do Stackdriver (stackdriver-log-forwarder) envia registos de cada máquina de nó para o Cloud Logging. Da mesma forma, o agente de métricas do GKE (gke-metrics-agent) envia métricas de cada máquina de nó para o Cloud Monitoring. Antes de os registos e as métricas serem enviados, o operador do Stackdriver (stackdriver-operator) anexa o valor do campo clusterLocation no recurso personalizado stackdriver a cada entrada de registo e métrica antes de serem encaminhados para Google Cloud. Além disso, os registos e as métricas estão associados ao Google Cloud projetostackdriver especificado na especificação do recurso personalizado (spec.projectID).
O recurso stackdriver recebe valores para os campos clusterLocation e projectID
dos campos
location
e
projectID
na secção clusterOperations do recurso Cluster no momento da criação do cluster.
Todas as métricas e entradas de registo enviadas pelos agentes do Stackdriver são encaminhadas para um ponto final de carregamento global. A partir daí, os dados são encaminhados para o ponto final Google Cloud regional Google Cloud acessível mais próximo para garantir a fiabilidade do transporte de dados.
Assim que o ponto final global recebe a métrica ou a entrada do registo, o que acontece a seguir depende do serviço:
Como o encaminhamento de registos está configurado: quando o ponto final de registo recebe uma mensagem de registo, o Cloud Logging passa a mensagem através do encaminhador de registos. Os destinos e os filtros na configuração do Log Router determinam como encaminhar a mensagem. Pode encaminhar as entradas de registo para destinos como contentores de registo regionais, que armazenam a entrada de registo, ou para o Pub/Sub. Para mais informações sobre como funciona o encaminhamento de registos e como o configurar, consulte a vista geral do encaminhamento e armazenamento.
Nem o campo
clusterLocationno recurso personalizadostackdrivernem o campoclusterOperations.locationna especificação do cluster são considerados neste processo de encaminhamento. Para os registos,clusterLocationé usado apenas para etiquetar entradas de registo, o que pode ser útil para filtrar no Explorador de registos.Como o encaminhamento de métricas está configurado: quando o ponto final de métricas recebe uma entrada de métricas, a entrada é encaminhada automaticamente para ser armazenada na localização especificada pela métrica. A localização na métrica veio do campo
clusterLocationno recurso personalizadostackdriver.Planeie a sua configuração: quando configurar o Cloud Logging e o Cloud Monitoring, configure o Log Router e especifique um
clusterOperations.locationadequado com localizações que melhor satisfaçam as suas necessidades. Por exemplo, se quiser que os registos e as métricas sejam enviados para a mesma localização, definaclusterOperations.locationpara a mesma Google Cloud região que o Log Router está a usar para o seu Google Cloud projeto.Atualize a configuração dos registos quando necessário: pode fazer alterações em qualquer altura às definições de destino dos registos devido a requisitos empresariais, como planos de recuperação de desastres. As alterações à configuração do Log Router noGoogle Cloud entram em vigor rapidamente. Os campos
locationeprojectIDna secçãoclusterOperationsdo recurso Cluster são imutáveis, pelo que não podem ser atualizados depois de criar o cluster. Não recomendamos que altere os valores no recursostackdriverdiretamente. Este recurso é revertido para o estado de criação do cluster original sempre que uma operação do cluster, como uma atualização, aciona uma reconciliação.
Requisitos de configuração para o registo e a monitorização
Existem vários requisitos de configuração para ativar o Cloud Logging e o Cloud Monitoring com o Google Distributed Cloud. Estes passos estão incluídos no artigo Configurar uma conta de serviço para utilização com o registo e a monitorização na página Ativar serviços Google e na seguinte lista:
- Tem de criar um espaço de trabalho do Cloud Monitoring noGoogle Cloud projeto. Para o fazer, clique em Monitorização na Google Cloud consola e siga o fluxo de trabalho.
Tem de ativar as seguintes APIs Stackdriver:
Tem de atribuir as seguintes funções de IAM à conta de serviço usada pelos agentes do Stackdriver:
logging.logWritermonitoring.metricWriterstackdriver.resourceMetadata.writermonitoring.dashboardEditoropsconfigmonitoring.resourceMetadata.writer
Etiquetas de registo
Muitos registos do Google Distributed Cloud têm uma etiqueta F:
logtag: "F"
Esta etiqueta significa que a entrada de registo está concluída ou completa. Para saber mais acerca desta etiqueta, consulte o formato de registo nas propostas de design do Kubernetes no GitHub.
Preços
Num cluster do Google Distributed Cloud, os registos e as métricas do sistema incluem o seguinte:
- Registos e métricas de todos os componentes num cluster de administrador.
- Registos e métricas de componentes nestes espaços de nomes num cluster de utilizador:
kube-system,gke-system,gke-connect,knative-serving,istio-system,monitoring-system,config-management-system,gatekeeper-system,cnrm-system.
Para mais informações, consulte os preços da Google Cloud Observability.
Para saber mais sobre o crédito para métricas do Cloud Logging, contacte a equipa de vendas para saber mais sobre os preços.